[深度学习] Python人脸识别库face_recognition使用教程
Posted 落痕的寒假
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[深度学习] Python人脸识别库face_recognition使用教程相关的知识,希望对你有一定的参考价值。
Python人脸识别库face_recognition使用教程
face_recognition号称是世界上最简单的开源人脸识别库,可以通过Python或命令行识别和操作人脸。face_recognition提供了十分完整的技术文档和应用实例,人脸识别初学者建议研究该库上手。face_recognition的官方代码仓库为:face_recognition。face_recognition也有自己的官方中文文档,该文档详情见:face_recognition中文使用说明。
本文所有的代码和大部分测试图像来自于face_recognition官方代码仓库的examples文件夹。实际使用建议看看官方文档的函数接口说明face_recognition函数接口。
face_recognition中的人脸识别模型来自开源的机器学习库Dlib,Dlib的官方代码仓库见:dlib。大部分模型用Labeled Faces in the Wild人脸数据集进行测试,有高达99.38%的准确率。但对小孩和亚洲人脸的识别准确率尚待提升。Labeled Faces in the Wild是美国麻省大学安姆斯特分校(University of Massachusetts Amherst)制作的人脸数据集,该数据集包含了从网络收集的13,000多张面部图像。该数据集算是一个非常小型的人脸数据集。
总体而言这个项目的人脸识别模型是基于成年人的,在孩子身上效果可能会一般。face_recognition一般学习代码使用或者研究源代码比较好,离工程应用还是有一定的距离。
某些网站会判定本文人脸图片违规,这是网站识别算法自身问题。本文所有算法展示效果和代码见:
github: Python-Study-Notes
1 face_recognition安装与相关知识
face_recognition支持linux,mac和windows系统,推荐linux系统使用face_recognition。安装face_recognition库之前需要安装dlib的python库。dlib的python库具体安装说明见:[常用工具] dlib编译调用指南中的第四节。注意windows下的dlib库安装不那么容易,多查查文档。
当dlib安装好后,输入以下命令安装face_recognition。
pip install face_recognition
人脸识别通用流程一般有人脸检测,人脸对齐和人脸识别三步:
- 1 人脸检测/人脸定位 face detection and location:人脸检测就是在图片中找到人脸的具体位置,并输出包含人脸位置的边界矩形框。某些检测算法可以同时输出人脸相应的关键点。
- 2 人脸对齐 face alignment:所谓的人脸对齐就是有时候人脸的角度不正,根据关键点检测结果通过图像变换或其他方法,将人脸上对准到一个预设的固定位置上(通常是正脸)。这样使得不同人脸的眼睛,鼻子都被放在同一个位置,大大提高识别精度。
- 3 人脸识别 face recognition:人脸识别有很多应用方向,但是目的都是识别当前人脸对应哪个人。
简单的人脸识别通用流程示意图如下图所示。在face_recognition中所有代码都有涉及这些步骤;但是人脸对齐是直接调用dlib代码,没有实例说明。

当然在成熟的商业工程应用不只有这三个部分,比如还有人脸质量判断,活体检测之类的,但是一般的项目都包含这三大步骤。关于人脸识别的更多介绍见:https://www.cnblogs.com/xiaoyh/p/11874270.html
2 人脸检测/定位
本部分主要是对人脸进行检测和定位,并输出人脸相应的矩形框。主要用到的face_recognition内置函数有:
-
face_recognition.api.face_locations(img, number_of_times_to_upsample=1, model=‘hog’)
- 用途:人脸检测,返回图像中人脸边界框的数组
- img:输入图像,numpy数组
- number_of_times_to_upsample:对图像进行上采样次数以找到更小的人脸,默认为1
- model:检测模型,默认是hog机器学习模型,另外可设置cnn选择卷积神经网络模型以提高检测精度
- 返回:包含多张人脸边界框的list数组,边界框数据以人脸(top, right, bottom, left) 顺序表示
-
face_recognition.api.load_image_file(file, mode=‘RGB’)
- 用途:加载图像
- file:图像路径名
- mode:图像颜色类型,设置RGB表示返回RGB图像,设置’L’表示返回灰度图像
- 返回:numpy数组
2.1 基于机器学习实现人脸检测
来自examples/find_faces_in_picture.py
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image
import face_recognition
# 通过PIL加载图片
image = face_recognition.load_image_file("test_img/obama.jpg")
# 基于hog机器学习模型进行人脸识别,不能使用gpu加速
face_locations = face_recognition.face_locations(image)
# 找到几张人脸
print("I found face(s) in this photograph.".format(len(face_locations)))
for face_location in face_locations:
# 打印人脸信息
top, right, bottom, left = face_location
print("A face is located at pixel location Top: , Left: , Bottom: , Right: ".format(top, left, bottom, right))
# 提取人脸
face_image = image[top:bottom, left:right]
pil_image = Image.fromarray(face_image)
# jupyter 绘图
# pil_image.show()
plt.imshow(pil_image)
plt.axis('off')
plt.show()
I found 1 face(s) in this photograph.
A face is located at pixel location Top: 142, Left: 349, Bottom: 409, Right: 617

2.2 基于卷积神经网络实现人脸检测
来自examples/find_faces_in_picture_cnn.py
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image
import face_recognition
# 通过PIL加载图片
image = face_recognition.load_image_file("test_img/obama.jpg")
# 基于cnn识别人脸,是否使用gpu看装机环境
face_locations = face_recognition.face_locations(image, number_of_times_to_upsample=0, model="cnn")
print("I found face(s) in this photograph.".format(len(face_locations)))
for face_location in face_locations:
# 打印人脸信息
top, right, bottom, left = face_location
print("A face is located at pixel location Top: , Left: , Bottom: , Right: ".format(top, left, bottom, right))
# 提取人脸
face_image = image[top:bottom, left:right]
pil_image = Image.fromarray(face_image)
# jupyter 绘图
# pil_image.show()
plt.imshow(pil_image)
plt.axis('off')
plt.show()
I found 1 face(s) in this photograph.
A face is located at pixel location Top: 154, Left: 375, Bottom: 390, Right: 611

2.3 人脸马赛克
来自examples/blur_faces_on_webcam.py
%matplotlib inline
import matplotlib.pyplot as plt
import face_recognition
import cv2
frame = cv2.imread("test_img/obama.jpg")
# 缩小图像以加快速度
small_frame = cv2.resize(frame, (0, 0), fx=0.25, fy=0.25)
# 找到人脸
face_locations = face_recognition.face_locations(small_frame, model="cnn")
for top, right, bottom, left in face_locations:
# 提取边界框在原图比例的边界框
top *= 4
right *= 4
bottom *= 4
left *= 4
# 提取人脸
face_image = frame[top:bottom, left:right]
# 高斯模糊人脸
face_image = cv2.GaussianBlur(face_image, (99, 99), 30)
# 原图人脸替换
frame[top:bottom, left:right] = face_image
# 展示图像
img = frame[:,:,::-1]
plt.axis('off')
plt.imshow(img)
<matplotlib.image.AxesImage at 0x2139a75cdf0>

3 人脸关键点识别
本部分主要是对人脸进行关键点识别,并输出人脸特征位置。主要用到的face_recognition内置函数有:
- face_recognition.api.face_landmarks(face_image, face_locations=None, model=‘large’)
- 用途:人脸关键点识别,返回图像人脸特征位置的字典
- face_image:输入图像,numpy数组
- face_locations:要识别的位置列表(可选)
- model:使用的识别模型。默认值为large表示大模型。small表示小模型,但只返回五个特征点
- 返回:特征位置(眼睛、鼻子等)的字典列表
3.1 提取图像中的人脸关键点
来自examples/find_facial_features_in_picture.py
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image, ImageDraw
import face_recognition
# 通过PIL加载图片
image = face_recognition.load_image_file("test_img/two_people.jpg")
# 找到图像中所有人脸的所有面部特征,返回字典
face_landmarks_list = face_recognition.face_landmarks(image)
# 发现人脸数
print("I found face(s) in this photograph.".format(len(face_landmarks_list)))
# 创建展示结果的图像
pil_image = Image.fromarray(image)
d = ImageDraw.Draw(pil_image)
# 绘制关键点
for face_landmarks in face_landmarks_list:
# 打印此图像中每个面部特征的位置
# for facial_feature in face_landmarks.keys():
# print("The in this face has the following points: ".format(facial_feature, face_landmarks[facial_feature]))
# 用一条线勾勒出图像中的每个面部特征
for facial_feature in face_landmarks.keys():
d.line(face_landmarks[facial_feature], width=5)
# jupyter 绘图
# pil_image.show()
plt.imshow(pil_image)
plt.axis('off')
plt.show()
I found 2 face(s) in this photograph.

3.2 人脸涂色
来自examples/digital_makeup.py
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image, ImageDraw
import face_recognition
# 通过PIL加载图片
image = face_recognition.load_image_file("test_img/two_people.jpg")
# 找到图像中所有人脸的所有面部特征,返回字典
face_landmarks_list = face_recognition.face_landmarks(image)
pil_image = Image.fromarray(image)
# 绘图
for face_landmarks in face_landmarks_list:
d = ImageDraw.Draw(pil_image, 'RGBA')
# 眉毛涂色
d.polygon(face_landmarks['left_eyebrow'], fill=(68, 54, 39, 128))
d.polygon(face_landmarks['right_eyebrow'], fill=(68, 54, 39, 128))
d.line(face_landmarks['left_eyebrow'], fill=(68, 54, 39, 150), width=5)
d.line(face_landmarks['right_eyebrow'], fill=(68, 54, 39, 150), width=5)
# 嘴唇涂色
d.polygon(face_landmarks['top_lip'], fill=(150, 0, 0, 128))
d.polygon(face_landmarks['bottom_lip'], fill=(150, 0, 0, 128))
d.line(face_landmarks['top_lip'], fill=(150, 0, 0, 64), width=8)
d.line(face_landmarks['bottom_lip'], fill=(150, 0, 0, 64), width=8)
# 眼睛涂色
d.polygon(face_landmarks['left_eye'], fill=(255, 255, 255, 30))
d.polygon(face_landmarks['right_eye'], fill=(255, 255, 255, 30))
# 眼线涂色
d.line(face_landmarks['left_eye'] + [face_landmarks['left_eye'][0]], fill=(0, 0, 0, 110), width=6)
d.line(face_landmarks['right_eye'] + [face_landmarks['right_eye'][0]], fill=(0, 0, 0, 110), width=6)
# jupyter 绘图
# pil_image.show()
plt.imshow(pil_image)
plt.axis('off')
plt.show()

3.3 人眼睁闭状态识别
来自examples / blink_detection.py
该部分代码作用为根据人眼关键点数据计算人眼的纵横比。人眼睁开的时候纵横比较高,人眼闭上的时候纵横比较小。如果眼睛闭上次数超过设定阈值,则输出人眼处于闭眼状态。
import matplotlib.pylab as plt
import face_recognition
import cv2
from scipy.spatial import distance as dist
# 这是一个检测眼睛状态的演示
# 人眼闭上次数超过设定阈值EYES_CLOSED_SECONDS,判定人眼处于闭眼状态
EYES_CLOSED_SECONDS = 2
def main():
# 闭眼次数
closed_count = 0
# 读取两张图像模仿人睁闭眼
img_eye_opened = cv2.imread('test_img/eye_opened.jpg')
img_eye_closed = cv2.imread('test_img/eye_closed.jpg')
# 设置图像输入序列,前1张睁眼,中间3张闭眼,最后1张睁眼
frame_inputs = [img_eye_opened] + [img_eye_closed] * 3 + [img_eye_opened] * 1
for frame_num, frame in enumerate(frame_inputs):
# 缩小图片
small_frame = cv2.resize(frame, (0, 0), fx=0.5, fy=0.5)
# bgr通道变为rgb通道
rgb_small_frame = small_frame[:, :, ::-1]
# 人脸关键点检测
face_landmarks_list = face_recognition.face_landmarks(rgb_small_frame)
# 没有检测到关键点
if len(face_landmarks_list) < 1:
continue
# 获得人眼特征点位置
for face_landmark in face_landmarks_list:
# 每只眼睛有六个关键点,以眼睛最左边顺时针顺序排列
left_eye = face_landmark['left_eye']
right_eye = face_landmark['right_eye']
# 计算眼睛的纵横比ear,ear这里不是耳朵的意思
ear_left = get_ear(left_eye)
ear_right = get_ear(right_eye)
# 判断眼睛是否闭上
# 如果两只眼睛纵横比小于0.2,视为眼睛闭上
closed = ear_left < 0.2 and ear_right < 0.2
# 设置眼睛检测闭上次数
if closed:
closed_count += 1
else:
closed_count = 0
# 如果眼睛检测闭上次数大于EYES_CLOSED_SECONDS,输出眼睛闭上
if closed_count > EYES_CLOSED_SECONDS:
eye_status = "frame | EYES CLOSED".format(frame_num)
elif closed_count > 0:
eye_status = "frame | MAYBE EYES CLOSED ".format(frame_num)
else:
eye_status = "frame | EYES OPENED ".format(frame_num)
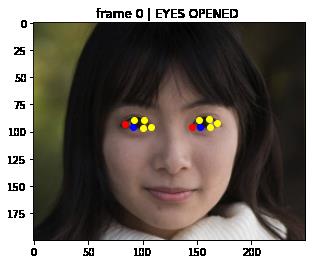
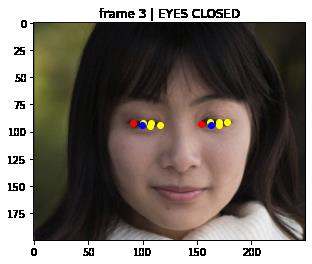
print(eye_status)
plt.imshow(rgb_small_frame)
# 左右眼轮廓第一个关键点颜色为red,最后一个关键点颜色为blue,其他关键点为yellow
color = ['red'] + ['yellow'] * int(len(left_eye) - 2) + ['blue']
# 按照顺序依次绘制眼睛关键点
for index in range(len(left_eye)):
leye = left_eye[index]
reye = right_eye[index]
plt.plot(leye[0], leye[1], 'bo', color=color[index])
plt.plot(reye[0], reye[1], 'bo', color=color[index])
plt.title(eye_status)
plt.show()
# 计算人眼纵横比
def get_ear(eye):
# 计算眼睛轮廓垂直方向上下关键点的距离
A = dist.euclidean(eye[1], eye[5])
B = dist.euclidean(eye[2], eye[4])
# 计算水平方向上的关键点的距离
C = dist.euclidean(eye[0], eye[3])
# 计算眼睛的纵横比
ear = (A + B) / (2.0 * C)
# 返回眼睛的纵横比
return ear
if __name__ == "__main__":
main()
frame 0 | EYES OPENED
frame 1 | MAYBE EYES CLOSED

frame 2 | MAYBE EYES CLOSED

frame 3 | EYES CLOSED
frame 4 | EYES OPENED

4 人脸识别
本部分主要是对人脸进行识别,提供多种实际任务案例。主要用到的face_recognition内置函数有:
-
face_recognition.api.face_encodings(face_image, known_face_locations=None, num_jitters=1, model=‘small’)
- 用途:返回图像中每个人脸的128维人脸特征
- face_image:输入图像,numpy数组
- known_face_locations:每个人脸的边界框(可选),能够大大提高识别速度
- num_jitters:计算人脸特征时重新采样人脸的次数。更高更准确,但更慢,即设置为100慢100倍
- model:使用的识别模型,默认值为small表示小模型,只返回五个特征点;可设置为large
- 返回:包含人脸特征的列表
-
face_recognition.api.compare_faces(known_face_encodings, face_encoding_to_check, tolerance=0.6)
- 用途:将人脸特征与候选人脸特征进行比较,以查看它们是否匹配。
- known_face_encodings:已知人脸特征列表
- face_encoding_to_check:与已知人脸特征列表进行比较的单个人脸特征
- tolerance:人脸距离越小表示人脸越相近,当人脸距离小于tolerance,表示是同一个人;0.6是默认值,也是作者认为的最佳值(实际有所出入)
- 返回:包含True或者False的列表,以表示是否为同一个人脸
-
face_recognition.api.face_distance(face_encodings, face_to_compare)
- 用途:给定一个人脸特征列表,将它们与已知的人脸特征进行比较,并获得人脸特征向量之间的欧几里德距离,距离越小面孔越相似。
- face_encodings:已知的人脸特征列表
- face_to_compare:未知的人脸特征列表
- 返回:代表距离的numpy数组,和face_encodings的排序方式一样
4.1 人脸比对
来自examples/recognize_faces_in_pictures.py
该部分代码就是输入两张已知人脸图像和一张未知人脸图像,看未知人脸图像和已知人脸的哪一张图像表示的是同一个人。
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image, ImageDraw
import face_recognition
# 通过PIL加载图片
biden_image = face_recognition.load_image_file("test_img/biden.jpg")
obama_image = face_recognition.load_image_file("test_img/obama.jpg")
unknown_image = face_recognition.load_image_file("test_img/obama2.jpg")
plt.imshow(biden_image)
plt.title('biden')
plt.axis('off')
plt.show()
plt.imshow(obama_image)
plt.title('obama')
plt.axis('off')
plt.show()
plt.imshow(unknown_image)
plt.title('unknown')
plt.axis('off')
plt.show()
# 获取输入图像文件中每个人脸的人脸特征,人脸特征维度为128
# 由于输入图像中可能有多张脸,因此它会返回一个特征列表。
# 默认输入图像只有一张人脸,只关心每个图像中的第一个特征,所以设置特征获取索引为0
# 建议单步看看该函数运行机制
try:
biden_face_encoding = face_recognition.face_encodings(biden_image)[0]
obama_face_encoding = face_recognition.face_encodings(obama_image)[0]
unknown_face_encoding = face_recognition.face_encodings(unknown_image)[0]
except IndexError:
# 没有找到人脸的情况
print("I wasn't able to locate any faces in at least one of the images. Check the image files. Aborting...")
quit()
# 已知人脸列表,按照顺序为拜登的人脸特征,奥巴马的人脸特征
known_faces = [
biden_face_encoding,
obama_face_encoding
]
# 如果未知人脸与已知人脸数组中的某个人匹配,则匹配结果为真
# 这个函数调用了face_distance人脸特征距离计算函数,可以单步调试看看源代码
results = face_recognition.compare_faces(known_faces, unknown_face_encoding)
# 是否和第一个人匹配
print("Is the unknown face a picture of Biden? ".format(results[0]))
# 是否和第二个人匹配
print("Is the unknown face a picture of Obama? ".format(results[1]))
# 这张人脸是否曾经见过
print("Is the unknown face a new person that we've never seen before? ".format(not True in results))



Is the unknown face a picture of Biden? False
Is the unknown face a picture of Obama? True
Is the unknown face a new person that we've never seen before? False
4.2 人脸识别之后在原图上画框并标注姓名
来自examples/identify_and_draw_boxes_on_faces.py
该部分代码就是输入两张已知人脸图像和一张未知人脸图像,然后进行人脸识别并在未知人脸图像标注各个人脸身份信息
%matplotlib inline
import matplotlib.pyplot as plt
import face_recognition
from PIL import Image, ImageDraw
import numpy as np
# 加载第一张示例图片并提取特征
obama_image = face_recognition.load_image_file("test_img/obama.jpg")
obama_face_encoding = face_recognition.face_encodings(obama_image)[0]
# 加载第二张示例图片并提取特征
biden_image = face_recognition.load_image_file("test_img/biden.jpg")
biden_face_encoding = face_recognition.face_encodings(biden_image)[0]
# 创建已知人脸识别实战:使用Python OpenCV 和深度学习进行人脸识别
在本教程中,您将学习如何使用 OpenCV、Python 和深度学习执行面部识别。
我们将首先简要讨论基于深度学习的面部识别的工作原理,包括“深度度量学习”的概念。 从那里,我将帮助您安装实际执行人脸识别所需的库。 最后,我们将为静止图像和视频流实现人脸识别。
理解深度学习人脸识别嵌入
那么,深度学习+人脸识别是如何运作的呢?
秘诀是一种称为深度度量学习的技术。 如果您之前有任何深度学习经验,您就会知道我们通常训练网络以: 接受单个输入图像 并输出该图像的分类/标签 然而,深度度量学习是不同的。
相反,我们不是尝试输出单个标签(甚至是图像中对象的坐标/边界框),而是输出实值特征向量。
对于 dlib 人脸识别网络,输出特征向量是 128-d(即 128 个实数值的列表),用于量化人脸。 训练网络是使用三元组完成的:
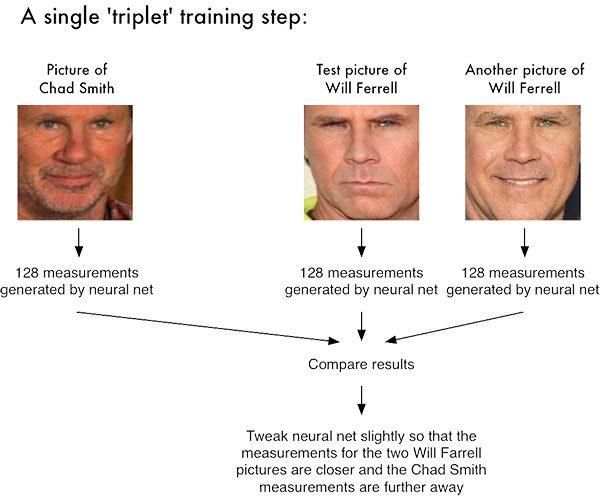
这里我们向网络提供三张图片: 其中两张图片是同一个人的示例面孔。 第三张图片是我们数据集中的一张随机人脸,与其他两张图片不是同一个人。
作为示例,让我们再次考虑图 1,其中我们提供了三张图像:一张 Chad Smith 和两张 Will Ferrell。 我们的网络对人脸进行量化,为每个人构建 128 维嵌入(量化)。
从那里开始,一般的想法是我们将调整我们的神经网络的权重,以便两个 Will Ferrel 的 128 维测量值将彼此更接近,并且与 Chad Smith 的测量值相距更远。
我们用于人脸识别的网络架构基于 He 等人的 Deep Residual Learning for Image Recognition 论文中的 ResNet-34,但层数更少,过滤器的数量减少了一半。
网络本身由 Davis King 在 ≈300 万张图像的数据集上进行训练。在野外标记人脸 (LFW) 数据集上,该网络与其他最先进的方法进行比较,准确率达到 99.38%。 Davis King(dlib 的创建者)和 Adam Geitgey(我们将很快使用的 face_recognition 模块的作者)都写了关于基于深度学习的面部识别如何工作的详细文章:
- 使用深度度量学习的高质量人脸识别 (Davis) dlib C++ Library: High Quality Face Recognition with Deep Metric Learning
- 深度学习的现代人脸识别 (Adam)https://medium.com/@ageitgey/machine-learning-is-fun-part-4-modern-face-recognition-with-deep-learning-c3cffc121d78
我强烈建议您阅读上述文章,以了解有关深度学习面部嵌入如何工作的更多详细信息。
安装人脸识别库
为了使用 Python 和 OpenCV 执行人脸识别,我们需要安装两个额外的库:
由 Davis King 维护的 dlib 库包含我们的“深度度量学习”实现,用于构建用于实际识别过程的人脸嵌入。
由 Adam Geitgey 创建的 face_recognition 库包含了 dlib 的面部识别功能,使其更易于使用。
安装 dlib
pip install dlib
或者你可以从源代码编译:
git clone https://github.com/davisking/dlib.git
cd dlib
mkdir build
cd build
cmake .. -DUSE_AVX_INSTRUCTIONS=1
cmake --build .
cd ..
python setup.py install --yes USE_AVX_INSTRUCTIONS
安装支持 GPU 的 dlib(可选)
如果你有一个兼容 CUDA 的 GPU,你可以安装支持 GPU 的 dlib,使面部识别更快、更高效。 为此,我建议从源代码安装 dlib,因为您可以更好地控制构建:
$ git clone https://github.com/davisking/dlib.git
$ cd dlib
$ mkdir build
$ cd build
$ cmake .. -DDLIB_USE_CUDA=1 -DUSE_AVX_INSTRUCTIONS=1
$ cmake --build .
$ cd ..
$ python setup.py install --yes USE_AVX_INSTRUCTIONS --yes DLIB_USE_CUDA
安装 face_recognition 包
face_recognition 模块可以通过一个简单的 pip 命令安装:
pip install face_recognition
安装 imutils
您还需要我的便利功能包 imutils。 你可以通过 pip 将它安装在你的 Python 虚拟环境中:
pip install imutils
人脸识别数据集

由于侏罗纪公园 (1993) 是我有史以来最喜欢的电影,为了纪念本周五在美国上映的侏罗纪世界:堕落王国 (2018),我们将对电影中的角色样本进行面部识别 : Alan Grant,古生物学家(22 张图片) Claire Dearing,公园运营经理(53 张图片) Ellie Sattler,古植物学家(31 张图片) 伊恩马尔科姆,数学家(41 张图片) 约翰哈蒙德,商人/侏罗纪公园所有者(36 张图片) Owen Grady,恐龙研究员(35 张图片)
获得此图像数据集,我们将:
- 为数据集中的每个人脸创建 128 维嵌入
- 使用这些嵌入来识别图像和视频流中人物的面部
人脸识别项目结构
myface
├── dataset
│ ├── alan_grant [22 entries]
│ ├── claire_dearing [53 entries]
│ ├── ellie_sattler [31 entries]
│ ├── ian_malcolm [41 entries]
│ ├── john_hammond [36 entries]
│ └── owen_grady [35 entries]
├── examples
│ ├── example_01.png
│ ├── example_02.png
│ └── example_03.png
├── output
│ └── lunch_scene_output.avi
├── videos
│ └── lunch_scene.mp4
├── encode_faces.py
├── recognize_faces_image.py
├── recognize_faces_video.py
├── recognize_faces_video_file.py
└── encodings.pickle
我们的项目有 4 个顶级目录:
- dataset/ :包含六个字符的面部图像,根据它们各自的名称组织到子目录中。
- examples/ :具有三个不在数据集中的用于测试的面部图像。
- output/ :这是您可以存储处理过的人脸识别视频的地方。 我要把我的一个留在文件夹里——原侏罗纪公园电影中的经典“午餐场景”。
- videos/ :输入视频应存储在此文件夹中。 该文件夹还包含“午餐场景”视频,但尚未经过我们的人脸识别系统。
我们在根目录下还有 6 个文件:
- encode_faces.py :人脸的编码(128 维向量)是用这个脚本构建的。
- identify_faces_image.py :识别单个图像中的人脸(基于数据集中的编码)。
- identify_faces_video.py :识别来自网络摄像头的实时视频流中的人脸并输出视频。
- identify_faces_video_file.py :识别驻留在磁盘上的视频文件中的人脸并将处理后的视频输出到磁盘。 我今天不会讨论这个文件,因为骨骼来自与视频流文件相同的骨架。
- encodings.pickle :面部识别编码通过 encode_faces.py 从您的数据集生成,然后序列化到磁盘。
创建图像数据集后(使用 search_bing_api.py ),我们将运行 encode_faces.py 来构建嵌入。 然后,我们将运行识别脚本来实际识别人脸。
使用 OpenCV 和深度学习对人脸进行编码

在识别图像和视频中的人脸之前,我们首先需要量化训练集中的人脸。 请记住,我们实际上并不是在这里训练网络——网络已经被训练为在大约 300 万张图像的数据集上创建 128 维嵌入。
我们当然可以从头开始训练网络,甚至可以微调现有模型的权重,但这对许多项目来说很可能是矫枉过正。
此外,您将需要大量图像来从头开始训练网络。 相反,使用预训练网络然后使用它为我们数据集中的 218 张人脸中的每一张构建 128 维嵌入更容易。
然后,在分类过程中,我们可以使用一个简单的 k-NN 模型 + 投票来进行最终的人脸分类。 其他传统的机器学习模型也可以在这里使用。 要构建我们的人脸嵌入,
请新建 encode_faces.py:
# import the necessary packages
from imutils import paths
import face_recognition
import argparse
import pickle
import cv2
import os
首先,我们需要导入所需的包。 再次注意,此脚本需要安装 imutils 、 face_recognition 和 OpenCV 。 向上滚动到“安装您的人脸识别库”以确保您已准备好在您的系统上使用这些库。 让我们处理在运行时使用 argparse 处理的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--dataset", required=True,
help="path to input directory of faces + images")
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
让我们列出参数标志并讨论它们:
- –dataset :数据集的路径(我们使用上周博客文章的方法 #2 中描述的 search_bing_api.py 创建了一个数据集)。
- –encodings :我们的人脸编码被写入这个参数指向的文件中。
- –detection-method :在我们对图像中的人脸进行编码之前,我们首先需要检测它们。 或者两种人脸检测方法包括 hog 或 cnn 。 这两个标志是唯一适用于 --detection-method 的标志。
现在我们已经定义了我们的参数,让我们获取数据集中文件的路径(以及执行两个初始化):
# grab the paths to the input images in our dataset
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize the list of known encodings and known names
knownEncodings = []
knownNames = []
输入数据集目录的路径来构建其中包含的所有图像路径的列表。
我们还需要在循环之前分别初始化两个列表 knownEncodings 和 knownNames 。 这两个列表将包含数据集中每个人的面部编码和相应的姓名。 是时候开始循环我们侏罗纪公园的角色面孔了!
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# extract the person name from the image path
print("[INFO] processing image /".format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
# load the input image and convert it from BGR (OpenCV ordering)
# to dlib ordering (RGB)
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
这个循环将循环 218 次,对应于我们在数据集中的 218 张人脸图像。
遍历每个图像的路径。 从那里,我们将从 imagePath(因为我们的子目录被适当命名)中提取人名。 然后让我们加载图像,同时将 imagePath 传递给 cv2.imread。 OpenCV 在 BGR 中订购颜色通道,但 dlib 实际上期望 RGB。 face_recognition 模块使用 dlib ,所以在我们继续之前,让我们在第 37 行交换颜色空间,将新图像命名为 rgb 。 接下来,让我们定位人脸并计算编码:
# detect the (x, y)-coordinates of the bounding boxes
# corresponding to each face in the input image
boxes = face_recognition.face_locations(rgb,
model=args["detection_method"])
# compute the facial embedding for the face
encodings = face_recognition.face_encodings(rgb, boxes)
# loop over the encodings
for encoding in encodings:
# add each encoding + name to our set of known names and
# encodings
knownEncodings.append(encoding)
knownNames.append(name)
这是剧本的有趣部分!
对于循环的每次迭代,我们将检测一张脸(或者可能是多张脸,并假设它是图像多个位置的同一个人——这个假设在你自己的图像中可能成立,也可能不成立,所以要小心 这里)。 例如,假设 rgb 包含一张(或多张)Ellie Sattler 脸部的图片。查找/定位了她的面孔,从而生成了面孔框列表。 我们将两个参数传递给 face_recognition.face_locations 方法:
-
rgb :我们的 RGB 图像。
-
model:cnn 或 hog(该值包含在与“detection_method”键关联的命令行参数字典中)。 CNN方法更准确但速度更慢。 HOG 速度更快,但准确度较低。
然后,我们将 Ellie Sattler 面部的边界框转换为 128 个数字的列表。这称为将面部编码为向量,而 face_recognition.face_encodings 方法会为我们处理它。 从那里我们只需要将 Ellie Sattler 编码和名称附加到适当的列表(knownEncodings 和 knownNames)。 我们将继续对数据集中的所有 218 张图像执行此操作。 除非我们可以在另一个处理识别的脚本中使用编码,否则对图像进行编码有什么意义? 现在让我们解决这个问题:
# dump the facial encodings + names to disk
print("[INFO] serializing encodings...")
data = "encodings": knownEncodings, "names": knownNames
f = open(args["encodings"], "wb")
f.write(pickle.dumps(data))
f.close()
构造了一个带有两个键的字典—— “encodings” 和 “names” 。
将名称和编码转储到磁盘以备将来调用。 我应该如何在终端中运行 encode_faces.py 脚本? 要创建我们的面部嵌入,请打开一个终端并执行以下命令:
python encode_faces.py --dataset dataset --encodings encodings.pickle
[INFO] quantifying faces...
[INFO] processing image 1/218
[INFO] processing image 2/218
[INFO] processing image 3/218
...
[INFO] processing image 216/218
[INFO] processing image 217/218
[INFO] processing image 218/218
[INFO] serializing encodings...
$ ls -lh encodings*
-rw-r--r--@ 1 adrian staff 234K May 29 13:03 encodings.pickle
正如您从我们的输出中看到的,我们现在有一个名为 encodings.pickle 的文件——该文件包含我们数据集中每个人脸的 128 维人脸嵌入。
在我的 Titan X GPU 上,处理整个数据集需要一分钟多一点的时间,但如果您使用的是 CPU,请准备好等待此脚本完成!
在我的 Macbook Pro(无 GPU)上,编码 218 个图像需要 21 分 20 秒。
如果你有一个 GPU 并且编译的 dlib 支持 GPU,你应该期望更快的速度。
识别图像中的人脸

现在我们已经为数据集中的每个图像创建了 128 维人脸嵌入,现在我们可以使用 OpenCV、Python 和深度学习来识别图像中的人脸。 打开recognize_faces_image.py 并插入以下代码:
# import the necessary packages
import face_recognition
import argparse
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
解析三个命令行参数:
–encodings :包含我们的面部编码的pickle文件的路径。
–image :这是正在进行面部识别的图像。
–detection-method :你现在应该很熟悉这个了——根据你系统的能力,我们要么使用 hog 方法,要么使用 cnn 方法。 为了速度,选择 hog ,为了准确,选择 cnn 。
然后,让我们加载预先计算的编码 + 人脸名称,然后为输入图像构建 128 维人脸编码:
# load the known faces and embeddings
print("[INFO] loading encodings...")
data = pickle.loads(open(args["encodings"], "rb").read())
# load the input image and convert it from BGR to RGB
image = cv2.imread(args["image"])
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# detect the (x, y)-coordinates of the bounding boxes corresponding
# to each face in the input image, then compute the facial embeddings
# for each face
print("[INFO] recognizing faces...")
boxes = face_recognition.face_locations(rgb,
model=args["detection_method"])
encodings = face_recognition.face_encodings(rgb, boxes)
# initialize the list of names for each face detected
names = []
从磁盘加载我们腌制的编码和人脸名称。 我们稍后将在实际的人脸识别步骤中需要这些数据。
然后,我们加载输入图像并将其转换为 rgb 颜色通道排序(就像我们在 encode_faces.py 脚本中所做的那样)。
然后我们继续检测输入图像中的所有人脸,并计算它们的 128 维编码(这些行看起来也应该很熟悉)。
现在是为检测到的每个人脸初始化名称列表的好时机——该列表将在下一步中填充。
接下来,让我们遍历面部编码:
# loop over the facial embeddings
for encoding in encodings:
# attempt to match each face in the input image to our known
# encodings
matches = face_recognition.compare_faces(data["encodings"],
encoding)
name = "Unknown"
我们开始遍历从输入图像计算出的人脸编码。 然后面部识别魔术发生了! 我们尝试使用 face_recognition.compare_faces将输入图像(编码)中的每个人脸与我们已知的编码数据集(保存在 data[“encodings”] 中)进行匹配。
此函数返回 True / False 值列表,数据集中的每个图像对应一个值。 对于我们的侏罗纪公园示例,数据集中有 218 个图像,因此返回的列表将有 218 个布尔值。
在内部,compare_faces 函数正在计算候选嵌入与我们数据集中所有人脸之间的欧几里德距离:
- 如果距离低于某个容差(容差越小,我们的面部识别系统就会越严格),那么我们返回 True ,表示面部匹配。
- 否则,如果距离高于容差阈值,我们将返回 False,因为人脸不匹配。
本质上,我们正在利用“更花哨”的 k-NN 模型进行分类。 请务必参考 compare_faces 实现以获取更多详细信息。 name 变量最终将保存此人的姓名字符串——现在,我们将其保留为“Unknown”,以防没有“投票”。
给定我们的匹配列表,我们可以计算每个名字的“投票”数(与每个名字关联的 True 值的数量),统计投票数,并选择对应票数最多的人的名字:
# check to see if we have found a match
if True in matches:
# find the indexes of all matched faces then initialize a
# dictionary to count the total number of times each face
# was matched
matchedIdxs = [i for (i, b) in enumerate(matches) if b]
counts =
# loop over the matched indexes and maintain a count for
# each recognized face face
for i in matchedIdxs:
name = data["names"][i]
counts[name] = counts.get(name, 0) + 1
# determine the recognized face with the largest number of
# votes (note: in the event of an unlikely tie Python will
# select first entry in the dictionary)
name = max(counts, key=counts.get)
# update the list of names
names.append(name)
如果匹配中有任何 True 投票,我们需要确定这些 True 值在匹配中的位置的索引。 我们就这样做了,在那里我们构造了一个简单的匹配Idxs 列表,对于 example_01.png 可能看起来像这样:
(Pdb) matchedIdxs
[35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 71, 72, 73, 74, 75]
然后我们初始化一个名为 counts 的字典,它将以字符名称作为键,将投票数作为值。 从那里,让我们循环匹配的Idxs并设置与每个名称关联的值,同时根据需要在 counts 中增加它。 对于 Ian Malcolm 的高票数,counts 字典可能如下所示:
(Pdb) counts
'ian_malcolm': 40
回想一下,我们在数据集中只有 41 张 Ian 的照片,所以在没有给其他任何人投票的情况下,40 分是非常高的。 从 counts 中提取得票最多的名称,在本例中为 ‘ian_malcolm’ 。 主要面部编码循环的第二次循环(因为我们的示例图像中有两个人脸)为 counts 生成以下内容:
(Pdb) counts
'alan_grant': 5
这绝对是一个较小的投票分数,但字典中仍然只有一个名字,所以我们可能已经找到了艾伦格兰特。
如下图 5 所示,Ian Malcolm 和 Alan Grant 都已被正确识别,因此这部分脚本运行良好。 让我们继续并遍历每个人的边界框和标记名称,并将它们绘制在我们的输出图像上以进行可视化:
# loop over the recognized faces
for ((top, right, bottom, left), name) in zip(boxes, names):
# draw the predicted face name on the image
cv2.rectangle(image, (left, top), (right, bottom), (0, 255, 0), 2)
y = top - 15 if top - 15 > 15 else top + 15
cv2.putText(image, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
我们开始遍历检测到的人脸边界框和预测的名称。
为了创建一个可迭代对象,以便我们可以轻松地遍历这些值,我们调用 zip(boxes, names) 生成元组,我们可以从中提取框坐标和名称。
我们使用框坐标绘制一个绿色矩形。 我们还使用坐标来计算应该在何处绘制人名文本,然后将姓名文本实际放置在图像上。如果人脸边界框在图像的最顶部,我们需要将文本移动到框顶部下方,否则文本将被截断。 然后我们继续显示图像,直到按下一个键。 您应该如何运行面部识别 Python 脚本? 使用您的终端,首先使用 workon 命令确保您在各自的 Python 正确虚拟环境中(当然,如果您使用的是虚拟环境)。
然后运行脚本,同时至少提供两个命令行参数。如果您选择使用 HoG 方法,请确保也通过 --detection-method hog(否则它将默认为深度学习检测器)。
加油吧! 要使用 OpenCV 和 Python 识别人脸,请打开您的终端并执行我们的脚本:
python recognize_faces_image.py --encodings encodings.pickle \\
--image examples/example_01.png
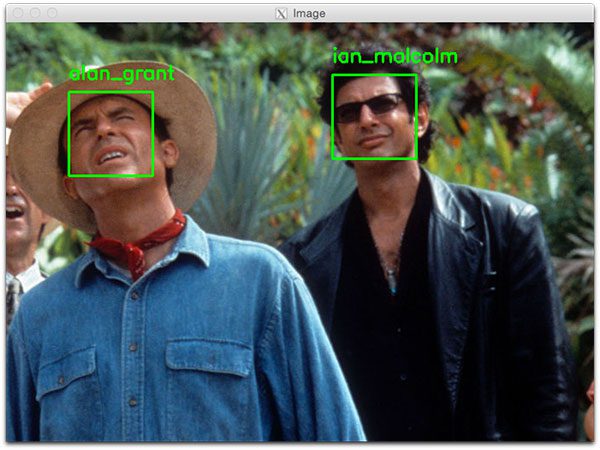
第二个人脸识别示例如下:
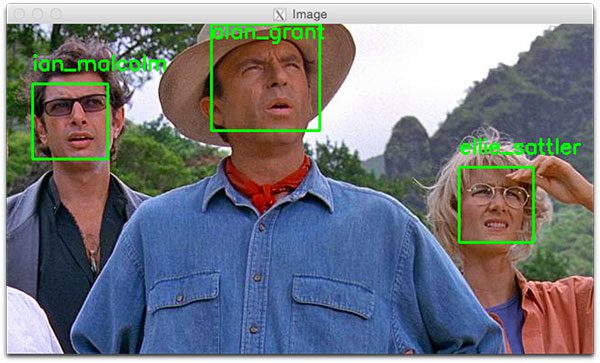
识别视频中的人脸

现在我们已经将人脸识别应用于图像,让我们也将人脸识别应用于视频(实时)。
重要的性能说明:只有在使用 GPU 时才能实时使用 CNN 面部识别器(您可以将它与 CPU 一起使用,但预计低于 0.5 FPS,这会导致视频断断续续)。
或者(您使用的是 CPU),您应该使用 HoG 方法(甚至在以后的博客文章中介绍的 OpenCV Haar 级联)并期望足够的速度。 以下脚本与之前的 identify_faces_image.py 脚本有很多相似之处。
因此,我将略过我们已经介绍过的内容,只查看视频组件,以便您了解正在发生的事情。
新建 identify_faces_video.py 并插入以下代码:
# import the necessary packages
from imutils.video import VideoStream
import face_recognition
import argparse
import imutils
import pickle
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--encodings", required=True,
help="path to serialized db of facial encodings")
ap.add_argument("-o", "--output", type=str,
help="path to output video")
ap.add_argument("-y", "--display", type=int, default=1,
help="whether or not to display output frame to screen")
ap.add_argument("-d", "--detection-method", type=str, default="cnn",
help="face detection model to use: either `hog` or `cnn`")
args = vars(ap.parse_args())
导入包,然后继续解析我们的命令行参数。 我们有四个命令行参数,其中两个您应该从上面识别(–encodings 和–detection-method)。 另外两个参数是:
–output : 输出视频的路径。
–display :指示脚本在屏幕上显示框架的标志。 值为 1 时显示,值为 0 时不会将输出帧显示到我们的屏幕上。
加载我们的编码并启动我们的 VideoStream :
# load the known faces and embeddings
print("[INFO] loading encodings...")
data = pickle.loads(open(args["encodings"], "rb").read())
# initialize the video stream and pointer to output video file, then
# allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
writer = None
time.sleep(2.0)
为了访问我们的相机,我们使用了 imutils 的 VideoStream 类。
启动流。 如果您的系统上有多个摄像头(例如内置网络摄像头和外部 USB 摄像头),您可以将 src=0 更改为 src=1 等等。 稍后我们将有选择地将处理过的视频帧写入磁盘,因此我们将 writer 初始化为 None。 休眠 2 秒可以让我们的相机预热。 从那里我们将开始一个 while 循环并开始抓取和处理帧:
# loop over frames from the video file stream
while True:
# grab the frame from the threaded video stream
frame = vs.read()
# convert the input frame from BGR to RGB then resize it to have
# a width of 750px (to speedup processing)
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
rgb = imutils.resize(frame, width=750)
r = frame.shape[1] / float(rgb.shape[1])
# detect the (x, y)-coordinates of the bounding boxes
# corresponding to each face in the input frame, then compute
# the facial embeddings for each face
boxes = face_recognition.face_locations(rgb,
model=args["detection_method"])
encodings = face_recognition.face_encodings(rgb, boxes)
names = []
我们采取的第一步是从视频流中抓取一帧。 上述代码块与前一个脚本中的行几乎相同,不同之处在于这是一个视频帧而不是静态图像。 本质上,我们读取帧,预处理,然后检测人脸边界框 + 计算每个边界框的编码。
接下来,让我们遍历与我们刚刚找到的人脸相关的人脸编码:
# loop over the facial embeddings
for encoding in encodings:
# attempt to match each face in the input image to our known
# encodings
matches = face_recognition.compare_faces(data["encodings"],
encoding)
name = "Unknown"
# check to see if we have found a match
if True in matches:
# find the indexes of all matched faces then initialize a
# dictionary to count the total number of times each face
# was matched
matchedIdxs = [i for (i, b) in enumerate(matches) if b]
counts =
# loop over the matched indexes and maintain a count for
# each recognized face face
for i in matchedIdxs:
name = data["names"][i]
counts[name] = counts.get(name, 0) + 1
# determine the recognized face with the largest number
# of votes (note: in the event of an unlikely tie Python
# will select first entry in the dictionary)
name = max(counts, key=counts.get)
# update the list of names
names.append(name)
在这个代码块中,我们遍历每个编码并尝试匹配人脸。 如果找到匹配项,我们会计算数据集中每个名字的投票数。 然后我们提取最高票数,即与人脸相关的名称。 这些行与我们查看的前一个脚本相同,所以让我们继续。
在下一个块中,我们遍历识别出的人脸并继续在人脸周围绘制一个框,并在人脸上方显示人的姓名:
# loop over the recognized faces
for ((top, right, bottom, left), name) in zip(boxes, names):
# rescale the face coordinates
top = int(top * r)
right = int(right * r)
bottom = int(bottom * r)
left = int(left * r)
# draw the predicted face name on the image
cv2.rectangle(frame, (left, top), (right, bottom),
(0, 255, 0), 2)
y = top - 15 if top - 15 > 15 else top + 15
cv2.putText(frame, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
这些行也是相同的,所以让我们关注与视频相关的代码。 或者,我们将帧写入磁盘,让我们看看如何使用 OpenCV 将视频写入磁盘:
# if the video writer is None *AND* we are supposed to write
# the output video to disk initialize the writer
if writer is None and args["output"] is not None:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 20,
(frame.shape[1], frame.shape[0]), True)
# if the writer is not None, write the frame with recognized
# faces to disk
if writer is not None:
writer.write(frame)
假设我们在命令行参数中提供了一个输出文件路径,并且我们还没有初始化视频编写器,让我们继续初始化它。 我们初始化 VideoWriter_fourcc 。 FourCC 是一个 4 个字符的代码,在我们的例子中,我们将使用“MJPG” 4 个字符的代码。 从那里,我们将该对象连同我们的输出文件路径、每秒帧数和帧尺寸一起传递到 VideoWriter。 最后,如果 writer 存在,我们可以继续将帧写入磁盘。
让我们来处理是否应该在屏幕上显示人脸识别视频帧:
# check to see if we are supposed to display the output frame to
# the screen
if args["display"] > 0:
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
如果设置了 display 命令行参数,我们继续显示框架并检查是否按下了退出键(“q”),此时我们将跳出 循环。 最后,让我们履行我们的家政职责:
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
# check to see if the video writer point needs to be released
if writer is not None:
writer.release()
我们清理并释放显示、视频流和视频编写器。 您准备好查看正在运行的脚本了吗?
要演示使用 OpenCV 和 Python 进行实时人脸识别,请打开终端并执行以下命令:
python recognize_faces_video.py --encodings encodings.pickle \\
--output output/webcam_face_recognition_output.avi --display 1
[INFO] loading encodings...
[INFO] starting video stream...
视频文件中的人脸识别
正如我在“人脸识别项目结构”部分中提到的,这篇博文的“下载”中包含一个额外的脚本——recognize_faces_video_file.py。
该文件与我们刚刚查看的网络摄像头文件基本相同,但如果您愿意,它会采用输入视频文件并生成输出视频文件。
我将我们的面部识别代码应用于原始侏罗纪公园电影中流行的“午餐场景”,其中演员围坐在桌子旁与公园分享他们的担忧:
python recognize_faces_video_file.py --encodings encodings.pickle \\
--input videos/lunch_scene.mp4 --output output/lunch_scene_output.avi \\
--display 0
总结
在本教程中,您学习了如何使用 OpenCV、Python 和深度学习执行人脸识别。 此外,我们利用了 Davis King 的 dlib 库和 Adam Geitgey 的 face_recognition 模块,该模块围绕 dlib 的深度度量学习,使面部识别更容易实现。 正如我们发现的,
我们的人脸识别实现是:
- 准确的
- 能够通过 GPU 实时执行
我希望你喜欢今天关于人脸识别的博文!
以上是关于[深度学习] Python人脸识别库face_recognition使用教程的主要内容,如果未能解决你的问题,请参考以下文章