CDH之HIVE-ON-SPARKSpark配置
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CDH之HIVE-ON-SPARKSpark配置相关的知识,希望对你有一定的参考价值。
文章目录
HIVE ON SPARK配置
CDH6.3.2的HIVE版本为:
2.1.1+cdh6.3.2
HIVE默认引擎
hive.execution.engine

Driver配置
spark.driver

| 配置名称 | 说明 | 建议 |
|---|---|---|
spark.driver.memory | 用于Driver进程的内存 | YARN可分配总内存的10% |
spark.driver.memoryOverhead | 集群模式下每个Driver进程的堆外内存 | D r i v e r 内存 × 0.1 Driver内存 \\times 0.1 Driver内存×0.1 |
spark.yarn.driver.memoryOverhead | 和spark.driver.memoryOverhead差不多,YARN场景专用 | A M 内存 × 0.1 AM内存 \\times 0.1 AM内存×0.1 |
spark.driver.cores | 集群模式下,用于Driver进程的核心数 |
Executor配置
spark.executor

| 配置名称 | 说明 | 建议 |
|---|---|---|
spark.executor.cores | 单个Executor的CPU核数 | 4 |
spark.executor.memory | Executor进程的堆内存大小,用于数据的计算和存储 | |
spark.executor.memoryOverhead | Executor进程的堆外内存,用于JVM的额外开销,操作系统开销等 | spark.executor.memoryOverhead=spark.executor.memory
×
\\times
× 0.1 |
spark.executor.instances | 静态分配executor数量 | 不使用静态分配 |
Spark on YARN的内存模型
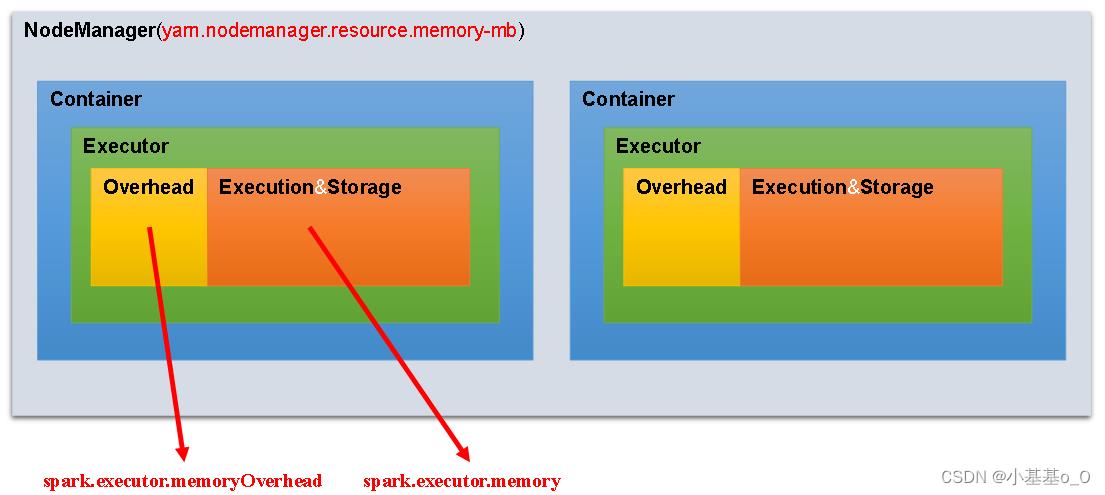
Executor数量动态分配
spark.dynamicAllocation

| 配置名称 | 说明 | 建议 |
|---|---|---|
spark.dynamicAllocation.enabled | 是否启用 Executor个数动态调配 | 启用 |
spark.dynamicAllocation.initialExecutors | 初始Executor个数 | |
spark.dynamicAllocation.minExecutors | 最少Executor个数 | 1 |
spark.dynamicAllocation.maxExecutors | 最多Executor个数 | |
spark.dynamicAllocation.executorIdleTimeout | Executor闲置超时就会被移除 | 默认60秒 |
spark.dynamicAllocation.schedulerBacklogTimeout | 待处理的任务积压超时就会申请启动新的Executor | 默认1秒 |
- 假设某节点 NM 有16个核可供Executor使用
若spark.executor.core配置为4,则该节点最多可启动4个Executor
若spark.executor.core配置为5,则该节点最多可启动3个Executor,会剩余1个核未使用 - Executor个数的指定方式有两种:静态分配和动态分配
- 动态分配可根据一个Spark应用的工作负载,动态地调整Executor数量
资源不够时增加Executor,Executor不工作时将被移除
启用方式是spark.dynamicAllocation.enabled设为true
- 动态分配可根据一个Spark应用的工作负载,动态地调整Executor数量
Spark配置
CDH6.3.2的Spark版本为:
2.4.0+cdh6.3.2
shuffle服务
- 启用了动态分配Executor数量的情况下,shuffle服务允许删除Executor时保留其编写的shuffle文件
每个工作节点上都要设置外部shuffle服务
spark.shuffle.service
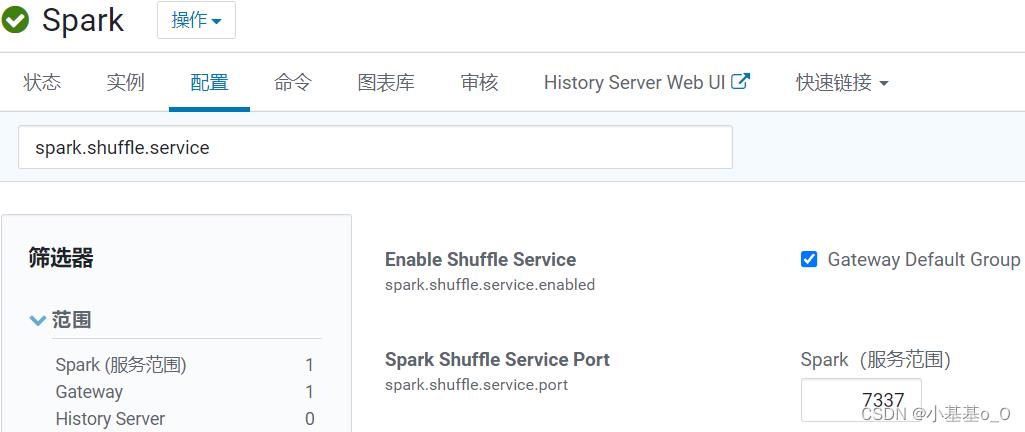
| Property Name | 说明 | 版本始于 | 建议 |
|---|---|---|---|
spark.shuffle.service.enabled | 启用额外shuffle服务,可保存Executor写的shuffle文件,从而可以安全移除工作完的Executor,或者在Executor失败的情况下继续获取shuffle文件 | 1.2.0 | 开启 |
spark.shuffle.service.port | 外部shuffle服务的端口 | 1.2.0 | 默认 |
配置建议
-
大数据集群分为管理节点和工作节点,建议:
管理节点的逻辑核数:内存(G)=1:2或1:4
工作节点的逻辑核数:内存(G)=1:4或1:8 -
建议给到 NM 约80%服务器资源,例如服务器有128G和32核,则:
yarn.nodemanager.resource.memory-mb可给100G
yarn.nodemanager.resource.cpu-vcores可给25
| 工作节点 | p101 | p102 | p103 | p104 | 总 | max |
|---|---|---|---|---|---|---|
| 内存(G) | 128 | 128 | 128 | 128 | 512 | 128 |
| 逻辑CPU个数(虚拟核心数) | 32 | 32 | 32 | 32 | 128 | 32 |
NM 可分配内存(G)yarn.nodemanager.resource.memory-mb | 100 | 100 | 100 | 100 | 400 | 100 |
NM 可分配虚拟核心数yarn.nodemanager.resource.cpu-vcores | 25 | 25 | 25 | 25 | 100 | 25 |
- MapReduce
AM内存:12G
AM虚拟核心数:3
Map内存:20G(单节点yarn.nodemanager.resource.memory-mb的约数)
Map虚拟核心数:5(单节点yarn.nodemanager.resource.cpu-vcores的约数)
Reduce内存:20G
Reduce虚拟核心数:5 - Spark
spark.driver.memory:10.8G
spark.driver.memoryOverhead:1.2G
spark.executor.memory:18G
spark.executor.memoryOverhead:2G
spark.executor.cores:5
Spark On YARN Cluster,Driver在ApplicationMaster中启动,Driver内存应小于AM内存
yarn.nodemanager.resource.memory-mb>50G,此时建议Driver内存为12G
附录
| 英 | 🔉 | 中 |
|---|---|---|
| idle | ˈaɪd(ə)l | adj. 无事可做的;闲置的;v. 无所事事;(发动机、车辆)空转 |
| overhead | ˌoʊvərˈhed | adv. 在头顶上方;adj. 头顶上的;n. 营运费用;日常管理费;间接费用 |
| backlog | ˈbæklɔːɡ | n. 积压的工作 |
| pending | ˈpendɪŋ | adj. 待定的,待处理的;即将发生的;prep. 直到……为止:v. 等候判定或决定 |
| pend | pend | v. 等候判定;悬挂 |
原文地址:
spark.apache.org/docs/latest=>Configuration
| Application Properties | Default Meaning | Since | Version |
|---|---|---|---|
spark.executor.memory | 1g | Amount of memory to use per executor process, in the same format as JVM memory strings with a size unit suffix (“k”, “m”, “g” or “t”) (e.g. 512m, 2g). | 0.7.0 |
spark.executor.memoryOverhead | executorMemory * 0.10, with minimum of 384 | Amount of additional memory to be allocated per executor process, in MiB unless otherwise specified. This is memory that accounts for things like VM overheads, interned strings, other native overheads, etc. This tends to grow with the executor size (typically 6-10%). This option is currently supported on YARN and Kubernetes. Note: Additional memory includes PySpark executor memory (when spark.executor.pyspark.memory is not configured) and memory used by other non-executor processes running in the same container. The maximum memory size of container to running executor is determined by the sum of spark.executor.memoryOverhead, spark.executor.memory, spark.memory.offHeap.size and spark.executor.pyspark.memory. | 2.3.0 |
| Dynamic Allocation | Default Meaning | Since | Version |
|---|---|---|---|
spark.dynamicAllocation.enabled | false | Whether to use dynamic resource allocation, which scales the number of executors registered with this application up and down based on the workload. This requires spark.shuffle.service.enabled or spark.dynamicAllocation.shuffleTracking.enabled to be set. The following configurations are also relevant: spark.dynamicAllocation.minExecutors, spark.dynamicAllocation.maxExecutors, and spark.dynamicAllocation.initialExecutors spark.dynamicAllocation.executorAllocationRatio | 1.2.0 |
spark.dynamicAllocation.executorIdleTimeout | 60s | If dynamic allocation is enabled and an executor has been idle for more than this duration, the executor will be removed. For more detail, see this description. | 1.2.0 |
spark.dynamicAllocation.cachedExecutorIdleTimeout | infinity | If dynamic allocation is enabled and an executor which has cached data blocks has been idle for more than this duration, the executor will be removed. | 1.4.0 |
spark.dynamicAllocation.initialExecutors | spark.dynamicAllocation.minExecutors | Initial number of executors to run if dynamic allocation is enabled. If --num-executors (or spark.executor.instances) is set and larger than this value, it will be used as the initial number of executors. | 1.3.0 |
spark.dynamicAllocation.maxExecutors | infinity | Upper bound for the number of executors if dynamic allocation is enabled. | 1.2.0 |
spark.dynamicAllocation.minExecutors | 0 | Lower bound for the number of executors if dynamic allocation is enabled. | 1.2.0 |
spark.dynamicAllocation.executorAllocationRatio | 1 | By default, the dynamic allocation will request enough executors to maximize the parallelism according to the number of tasks to process. While this minimizes the latency of the job, with small tasks this setting can waste a lot of resources due to executor allocation overhead, as some executor might not even do any work. This setting allows to set a ratio that will be used to reduce the number of executors w.r.t. full parallelism. Defaults to 1.0 to give maximum parallelism. 0.5 will divide the target number of executors by 2 The target number of executors computed by the dynamicAllocation can still be overridden by the spark.dynamicAllocation.minExecutors and spark.dynamicAllocation.maxExecutors settings | 2.4.0 |
spark.dynamicAllocation.schedulerBacklogTimeout | 1s | If dynamic allocation is enabled and there have been pending tasks backlogged for more than this duration, new executors will be requested. | 1.2.0 |
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout | schedulerBacklogTimeout | Same as spark.dynamicAllocation.schedulerBacklogTimeout, but used only for subsequent executor requests. | 1.2.0 |
spark.dynamicAllocation.shuffleTracking.enabled | false | Experimental. Enables shuffle file tracking for executors, which allows dynamic allocation without the need for an external shuffle service. This option will try to keep alive executors that are storing shuffle data for active jobs. | 3.0.0 |
spark.dynamicAllocation.shuffleTracking.timeout | infinity | When shuffle tracking is enabled, controls the timeout for executors that are holding shuffle data. The default value means that Spark will rely on the shuffles being garbage collected to be able to release executors. If for some reason garbage collection is not cleaning up shuffles quickly enough, this option can be used to control when to time out executors even when they are storing shuffle data. | 3.0.0 |
以上是关于CDH之HIVE-ON-SPARKSpark配置的主要内容,如果未能解决你的问题,请参考以下文章