如何查看hive引擎 hive.execution.engine
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何查看hive引擎 hive.execution.engine相关的知识,希望对你有一定的参考价值。
参考技术A Hive中在做多表关联时,由于Hive的SQL优化引擎还不够强大,表的关联顺序不同往往导致产生不同数量的MapReduce作业数。这时就需要通过分析执行计划对SQL进行调整,以获得最少的MapReduce作业数。 参考技术B set hive.execution.engine;CDH之HIVE-ON-SPARKSpark
文章目录
HIVE ON SPARK配置
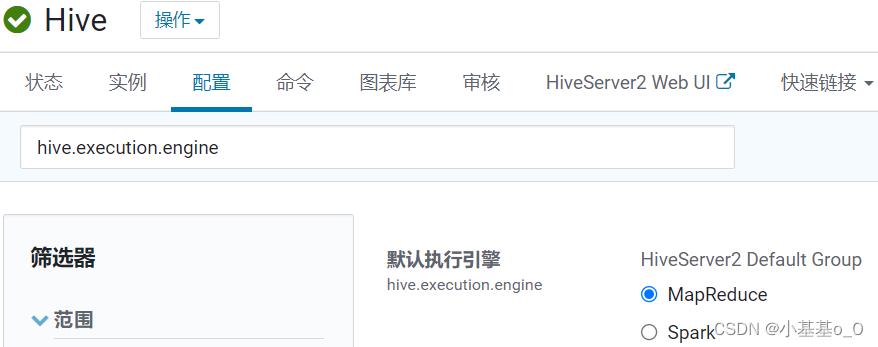
HIVE默认引擎
hive.execution.engine
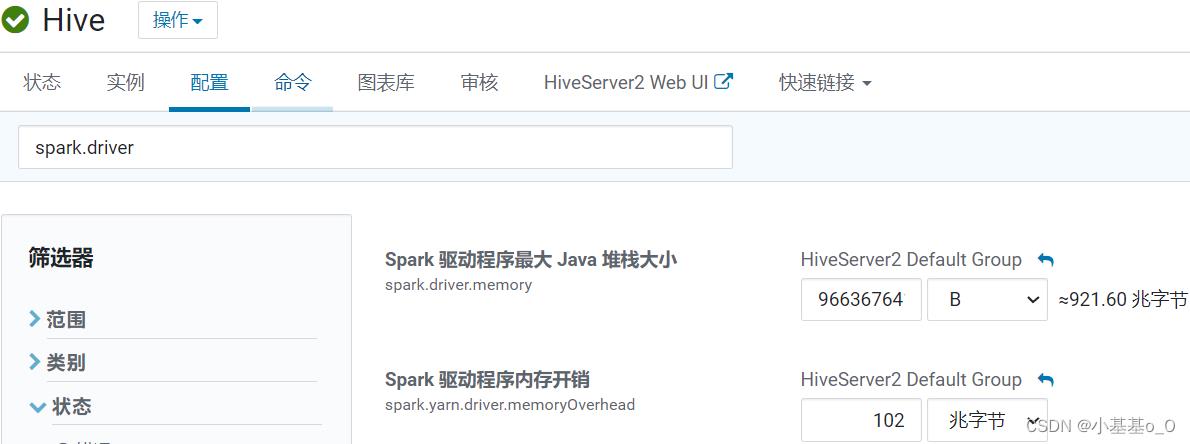
Driver配置
spark.driver
| 配置名称 | 说明 | 建议 |
|---|---|---|
spark.driver.memory | 用于Driver进程的内存 | YARN可分配总内存的10% |
spark.driver.memoryOverhead | 集群模式下每个Driver进程的堆外内存 | D r i v e r 内 存 × 0.1 Driver内存 \\times 0.1 Driver内存×0.1 |
spark.yarn.driver.memoryOverhead | 和spark.driver.memoryOverhead差不多,YARN场景专用 | A M 内 存 × 0.1 AM内存 \\times 0.1 AM内存×0.1 |
spark.driver.cores | 集群模式下,用于Driver进程的核心数 |
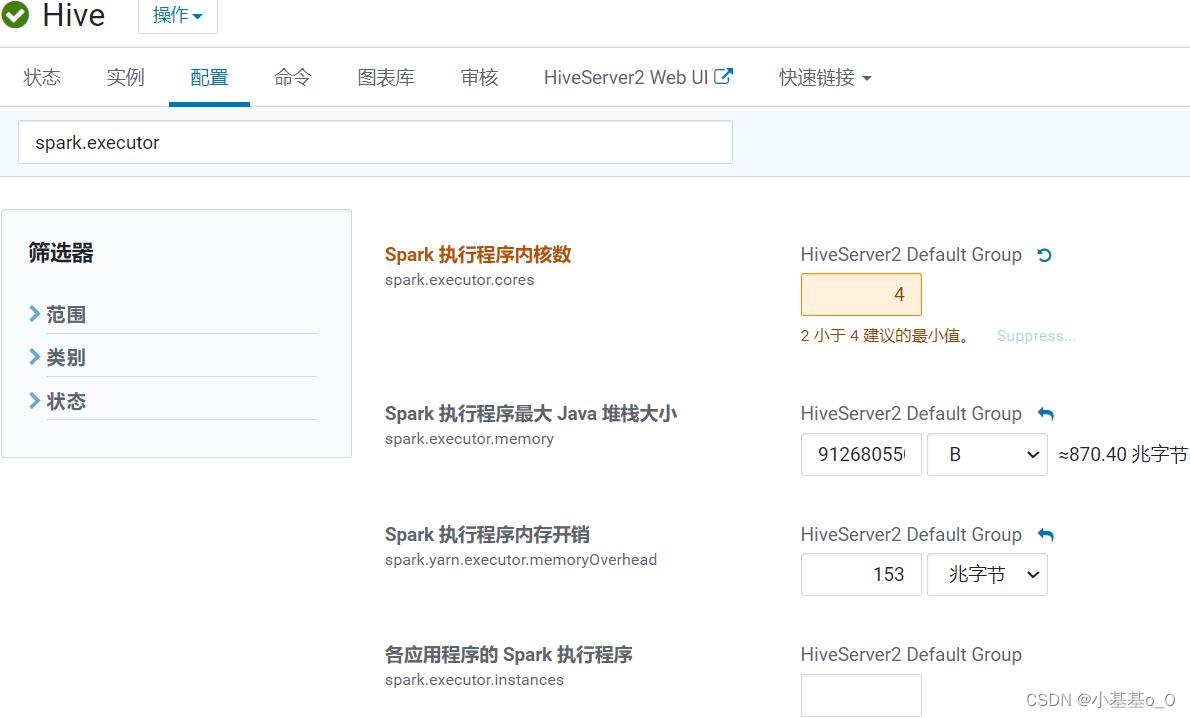
Executor配置
spark.executor
| 配置名称 | 说明 | 建议 |
|---|---|---|
spark.executor.cores | 单个Executor的CPU核数 | 4 |
spark.executor.memory | Executor进程的堆内存大小,用于数据的计算和存储 | |
spark.executor.memoryOverhead | Executor进程的堆外内存,用于JVM的额外开销,操作系统开销等 | spark.executor.memoryOverhead=spark.executor.memory
×
\\times
× 0.1 |
spark.executor.instances | 静态分配executor数量 | 不使用静态分配 |
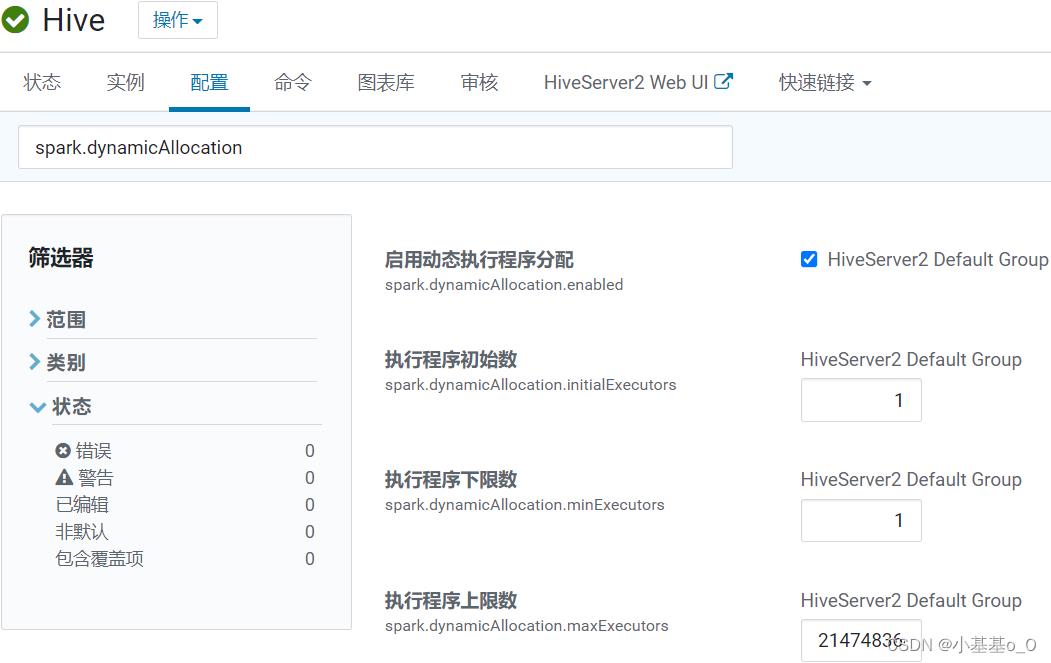
spark.dynamicAllocation
| 配置名称 | 说明 | 建议 |
|---|---|---|
spark.dynamicAllocation.enabled | 是否启用 Executor个数动态调配 | 启用 |
spark.dynamicAllocation.initialExecutors | 初始Executor个数 | |
spark.dynamicAllocation.minExecutors | 最少Executor个数 | 1 |
spark.dynamicAllocation.maxExecutors | 最多Executor个数 | |
spark.dynamicAllocation.executorIdleTimeout | Executor闲置超时就会被移除 | 默认60秒 |
spark.dynamicAllocation.schedulerBacklogTimeout | 待处理的任务积压超时就会申请启动新的Executor | 默认1秒 |
- 假设某节点 NM 有16个核可供Executor使用
若spark.executor.core配置为4,则该节点最多可启动4个Executor
若spark.executor.core配置为5,则该节点最多可启动3个Executor,会剩余1个核未使用 - Executor个数的指定方式有两种:静态分配和动态分配
- 动态分配可根据一个Spark应用的工作负载,动态地调整Executor数量
资源不够时增加Executor,Executor不工作时将被移除
启用方式是spark.dynamicAllocation.enabled设为true
- 动态分配可根据一个Spark应用的工作负载,动态地调整Executor数量
Spark
shuffle服务
- 启用了动态分配Executor数量的情况下,shuffle服务允许删除Executor时保留其编写的shuffle文件
每个工作节点上都要设置外部shuffle服务
spark.shuffle.service
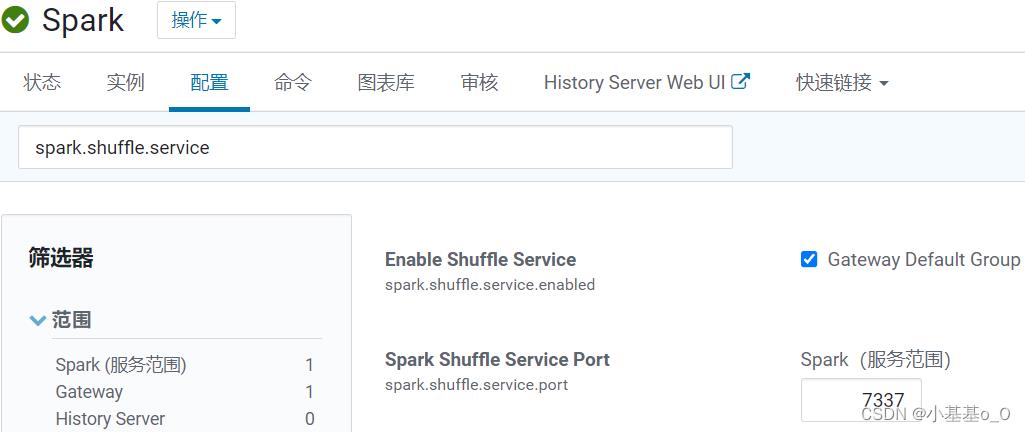
| Property Name | 说明 | 版本始于 | 建议 |
|---|---|---|---|
spark.shuffle.service.enabled | 启用额外shuffle服务,可保存Executor写的shuffle文件,从而可以安全移除工作完的Executor,或者在Executor失败的情况下继续获取shuffle文件 | 1.2.0 | 开启 |
spark.shuffle.service.port | 外部shuffle服务的端口 | 1.2.0 | 默认 |
建议
- 大数据集群分为管理节点和工作节点,建议:
管理节点的逻辑核数:内存(G)=1:2或1:4
工作节点的逻辑核数:内存(G)=1:4或1:8
| 工作节点 | p101 | p102 | p103 | p104 | P105 | 总 | max |
|---|---|---|---|---|---|---|---|
| 内存(G) | 128 | 128 | 128 | 128 | 128 | 640 | 128 |
| 逻辑CPU个数(虚拟核心数) | 32 | 32 | 32 | 32 | 32 | 160 | 32 |
NM可分配内存yarn.nodemanager.resource.memory-mb | 120 | 120 | 120 | 120 | 120 | 600 | 120 |
NM可分配虚拟核心数yarn.nodemanager.resource.cpu-vcores | 30 | 30 | 30 | 30 | 30 | 150 | 30 |
- ApplicationMaster
AM内存:60G(总内存的十分之一)
AM虚拟核心数:15 - MapReduce
Map内存:20G(单节点yarn.nodemanager.resource.memory-mb的约数)
Map虚拟核心数:5(单节点yarn.nodemanager.resource.cpu-vcores的约数)
Reduce内存:20G
Reduce虚拟核心数:5 - Spark
spark.driver.memory:54G
spark.driver.memoryOverhead:6G
spark.executor.memory:18G
spark.executor.memoryOverhead:2G
spark.executor.cores:5
附录
| 英 | 🔉 | 中 |
|---|---|---|
| idle | ˈaɪd(ə)l | adj. 无事可做的;闲置的;v. 无所事事;(发动机、车辆)空转 |
| overhead | ˌoʊvərˈhed | adv. 在头顶上方;adj. 头顶上的;n. 营运费用;日常管理费;间接费用 |
| backlog | ˈbæklɔːɡ | n. 积压的工作 |
| pending | ˈpendɪŋ | adj. 待定的,待处理的;即将发生的;prep. 直到……为止:v. 等候判定或决定 |
| pend | pend | v. 等候判定;悬挂 |
原文:
spark.apache.org/docs/latest=>Configuration
以上是关于如何查看hive引擎 hive.execution.engine的主要内容,如果未能解决你的问题,请参考以下文章
当 hive.execution.engine 重视其 tez 时出现 NoSuchMethodError
Hive启动时报错Missing Hive Execution Jar: /opt/module/hive/lib/hive-exec-*.jar