利用GPT-3 Fine-tunes训练专属语言模型
Posted JarodYv
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用GPT-3 Fine-tunes训练专属语言模型相关的知识,希望对你有一定的参考价值。
利用GPT-3 Fine-tunes训练专属语言模型

文章目录
什么是模型微调(fine-tuning)?
ChatGPT已经使用来自互联网的海量开放数据进行了预训练,对于任何输入都可以给出通用回答。如果我们想让ChatGPT的回答更有针对性,我们可以在输入时给出示例,ChatGPT可以通过“示例学习”(few-shot learning)理解你希望它完成的任务,并产生类似的合理输出。
但是“示例学习”每次需要给出示例,使用起来很不方便。微调(fine-tuning)可以通过训练更多示例来改进“短学习”,使用微调后的模型将不再需要在输入中提供示例。 这样既可以节约成本又可以实现更低延迟的请求。
更重要的是,对于一些专业场景,预训练模型可能无法达到理想的输出效果。此时需要我们给出更加具体和对口的数据对模型进行专门的强化,使其能够更好地回答该领域的问题,从而提升整体效果。
简而言之,微调允许我们将自定义数据集与大型语言模型(LLM)相匹配,让模型在我们的特定任务场景下依然表现良好。
为什么需要模型微调?
微调 vs 重新训练
这里有必要区分一下微调(fine-tuning) 和 重新训练(re-training) 的概念。
简单地说,重新训练是用新数据从头开始训练模型,而微调是用新数据调整先前训练模型的参数。
针对特定任务场景,微调比重新训练无论从时间还是费用上都更快更经济。
从头重新训练GPT-3 或 ChatGPT成本高的惊人。据估算,GPT-3一次训练的成本大约140万美元,ChatGPT模型更大,一次训练大约需要1200万美元。这还不包括上万颗A100GPU的成本。一块Nvidia A100 80G显存显卡按5万计算,1万块A100显卡光初始费用就5个小目标!很少有企业能够负担得起这么巨大的软硬件支出。
在GPT-3上微调也有成本,以功能最强的Davinci为例,训练成本0.03美元/1千token,这个成本相比重新训练天壤之别。下图是微调模型的训练和使用成本:
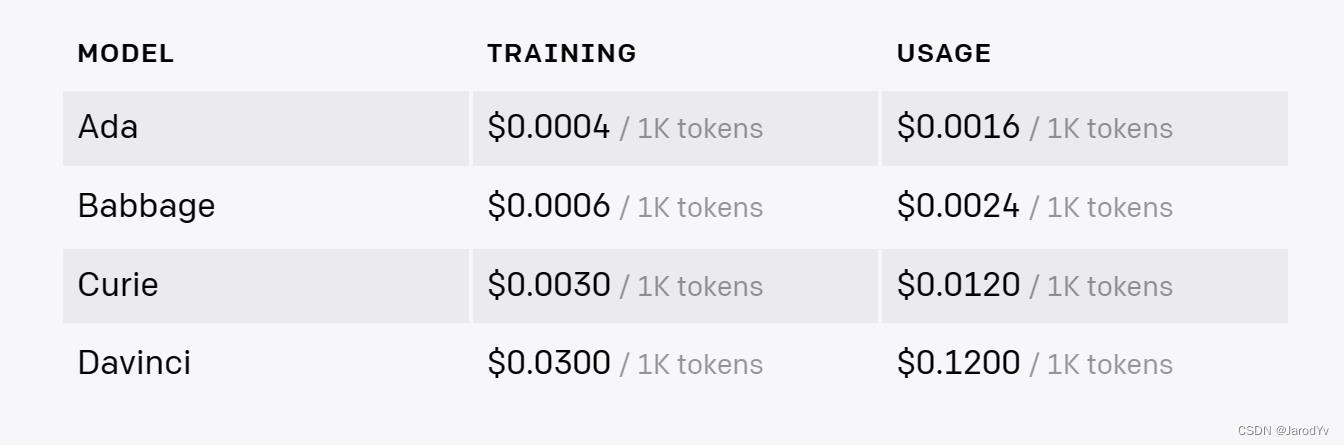
所以目前对大多数企业来说,只适合在GPT-3上做微调,除了少数巨头,绝大多数企业都没实力和能力重新训练。
微调 vs 提示设计
GPT-3支持“示例学习”(few-shot learning),我们可以通过在输入prompt时给予示例来提升模型输出效果,但提升效果远不如微调的效果,下面是微调和提示设计的效果对比:
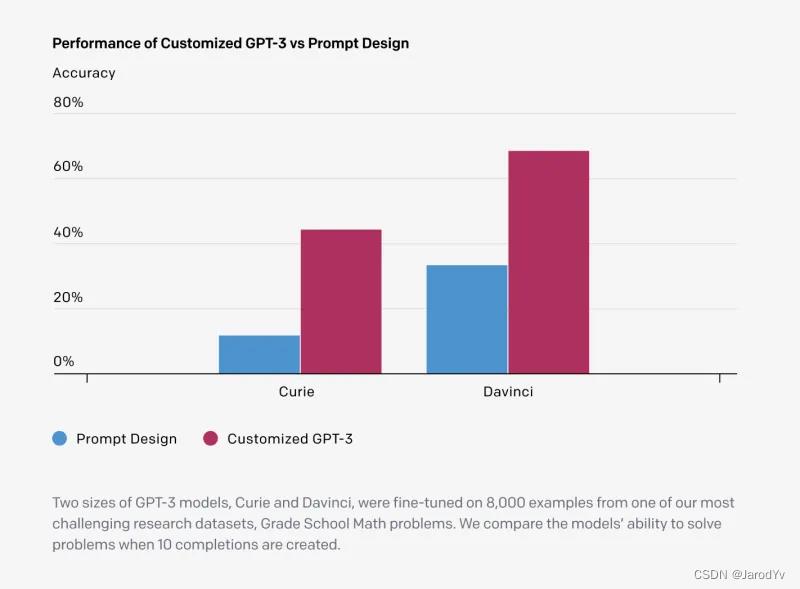
对比提示设计,微调模型可以获得如下优势:
- 更好的输出效果
- 比示例学习更多的训练数据
- 减少token消耗从而节约成本
- 请求延迟更低
训练专属模型
可以通过以下6个主要步骤开始创建微调模型。为了方便大家理解,我会结合我们在GPT-3上定制客服机器人的Python代码来演示微调过程。
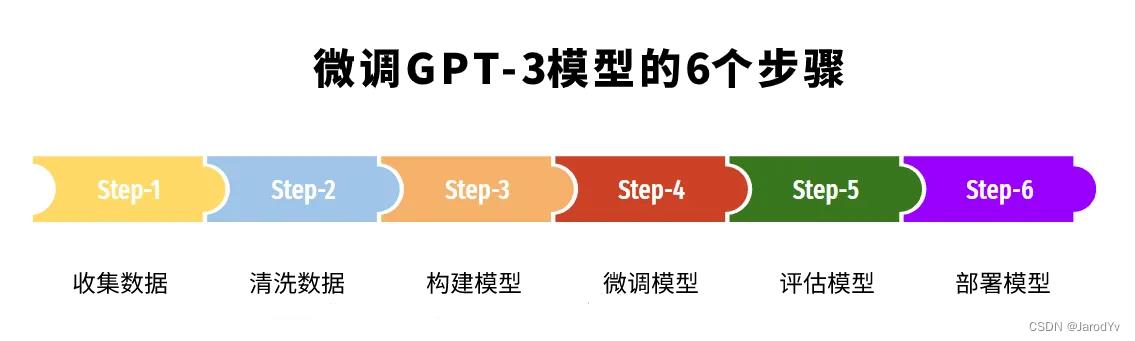
数据准备
GPT-3微调需要的数据格式是专属JSONL格式,形式如下:
"prompt": "<prompt text>", "completion": "<ideal generated text>"
"prompt": "<prompt text>", "completion": "<ideal generated text>"
"prompt": "<prompt text>", "completion": "<ideal generated text>"
上面的数据格式很好理解——每行都包含一个prompt和一个completion,表示特定提示对应的理想文本。
我们日常系统中的数据一般不会保存为JSONL格式,因此需要先将数据转换为JSONL格式。OpenAI提供了命令行工具来帮我们将常见数据格式转化为JSONL格式,用法如下:
openai tools fine_tunes.prepare_data -f <LOCAL_FILE>
其中<LOCAL_FILE>传入本地数据文件,支持CSV、TSV、XLSX、JSON 和 JSONL格式,只要文件中的数据格式是包含 prompt 和 completion 列或关键字就行。
数据准备阶段大家经常问的一个问题是*“我要准备多少数据用于微调才够?”*。通常来说,自然是“多多益善”,但由于微调设计训练成本,我们需要从中取得一个平衡。Open AI建议至少提供150–200个微调示例,但我个人在实际项目中发现150-200个微调示例往往不够,建议先从几百到一千条数据作为起始测试,根据微调后的模型效果再决定是否追加更多训练数据。
GPT-3支持自定义模型的持续微调,因此你可以随时用新数据在之前微调的模型上做进一步微调。
清洗数据
相比数据数量,数据质量更为关键。
GPT-3本质上是一个大型神经网络,它对我们来说是一个黑盒。所以它是典型的“garbage in, garbage out”,模型输出质量与训练数据质量有着直接的关系。
数据质量和多样性越高,模型就会工作得越好。通常需要一组不同的示例,以确保模型能够很好地泛化到新的示例。最好能够提供一个正面示例和负面示例,以确保模型能够处理各种输入。
为了验证微调模型质量,我们通常会将数拆分为训练集和验证集,通常按照 80 % / 20 % 80\\%/20\\% 80%/20%的比例进行拆分。
⚠注意:除JSONL格式外,训练数据和验证数据文件必须是UTF-8编码,并包含字节顺序标记(BOM),文件大小不能超过200MB。
构建模型
微调数据准备好后,我们就协议开始着手微调模型了。在开始微调训练之前,我们需要先确定微调的基础模型。
每个微调工作都从一个基础模型开始,默认为curie。基础模型不同会影响模型的性能和微调模型的成本。目前支持微调的基础模型包括:ada、babbage、curie或davinci。
下面是用Python完成模型构建:
import openai
openai.api_key = "YOUR_API_KEY"
resp = openai.FineTune.create(training_file="training_file_path",
validation_file="validation_file_path",
check_if_files_exist=True,
model="davinci")
job_id = resp["id"]
status = resp["status"]
print(f'微调任务ID: job_id,状态: status\\n')
上面的代码选择davinci作为基础模型,并传入了训练集和验证集的本地文件路径,创建微调任务。如果创建成功,则会返回微调任务的id及状态。
创建微调任务还支持其他参数,说明如下:
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
training_file | string | 训练集文件路径,必须是JSONL格式 | |
validation_file | string | null | 验证集文件路径,必须是JSONL格式 如果提供,则在微调期间,定期生成验证度量。这些指标可以在微调结果文件中查看。 训练集数据与验证集数据必须互斥。 |
check_if_files_exist | boolean | true | 是否检验文件是否存在 |
model | string | curie | 要微调的基础模型的名称。可以选择ada、babbage、curie、davinci或2022-04-21之后创建的微调模型。 |
n_epochs | int | 4 | 训练几轮。 |
batch_size | int | null | 训练的批次大小。默认情况下,批次大小将动态配置为训练集样本数的约0.2%,上限为256。通常来说较大的批次大小对于较大的数据集更有效。 |
learning_rate_multiplier | float | null | 学习率系数。微调学习率=预训练的原始学习率乘以该值。 默认情况下,学习率系数为0.05、0.1或0.2,具体取决于最终批次大小(较大的学习率往往在较大的批次大小下表现更好)。我们建议使用0.02到0.2范围内的值进行实验,以查看产生最佳结果的方法。 |
prompt_loss_weight | float | 0.01 | 提示损失权重。控制模型学习生成提示(生成输出的权重为1),并增加输出较短时训练的稳定性。 如果提示非常长(相对于输出),那么减少这个权重可以避免过度学习。 |
compute_classification_metrics | boolean | false | 如果为true,则在每轮训练结束时使用验证集计算效果,例如准确度和F-1 score 。这些指标可以在结果文件中查看。 |
classification_n_classes | int | null | 分类任务中的类别数。 多类别分类需要此参数。 |
classification_positive_class | string | null | 二分类任务中的正例。 在进行二分类时,需要此参数来生成精度、召回率和F1 score 。 |
classification_betas | array | null | 如果提供,将按照指定的beta值计算F-beta分数。F-beta是F-1的概括。仅用于二分类任务。 beta为1(即F-1分数)时,准确率和召回率的权重相同。beta越大,召回率的权重越大,准确率的权重越小。beta分数越小,准确率权重越高,召回率权重越低。 |
suffix | string | null | 最多40个字符的字符串,将添加到微调后的模型名称中。 |
微调模型
微调任务创建之后通常处于Pending状态,这是因为OpenAI系统中通常有其他任务排在你之前,我们的任务会先放在队列中,等待被处理。一般来说一旦进入训练状态,微调训练可能需要几分钟或几小时,具体取决于选择的基础模型和数据集的大小。我们可以用微调任务id来查询微调任务的状态:
while status not in ["succeeded", "failed"]:
time.sleep(2)
# 获取微调任务的状态
status = openai.FineTune.retrieve(id=job_id)["status"]
print(f'微调任务ID: job_id,状态: status')
print(f'微调任务ID: job_id 完成, 结束状态: status\\n')
评估模型
微调成功后都会有训练结果输出,可以通过如下代码获取评估结果:
fine_tune = openai.FineTune.retrieve(id=job_id)
result_files = fine_tune.get("result_files", [])
if result_files:
result_file = result_files[0]
resp = openai.File.download(id=result_file["id"])
print(resp.decode("utf-8"))
这里有丰富的模型评估数据,供我们对模型微调质量进行评估。
部署模型
如果模型效果满意,我们就可以将模型投入生产使用了。openai.FineTune.retrieve()方法返回的数据结构中的fine_tuned_model就是微调后的模型名称。可以直接拿这个模型名称在API中使用。
model_name = openai.FineTune.retrieve(id=job_id)["fine_tuned_model"]
response = openai.Completion.create(
model=model_name,
prompt="今天晚上吃什么好呢?\\n",
temperature=0.7,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=["END"]
)
总结
ChatGPT最让人惊艳的一点,就在于能够像人一样去对话。这种流畅的人机对话背后所展现的强大的自然语言理解力和表达力,目前只表现在通用领域。一旦进入某个专业领域,ChatGPT经常会“一本正经,胡说八道”。此时用特定领域的知识对模型进行微调是时间成本和经济成本最高的解决方案。事实证明,哪怕是最小的训练数据,也会带来明显的表现提升。
未来随着LLM变得更大、更易访问和开源,相信在不久的将来,我们可以看到微调在自然语言处理中无处不在。同时我也非常期待边缘学习的突破,可以将大模型训练的成本降下来,那时我们再来看如何从头重新训练一个大模型。
预训练语言模型整理(ELMo/GPT/BERT...)
排列语言模型(Permutation Language Model,PLM)#
对Embedding因式分解(Factorized embedding parameterization)#
跨层参数共享(Cross-layer parameter sharing)#
句间连贯性损失(Inter-sentence coherence loss)#
简介
2018年ELMo/GPT/BERT的相继提出,不断刷新了各大NLP任务排行榜,自此,NLP终于找到了一种方法,可以像计算机视觉那样进行迁移学习,被誉为NLP新时代的开端。
与计算机视觉领域预训练模型不同的是,其通过采用自监督学习的方法,将大量的无监督文本送入到模型中进行学习,即可得到通用的预训练模型,而NLP领域中无监督文本数据要多少有多少,2019年发布的后续研究工作(GPT2、Roberta、T5等)表明,采用更大的数据、更强大的炼丹炉可以不断提高模型性能表现,至少目前看来还没有达到上限。同时,如何缩减模型参数也成为了另一个研究热点,并有相应的论文在今年发表(ALBERT、ELECTRA)。这一类工作为NLP研发者趟通并指明了一条光明大道:就是通过自监督学习,把大量非监督的文本充分利用起来,并将其中的语言知识编码,对各种下游NLP任务产生巨大的积极作用。
为何预训练语言模型能够达到如此好的效果?主要有如下几点:
- word2vec等词向量模型训练出来的都是静态的词向量,即同一个词,在任何的上下文当中,其向量表征是相同的,显然,这样的一种词向量是无法体现一个词在不同语境中的不同含义的。
- 我们采用预训练模型来代替词向量的关键在于,其能够更具上下文的不同,对上下文中的词提取符合其语境的词表征,该词表征向量为一个动态向量,即不同上下文输入预训练模型后,同一个词的词表征向量在两个上下文中的词表征是不同的。
本文将对一下几个模型进行简单的总结,主要关注点在于各大模型的主要结构,预训练任务,以及创新点: - ELMo
- GPT
- BERT
- BERT-wwm
- ERNIE_1.0
- XLNET
- ERNIE_2.0
- RoBERTa
- ALBERT
- ELECTRA
预训练任务简介#
总的来说,预训练模型包括两大类:自回归语言模型与自编码语言模型
自回归语言模型#
通过给定文本的上文,对当前字进行预测,训练过程要求对数似然函数最大化,即:

代表模型:ELMo/GPT1.0/GPT2.0/XLNet
优点:该模型对文本序列联合概率的密度估计进行建模,使得该模型更适用于一些生成类的NLP任务,因为这些任务在生成内容的时候就是从左到右的,这和自回归的模式天然匹配。
缺点:联合概率是按照文本序列从左至右进行计算的,因此无法得到包含上下文信息的双向特征表征;
自编码语言模型
BERT系列的模型为自编码语言模型,其通过随机mask掉一些单词,在训练过程中根据上下文对这些单词进行预测,使预测概率最大化,即

其本质为去噪自编码模型,加入的 [MASK] 即为噪声,模型对 [MASK] 进行预测即为去噪。
优点:能够利用上下文信息得到双向特征表示
缺点:其引入了独立性假设,即每个 [MASK] 之间是相互独立的,这使得该模型是对语言模型的联合概率的有偏估计;另外,由于预训练中 [MASK] 的存在,使得模型预训练阶段的数据与微调阶段的不匹配,使其难以直接用于生成任务。
预训练模型的简介与对比
ELMo
原文链接:Deep contextualized word representations
ELMo为一个典型的自回归预训练模型,其包括两个独立的单向LSTM实现的单向语言模型进行自回归预训练,不使用双向的LSTM进行编码的原因正是因为在预训练任务中,双向模型将提前看到上下文表征而对预测结果造成影响。因此,ELMo在本质上还是属于一个单向的语言模型,因为其只在一个方向上进行编码表征,只是将其拼接了而已
细节#
- 引入双向语言模型,其实是2个单向语言模型(前向和后向)的集成,这样做的原因在上一节已经解释过了,用共享词向量来进行预训练;
- 通过保存预训练好的2层biLSTM,提取每层的词表征用于下游任务;
ELMo的下游使用#
-
对于每一个字符,其每一层的ELMo表征均为输入词向量与该层的双向编码表征拼接而成,即:
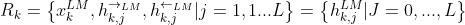
-
对于下游任务而言,我们需要把所有层的ELMo表征整合为一个单独的向量,最简单的方式是只用最上层的表征,而更一般的,我们采用对所有层的ELMo表征采取加权和的方式进行处理,即:

其中staskstask可以作为学习参数,为一个归一化的权重因子,用于表示每一层的词向量在整体的重要性。γtaskγtask为缩放参数,允许具体的task模型去放缩 ELMo 的大小,因为ELMo的表征分布与具体任务的表征分布不一定是一样的,可以将其作为一个辅助特征参数。
- 得到ELMo表征之后,则需要将其用于下游任务中去,注意,ELMo的微调过程中,并不是严格意义上的微调,预训练模型部分通常是固定的,不参与到后续训练当中。具体的,有以下几种操作方法:
- 方法一:直接将ELMo表征与词向量拼接,输入到下游任务当中去;
- 方法二:直接将ELMo表征与下游模型的输出层拼接
- 另外,还可以在ELMo模型中加入dropout, 以及采用 L2 loss的方法来提升模型。
GPT/GPT2#
GPT:Improving Language Understanding by Generative Pre-Training
GPT2:Language Models are Unsupervised Multitask Learners
GPT#
GPT是“Generative Pre-Training”的简称,从名字上就可以看出其是一个生成式的预训练模型,即与ELMo类似,是一个自回归语言模型。与ELMo不同的是,其采用多层Transformer Decoder作为特征抽取器,多项研究也表明,Transformer的特征抽取能力是强于LSTM的。
细节#
- 由于GPT仍然是一个生成式的语言模型,因此需要采用Mask Multi-Head Attention的方式来避免预测当前词的时候会看见之后的词,因此将其称为单向Transformer,这也是首次将Transformer应用于预训练模型,预测的方式就是将position-wise的前向反馈网络的输出直接送入分类器进行预测
- 此外整个GPT的训练包括预训练和微调两个部分,或者说,对于具体的下游任务,其模型结构也必须采用与预训练相同的结构,区别仅在于数据需要进行不同的处理
微调#
对于带有标签yy的监督数据[x1,...,xm][x1,...,xm],我们直接将其输入到已经完成预训练的模型中,然后利用最后一个位置的输出对标签进行预测,即

其中,WyWy为分类器的参数,hmlhlm为最后一层最后一个位置的输出。则最大化优化目标即为:
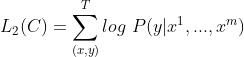
具体的,对于不同的微调任务,我们需要对数据进行如下处理:
GPT2#
GPT2 与 GPT 的大致模型框架和预训练目标是一致的,而区别主要在于以下几个方面:
- 其使用了更大的模型
- 使用了数量更大、质量更高、涵盖范围更广的预训练数据
- 采用了无监督多任务联合训练的方式,即对于输入样本,给予一个该样本所属的类别作为引导字符串,这使得该模型能够同时对多项任务进行联合训练,并增强模型的泛化能力
其他的就不深究了
优缺点#
BERT#
原文链接:BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding
BERT 的特征抽取结构为双向的 Transformer,简单来说,就直接套用了 Attention is all you need 中的 Transformer Encoder Block 结构,虽然相比于GPT,仅仅是从单向的变为双向的,但这也意味着 BERT 无法适用于自回归语言模型的预训练方式,因此,BERT提出了两种预训练任务来对其模型进行预训练。
BERT的预训练#
Task 1: MLM
由于BERT需要通过上下文信息,来预测中心词的信息,同时又不希望模型提前看见中心词的信息,因此提出了一种 Masked Language Model 的预训练方式,即随机从输入预料上 mask 掉一些单词,然后通过的上下文预测该单词,类似于一个完形填空任务。
在预训练任务中,15%的 Word Piece 会被mask,这15%的 Word Piece 中,80%的时候会直接替换为 [Mask] ,10%的时候将其替换为其它任意单词,10%的时候会保留原始Token
- 没有100%mask的原因
- 如果句子中的某个Token100%都会被mask掉,那么在fine-tuning的时候模型就会有一些没有见过的单词
- 加入10%随机token的原因
- Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token ’hairy‘
- 另外编码器不知道哪些词需要预测的,哪些词是错误的,因此被迫需要学习每一个token的表示向量
- 另外,每个batchsize只有15%的单词被mask的原因,是因为性能开销的问题,双向编码器比单项编码器训练要更慢
Task 2: NSP
仅仅一个MLM任务是不足以让 BERT 解决阅读理解等句子关系判断任务的,因此添加了额外的一个预训练任务,即 Next Sequence Prediction。
具体任务即为一个句子关系判断任务,即判断句子B是否是句子A的下文,如果是的话输出’IsNext‘,否则输出’NotNext‘。
训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。这个关系保存在图4中的[CLS]符号中
输入表征#
BERT的输入表征由三种Embedding求和而成:
- Token Embeddings:即传统的词向量层,每个输入样本的首字符需要设置为[CLS],可以用于之后的分类任务,若有两个不同的句子,需要用[SEP]分隔,且最后一个字符需要用[SEP]表示终止
- Segment Embeddings:为[0,1][0,1]序列,用来在NSP任务中区别两个句子,便于做句子关系判断任务
- Position Embeddings:与Transformer中的位置向量不同,BERT中的位置向量是直接训练出来的
Fine-tunninng#
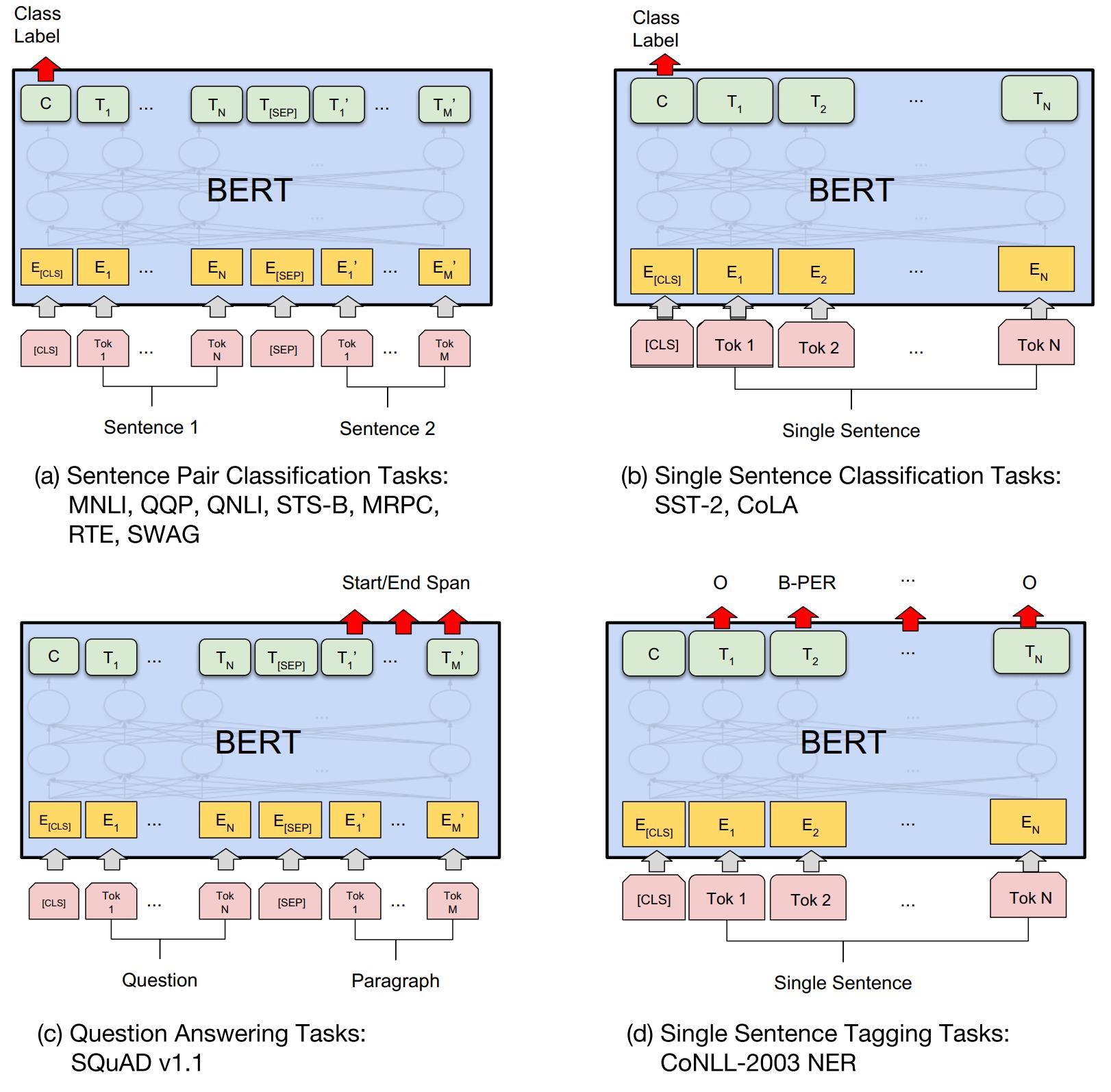
对于不同的下游任务,我们仅需要对BERT不同位置的输出进行处理即可,或者直接将BERT不同位置的输出直接输入到下游模型当中。具体的如下所示:
- 对于情感分析等单句分类任务,可以直接输入单个句子(不需要[SEP]分隔双句),将[CLS]的输出直接输入到分类器进行分类
- 对于句子对任务(句子关系判断任务),需要用[SEP]分隔两个句子输入到模型中,然后同样仅须将[CLS]的输出送到分类器进行分类
- 对于问答任务,将问题与答案拼接输入到BERT模型中,然后将答案位置的输出向量进行二分类并在句子方向上进行softmax(只需预测开始和结束位置即可)
- 对于命名实体识别任务,对每个位置的输出进行分类即可,如果将每个位置的输出作为特征输入到CRF将取得更好的效果。

缺点#
- BERT的预训练任务MLM使得能够借助上下文对序列进行编码,但同时也使得其预训练过程与中的数据与微调的数据不匹配,难以适应生成式任务
- 另外,BERT没有考虑预测[MASK]之间的相关性,是对语言模型联合概率的有偏估计
- 由于最大输入长度的限制,适合句子和段落级别的任务,不适用于文档级别的任务(如长文本分类);
- 适合处理自然语义理解类任务(NLU),而不适合自然语言生成类任务(NLG)
ELMo/GPT/BERT对比,其优缺点#
ELMo/GPT/BERT 均为在2018年提出的三个模型,且性能是依次提高的,这里将其放在一起对比,来看看这三者之间的主要区别有哪些
- ELMo 的特征提取器为LSTM,特征抽取能力明显较Transformer更弱,且并行能力较差
- ELMo/GPT 均为单向语言模型,即自回归语言模型,天生适合用于处理生成式任务,但这种特性也决定了无法提取上下文信息用于序列编码
- BERT采用双向Transformer作为特征抽取结构,能够有效提取上下文信息用于序列编码
BERT-wwm#
原文链接:Pre-Training with Whole Word Masking for Chinese BERT
Github链接:Pre-Training with Whole Word Masking for Chinese BERT(中文BERT-wwm系列模型)
Whole Word Masking (wwm),暂翻译为全词Mask或整词Mask,是哈工大讯飞联合实验室提出的BERT中文预训练模型的升级版本,主要更改了原预训练阶段的训练样本生成策略。 简单来说,原有基于WordPiece的分词方式会把一个完整的词切分成若干个子词,在生成训练样本时,这些被分开的子词会随机被mask。
在全词Mask中,如果一个完整的词的部分WordPiece子词被mask,则同属该词的其他部分也会被mask,即全词Mask。这样的做法强制模型预测整个的词,而不是词的一部分,即对同一个词不同字符的预测将使得其具有相同的上下文,这将加强同一个词不同字符之间的相关性,或者说引入了先验知识,使得BERT的独立性假设在同一个词的预测上被打破,但又保证了不同的词之间的独立性。
作者将全词Mask的方法应用在了中文中,使用了中文维基百科(包括简体和繁体)进行训练,并且使用了哈工大LTP作为分词工具,即对组成同一个词的汉字全部进行Mask。这样一个简单的改进,使得同样规模的模型,在中文数据上的表现获得了全方位的提升
RoBERTa#
从模型结构上看,RoBERTa基本没有什么太大创新,最主要的区别有如下几点:
- 移除了NSP这个预训练任务,效果变得更好
-
动态改变mask策略,把数据复制10份,然后统一进行随机mask;
-
其他的区别就在于学习率/数据量/batch_size 等
ERNIE(艾尼) 1.0#
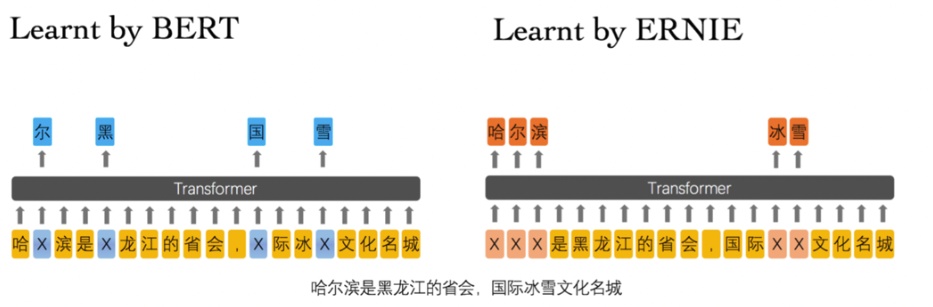
作者认为BERT在中文文本中的MLM预训练模型很容易使得模型提取到字搭配这种低层次的语义信息,而对于短语以及实体层次的语义信息抽取能力是较弱的。因此将外部知识引入大规模预训练语言模型中,提高在知识驱动任务上的性能。具体有如下三个层次的预训练任务:
- Basic-Level Masking: 跟bert一样对单字进行mask,很难学习到高层次的语义信息;
- Phrase-Level Masking: 输入仍然是单字级别的,mask连续短语;
- Entity-Level Masking: 首先进行实体识别,然后将识别出的实体进行mask。

ERNIE 2.0#
ERNIE 2.0相比于 1.0 来说,主要的改进在于采取 Multi-task learning(多任务同时学习,同时学习的任务数量逐渐增多)以及 Continue-Learning(不同任务组合轮番学习)的机制。其训练任务包括了三个级别的任务:
- 词级别:
- Knowledge Masking(短语Masking)
- Capitalization Prediction(大写预测)
- Token-Document Relation Prediction(词是否会出现在文档其他地方)
- 结构级别
- Sentence Reordering(句子排序分类)
- Sentence Distance(句子距离分类)
- 语义级别:
- Discourse Relation(句子语义关系)
- IR Relevance(句子检索相关性)
XLNet#
XLNet针对自回归语言模型单向编码以及BERT类自编码语言模型的有偏估计的缺点,提出了一种广义自回归语言预训练方法。
提出背景#
- 传统的语言模型(自回归语言模型AR天然适合处理生成任务,但是无法对双向上下文进行表征;
- 而自编码语言模型(AE)虽然可以实现双向上下文进行表征,但是:
- BERT系列模型引入独立性假设,没有考虑预测[MASK]之间的相关性;
- MLM预训练目标的设置造成预训练过程和生成过程不一致;
- 预训练时的[MASK]噪声在finetune阶段不会出现,造成两阶段不匹配问题;
- XLNet提出了一种排列语言模型(PLM),它综合了自回归模型和自编码模型的优点,同时避免他们的缺点
排列语言模型(Permutation Language Model,PLM)#
排列语言模型的思想就是在自回归和自编码的方式中间额外添加一个步骤,即可将两者完美统一起来,具体的就是希望语言模型从左往右预测下一个字符的时候,不仅要包含上文信息,同时也要能够提取到对应字符的下文信息,且不需要引入Mask符号。即在保证位置编码不变的情况下,将输入序列的顺序打乱,然后预测的顺序还是按照原始的位置编码顺序来预测的,但是相应的上下文就是按照打乱顺序的上下文来看了,这样以来,预测对象词的时候,可以随机的看到上文信息和下文信息。另外,假设序列长度为TT,则我们如果遍历T!T!种分解方法,并且模型参数是共享的,PLM就一定可以学习到预测词的所有上下文信息。但显然,遍历T!T!种上下文计算量是十分大的,XLNet采用的是一个部分预测的方法(Partial Prediction),为了减少计算量,作者只对随机排列后的末尾几个词进行预测,并使得如下期望最大化:
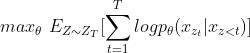
Two-Stream Self-Attention#
直接用标准的Transformer来建模PLM,会出现没有目标(target)位置信息的问题。即在打乱顺序之后,我们并不知道下一个要预测的词是一个什么词,这将导致用相同上文预测不同目标的概率是相同的。
XLNet引入了双流自注意力机制(Two-Stream Self-Attention)来解决这个问题。Two-Stream Self-Attention表明了其有两个分离的Self-Attention信息流:
- Query Stream 就为了找到需要预测的当前词,这个信息流的Self-Attention的Query输入是仅包含预测词的位置信息,而Key和Value为上下文中包含内容信息和位置信息的输入,表明我们无法看见预测词的内容信息,该信息是需要我们去预测的;
- Content Stream 主要为 Query Stream 提供其它词的内容向量,其Query输入为包含预测词的内容信息和位置信息,Value和Key的输入为选中上下文的位置信息和内容信息;
两个信息流的输出同样又作为对应的下一层的双信息流的输入。而随机排列机制实际上是在内部用Mask Attention的机制实现的。
 转存失败重新上传取消
转存失败重新上传取消
Transformer-XL#
Transformer-XL是 XLNet 的特征抽取结构,其相比于传统的Transformer能捕获更长距离的单词依赖关系。
原始的Transformer的主要缺点在于,其在语言建模中会受到固定长度上下文的限制,从而无法捕捉到更长远的信息。
Transformer-XL采用片段级递归机制(segment-level recurrence mechanism)和相对位置编码机制(relative positional encoding scheme)来对Transformer进行改进。
-
片段级递归机制:指的是当前时刻的隐藏信息在计算过程中,将通过循环递归的方式利用上一时刻较浅层的隐藏状态,这使得每次的计算将利用更大长度的上下文信息,大大增加了捕获长距离信息的能力。
-
相对位置编码:Transformer本身引入了三角函数向量作为位置编码向量。而Transformer-XL复用了上文的信息,这就导致位置编码出现重叠,因此采用了训练的方式得到相对位置编码向量。
ALBERT#
论文原文:ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
首先,论文作者提出,当我们让一个模型的参数变多的时候,一开始模型效果是提高的趋势,但一旦复杂到了一定的程度,接着再去增加参数反而会让效果降低,这个现象叫作模型退化(model degratation)。
因此ALBERT的主要创新点就在于,其提出了两种模型参数缩减的技术,使得在减小模型重量的同时,模型性能不会受到太大的影响。
对Embedding因式分解(Factorized embedding parameterization)#
在BERT中,Embedding层和隐藏层的维度大小是一致的,即E=HE=H。作者认为,词级别的Embedding是没有上下文依赖的表述,而隐藏层的需要对上下文的信息进行处理,因此相对来说隐藏层的维度应该相对来说更高一点,因此采用了一个因式分解的方式对Embedding层的矩阵进行压缩。简单来说,就是先将one-hot映射到一个低维空间EE,然后再将其从低维空间映射到高维空间HH,即参数量的变化为O(V×H)=>O(V×E+E×H)O(V×H)=>O(V×E+E×H),且论文也用实验证明,Embedding的参数缩减对整个模型的性能并没有太大的影响 转存失败重新上传取消
转存失败重新上传取消
跨层参数共享(Cross-layer parameter sharing)#
ALBERT借鉴了Universal Transformer中的参数共享机制来提高参数利用率,即多层使用同一个模块,从而可以使得参数量得到有效的减少。参数共享的对象为Transformer中的 feed-forward layer 参数和 self-attention 参数,默认方式是两者均共享。
由实验结果中可知,参数共享的操作可以大幅减少参数量,且模型性能的下降仍然是在可接受的范围。 转存失败重新上传取消
转存失败重新上传取消
句间连贯性损失(Inter-sentence coherence loss)#
之前的XLNet以及RoBERTa模型已经表明,NSP任务对模型的预训练并没有太大的帮助,主要原因是在于该任务的负例是从不想关的平行语料中提取的,这仅仅需要判断两个句子是否具有相同的主题就行了,并不是一个难度适当的任务。
ALBERT提出了一种新的预训练任务,即句间连贯性判断。正例样本是正常顺序的两段文本,而负例样本是将两段文本的顺序进行颠倒。这样的预训练任务就逼迫模型去学习这两个句子的语义,从而去进行相关的推断。相比于NSP任务更加巧妙。
ELECTRA#
未完待续...
参考链接
https://zhuanlan.zhihu.com/p/76912493
https://zhuanlan.zhihu.com/p/89894807
https://zhuanlan.zhihu.com/p/37684922
https://zhuanlan.zhihu.com/p/56865533
https://zhpmatrix.github.io/2019/02/16/transformer-multi-task/
https://zhuanlan.zhihu.com/p/57251615
https://zhuanlan.zhihu.com/p/68295881
https://www.zhihu.com/question/316140575
以上是关于利用GPT-3 Fine-tunes训练专属语言模型的主要内容,如果未能解决你的问题,请参考以下文章