大数据平台架构
Posted rona1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据平台架构相关的知识,希望对你有一定的参考价值。
一、数据采集
1.ETL,数据从来源端经过抽取(extract)、交互转换(transform)、加载(load)至目的端的过程。
开源工具:Apatat,Scriptella,Talend,kettle
2.实时采集
Flume,
Flink 流处理,批处理都可
Kafka场景应用
-
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
-
消息系统:解耦和生产者和消费者、缓存消息等。
-
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
-
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
-
流式处理:比如spark streaming和storm
-
事件源
分布式流处理平台 Kafka Streams。
Faust 把 Kafka Streams 带到了 PythonFaust 需求 Python 3.6 或以上
二、数据存储
HDFS
Hive 根据SQL自动生成MapReduce
HBase 分布式面向列开源数据库
关系数据库
Sqoop,DataX HDFS,Hive与关系数据库之间传递 Sqoop比较繁重
三、分析计算
Spark 在MapReduce的基础上进行了改进,它主要使用内存进行中间计算数据存储,加快了计算执行时间,RDD弹性数据集,Dataframe
SparkSQL
SparkMLlib
统计分析、数据挖掘、机器学习、深度学习
四、实时计算
Storm
Spark Streaming 将实时流入的数据切分成小的一批一批的数据,然后将这些小的一批批数据交给Spark执行。由于数据量比较小,Spark Streaming又常驻系统,不需要重新启动,因此可以在毫秒级完成计算,看起来像是实时计算一样
Flink 其架构原理和Spark Streaming很相似,它可以基于不同的数据源,根据数据量和计算场景的要求,灵活地适应流计算和批处理计算。
五、调度
调度引擎Oozie,HUE
六、应用呈现
CRM,ERP,FineReport,
OLAP 联机分析 多维度多度量,钻取,旋转,切片,切块,数据CUBE与运算。
一个常见大数据平台架构
一个常见的大数据平台架构
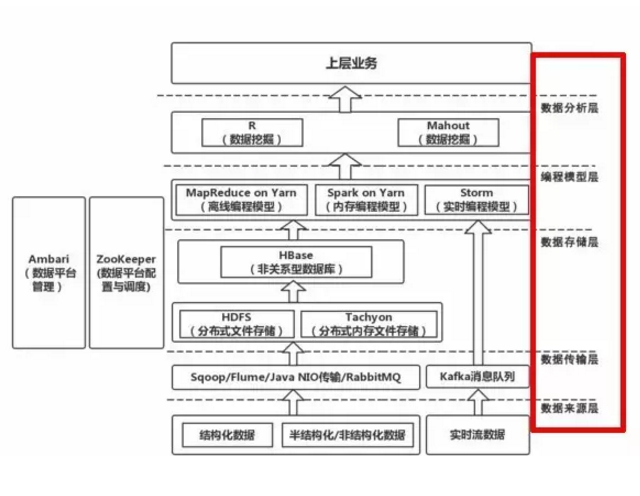
这是一个典型的大数据架构,且对架构进行了「分层」,分为「数据源层」、「数据传输层」、「数据存储层」、「编程模型层」和「数据分析层」,如果继续往上走的话,还有「数据可视化层」和「数据应用层」。
以上是关于大数据平台架构的主要内容,如果未能解决你的问题,请参考以下文章
如何利用大数据技术深入挖掘商业价值--Oracle Big Data Fundamentals 专家培训,火热报名中!
Big Data - Hadoop - MapReduce初学Hadoop之图解MapReduce与WordCount示例分析
Big Data - Hadoop - MapReduce通过腾讯shuffle部署对shuffle过程进行详解
大数据时代之一,Spark或为Big data主流平台,什么是Scala函数式编程?计算机诞生之前,数学与统计学家们是如何计算?