Linux CentOs7 监控CPU 内存 硬盘IO读写,网络负载,CPU温度等
Posted 优雅码农
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux CentOs7 监控CPU 内存 硬盘IO读写,网络负载,CPU温度等相关的知识,希望对你有一定的参考价值。
一般我们都知道TOP命令可以加载服务器的负载详情,但界面不太友好。因此用到htop
我们开发的软件服务需要在服务器上运行,所以服务器性能代表了软件的性能上限,因此服务器性能调优是个十分重要的环节,然而大部分同学对服务器性能调优关注的较少,今天从3个部分对服务器性能调优进行介绍,分别是:服务器配置选择,服务器负载分析,服务器内核参数调优。
服务器配置选择
服务器一般是由CPU、内存、磁盘和网卡组成,因此选择服务器配置就是选择CPU核数、内存大小、磁盘大小及类型、网络带宽。但是,服务器配置的选择是很难标准化的,也就是说很难推断出“一台需要达到1000TPS的后端服务器”的配置应该是什么样的。因为软件的最终运行性能与软件的实现方式是紧密相关的,即使是同一个后端应用程序中的两个接口,由于具体功能的差别,性能也会有所差别。
因此,服务器配置的选择应该基于具体的测试结果。一开始可以选用配置较低的服务器做调优和测试,并以该服务器的测试结果作为选择服务器的依据。
以一个订单业务为例,经过测试后,一台配置为4核 CPU 、16GB内存、10Mbps带宽、50GB机械磁盘的服务器的测试结果为:支持50并发量和300TPS吞吐量(增大并发量后会出现超时报错)。而在压力测试过程中, CPU 的使用率接近75%,内存使用率在 50%以下,带宽使用率在50%以下,除去日志以外无磁盘操作。
因此可以认为,一台配置为4核 CPU ( CPU 使用率需要在75%以下)、8GB内存(内存使用率可以接近100%)、 5Mbps 带宽(带宽使用率可以接近100%)的服务器,可以满足订单接口支持50并发量、300TPS吞吐量的压力。
如果需要达到200并发数、2400TPS吞吐量的目标的话,则需要8台配置为4核 CPU 、8GB内存、5Mbps带宽的服务器,或者1台配置为32核 CPU 、64GB内存、40Mbps带宽的服务器。当然,最终的服务器配置还是需要通过测试来验证。
注意:在以上订单接口的例子中,后端服务器和数据库等服务器需要一起调试,避免后端服务器性能过剩,而数据库等服务器性能不足的情况发生。另外,以上选择服务器配置的方法不一定适用于所有场景,请斟酌参考。
服务器负载分析
在性能调优时,需要先对服务器负载进行分析,通常而言,我们主要分析CPU使用率、内存使用率、磁盘I/O,服务器负载和带宽使用情况。
CPU使用率
CPU使用率反应的是CPU的忙碌情况。当CPU达到100%时,部分进程会进入等待状态,CPU暂时不会对其进行处理。在实际情况下,为了应对一下突发性的请求压力,服务器CPU使用率一般需要在75%以下。如果一台服务器的CPU使用率多次高于75%,这时候就考虑增加新的服务器。
监控CPU使用率我推荐大家使用htop工具,可以非常直观看到CPU使用率、内存使用率、及负载等信息。
使用htop查看CPU负载
首先我们需要安装htop,以centos为例,安装命令如下:
安装htop
yum install -y epel-release
yum install -y htop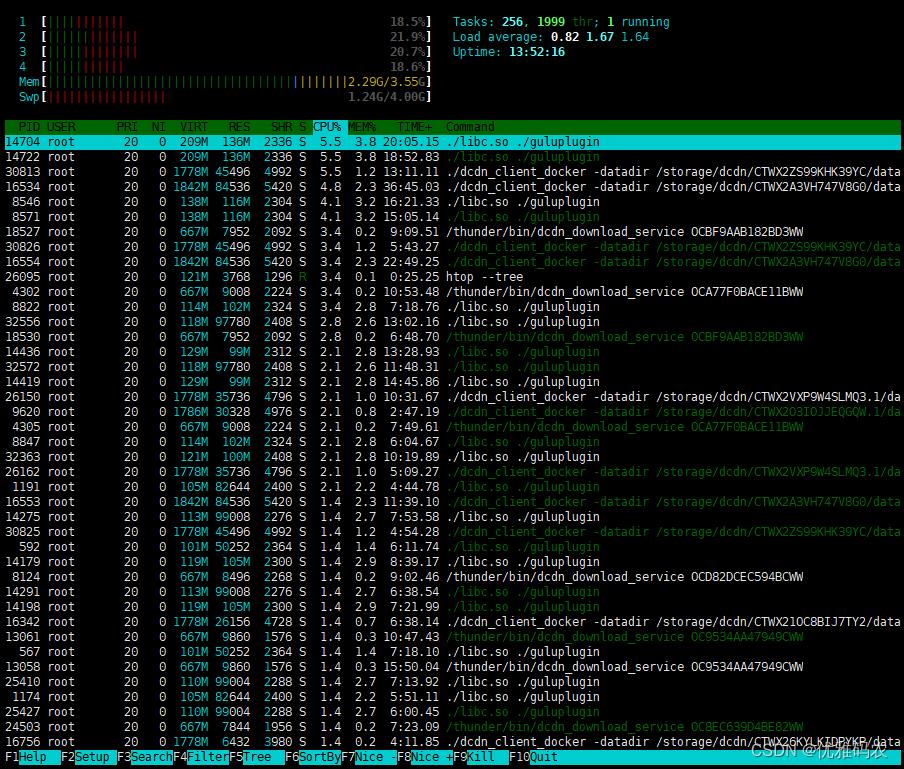
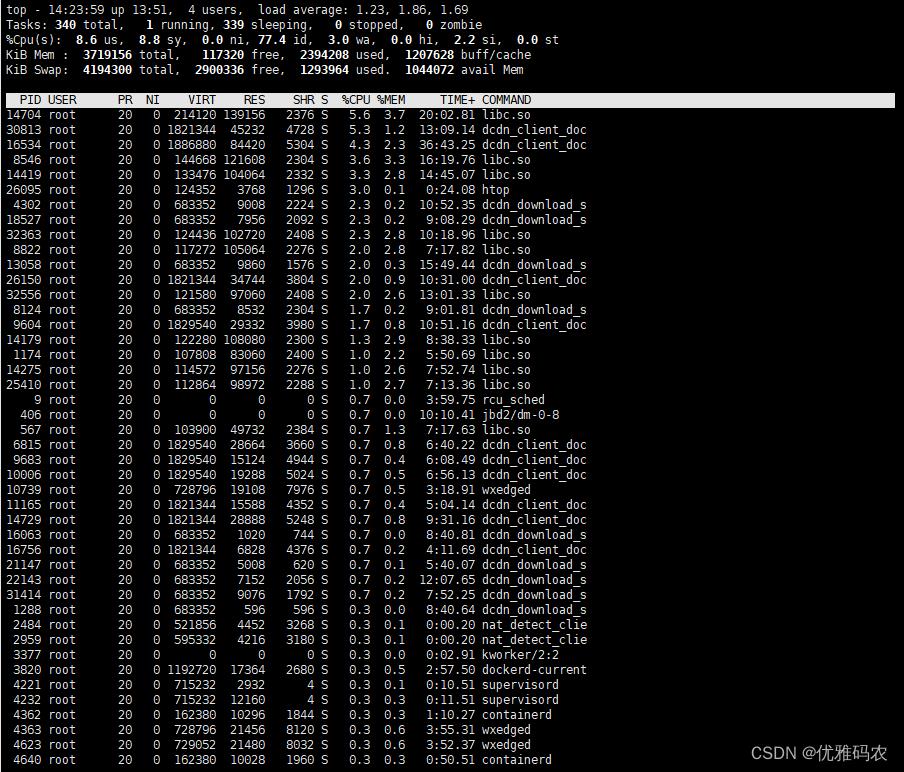
cpu负载
如上图所示,这是一个4核CPU服务器,在截图的时候其中3核CPU使用率都超过了75%,再观察一会发现所有CPU的使用率都在85%左右徘徊,说明CPU负载很高了,需要考虑增加新的服务器。
内存使用率
内存使用率反应的是内存的使用情况。内存用于存放程序的代码及数据,一般分为物理内存和虚拟内存,其中物理内存指的是服务器的内存,而虚拟内存指的是硬盘的一块空间。当物理内存使用率达到100%时将会使用虚拟内存。需要注意的是,虚拟内存的读写速度远远低于物理内存,如果程序被放在了虚拟内存执行,那么程序的执行效率会变得很低。
一般而言,服务器的物理内存应该保持在80%以下,虚拟内存使用率保持在0%。
服务器内存使用情况还是可以通过hop工具进行查看
内存使用率
上面显示了服务器的内存使用情况:总内存16G,使用了10G左右,内存使用率62%,可以继续使用,同时关闭了Swap虚拟内存。
在下MEM%栏中显示了单个进程的内存使用率。
磁盘I/O
磁盘I/O指的是磁盘的读写,在软件系统中,日志、文件操作、数据库操作都会造成磁盘读写压力,其中又以数据库操作为甚,在高并发情况下往往数据库会首先成为系统的瓶颈。
磁盘监控我推荐大家使用iostat工具,可以很方便查看磁盘的使用情况。
使用iostat查看磁盘I/O
首先我们需要安装iostat,以centos为例,安装命令如下:
yum install sysstat -y# 查看磁盘总体读写情况, 1代表每1秒读取一次数据
iostat -x 1
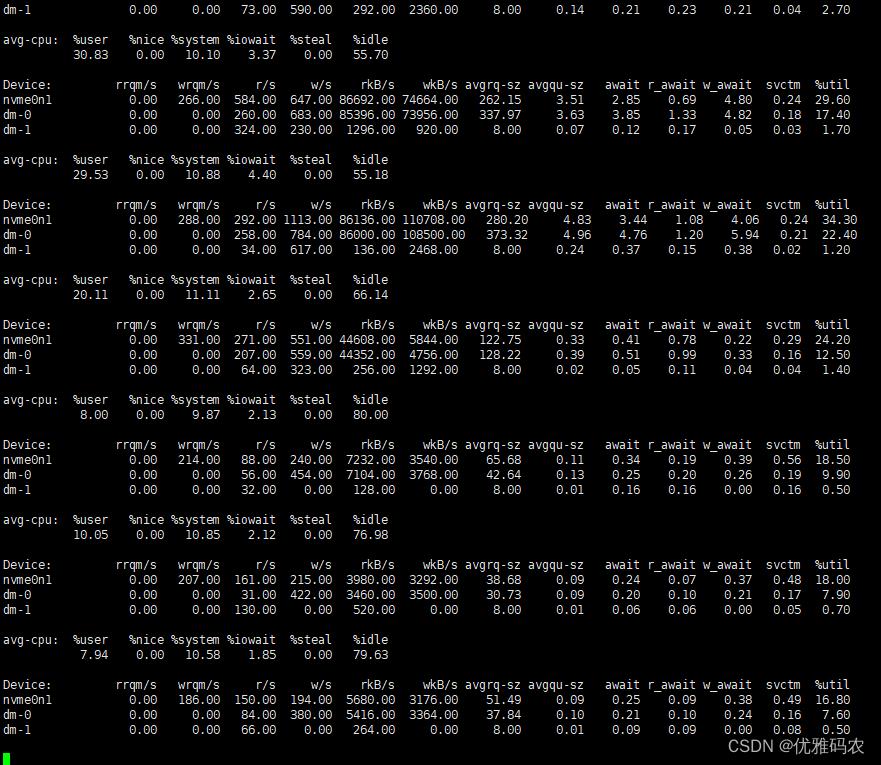
磁盘IO
输入iostat命令后,磁盘总体读写情况如上所示。磁盘负载主要关注2个指标:%idle,%util
-
%idle:表示CPU除去等待磁盘I/O以外的空闲时间百分比,这个指标应该要保证在70%以上 -
%util:该设备用于I/O操作的时间百分比,这个指标需要保证在70%以下,当到达100%时表示已经满负载。为了降低磁盘负载,可以采用性能更高的磁盘(OSD,PCIE)或者降低磁盘的操作频率(异步写、合并写)
平均负载
平均负载指的是单位时间内平均的活跃进程数,是一个表示服务器负载的指标。一般情况下需要保证平均负载的值小于当前服务器的CPU核数。
同样的,查看服务器平均负载我们也可以使用htop命令
在这里我们主要关注Load average指标,上图有3个数字,分别代表1分钟,5分钟,15分钟的平均负载。
一般情况下服务器的平均负载需要小于当前服务器的CPU核数,为了应对突发状况,服务器的平均负载应该在75%即3 以下,很显然,上图这台服务器平均负载超过了75%,需要考虑提升性能了。
网络使用情况
网络使用情况也是监控的重要指标。当带宽不足时会大大增加请求的响应时间。为了防止突发性并发压力,应该保证服务器的带宽使用率在80%以上。这里需要注意的是,物理网卡限制了服务器所能使用的最大宽带。
查看网络使用情况我推荐使用nload工具。
使用nload查看网络
首先需要安装nload,以centos为例
yum install nload -y 安装完成后我们直接运行nload
nload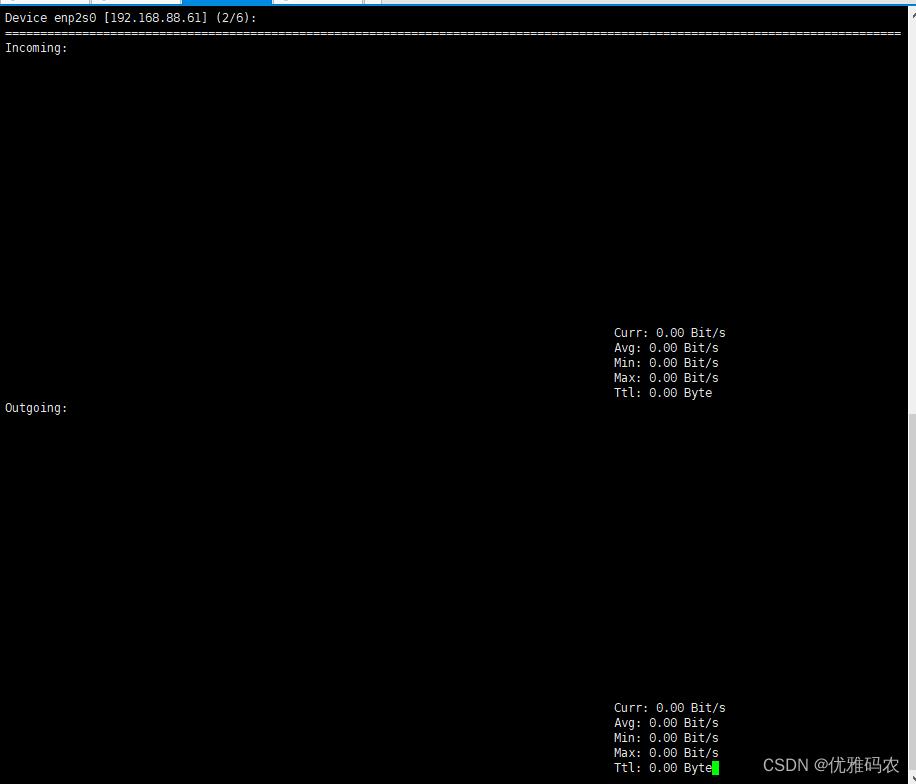
输入nload命令后,网络使用情况如上图所示。其中,网络使用情况分为流入网卡的数据与流出网卡的数据。流入网卡的对应下行带宽的网速,流出网卡的数据对应上行带宽的网速。如果 “当前网速” 持续接近 “最大网速” 时,代表带宽使用率已经接近100%。
指标说明:
- Curr:当前网速
- Avg:平均网速
- Min:最小网速
- Max:最大网速
- Ttl:总流量
如还不满意可用iftop
使用iftop命令,
CentOS系统下使用yum install iftop -y进行安装(非常好用其他的真的一般)**
iftop -P (可动态展示所有有流量的连接,包含端口解析)
-i:指定需要监测的网卡
-n:将输出的主机信息都通过IP显示,不进行DNS反向解析
-B:将输出以bytes为单位显示网卡流量,默认是bits
-p:以混杂模式运行iftop,此时iftop可以作为网络嗅探器使用
-N:只显示连接端口号,不显示端口对应的服务名称
-P:显示主机以及端口信息,这个参数非常有用
-F:显示特定网段的网卡进出流量
-m:设置iftop输出界面中最上面的流量刻度最大值,流量刻度分五个大段显示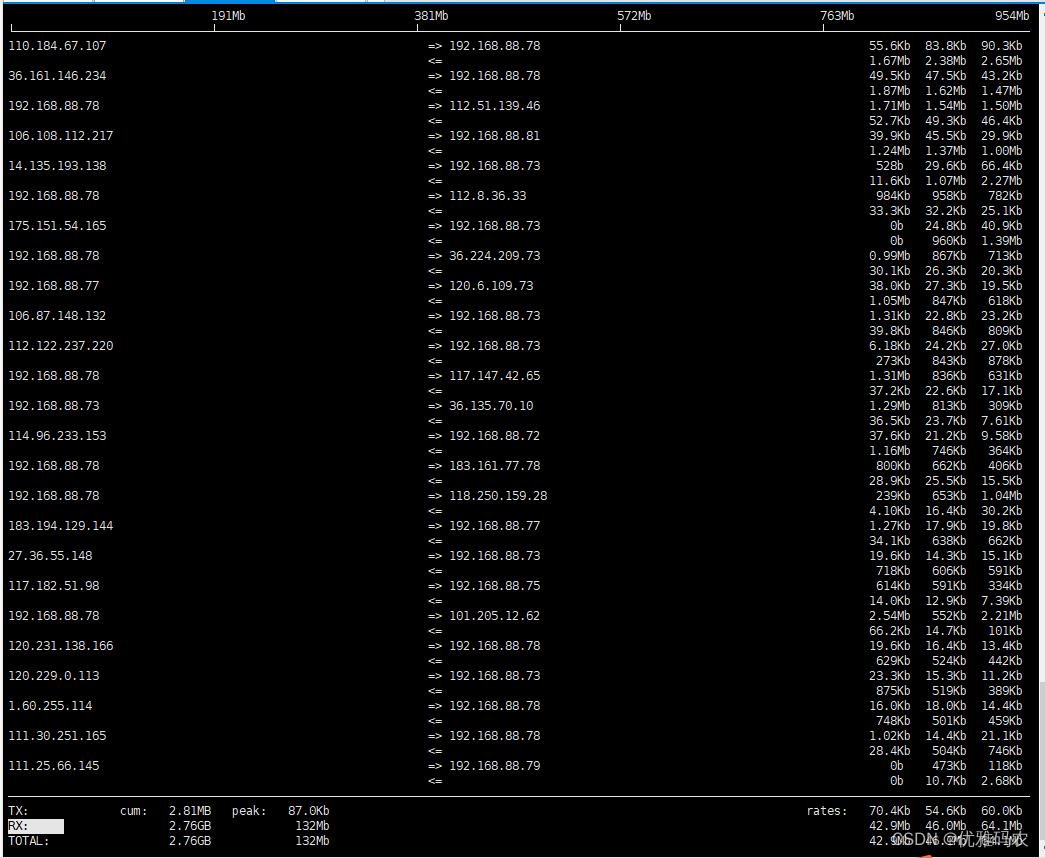
界面上面显示的是类似刻度尺的刻度范围,为显示流量图形的长条作标尺用的。
#"TX":从网卡发出的流量
#"RX":网卡接收流量
#"TOTAL":网卡发送接收总流量
#"cum":iftop开始运行到当前时间点的总流量
#"peak":网卡流量峰值
#"rates":分别表示最近2s、10s、40s 的平均流量iftop交互式参数:
参数 含义
P 暂停/继续 (Display unpaused/paused )
h 帮助/显示(help / Display)
b 平均流量刻度条开关 (Bars on/off)
B 2s、10s、40s内的平均流量 (Bars show 2s/10s/40s average)
T 显示/隐藏每个连接的总流量( show / hide cumulative totals)
j/k 上移/下滚(通vi hjkl 左上下右)
l 过滤 (screen filter > IP、主机名或端口支持模糊查询 ctrl+删除键回退)
L 对数尺度、计算尺; 直线标度、线性标尺 (logarithmic scale && linear scale)==加个进度条比例不同
q 退出(quit)
n DNS解析开关(DNS resolution off/on)主要看hosts 文件有无
s/d 显示源/目的主机信息 show/hide source/dest host
S/D 显示源/目的端口信息 port display dest/source或on
t 仅显示接收流量。received traffic only , 仅显示发送流量 sent traffic only,接收发送同时显示 two line per host 接收发送合并显示 one line per host
N 端口号及对应服务名称切换,只识别通用端口修改后不显示服务。port resolution on/off
p 全量显示/关闭端口信息 (port display off/on)
1/2/3 根据近2 秒、10 秒、40 秒的平均网络流量排序 sort by col 1/2/3
< 根据源ip/主机名排序 (sort by source)
> 根据目的地址ip或主机名排序 (sort by dest)
o 冻结当前连接显示 order frozen/unfrozenCPU温度
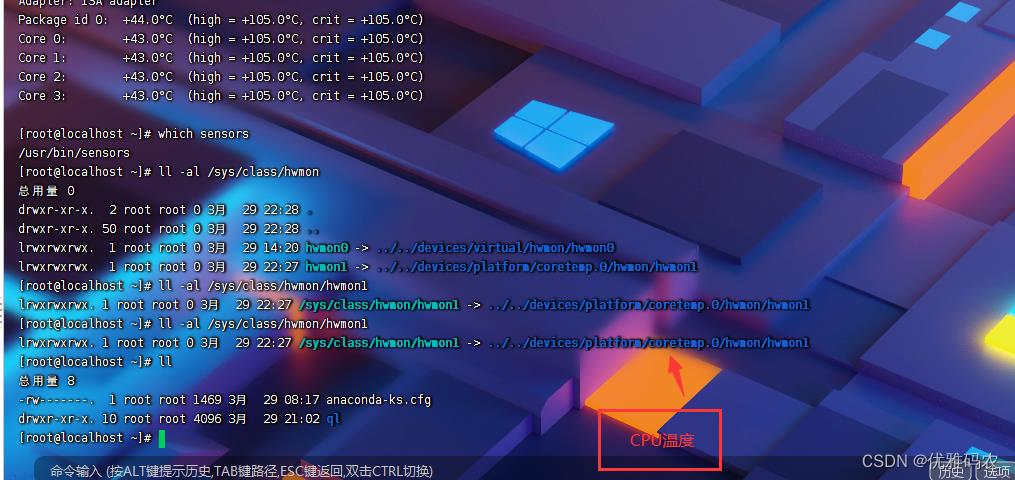
lm_sensors是一款linux的硬件监控的软件,可以帮助我们来监控主板,CPU的工作电压,风扇转速、温度等数据。这些数据我们通常在主板的 BIOS也可以看到。当我们可以在机器运行的时候通过lm_sensors随时来监测着CPU的温度变化,可以预防和保护因为CPU过热而会烧掉。
三、sensors命令安装及使用
1、yum安装lm_sensors
yum install -y lm_sensors
2、查看sensors版本
[root@s146 opt]# sensors -v
sensors version 3.4.0 with libsensors version 3.4.0
3、传感器探测
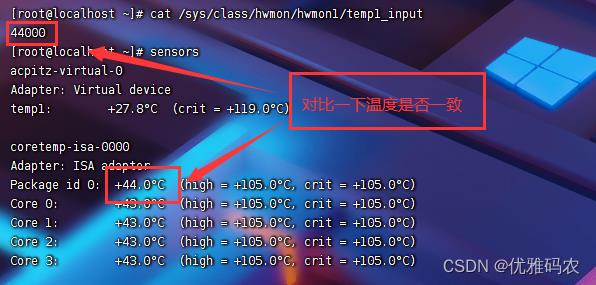
五、QA
1、虚拟机执行sensors命令报错No sensors found!

报错原因:因为找不到传感器
解决方案:可以使用sensors-detect命令探测,如果是虚拟机不存在直接连接传感器,无法查看温度信息。
2、kmod-coretemp安装
关于kmod-coretemp的安全要求,实际上如果是centos7,我们并不需要安装此模块,因为操作系统已经安装了kmod-20-28.el7.x86_64、kmod-libs-20-23.el7.x86_64。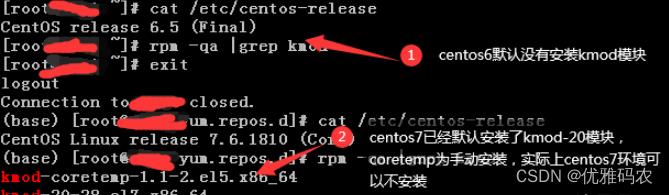
#centos6安装kmod-coretemp软件包
#wget http://www.pperry.f2s.com/linux/coretemp/kmod-coretemp-1.1-2.el5.x86_64.rpm
#rpm -ivh kmod-coretemp-1.1-2.el5.x86_64.rpm
服务器内核参数调优
光有强大的物理性能是不够的,还需要对内核参数进行调优,这样才能在高并发压力下充分体现服务器应有的性能。当然,并不是所有的服务器都需要做高并发性能调优,一般来说,只需要对要处理高并发请求的服务器进行内核参数调优即可,常见的包括:前端服务器,后端服务器,数据库服务器。
服务器常见的调优参数主要有两个:单个进程最大打开文件数 和 TCP相关设置。
单个进程最大打开文件数
修改单个文件最大打开文件数,只需要编辑/etc/security/limits.conf文件,在文件末尾加上以下四句
* soft nofile 65535
* hard nofile 65535
* soft nproc 65535
* hard nproc 65535 其中* 代表所有用户,65536代表修改的值,重启后生效。
TCP相关设置
修改TCP相关参数,可以优化TCP高并发通信,编辑/etc/sysctl.conf文件,添加以下内容
# 为防止洪水,高并发系统需要将此项关闭
net.ipv4.tcp_syncookies = 0
# 开启TCP连接重用,允许处理TIME-WAIT状态的连接重新用于新的TCP连接
net.ipv4.tcp_tw_reuse = 1
# 开启快速回收TCP连接中处于TIME-WAIT状态的连接
net.ipv4.tcp_tw_recycle = 1
#修改超时时间( s ),该值表示如果连接由本端关闭,则连接处于 FIN-WAIT-2状态的时间为
net.ipv4.tcp_fin_timeout = 30
#当 keepalive(长连接)启用的时候,TCP发送 keepalive 消息(探测包)的时间间隔( s ),默认为2个小时
net.ipv4.tcp_keepalive_time =1200
#服务器对外连接的端口范围,影响该服务器与其他服务器的连接数
net.ipv4.ip_local_port_range =102465535
#SYN队列的长度,可以容纳更多等待连接的网络连接数,默认为1024
net.ipv4.tcp_max_syn_backlog = 65535
#保持 TIME_WAIT 状态连接的最大数量,如果超过此值,TIME_WAIT 将立刻被清除并打印警告信息,默认为180000
net.ipv4.tcp_max_tw_buckets =5000
#每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目
net.core.netdev_max_backlog =65535
# TCP最大连接数
net.core.somaxconn = 65535
#预留用于接收缓冲的内存默认值(字节)
net.core.rmem_default = 8388608
#预留用于接收缓冲的内存最大值(字节)
net.core.rmem_max = 16777216
#预留用于发送缓冲的内存默认值(字节)
net.core.wmem_default = 8388608
#预留用于发送缓冲的内存最大值(字节)
net.core.wmem_maX = 16777216
#避免时间戳异常
net.ipv4.tcp_timestamps = 0
#系统中最多有多少个 TCP 套接字不被关联到任何一个用户文件句柄上,如果超过这个数字,连接将即刻被复位并打印警告信息,这个限制仅仅是为了防止简单的DoS 攻击
net.ipv4.tcp_max_orphans =3276800Linux系统命令与CPU硬盘内存网络状态监控
1. Linux常用工具命令:
Linux系统中需要关注的指标包括CPU、硬盘、内存、网络状态这四个模块。
常用于“监控”的Linux系统命令包括:
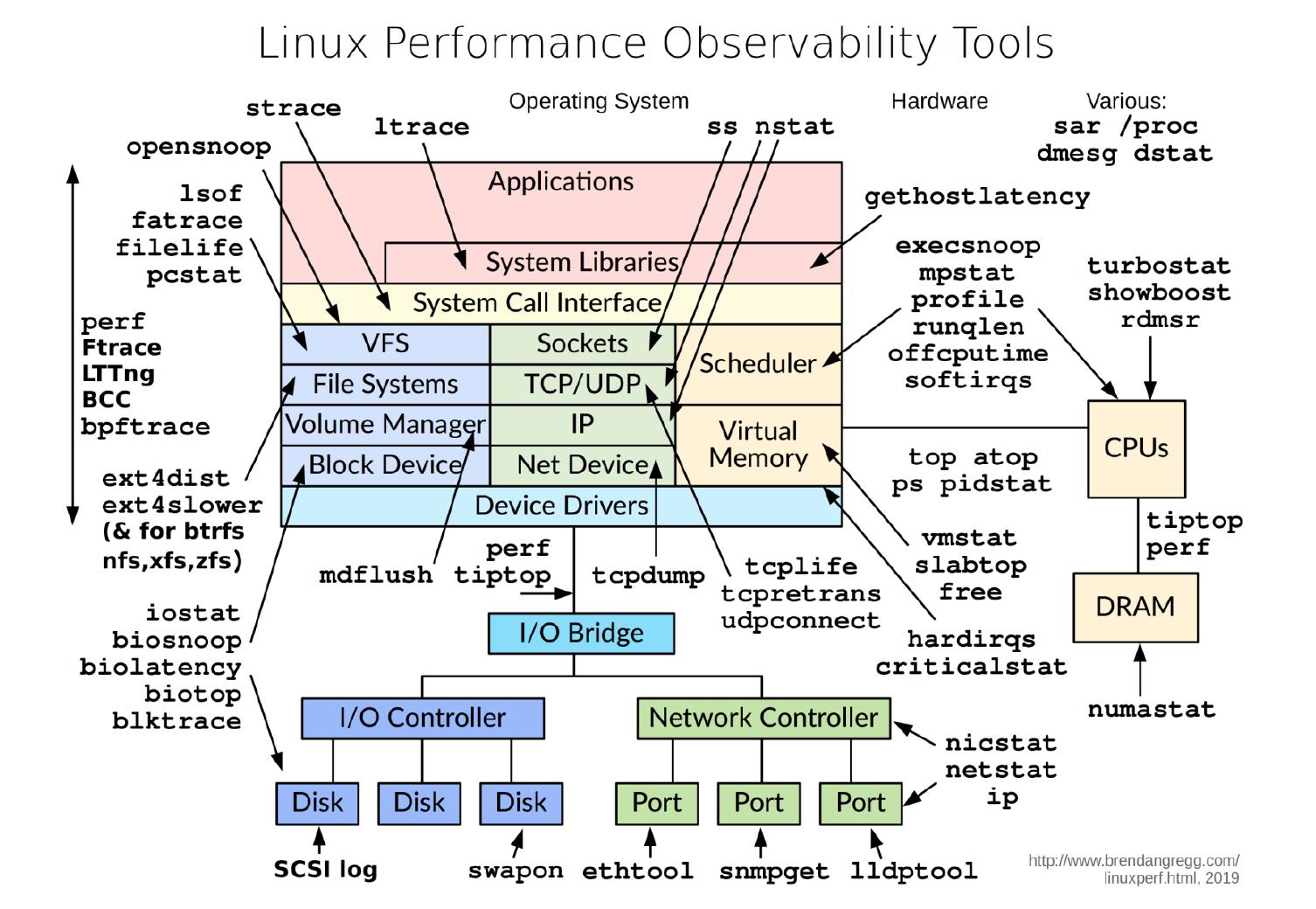
常用于“性能测试”的Linux系统命令包括:
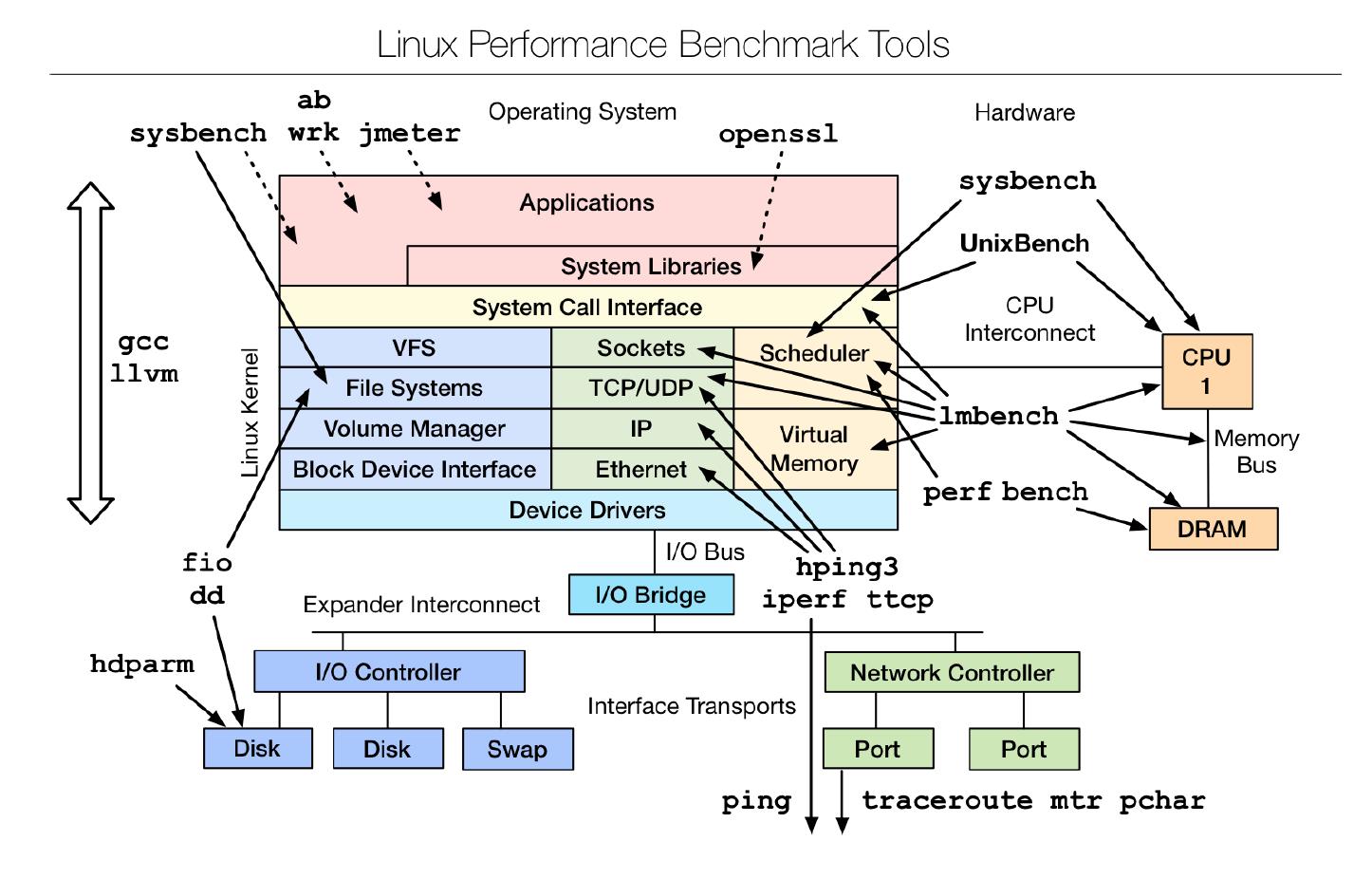
常用于“优化”的Linux系统命令包括:
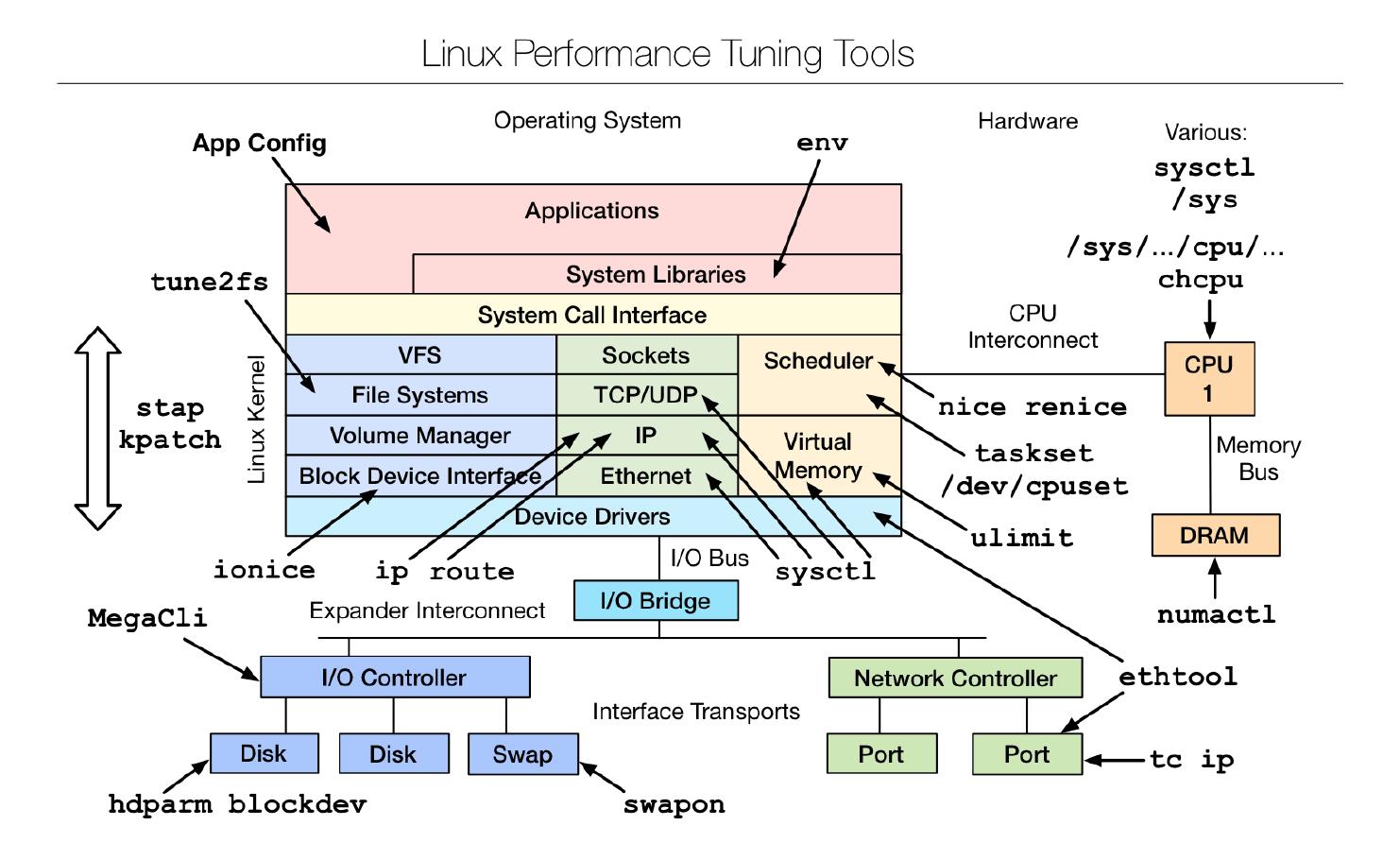
2. 基础命令和工具:
2.1 uptime:机器启动时间+负载
root@virtual-machine:/# uptime
16:19:47 up 4 days, 5:30, 2 users, load average: 1.30, 1.34, 1.34
通常用于在线上应急或者技术攻关中,确定操作系统的重启时间。
2.2 ulimit:用户资源
Linux系统对每个登录用户都限制其最大进程数和打开的最大文件句柄数。可根据实际的需求进行设置,使用 ulimit -a 来显示当前系统对用户的各项使用资源的限制。
root@virtual-machine:/# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 15394
max locked memory (kbytes, -l) 65536
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 15394
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
2.3 curl http:HTTP返回结果
curl命令用于查看HTTP调用返回的结果是否符合预期。
curl -i "http://www.sina.com" # 打印请求响应头信息
curl -I "http://www.sina.com" # 仅返回http头
curl -v "http://www.sina.com" # 打印更多的调试信息
curl -verbose "http://www.sina.com" # 打印更多的调试信息
curl -d 'abc=def' "http://www.sina.com" # 使⽤post⽅法提交http请求
curl -sw '%{http_code}' "http://www.sina.com" # 打印http响应码
例如:
root@virtual-machine:/# curl -I www.baidu.com
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Connection: keep-alive
Content-Length: 277
Content-Type: text/html
Date: Thu, 07 Oct 2021 08:28:21 GMT
Etag: "575e1f72-115"
Last-Modified: Mon, 13 Jun 2016 02:50:26 GMT
Pragma: no-cache
Server: bfe/1.0.8.18
3. 关于进程的命令:
3.1 ps:进程信息
ps -ef 查看系统内所有进程,使用 grep进行过滤:
root@virtual-machine:/# ps -ef | grep redis
xuesong 6573 1379 0 10月03 ? 00:10:52 ./redis-server 127.0.0.1:6379
root 309595 308064 0 16:33 pts/4 00:00:00 grep --color=auto redis
使用 grep -v 反向过滤,忽略某些不想看到的内容:
root@virtual-machine:/# ps -ef | grep redis | grep -v grep
xuesong 6573 1379 0 10月03 ? 00:10:52 ./redis-server 127.0.0.1:6379
3.2 top:进程CPU内存信息
top命令用于查看活动进程的CPU和内存信息,能够实时显示系统中各个进程的资源占用情况,可以按照CPU、内存的使用情况和执行时间对进程进行排序。
top - 17:04:13 up 4 days, 5:58, 2 users, load average: 1.17, 1.33, 1.39
任务: 360 total, 3 running, 356 sleeping, 1 stopped, 0 zombie
%Cpu(s): 40.3 us, 11.2 sy, 0.0 ni, 48.2 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
MiB Mem : 3906.4 total, 122.4 free, 3107.5 used, 676.5 buff/cache
MiB Swap: 923.3 total, 0.0 free, 923.3 used. 505.3 avail Mem
进程号 USER PR NI VIRT RES SHR %CPU %MEM TIME+ COMMAND
303054 root 20 0 78648 21620 176 R 99.7 0.5 167:38.28 gdb
307836 root 20 0 0 0 0 I 0.7 0.0 0:03.51 kworker/1:4-events
10 root 20 0 0 0 0 S 0.3 0.0 0:13.30 ksoftirqd/0
6573 xuesong 20 0 60588 1552 948 S 0.3 0.0 10:53.75 redis-server
7715 root 20 0 84696 276 0 S 0.3 0.0 2:32.02 file_server
7763 root 20 0 85108 892 556 S 0.3 0.0 3:34.93 http_msg_server
7785 root 20 0 644128 44592 896 S 0.3 1.1 28:36.37 db_proxy_server
45195 root 20 0 972708 4896 0 S 0.3 0.1 10:03.11 containerd
245808 xuesong 20 0 2452252 34200 10200 S 0.3 0.9 0:28.57 WebExtensions
309588 root 20 0 0 0 0 I 0.3 0.0 0:00.71 kworker/0:2-events
309875 root 20 0 20792 3896 3128 R 0.3 0.1 0:01.75 top
1 root 20 0 171580 7808 3704 S 0.0 0.2 1:29.20 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.58 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.01 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
top命令参数详解参考:
https://blog.csdn.net/yjclsx/article/details/81508455
3.3 pidstat:进程资源:
pidstat 用于监控全部或指定进程占用系统资源的情况,包括CPU、内存、磁盘I/O、线程切换、线程数等数据。
命令参数:
-u: 查看cpu相关的性能指标
-r: 查看内存使用信息
-d: 查看磁盘I/O统计数据
-p: 指明进程号
例如:
//第一步先使用ps命令查看redis的进程号:
root@virtual-machine:/home/xuesong# ps -ef | grep redis | grep -v grep
xuesong 6573 1379 0 10月03 ? 00:10:54 ./redis-server 127.0.0.1:6379
//第二步根据进程号6573查看进程的CPU、内存、磁盘的占用信息:
root@virtual-machine:/# pidstat -urd -p 6573
Linux 5.8.0-53-generic (xuesong-virtual-machine) 2021年10月07日 _x86_64_ (2 CPU)
17时12分48秒 UID PID %usr %system %guest %wait %CPU CPU Command
17时12分48秒 1000 6573 0.08 0.10 0.00 0.05 0.18 0 redis-server
17时12分48秒 UID PID minflt/s majflt/s VSZ RSS %MEM Command
17时12分48秒 1000 6573 11.19 0.01 60588 1512 0.04 redis-server
17时12分48秒 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
17时12分48秒 1000 6573 1.56 0.00 0.00 447 redis-server
CPU信息:
%usr:用户层正在使用的CPU百分比;
%system: 系统层正在使用的CPU百分比;
%CPU:进程整个占用的CPU时间百分比(%usr+%system)
CPU:处理器个数
%guest:运行虚拟机的CPU占用百分比。
对于“计算密集型”的应用,正常情况下应该占用更多的 %usr;
对于“IO密集型”的应用,正常情况下应该占用更多的 %system。
所以,如果你的应用程序是IO密集型的,比如是处理网络IO的程序,但是却 %usr过高导致cpu过高,那么这个时候需要关注一下是不是应用程序写的有问题。
内存信息:
VSZ:该线程使用的虚拟内存(以KB为单位);
RSS:该线程使用的物理内存(以KB为单位);
%MEM:当前任务使用的有效内存的百分比;
磁盘信息:
kB_rd/s:每秒此进程从磁盘读取的字节数(kB/s);
kB_wr/s:每秒此进程已经或者将要写入磁盘的字节数(kB/s)
kB_ccwr/s:由任务取消的写入磁盘的字节数(kB/s)。
4. 关于内存的命令:
4.1 free:内存
free命令用于显示系统内存的使用情况,包括总体内存、已经使用的内存;还可用于显示系统内核使用的缓冲区,包括缓冲(buffer)和缓存(cache)等。
root@virtual-machine:/# free
总计 已用 空闲 共享 缓冲/缓存 可用
内存: 4000136 3200592 126500 41356 673044 500884
交换: 945464 945464 0
5. 关于CPU使用情况的命令:
5.1 vmstat:
vmstat命令用于显示关于内核线程、虚拟内存、磁盘I/O、陷阱和CPU占用率的统计信息。
root@virtual-machine:/# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b 交换 空闲 缓冲 缓存 si so bi bo in cs us sy id wa st
1 0 945464 122688 13800 659896 1 3 133 65 5 20 3 2 95 0 0
cs: 表示线程环境的切换次数,此数据如果太大时表明线程的同步机制有问题;(图中cs值为20)
si和so较大时,说明系统频繁使用交换区,应该查看操作系统的内存是否够用
6. 关于磁盘I/O的监控命令:
6.1 iostat:IO状态
iostat命令用于监控CPU占用率、平均负载值和I/O读写速度等。
root@virtual-machine:/# iostat
Linux 5.8.0-53-generic (virtual-machine) 2021年10月07日 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
3.30 0.09 1.81 0.04 0.00 94.75
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
loop0 0.02 0.55 0.00 0.00 204205 0 0
loop1 0.01 0.03 0.00 0.00 10397 0 0
loop10 0.00 0.01 0.00 0.00 3264 0 0
loop11 0.22 13.99 0.00 0.00 5177743 0 0
loop12 0.00 0.01 0.00 0.00 4109 0 0
loop13 0.00 0.05 0.00 0.00 17772 0 0
loop14 0.00 0.01 0.00 0.00 3933 0 0
loop15 0.00 0.01 0.00 0.00 3248 0 0
loop16 0.00 0.01 0.00 0.00 2415 0 0
loop17 0.00 0.00 0.00 0.00 1203 0 0
loop18 0.00 0.00 0.00 0.00 14 0 0
loop2 0.01 0.03 0.00 0.00 12149 0 0
loop3 0.01 0.18 0.00 0.00 66360 0 0
loop4 0.03 0.62 0.00 0.00 227688 0 0
loop5 0.00 0.01 0.00 0.00 3668 0 0
loop6 0.04 0.35 0.00 0.00 129844 0 0
loop7 0.00 0.15 0.00 0.00 55638 0 0
loop8 0.02 0.04 0.00 0.00 13506 0 0
loop9 0.03 1.21 0.00 0.00 448455 0 0
sda 7.09 247.27 129.15 0.00 91507211 47796127 0
scd0 0.00 0.00 0.00 0.00 4 0 0
//cpu的统计信息:(如果是多cpu系统,显示的所有cpu的平均统计信息)
%user: ⽤户进程消耗cpu的⽐例
%nice: ⽤户进程优先级调整消耗的cpu⽐例
%sys: 系统内核消耗的cpu⽐例
%iowait: 等待磁盘io所消耗的cpu⽐例
%idle: 闲置cpu的⽐例(不包括等待磁盘I/O)
//磁盘的统计参数:
tps: 该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。"⼀次传输"意思是"⼀次I/O请求"。多个逻辑请求可能会被合并为"⼀次I/O请求"。"⼀次传输"请求的⼤⼩是未知的。
kB_read/s: 每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s: 每秒向设备(drive expressed)写⼊的数据量;
kB_read: 读取的总数据量;
kB_wrtn: 写⼊的总数量数据量;这些单位都为Kilobytes
5.2 df:硬盘使用情况:
df命令用于查看文件系统的硬盘挂载点和空间使用情况。
root@virtual-machine:/# df
文件系统 1K-块 已用 可用 已用% 挂载点
udev 1970520 0 1970520 0% /dev
tmpfs 400016 3624 396392 1% /run
/dev/sda2 19993200 14781992 4172568 78% /
tmpfs 2000068 0 2000068 0% /dev/shm
tmpfs 5120 4 5116 1% /run/lock
tmpfs 2000068 0 2000068 0% /sys/fs/cgroup
/dev/loop1 224256 224256 0 100% /snap/gnome-3-34-1804/66
/dev/loop4 224256 224256 0 100% /snap/gnome-3-34-1804/72
/dev/loop6 52224 52224 0 100% /snap/snap-store/547
/dev/loop5 52352 52352 0 100% /snap/snap-store/518
/dev/loop8 66688 66688 0 100% /snap/gtk-common-themes/1515
/dev/sda1 523248 8036 515212 2% /boot/efi
tmpfs 400012 120 399892 1% /run/user/1000
/dev/loop10 56832 56832 0 100% /snap/core18/2074
/dev/loop12 56832 56832 0 100% /snap/core18/2128
/dev/loop16 101760 101760 0 100% /snap/core/11606
/dev/loop9 33152 33152 0 100% /snap/snapd/12883
/dev/loop0 213504 213504 0 100% /snap/code/74
/dev/loop13 33152 33152 0 100% /snap/snapd/13170
/dev/loop17 101760 101760 0 100% /snap/core/11743
/dev/loop11 128 128 0 100% /snap/bare/5
/dev/loop14 213504 213504 0 100% /snap/code/75
/dev/loop15 66816 66816 0 100% /snap/gtk-common-themes/1519
7. 查看网络信息和网络监控的命令:
7.1 ifconfig:网卡信息
ifconfig命令用于查看机器挂载的网卡情况。
其中lo是本地回绕。
root@virtual-machine:/# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:29ff:fe65:1c1a prefixlen 64 scopeid 0x20<link>
ether 02:42:29:65:1c:1a txqueuelen 0 (以太网)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 10 bytes 1104 (1.1 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.5X.139 netmask 255.255.255.0 broadcast 172.16.5X.255
inet6 fe80::8798:75a4:862d:d083 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:3b:d5:f0 txqueuelen 1000 (以太网)
RX packets 2192604 bytes 2726506782 (2.7 GB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 653905 bytes 83491630 (83.4 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (本地环回)
RX packets 5533524 bytes 508807570 (508.8 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5533524 bytes 508807570 (508.8 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
7.2 ping:检查网络连接
ping命令是用检测网络故障的常用命令,可以用来测试一台主机到另外一台主机的网络是否连通。
7.3 telnet:远程登录:
telnet 是TCP/IP协议族的一员,是网络远程登录服务器的标准协议,帮助用户在本地计算机上连接远程主机。
telnet与ssh的区别:
本质区别:telnet是明文传输,ssh是加密传输;
端口区别:telnet使用端口 23,ssh使用端口 22。
7.4 netstat:网络连接端口信息:
netstat命令用于显示网络连接、端口信息等。
主要能查看到的信息包括: ① 端口状态(TCP的11个状态)、② 某条连接上的本端和对端的IP/端口信息、③ 某条连接上的发送队列/接收队列中的缓存报文信息(Recv-Q/Send-Q)。
常用参数:
`-t`: tcp
`-u`: udp
`-l`: listening //监听态
`-a`: all //所有的
`-n`: numeric //不要显示主机名,而是显示IP地址
`-c`: continuous //动态刷新,一秒一次
`-p`: program //显示占用端口的主机程序名,如redis
netstat -a:显示所有:
注意其中显示的是localhost主机名,使用-n则可以转为IP地址127.0.0.1。
root@virtual-machine:/# netstat -a
激活Internet连接 (服务器和已建立连接的)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:8700 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:microsoft-ds 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8000 0.0.0.0:* LISTEN
tcp 0 0 localhost:33060 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8100 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:10600 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8200 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8008 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:netbios-ssn 0.0.0.0:* LISTEN
tcp 0 0 localhost:6379 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:http 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8400 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:http-alt 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:tproxy 0.0.0.0:* LISTEN
tcp 0 0 localhost:domain 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN
tcp 0 0 localhost:ipp 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8600 0.0.0.0:* LISTEN
tcp 0 0 localhost:8601 0.0.0.0:* LISTEN
tcp 0 0 localhost:55934 localhost:mysql ESTABLISHED
tcp 0 0 localhost:36074 localhost:6379 ESTABLISHED
tcp 0 0 localhost:36072 localhost:6379 ESTABLISHED
tcp 0 0 localhost:55928 localhost:mysql ESTABLISHED
tcp 0 0 localhost:10600 localhost:59514 ESTABLISHED
tcp 0 0 localhost:59536 localhost:10600 ESTABLISHED
tcp 0 0 localhost:36060 localhost:6379 ESTABLISHED
使用方法:
- 根据进程ID或应用程序名称查找端口:
注意:此时必须使用参数-p,否则不显示进程ID或者程序名,也就无法使用grep进行过滤了
root@xuesong-virtual-machine:/# netstat -anp | grep redis
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36062 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36066 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36060 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36058 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36076 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36074 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36072 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36064 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36068 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36070 ESTABLISHED 6573/./redis-server
//或者:
root@xuesong-virtual-machine:/# netstat -anp | grep 6573
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36062 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36066 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36060 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36058 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36076 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36074 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36072 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36064 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36068 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36070 ESTABLISHED 6573/./redis-server
- 想要看看某个端口被哪个进程所占用,或者想要查看某个端口的当前TCP状态,使用netstat按照端口号进行过滤:
root@xuesong-virtual-machine:/# netstat -antp | grep 6379
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 6573/./redis-server
tcp 0 0 127.0.0.1:36074 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36072 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36060 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36062 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36068 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:6379 127.0.0.1:36062 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36066 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36060 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:36066 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:6379 127.0.0.1:36058 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36076 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:36070 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36064 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36058 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36076 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:6379 127.0.0.1:36074 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36072 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36064 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36068 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36070 ESTABLISHED 6573/./redis-server
-p是一个很有用的参数,可以查看到对应某个端口的应用程序名称及进程ID。
7.5 tcpdump:网络抓包
tcpdump是网络状况分析和跟踪工具,是可以用来抓包的使用命令。以上是关于Linux CentOs7 监控CPU 内存 硬盘IO读写,网络负载,CPU温度等的主要内容,如果未能解决你的问题,请参考以下文章
如何使用PHP实时监控Linux服务器的cpu,内存,硬盘信息
Linux shell 脚本监控cpu,内存,硬盘,网络,是否存活
[转帖]linux下CPU内存IO网络的压力测试,硬盘读写速度测试,Linux三个系统资源监控工具