如何使用OpenAI fine-tuning(微调)训练属于自己专有的ChatGPT模型?
Posted 源代码杀手
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用OpenAI fine-tuning(微调)训练属于自己专有的ChatGPT模型?相关的知识,希望对你有一定的参考价值。
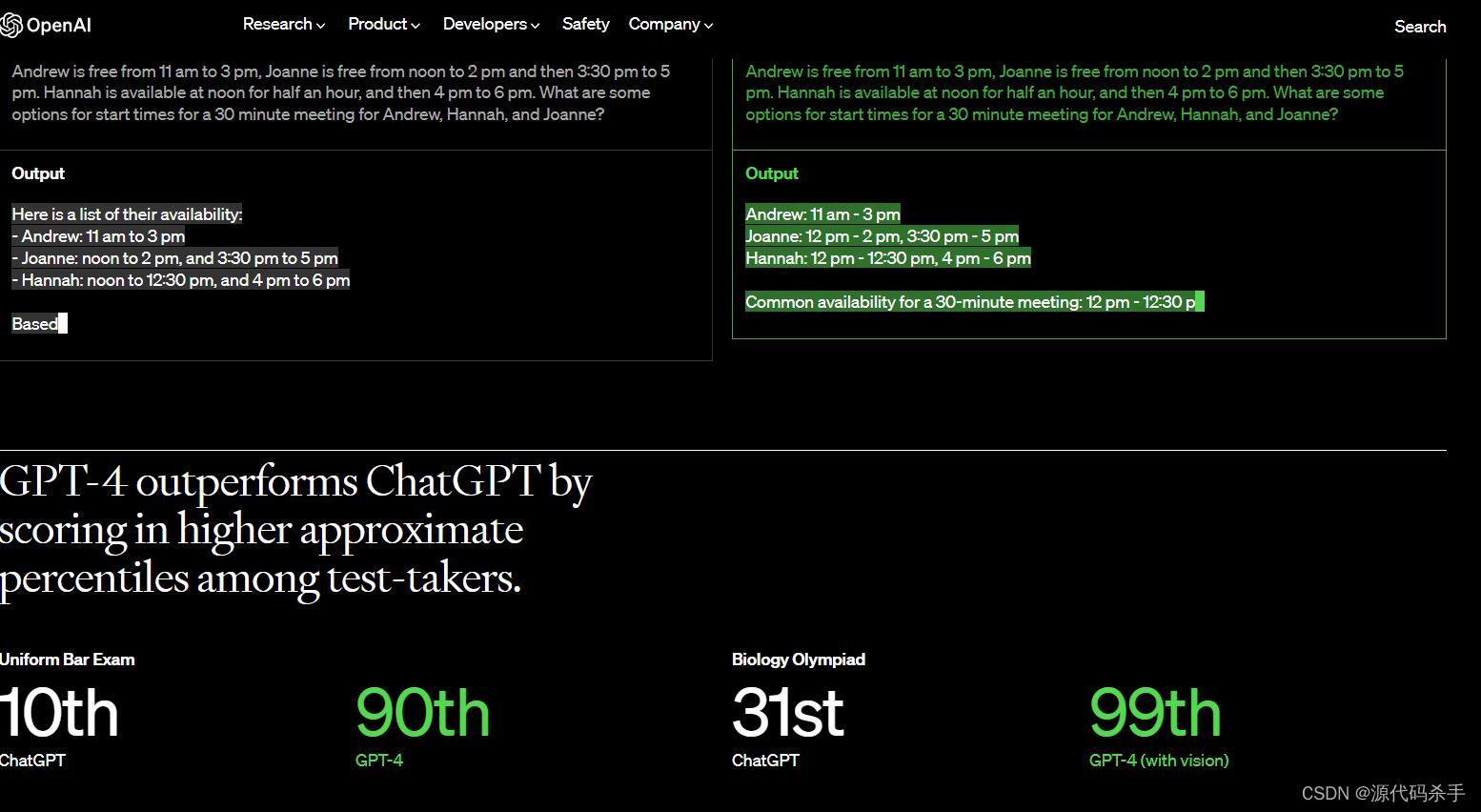
要使用OpenAI的微调技术来训练自己的专有模型,您需要遵循以下步骤:
获取和准备数据集:首先,您需要准备自己的数据集。可以使用公共数据集,也可以使用自己的数据集。数据集需要以特定格式(如JSONL)进行存储,并且需要经过清洗和预处理。
选择合适的模型和超参数:根据您的任务需求,选择合适的模型和超参数。例如,如果您的任务是文本分类,可以选择GPT或BERT等模型,并选择合适的学习率、批量大小等超参数。
安装OpenAI的API:您需要安装OpenAI的API并获得访问密钥,以便使用OpenAI的微调技术。您可以参考OpenAI API的文档来完成这一步。
编写微调脚本:您需要编写一个微调脚本,用于将您的数据集传递给OpenAI API,并使用它来微调您选择的模型。可以使用Python等编程语言来编写脚本。
执行微调:一旦您的微调脚本准备好,您可以运行它来启动微调过程。微调过程可能需要一段时间才能完成,具体取决于您的数据集大小和选择的模型。
评估和优化:一旦微调完成,您需要评估模型的性能,并根据需要进行优化。您可以使用评估指标,如准确率、F1得分等来评估模型性能,并调整模型超参数以获得更好的结果。
以下是使用OpenAI微调技术训练自己的专有模型的基本代码实现示例。这是一个Python脚本,假设您已经安装了OpenAI API并获得了访问密钥。这个示例假设您要使用GPT模型进行微调。
Pytorch Note56 Fine-tuning 通过微调进行迁移学习
Pytorch Note56 Fine-tuning 通过微调进行迁移学习
文章目录
全部笔记的汇总贴: Pytorch Note 快乐星球
通过微调进行迁移学习
前面我们介绍了如何训练卷积神经网络进行图像分类,可能你已经注意到了,训练一个卷积网络是特别耗费时间的,特别是一个比较深的卷积网络,而且可能因为训练方法不当导致训练不收敛的问题,就算训练好了网络,还有可能出现过拟合的问题,所以由此可见能够得到一个好的模型有多么困难。
有的时候,我们的数据集还特别少,这对于我们来讲无异于雪上加霜,因为少的数据集意味着非常高的风险过拟合,那么我们有没有办法在某种程度上避免这个问题呢?其实现在有一种方法特别流行,大家一直在使用,那就是微调(fine-tuning),在介绍微调之前,我们先介绍一个数据集 ImageNet。
ImageNet
ImageNet 是一个计算机视觉系统识别项目,是目前世界上最大的图像识别数据库,由斯坦福大学组织建立,大约有 1500 万张图片,2.2 万中类别,其中 ISLVRC 作为其子集是学术界中使用最为广泛的公开数据集,一共有 1281167 张图片作为训练集,50000 张图片作为验证集,一共是 1000 分类,是目前测试网络性能的标杆。
我们说的这个数据集有什么用呢?我们又不关心这个数据集,但是对于我们自己的问题,我们有没有办法借助 ImageNet 中的数据集来提升模型效果,比如我们要做一个猫狗分类器,但是我们现在只有几百张图片,肯定不够,ImageNet 中有很多关于猫狗的图片,我们如果能够把这些图片拿过来训练,不就能够提升模型性能了吗?
但是这种做法太麻烦了,从 ImageNet 中寻找这些图片就很困难,如果做另外一个问题又要去找新的图片,所以直接找图片并不靠谱,那么有没有办法能够让我们不去找这些图片,又能使用这些图片呢?
非常简单,我们可以使用在 ImageNet 上训练好的网路,然后把这个网络在放到我们自己的数据集上进行训练不就好了。这个方法就叫做微调,这十分形象,相当于把一个已经很厉害的模型再微调到我们自己的数据集上来,也可称为迁移学习。
迁移学习的方法非常简单,将预训练的模型导入,然后将最后的分类全连接层换成适合我们自己问题的全连接层,然后开始训练,可以固定卷积层的参数,也可以不固定进行训练,最后能够非常有效的得到结果
pytorch 一直为我们内置了前面我们讲过的那些著名网络的预训练模型,不需要我们自己去 ImageNet 上训练了,模型都在 torchvision.models 里面,比如我们想使用预训练的 50 层 resnet,就可以用 torchvision.models.resnet50(pretrained=True) 来得到
下面我们用一个例子来演示一些微调
import sys
sys.path.append('..')
import numpy as np
import torch
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import models
from torchvision import transforms as tfs
from torchvision.datasets import ImageFolder
首先我们点击下面的链接获得数据集,终端可以使用
wget https://download.pytorch.org/tutorial/hymenoptera_data.zip
下载完成之后,我们将其解压放在程序的目录下,这是一个二分类问题,区分蚂蚁和蜜蜂
我们可以可视化一下图片,看看你能不能区分出他们来
import os
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
root_path = './hymenoptera_data/train/'
im_list = [os.path.join(root_path, 'ants', i) for i in os.listdir(root_path + 'ants')[:4]]
im_list += [os.path.join(root_path, 'bees', i) for i in os.listdir(root_path + 'bees')[:5]]
nrows = 3
ncols = 3
figsize = (8, 8)
_, figs = plt.subplots(nrows, ncols, figsize=figsize)
for i in range(nrows):
for j in range(ncols):
figs[i][j].imshow(Image.open(im_list[nrows*i+j]))
figs[i][j].axes.get_xaxis().set_visible(False)
figs[i][j].axes.get_yaxis().set_visible(False)
plt.show()

定义数据预处理
# 定义数据预处理
train_tf = tfs.Compose([
tfs.RandomResizedCrop(224),
tfs.RandomHorizontalFlip(),
tfs.ToTensor(),
tfs.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 使用 ImageNet 的均值和方差
])
valid_tf = tfs.Compose([
tfs.Resize(256),
tfs.CenterCrop(224),
tfs.ToTensor(),
tfs.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 使用 ImageFolder 定义数据集
train_set = ImageFolder('./hymenoptera_data/train/', train_tf)
valid_set = ImageFolder('./hymenoptera_data/val/', valid_tf)
# 使用 DataLoader 定义迭代器
train_data = DataLoader(train_set, 25, True, num_workers=4)
valid_data = DataLoader(valid_set, 32, False, num_workers=4)
使用预训练的模型
# 使用预训练的模型
net = models.resnet50(pretrained=True)
print(net)
ResNet( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): Bottleneck( (conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (layer2): Sequential( (0): Bottleneck( (conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (3): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1)预训练(pre-training/trained)与微调(fine-tuning)