Python-mne库使用教程
Posted 一拳十个锵锵怪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python-mne库使用教程相关的知识,希望对你有一定的参考价值。
一.读取数据
mne库支持多种数据格式的读取,这里我来写一点我的样例。一个是从csv读取数据,一个是读取EDF(信息较为多)里的数据。
1.从csv读取数据
csv读取的话只有电压值很多信息是没有的。
#因为数据为22导,将取出的数据放入列表,因为mne的raw需要这个格式
for j in range(1,23):
data = pd.read_csv(data_path, usecols=[str(j)])
list1 = data.values.tolist()
final_list = list(chain.from_iterable(list1))
data1.append(final_list)
#需要与电极名相匹配的名字,我这里使用的是与 standard_1020相匹配的名字
ch_names = ['Fz', 'FC3', 'FC1', 'FCz', 'FC2', 'FC4', 'C5', 'C3', 'C1', 'Cz', 'C2', 'C4', 'C6', 'CP3', 'CP1', 'CPz','CP2', 'CP4', 'P1', 'Pz', 'P2', 'POz']
#电极类型源代码可找支持的数据(这个不填写也有默认值,因为我们是只读数据所以需要根据电极信息 自行设置)
ch_types = ['eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg','eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg']
#采样频率
sfreq = 100 # Hz
#组成info
info = mne.create_info(ch_names, sfreq, ch_types)
#组成原始数据
raw = mne.io.RawArray(data1, info)
#电极信息
montage = mne.channels.make_standard_montage("standard_1020")
raw.set_montage(montage)
2.从EDF读取数据
EDF里保存的信息较多
#直接读取EDF文件
raw = mne.io.read_raw_edf(r"C:\\Users\\Administrator\\PycharmProjects\\EEG\\0000249.EDF")
#需要一个电极名
ch_names=['Fp1' 'Fp2' 'F7' 'F3' 'Fz' 'F4' 'F8' 'T7' 'C3' 'Cz' 'C4' 'T8' 'P7' 'P3''Pz' 'P4' 'P8' 'O1' 'O2']
#电极信息,有俩种用法一个是导入自己的电极图,一个是引用官方的图
locs_info_path = "Standard-10-20-Cap19.locs"
montage = mne.channels.read_custom_montage(locs_info_path)
#这里根据读取的电极名字要和edf读取的电极名一致,否则需要修改(而且因为给的edf只有18导因此,生成的也就18导的电极了)
montage = mne.channels.read_custom_montage(locs_info_path)
new_chan_names = np.loadtxt(locs_info_path,dtype=str,usecols=3)
old_chan_names = raw.info["ch_names"]
chan_names_dict = old_chan_names[i]:new_chan_names[i] for i in range(18)
#更新数据的电极名字(不是标准名无法运行)
raw.rename_channels(chan_names_dict)
#输入电极位置信息
raw.set_montage(montage)
这个可以用来修改你的电极类型
#用来修改电极类型(对于已经存在的类型我们需要这么修改)
chan_types_dict = 'P8':"eog",'O1':"eog"
raw.set_channel_types(chan_types_dict)当然mne库也可以使用更多的读取方式,这是在Python 脑电数据处理中文手册所写的其他读取方式。
# MNE-Python中对多种格式的脑电数据都进⾏了⽀持:
# *** 如数据后缀为.set (来⾃EEGLAB的数据)
# 使⽤mne.io.read_raw_eeglab()
# *** 如数据后缀为.vhdr (BrainVision系统)
# 使⽤mne.io.read_raw_brainvision()
# *** 如数据后缀为.edf
# 使⽤mne.io.read_raw_edf()
# *** 如数据后缀为.bdf (Biosemi放⼤器)
# 使⽤mne.io.read_raw_bdf()
# *** 如数据后缀为.gdf
# 使⽤mne.io.read_raw_gdf()
# *** 如数据后缀为.cnt (Neuroscan系统)
# 使⽤mne.io.read_raw_cnt()
# *** 如数据后缀为.egi或.mff
# 使⽤mne.io.read_raw_egi()
# *** 如数据后缀为.data
# 使⽤mne.io.read_raw_nicolet()
# *** 如数据后缀为.nxe (Nexstim eXimia系统)
# 使⽤mne.io.read_raw_eximia()
# *** 如数据后缀为.lay或.dat (Persyst系统)
# 使⽤mne.io.read_raw_persyst()
# *** 如数据后缀为.eeg (Nihon Kohden系统)
# 使⽤mne.io.read_raw_nihon()二.可视化数据
这里我介绍几个常用的函数
1.查看信息
#观察数据信息
print(raw.info) 
2.原始数据波形图
#生成的原始数据波形图
raw.plot(duration=5, n_channels=32, clipping=None)
plt.show()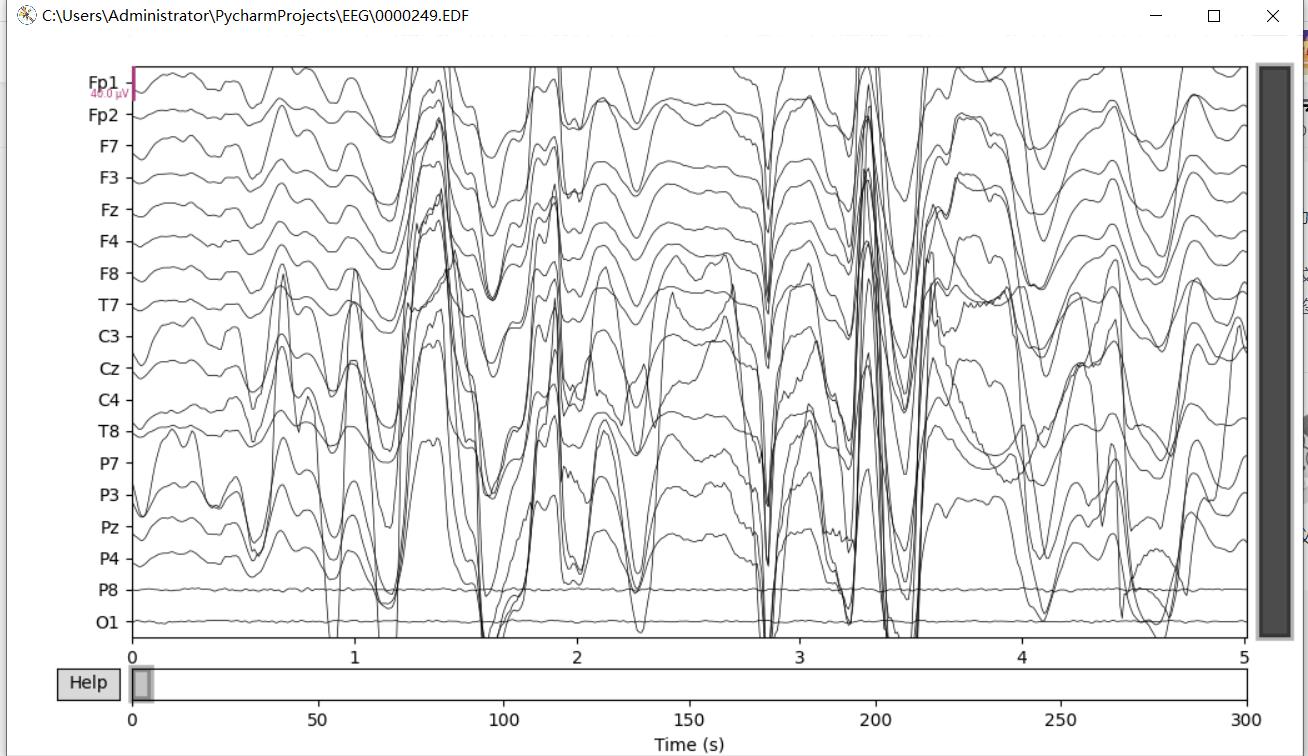
3.原始数据功率谱图
#原始数据功率谱图(如果有多种类型的channel_type有个图)
raw.plot_psd(average=True)
plt.show()

4.电极位置图
#电极位置图
raw.plot_sensors(ch_type='eeg', show_names=True)
plt.show()
5.原始数据拓扑图
#原始数据拓扑图
raw.plot_psd_topo()
plt.show()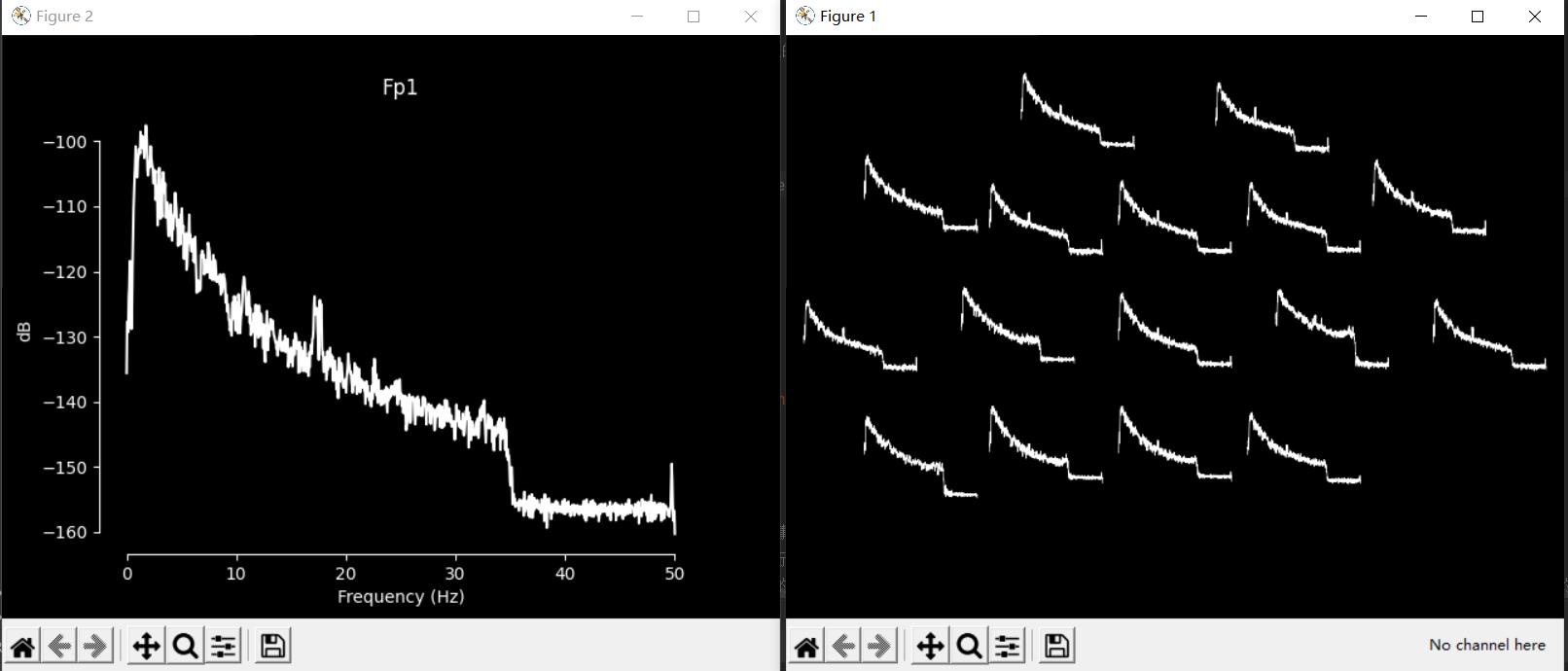
三.滤波
1.环境滤波
#陷波滤波
raw = raw.notch_filter(freqs=(60))
Setting up band-stop filter from 59 - 61 Hz
FIR filter parameters
---------------------
Designing a one-pass, zero-phase, non-causal bandstop filter:
- Windowed time-domain design (firwin) method
- Hamming window with 0.0194 passband ripple and 53 dB stopband attenuation
- Lower passband edge: 59.35
- Lower transition bandwidth: 0.50 Hz (-6 dB cutoff frequency: 59.10 Hz)
- Upper passband edge: 60.65 Hz
- Upper transition bandwidth: 0.50 Hz (-6 dB cutoff frequency: 60.90 Hz)
- Filter length: 845 samples (6.602 sec)2.高低通滤波
预处理步骤中,通常需要对数据进⾏⾼通滤波操作 此处采⽤最常规的滤波操作,进⾏30Hz的低通滤波及0.1Hz的⾼通滤波 ⾼通滤波为了消除电压漂移,低通滤波为了消除⾼频噪⾳raw = raw.filter(l_freq=0.1, h_freq=30)
Filtering raw data in 1 contiguous segment
Setting up band-pass filter from 0.1 - 30 Hz
FIR filter parameters
---------------------
Designing a one-pass, zero-phase, non-causal bandpass filter:
- Windowed time-domain design (firwin) method
- Hamming window with 0.0194 passband ripple and 53 dB stopband attenuation
- Lower passband edge: 0.10
- Lower transition bandwidth: 0.10 Hz (-6 dB cutoff frequency: 0.05 Hz)
- Upper passband edge: 30.00 Hz
- Upper transition bandwidth: 7.50 Hz (-6 dB cutoff frequency: 33.75 Hz)
- Filter length: 4225 samples (33.008 sec)四.去伪迹
1.去坏段
fig = raw.plot(duration=5, n_channels=22, clipping=None)
fig.canvas.key_press_event('a')
plt.show()
#若无法打开添加下列代码
#import matplotlib
#matplotlib.use('TkAgg')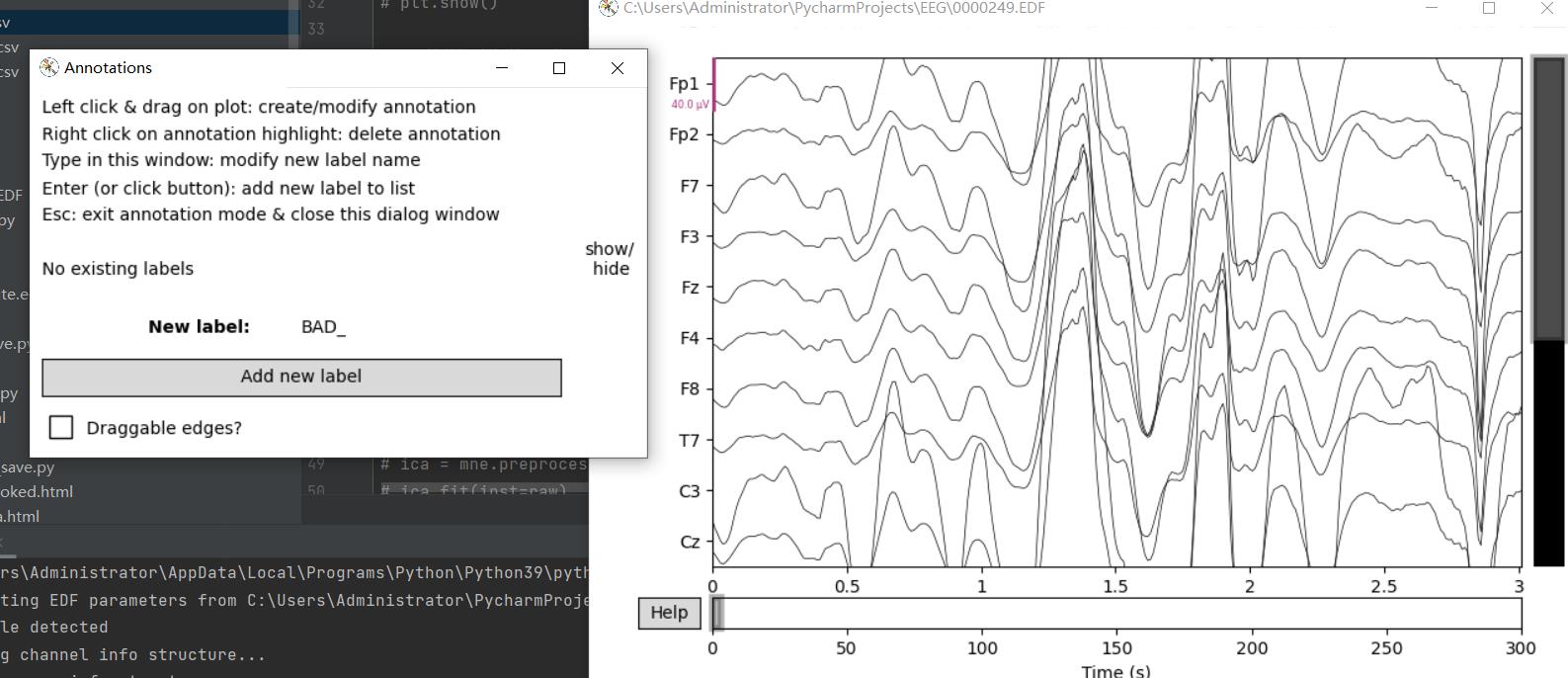
2.去坏道
# 坏道标记
raw.info['bads'].append('FC5')
# 打印出当前的坏道
print(raw.info['bads'])3.坏道值重建
raw = raw.interpolate_bads()
Interpolating bad channels
Automatic origin fit: head of radius 95.0 mm
Computing interpolation matrix from 29 sensor positions
Interpolating 1 sensors
进⾏信号重建后会默认把坏掉的'bads'标记去掉4.独立成分分析(ICA)
#绘制ICA成分地形图
ica = mne.preprocessing.ICA(n_components=12, random_state=97, max_iter=800)
ica.fit(inst=raw)
ica.plot_components()
plt.show()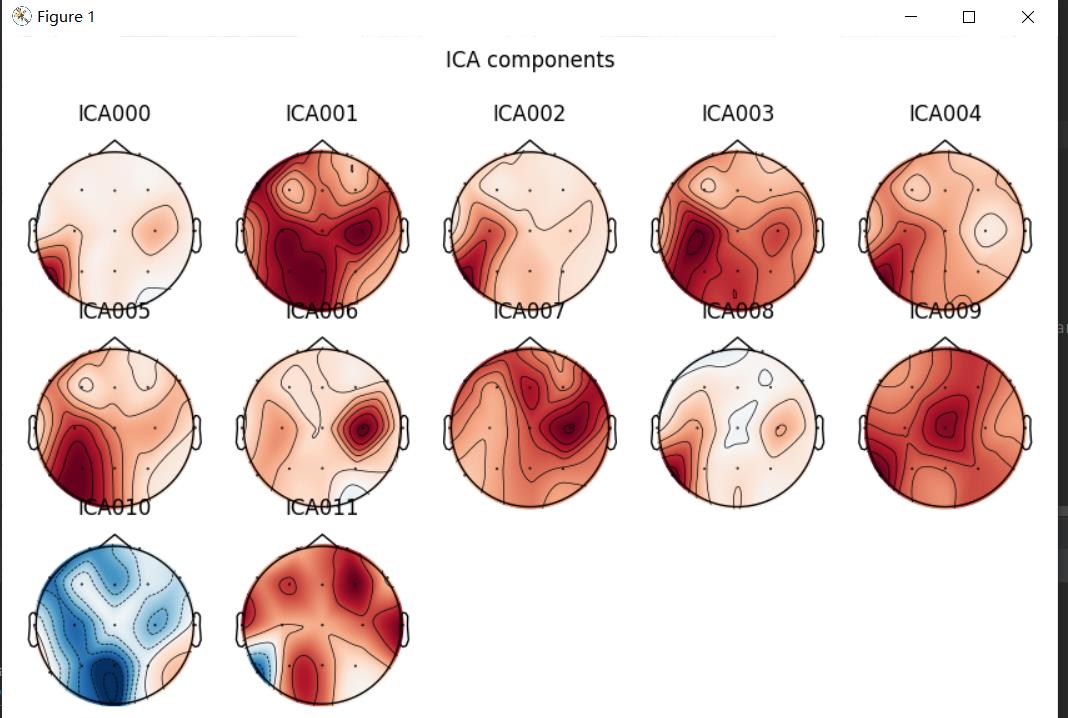
#ICA分析,这个是单独拿成分出来
ica = mne.preprocessing.ICA(n_components=12, random_state=97, max_iter=800)
ica.fit(inst=raw)
ica.plot_properties(raw,picks=[1,5]) 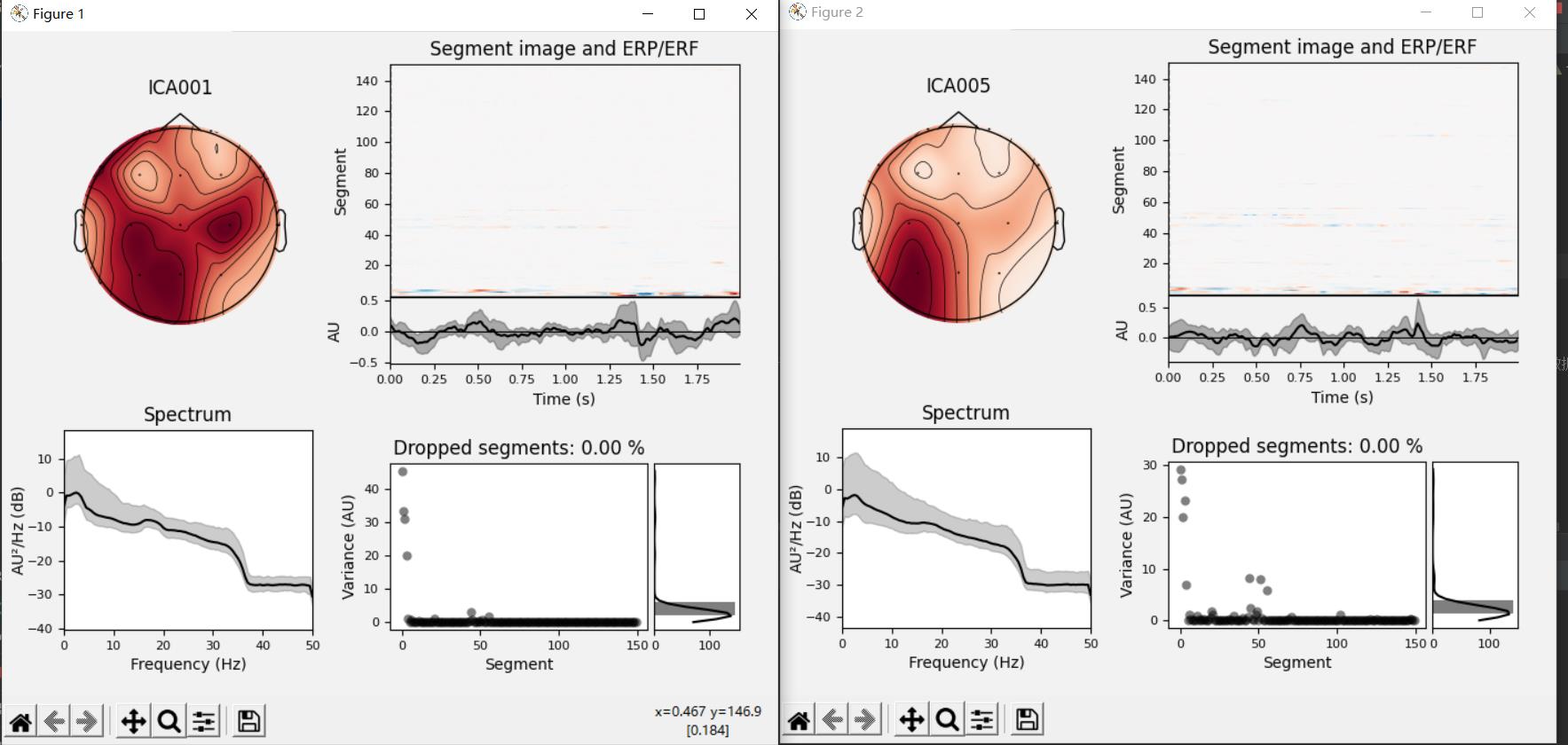
五.结束语
mne库这只是开始和基础的用法,其中参考了mne官方文档和Python脑电数据处理中文手册,后面的操作较难暂时先不展示了如果看的人多我就继续更新。
requests库,简明使用教程(python)
Requests库为python的外部库,话不多话,直接开干吧!
首先是安装requests库,很简单不说了。
文件,引入requests库:
import requests
下面来看一个简单的例子吧:
#一个最简单的爬虫小程序,这里只到获得源html文件结束
import requests
url1="https://live.500.com/" #ISO-8859-1
url2="https://www.baidu.com/" #ISO-8859-1
url3="https://study.163.com/course/introduction.htm?courseId=1209448892#/courseDetail?tab=1" #UTF-8
url4="http://www.cwl.gov.cn/kjxx/ssq/kjgg/" #ISO-8859-1
re=requests.get(url3)
if re.status_code==200: #如果请求成功,那返回的状态码就是200。
#表示请求成功,可以继续往下面走
# print(re.text) #可能会有乱码,因为编码的问题
# print(re.encoding) #得到字符编码UTF-8 or ISO-8859-1
if re.encoding=="ISO-8859-1": #如果是这个编码的话,字集应该是gb2312,就要转一下码,不然会有中文乱码问题
html=re.text.encode("ISO-8859-1").decode("GBK") #先编码,再解码
else:
html=re.text #utf-8,这个直接用,没有中文乱码问题
print(html)
else: #请求不成功。
print("访问失败,换个URL试吧!")
#_________________________________________________________________________________________
re.text #返回的是字符类型
re.content #返回的是字节类型,这一类用于图片啊,声音啊,视频等
上面的例子是requests库发出的一个get请求,也可以发送一个post请求:
re=requests.post(url3,data={"key":"value"}) #参数跟一个字典即可。
还有几个http请求如下:
re = requests.put(‘http://www.baidu.com‘, data = {‘key‘:‘value‘})
re = requests.delete(‘baidu.com‘)
re = requests.head(‘www.baidu.com‘)
re = requests.options(‘http://www.sina.com.cn‘)
未完待续...
以上是关于Python-mne库使用教程的主要内容,如果未能解决你的问题,请参考以下文章
Python 自动化教程 : Excel自动化:使用pandas库
Python 自动化教程 : Excel自动化:使用pandas库