使用线程池多线程爬取链接,检验链接正确性
Posted 不当咸鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用线程池多线程爬取链接,检验链接正确性相关的知识,希望对你有一定的参考价值。
我们网站大多数链接都是活链接都是运营配置的,而有的时候运营会将链接配置错误使访问出错,有时也会因为程序bug造成访问出错,因此对主站写了个监控脚本,使用python爬取主站设置的链接并访问,统计访问出错的链接,因为链接有上百个,所以使用了多线程进行,因为http访问是io密集型,所以python多线程还是可以很好的完成并发访问的。
首先是index.py
使用了线程池管理线程,做到了配置需要检验的链接,然后爬取配置的链接页面中的所有链接,同时因为可能子页面许多url链接是和主站重复的,也可以做剔除
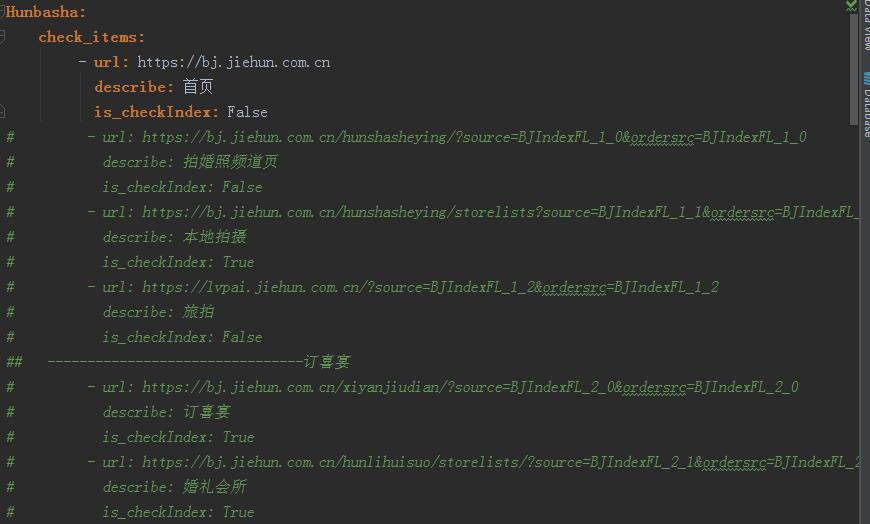
配置文件使用了yml文件: is_checkIndex 是否检查与首页重复,如果为True,则剔除和首页重复的url
爬取链接使用了requests和正则表达式
最后是统计出错的链接,在这里也做了筛选,只筛选与网站相关的url,像一些合作网站等广告链接是不会记录返回
# encoding=utf-8 from queue import Queue import queue from Tool.hrefTool import HrefTest import threading import time from Tool.Log.logTool import LogTool index_url = \'https://bj.jiehun.com.cn\' class HunIndex: def __init__(self, url, is_checkIndex, index_items): self.url_queue = Queue() self.headers = { \'User-Agent\': \'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6\', } self.thread_stop = False self.items = HrefTest.get_hostsit_href(url, self.headers) if is_checkIndex: self.index_items = index_items self.start_time = time.time() self.stop_time = None self.error_list = [] self.url = url self.is_checkIndex = is_checkIndex self.execute_items = [] def get_index_urlitem(self): LogTool.info(\'开始获取页面url,当前页面:{url}\'.format(url=self.url)) if self.is_checkIndex: self.execute_items.extend([item for item in self.items if item not in self.index_items]) else: self.execute_items.extend(self.items) for item in list(set(self.execute_items)): if HrefTest.check_url(item[0]): item1 = (HrefTest.change_url(item[0], index_url), item[1]) self.url_queue.put(item1, block=True, timeout=5) LogTool.info(\'页面url获取完成,共{sum_url}个url\'.format(sum_url=self.url_queue.qsize())) def _parse_url(self, item): try: LogTool.info(\'检查url: %s, 标题:%s\' % (str(item[0]), str(item[1]))) response = HrefTest.get(item[0], self.headers) except Exception as e: LogTool.error(\'请求失败,url=%s, error_messge:%s\' % (str(item[0]), e)) print(\'error-%s, message-%s\' % (item[0], e)) error = list(item) print(\'error\', list(item)) error.append(\'error_message=%s\' % e) self.error_list.append(error) else: if not response.status_code == 200: LogTool.error(\'请求失败,url=%s, error_code:%s\' % (str(item[0]), response.status_code)) print(\'error-%s error_code:%s\' % (item[0], response.status_code)) error = list(item).append(\'error_message=%s\' % response.status_code) print(\'error\', item) print(\'----\', error) self.error_list.append(error) else: LogTool.info(\'请求成功,测试通过,url=%s,title=%s\' % (str(item[0]), str(item[1]))) print(\'success-%s\' % item[0]) pass def parse_url(self): while not self.thread_stop: try: item = self.url_queue.get(timeout=5) except queue.Empty: self.thread_stop = True break self._parse_url(item) self.url_queue.task_done() def run(self): thread_list = [] t_url = threading.Thread(target=self.get_index_urlitem) thread_list.append(t_url) for i in range(35): t_parse = threading.Thread(target=self.parse_url) thread_list.append(t_parse) for t in thread_list: t.setDaemon(True) t.start() for q in [self.url_queue]: q.join() self.stop_time = time.time() if __name__ == \'__main__\': page_url = \'https://bj.jiehun.com.cn/hunshasheying/storelists?source=BJIndexFL_1_1&ordersrc=BJIndexFL_1_1\' hun = HunIndex(page_url, True) hun.run() sum_time = int(hun.stop_time - hun.start_time) print(sum_time)
爬取链接:
def get_hostsit_href(cls, url, headers): \'\'\' 获取url页面所有href a标签 :param url: 要抓取的url :param headers: 请求头 :return: 所有符合的url 及标题 \'\'\' try: response = requests.request(\'GET\', url=url, headers=headers) except Exception as e: print(\'error-{url} message-{e}\'.format(url=url, e=e)) else: # print(response.text) # pattern = re.compile(\'<a.*href="(.*?)".{0}=?"?.*"?>(.*?)</a>\') pattern = re.compile(\'href="(.*?)"{1}.?.{0,10}?=?"?.*"?>(.+)?</a>\') # pattern = re.compile(\'<a\\b[^>]+\\bhref="([^"]*)"[^>]*>([\\s\\S]*?)</a>\') items = re.findall(pattern, response.text) return items
比较简单 正则写的不是很匹配,但是已经能匹配出90%以上的链接,完全满足需求了,因为对这方面还不是很熟悉,还有待学习。
效果:
因为链接访问,即使多线程也要看网速等影响因素,网速好首页300多个链接用时20秒左右,不好要40来秒,作为日常检测还是可以的,如果检测我们网站主站所有主频道页面,基本在10分钟内可以完成,但是如果要是完成分城市站的所有监控那就有点鸡肋了,写过一级链接检测完接着检测二级链接的,用了半个多小时,4万多个链接,有点过分了。。,并且有的链接可能只是id不同,并没有很大的实际意义(例如商品类的url只是id不同,那这类检测在这4万多个中可能就有很多个重复的类似链接),后续看如何优化。。
以上是关于使用线程池多线程爬取链接,检验链接正确性的主要内容,如果未能解决你的问题,请参考以下文章