RocketMQ 源码阅读 ---- 消息存储(普通消息)
Posted wenniuwuren
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RocketMQ 源码阅读 ---- 消息存储(普通消息)相关的知识,希望对你有一定的参考价值。
零、关键词解释 cache 是为了弥补高速设备和低速设备的鸿沟而引入的中间层,最终起到**加快访问速度**的作用。 buffer 的主要目的进行流量整形,把突发的大数量较小规模的 I/O 整理成平稳的小数量较大规模的 I/O,以**减少响应次数**(比如从网上下电影,你不能下一点点数据就写一下硬盘,而是积攒一定量的数据以后一整块一起写,不然硬盘都要被你玩坏了)。 -- 知乎 数据复制:当我们在某段代码中往某个文件写入一段字符串的时候,实际发生了什么呢?数据从 Application Memory 逐渐被复制到 Disk,中间会有多次数据复制 Application Memory -> Page Cache -> Disk 。读数据的时候,顺序反过来。 内存映射:内存映射( 即 Memory Map,简称 mmap 也被称为 zero-copy 技术) , 如 Java NIO 中 的 MappedByteBuffer 或者 MappedFileChannel 用的就是这项技术,它的作用其实就是不再使用应用层自己的内存空间(也就是用户空间的内存),直接操作 Page Cache 区域,减少了数据复制。 通俗解释,在应用这一层,是让你把文件的某一段,当作内存一样来访问。 Consumer 消费消息过程,使用了零拷贝,零拷贝包含以下两种方式 1. 使用 mmap + write 方式 优点:即使频繁调用,使用小块文件传输,效率也很高 缺点:不能很好的利用 DMA 方式,会比 sendfile 多消耗 CPU,内存安全性控制复杂,需要避免 JVM Crash 问题。 2. 使用 sendfile 方式 优点:可以利用 DMA 方式,消耗 CPU 较少,大块文件传输效率高,无内存安全新问题。 缺点:小块文件效率低于 mmap 方式,只能是 BIO 方式传输,不能使用 NIO。 RocketMQ 选择了第一种方式,mmap+write 方式,因为有小块数据传输的需求,效果会比 sendfile 更好。 一、前言 存储子系统的选择。理论上,从速度上,文件系统 > 分布式 KV (持久化的,MongoDB)> 分布式文件系统 > 数据库,而可靠性则相反。 诸如Kafka之类的消息中间件,在队列数上升时性能会产生巨大的损失,RocketMQ之所以能单机支持上万的持久化队列与其独特的 存储结构和 mmap 技术来实现。 分区(partition 对应 RocketMQ 的 queue)数量在Kafka中有什么作用? Producer(消息发送者)的往消息Server的写入并发数与分区数成正比。 Consumer(消息消费者)消费某个Topic的并行度与分区数保持一致,假设分区数是20,那么Consumer的消费并行度最大为20。 每个Topic由固定数量的分区数组成,分区数的多少决定了单台Broker能支持的Topic数量,Topic数量又决定了支持的业务数量。 为什么Kafka不能支持更多的分区数? 每个分区 存储了完整的消息数据,虽然每个分区写入是磁盘顺序写,但是多个分区同时顺序写入 在操作系统层面变为了随机写入。 由于数据分散为多个文件,很难利用IO层面的GroupCommit机制,网络传输也会用到类似优化算法。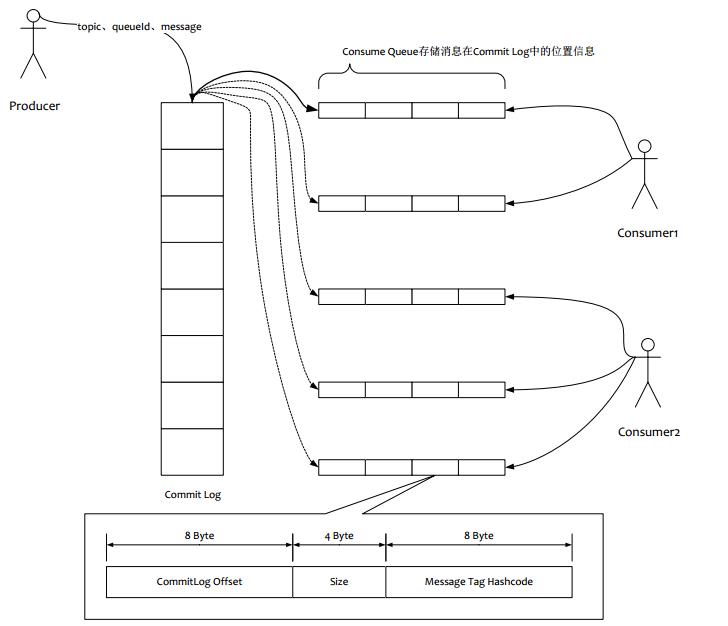 RocketMQ 存储架构
如上图所示,所有的消息数据单独存储到一个 Commit Log,
完全顺序写,随机读。对最终用户展现的队列(ConsumeQueue)实际只存储消息在 Commit Log 的
位置信息和 Tag 的 hashcode,并且串行方式刷盘。
顺序写高性能磁盘最高能到 600M/s,但是磁盘随机写的速度只有大概 100KB/ s,相差6000倍,所以存储方式和方法的选择会导致好几个数量级的队列性能差距。
架构优点:
RocketMQ 存储架构
如上图所示,所有的消息数据单独存储到一个 Commit Log,
完全顺序写,随机读。对最终用户展现的队列(ConsumeQueue)实际只存储消息在 Commit Log 的
位置信息和 Tag 的 hashcode,并且串行方式刷盘。
顺序写高性能磁盘最高能到 600M/s,但是磁盘随机写的速度只有大概 100KB/ s,相差6000倍,所以存储方式和方法的选择会导致好几个数量级的队列性能差距。
架构优点:
- 队列轻量化,单个队列数据非常少
- 对磁盘访问串行化,避免磁盘竞争,不会因为队列增加导致 IOWAIT 增加
- 写虽然是顺序写,但是读却变成了随机读
- 读一条消息先读 ConsumeQueue,再去找到对应 CommitLog 消息,多了一次读取操作
- 要保证 CommitLog 与 ConsumeQueue 完全一致,增加了编程复杂度
- 随机读,尽可能能去命中 Page Cache,减少读 IO 操作,所以内存越大越好。如果系统中堆积消息过多,读数据要访问磁盘会不会由于随机读导致系统性能急剧下降,答案是否定的
- 由于 ConsumeQueue 存储数据量极少,而且是顺序读,在 Page Cache 预读作用下,即使消息堆积,ComsumeQueue 的读取性能几乎与内存一致。所以可以认为 ConsumeQueue 完全不阻碍读性能。
- CommitLog 存储了所有元信息,包含消息体,类似于 mysql 的 binlog,所以只要有 CommitLog 在,ConsumeQueue 即使数据丢失,仍然可以恢复出来
 1、2、client 通过 Netty 发送消息的请求 invokeSync(addr, RemotingCommand, timeoutMillis) 在 NettyRemotingServer 的内部类 NettyServerHandler 服务端处理器接收
3、根据请求 code 从 HashMap<Integer/* request code */, Pair<NettyRequestProcessor, ExecutorService>> processorTable 内存(在 broker 启动的时候写入的对应关系)中拿到对应的处理类,比如现在是发送消息,所以 code=310 对应的是 SendMessageProcessor 处理类。
4、提取出请求头信息
5、响应信息 opaque 保持不变作为请求响应,这样客户端才能用这个跟原来发的请求对应起来。(dubbo 中叫 requestId、responseId 一个道理)
6、对 %RETRY% 类型的消息处理。
如果超过最大消费次数,则 topic 修改成"%DLQ%" + 分组名,即加入死信队列(Dead Letter Queue)
8 ~ 消息持久化到文件
RocketMQ 的消息存储与 Kafka 不同,RocketMQ 存储在 queue 的消息较为简洁,comsume queue 只是存消息的索引,而真正的消息在 commitlog 里面。
(1)ConsumeQueue 消息存储结构(可以理解为消息索引):
1、2、client 通过 Netty 发送消息的请求 invokeSync(addr, RemotingCommand, timeoutMillis) 在 NettyRemotingServer 的内部类 NettyServerHandler 服务端处理器接收
3、根据请求 code 从 HashMap<Integer/* request code */, Pair<NettyRequestProcessor, ExecutorService>> processorTable 内存(在 broker 启动的时候写入的对应关系)中拿到对应的处理类,比如现在是发送消息,所以 code=310 对应的是 SendMessageProcessor 处理类。
4、提取出请求头信息
5、响应信息 opaque 保持不变作为请求响应,这样客户端才能用这个跟原来发的请求对应起来。(dubbo 中叫 requestId、responseId 一个道理)
6、对 %RETRY% 类型的消息处理。
如果超过最大消费次数,则 topic 修改成"%DLQ%" + 分组名,即加入死信队列(Dead Letter Queue)
8 ~ 消息持久化到文件
RocketMQ 的消息存储与 Kafka 不同,RocketMQ 存储在 queue 的消息较为简洁,comsume queue 只是存消息的索引,而真正的消息在 commitlog 里面。
(1)ConsumeQueue 消息存储结构(可以理解为消息索引):
| 字段 | 描述 | 数据类型 | 字节 |
| offset | 这条消息在commitLog文件实际偏移量 | long | 8 |
| size | 消息大小 | int | 4 |
| tagsCode | 消息 tag 哈希值 | long | 8 |
- 同步,把消息主体存入到commitLog的同时把消息存入consumeQueue,RocketMQ 的早期版本就是这样处理的。
-
异步,起一个线程,不停的轮询,将当前的consumeQueue中的offSet和commitLog中的offSet进行对比,将多出来的offSet进行解析,然后put到consumeQueue中的MapedFile中(这就能提升写入性能)。

| 序号 | 字段 | 描述 | 数据类型 | 字节 |
| 1 | totalSize | 消息总大小 | int | 4 |
| 2 | magicCode | int | 4 | |
| 3 | bodyCRC | crc 校验码 | int | 4 |
| 4 | queueId | 队列 id | int | 4 |
| 5 | flag | 标志值rocketmq不做处理,只存储后透传 | int | 4 |
| 6 | queueOffset | 这个值是个自增值不是真正的 consume queue 的偏移量,可以代表这个队列中消息的个数,要通过这个值查找到 consume queue 中数据,QUEUEOFFSET * 20才是偏移地址 | long | 8 |
| 7 | physicOffset | 物理偏移量。即在 commitlog 文件中的存储位置 | long | 8 |
| 8 | sysFlag | 指明消息是事务等消息特征 | int | 4 |
| 9 | bornTimeStamp | 消息生产者生产消息时间 | long | 8 |
| 10 | BORNHOST | 消息生产者的 ip:port 信息 | long | 8 |
| 11 | STORETIMESTAMP | 消息存储在 broker 的时间 | long | 8 |
| 12 | STOREHOSTADDRESS | 消息存储在 broker 的地址 | long | 8 |
| 13 | RECONSUMETIMES | 消息被某个订阅组重新消费了几次(订阅组之间独立计数),因为重试消息发送到topic=%RETRY%groupName的队列queueId=0的队列中 | int | 4 |
| 14 | Prepared Transaction Offset | prepared状态的事物消息 | long | 8 |
| 15 | bodyLength | 前4个字节存放消息体大小值,后bodylength大小空间存储了消息体内容 | int | 4 + bodyLength |
| 16 | topicLength | 前面1个字节存放topic长度,后面存放topic | int | 1 + topicLength |
| 17 | propertiesLength | 前面2字节存放属性长度,后面存放属性数据 | int | 2 + propertiesLength |
| 方式 | 写入 | 落盘 |
| 方式一 | 写入内存字节缓冲区,direct 类型(writeBuffer) | 从内存字节缓冲区(wirteBuffer) commit 到 FileChannel【fileChannel.write(byteBuffer)】,fileChannel force到磁盘 |
| 方式二 | 写入映射文件字节缓冲区(mappedByteBuffer) | mappedByteBuffer force 到磁盘 |
| 后台服务 | 操作内容 | 性能 |
| CommitRealTimeService | 异步刷盘 && buff 由 linux 系统自动 flush 到磁盘 | 最好 |
| FlushRealTimeService | 异步刷盘 && buff 由应用 flush 到磁盘 | 中等 |
| GroupCommitService | 同步刷盘 | 最差 |
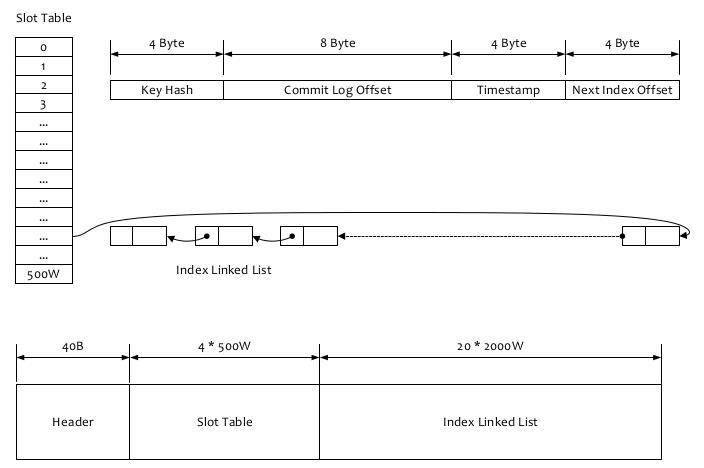 RocketMQ可以为每条消息指定Key,并根据建立高效的消息索引,索引逻辑结果如上图所示(PS:类似 HashMap 的索引),
查询过程如下:
1、根据查询的key的hashcode%slotNum得到具体的槽的位置(slotNum是一个索引文件里面包含的最大槽的数目,例如图中所示slotNum=500W)。
2、根据slotValue(slot位置对应的值)查找到索引项列表的最后一项(倒序排列,slotValue总是指向最新的一个索引项)。
3、遍历索引项列表返回查询时间范围内的结果集(默认一次最大返回的32条记录)
4、Hash冲突;寻找key的slot位置时相当于执行了两次散列函数,一次key的hash,一次key的hash值取模,因此这里存在两次冲突的情况;第一种,key的hash值不同但模数相同,此时查询的时候会在比较一次key的hash值(每个索引项保存了key的hash值),过滤掉hash值不相等的项。第二种,hash值相等但key不等,出于性能的考虑冲突的检测放到客户端处理(key的原始值是存储在消息文件中的,避免对数据文件的解析),客户端比较一次消息体的key是否相同。
5、存储;为了节省空间索引项中存储的时间是时间差值(存储时间-开始时间,开始时间存储在索引文件头中),整个索引文件是定长的,结构也是固定的 。
索引建立过程:
public boolean putKey(final String key, final long phyOffset, final long storeTimestamp)
if (this.indexHeader.getIndexCount() < this.indexNum) // 索引最大数量是 indexNum=2000W
int keyHash = indexKeyHashMethod(key); // 第一次散列。
int slotPos = keyHash % this.hashSlotNum; // 第二次散列。 hashSlotNum=500W key具体槽位。参看 1、根据查询的key的hashcode%slotNum得到具体的槽的位置
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize; // Slot 的位置。INDEX_HEADER_SIZE=40 hashSlotSize=4
FileLock fileLock = null;
try
// fileLock = this.fileChannel.lock(absSlotPos, hashSlotSize,
// false);
int slotValue = this.mappedByteBuffer.getInt(absSlotPos); // 拿到 slot 中的值
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount())
slotValue = invalidIndex;
long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
timeDiff = timeDiff / 1000;
if (this.indexHeader.getBeginTimestamp() <= 0)
timeDiff = 0;
else if (timeDiff > Integer.MAX_VALUE)
timeDiff = Integer.MAX_VALUE;
else if (timeDiff < 0)
timeDiff = 0;
// Index 在索引文件具体位置 indexSize=20
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ this.indexHeader.getIndexCount() * indexSize;
// 消息数据存放
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue); // 指向前一个节点
// 存入索引。 根据Message 的 Key 找到 absSlotPos和对应的value indexCount,根据 indexCount可以找到 absIndexPos 位置
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
if (this.indexHeader.getIndexCount() <= 1)
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
this.indexHeader.incHashSlotCount();
this.indexHeader.incIndexCount();
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);
return true;
catch (Exception e)
log.error("putKey exception, Key: " + key + " KeyHashCode: " + key.hashCode(), e);
finally
if (fileLock != null)
try
fileLock.release();
catch (IOException e)
log.error("Failed to release the lock", e);
RocketMQ可以为每条消息指定Key,并根据建立高效的消息索引,索引逻辑结果如上图所示(PS:类似 HashMap 的索引),
查询过程如下:
1、根据查询的key的hashcode%slotNum得到具体的槽的位置(slotNum是一个索引文件里面包含的最大槽的数目,例如图中所示slotNum=500W)。
2、根据slotValue(slot位置对应的值)查找到索引项列表的最后一项(倒序排列,slotValue总是指向最新的一个索引项)。
3、遍历索引项列表返回查询时间范围内的结果集(默认一次最大返回的32条记录)
4、Hash冲突;寻找key的slot位置时相当于执行了两次散列函数,一次key的hash,一次key的hash值取模,因此这里存在两次冲突的情况;第一种,key的hash值不同但模数相同,此时查询的时候会在比较一次key的hash值(每个索引项保存了key的hash值),过滤掉hash值不相等的项。第二种,hash值相等但key不等,出于性能的考虑冲突的检测放到客户端处理(key的原始值是存储在消息文件中的,避免对数据文件的解析),客户端比较一次消息体的key是否相同。
5、存储;为了节省空间索引项中存储的时间是时间差值(存储时间-开始时间,开始时间存储在索引文件头中),整个索引文件是定长的,结构也是固定的 。
索引建立过程:
public boolean putKey(final String key, final long phyOffset, final long storeTimestamp)
if (this.indexHeader.getIndexCount() < this.indexNum) // 索引最大数量是 indexNum=2000W
int keyHash = indexKeyHashMethod(key); // 第一次散列。
int slotPos = keyHash % this.hashSlotNum; // 第二次散列。 hashSlotNum=500W key具体槽位。参看 1、根据查询的key的hashcode%slotNum得到具体的槽的位置
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize; // Slot 的位置。INDEX_HEADER_SIZE=40 hashSlotSize=4
FileLock fileLock = null;
try
// fileLock = this.fileChannel.lock(absSlotPos, hashSlotSize,
// false);
int slotValue = this.mappedByteBuffer.getInt(absSlotPos); // 拿到 slot 中的值
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount())
slotValue = invalidIndex;
long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
timeDiff = timeDiff / 1000;
if (this.indexHeader.getBeginTimestamp() <= 0)
timeDiff = 0;
else if (timeDiff > Integer.MAX_VALUE)
timeDiff = Integer.MAX_VALUE;
else if (timeDiff < 0)
timeDiff = 0;
// Index 在索引文件具体位置 indexSize=20
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ this.indexHeader.getIndexCount() * indexSize;
// 消息数据存放
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue); // 指向前一个节点
// 存入索引。 根据Message 的 Key 找到 absSlotPos和对应的value indexCount,根据 indexCount可以找到 absIndexPos 位置
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
if (this.indexHeader.getIndexCount() <= 1)
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
this.indexHeader.incHashSlotCount();
this.indexHeader.incIndexCount();
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);
return true;
catch (Exception e)
log.error("putKey exception, Key: " + key + " KeyHashCode: " + key.hashCode(), e);
finally
if (fileLock != null)
try
fileLock.release();
catch (IOException e)
log.error("Failed to release the lock", e);
以上是关于RocketMQ 源码阅读 ---- 消息存储(普通消息)的主要内容,如果未能解决你的问题,请参考以下文章