kettle使用过程记录(详细)
Posted 菜鸟装大神
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kettle使用过程记录(详细)相关的知识,希望对你有一定的参考价值。
话不多说上干货
下载地址
https://sourceforge.net/projects/pentaho/files/
下载所需要的安装版本
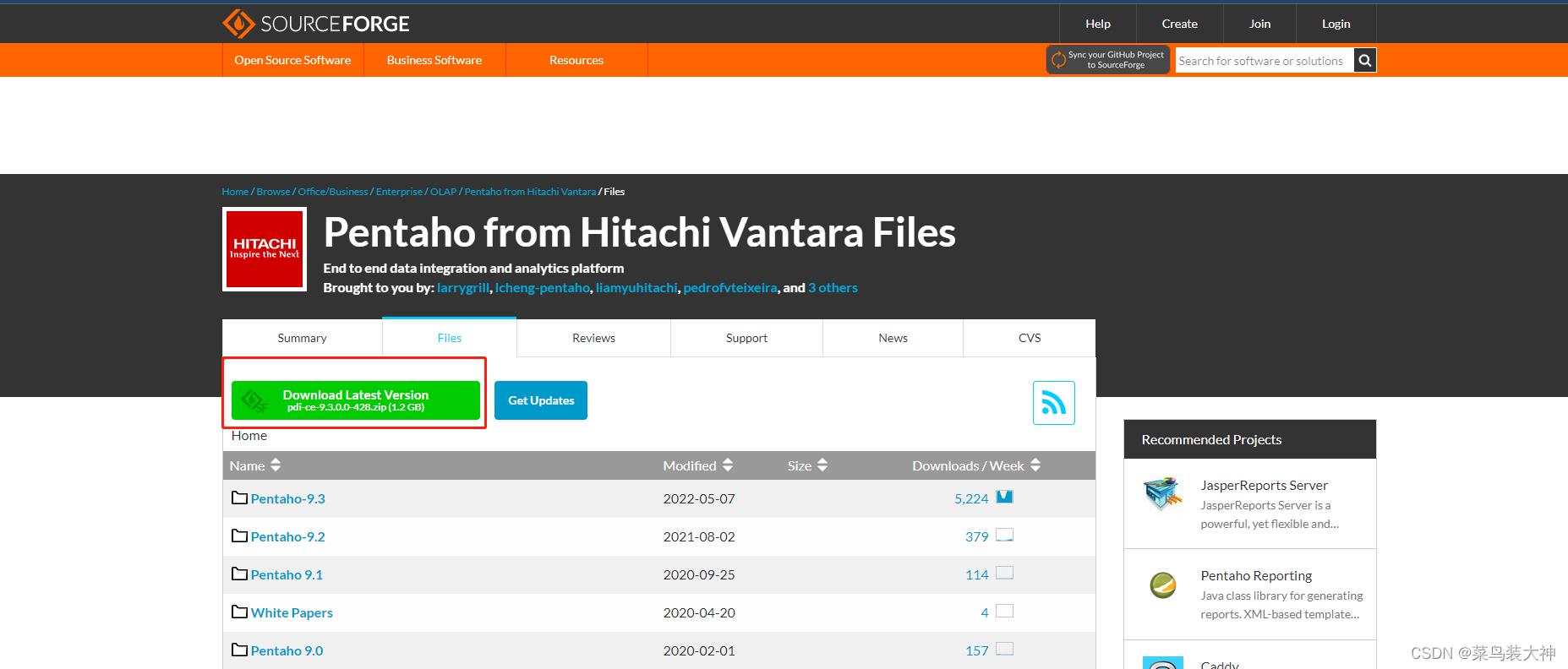
下载好后解压到本地 kettle是支持linux与windows的
windows安装解压后生成

这里需要注意 有的人说Spoon.bat配置中的参数不修改可能会出现卡死的状况,所以我也进行了修改(这里描述下 我并没有出现卡死的状况)
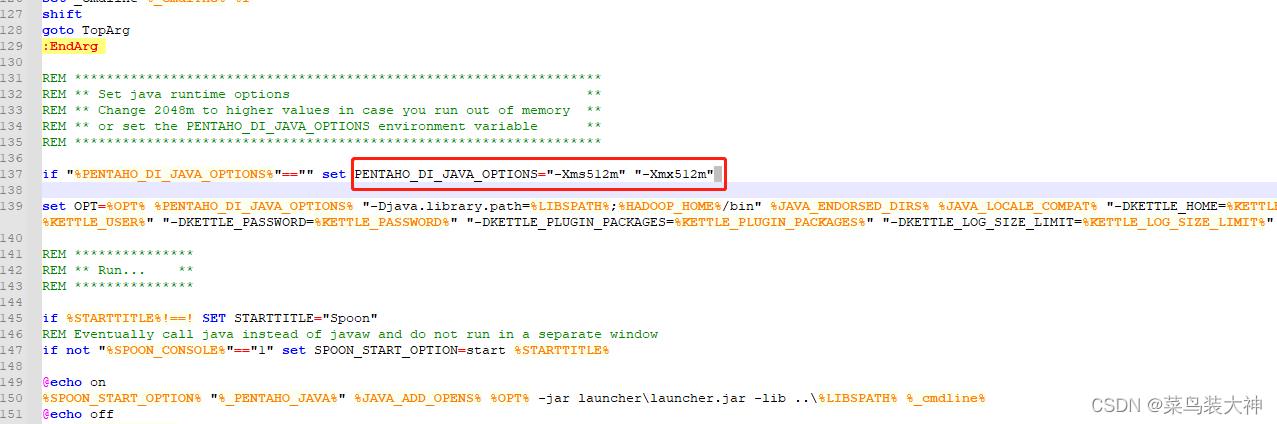
然后运行data-integration文件夹中的Spoon.bat

这时候就会启动
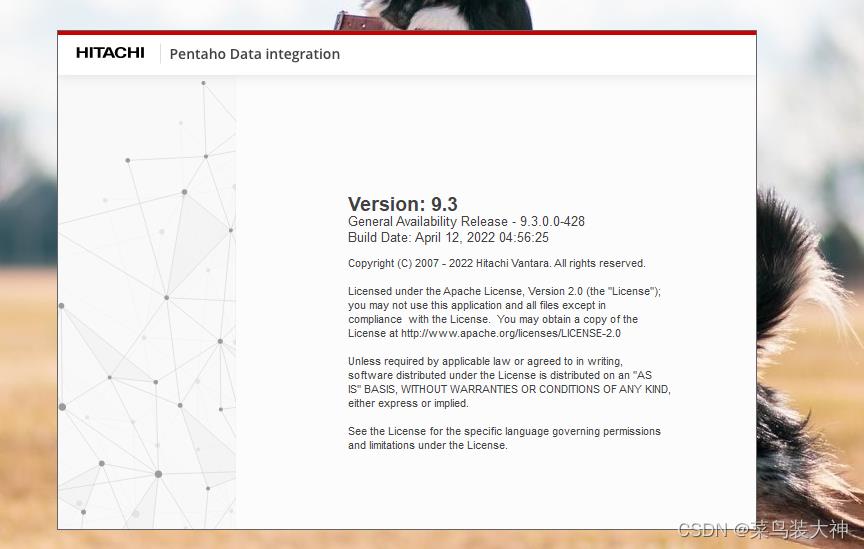
当然启动kettle后使用起来会出现常见的报错
创建连接数据库(mysql为例)
例如 :
Driver class 'org.gjt.mm.mysql.Driver' could not be found, make sure the 'MySQL' driver (jar file) is installed.
org.gjt.mm.mysql.Driver
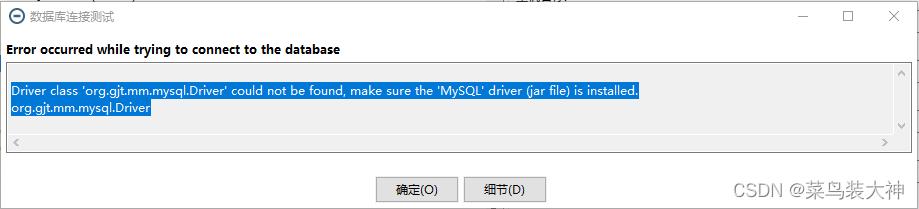
这个报错的原因是因为当前的kettle目录下没有需要连接的数据库驱动,所以我们需要下载一个驱动放到他的lib包里重新启动即可,我创建的是mysql连接所以需要mysql连接驱动,我选择的是
mysql-connector-java-8.0.28.jar

放入lib包下即可,这里可能有小伙伴找不到这个驱动所以我把下载方式也贴出来
MySQL :: Download MySQL Connector/J (Archived Versions)
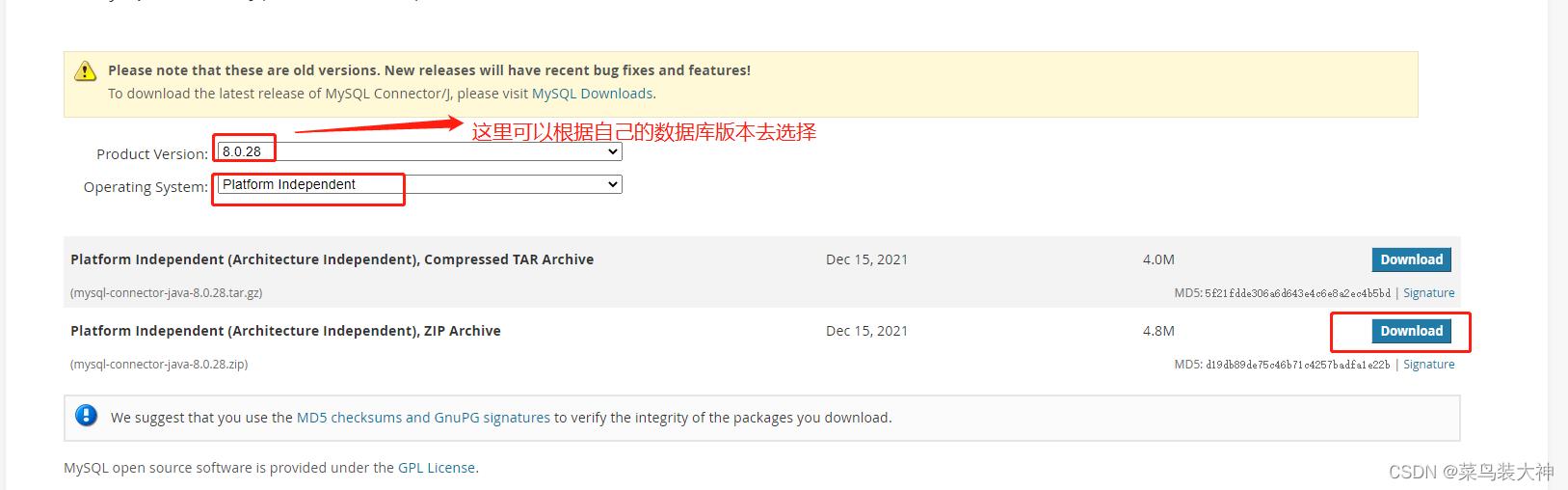
将下载好的jar解压放到\\data-integration\\lib\\的目录下就可以了
这是后去创建数据库连接 可能会报这样的错误
Connection failed. Verify all connection parameters and confirm that the appropriate driver is installed.
Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
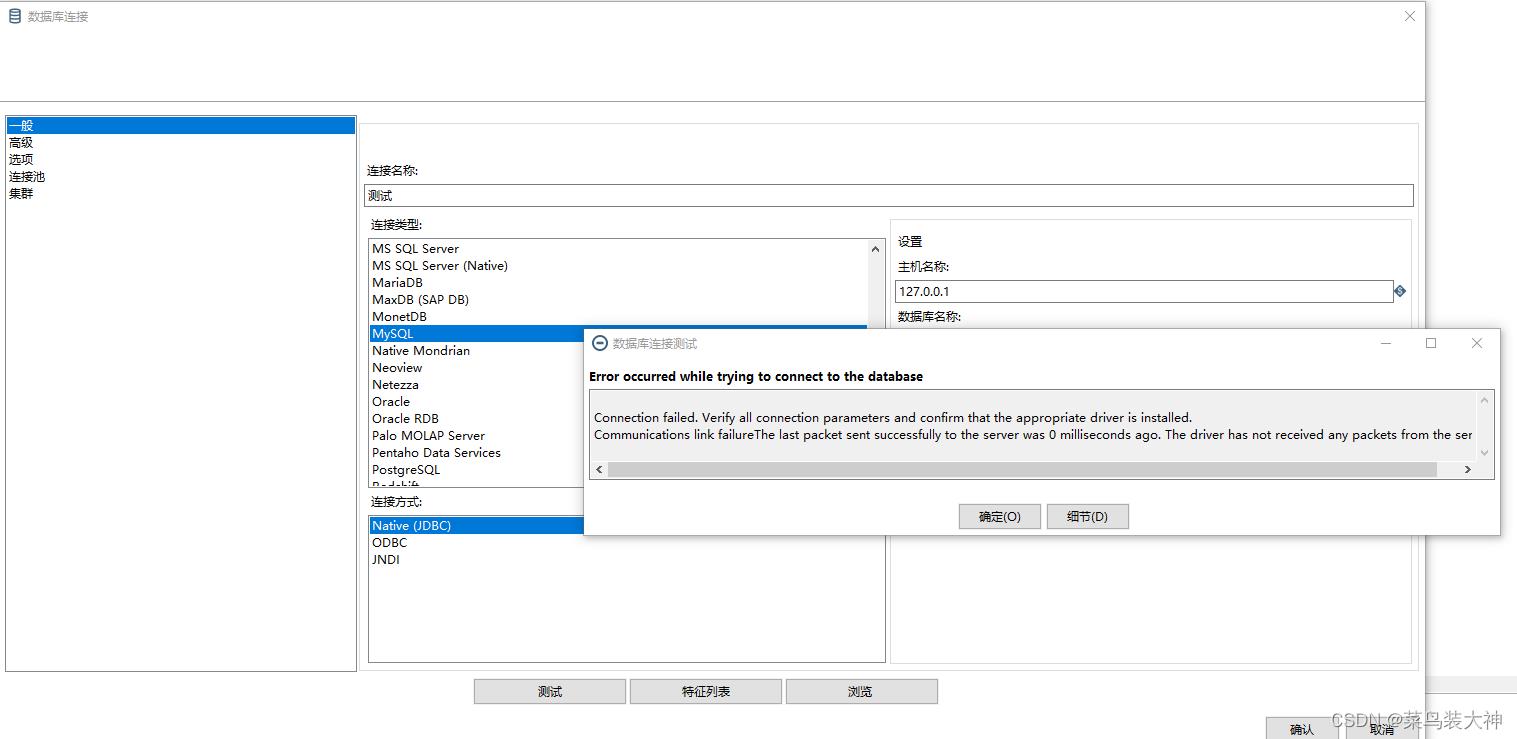
原因是因为没有选择相应的配置
在选项中新增useSSL=false即可

然后返回主页测试链接成功
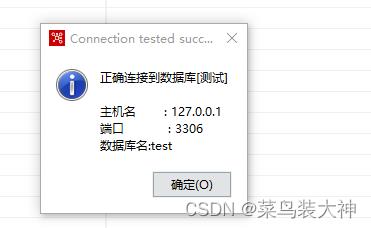
然后我们可以做一个小测试
创建一个输入表,创建一个输出表两个进行关联

原始数据可以用sql来指定你所需要筛选的内容,然后对应到你需要数据迁移的表中,表与表之间的字段必须两两对应
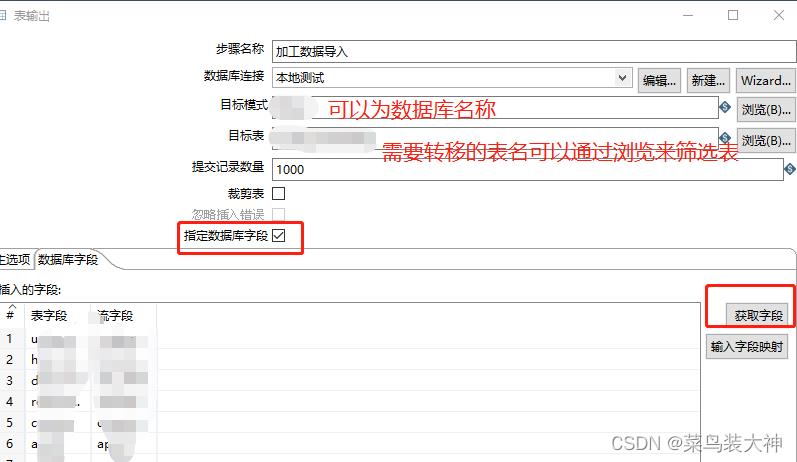
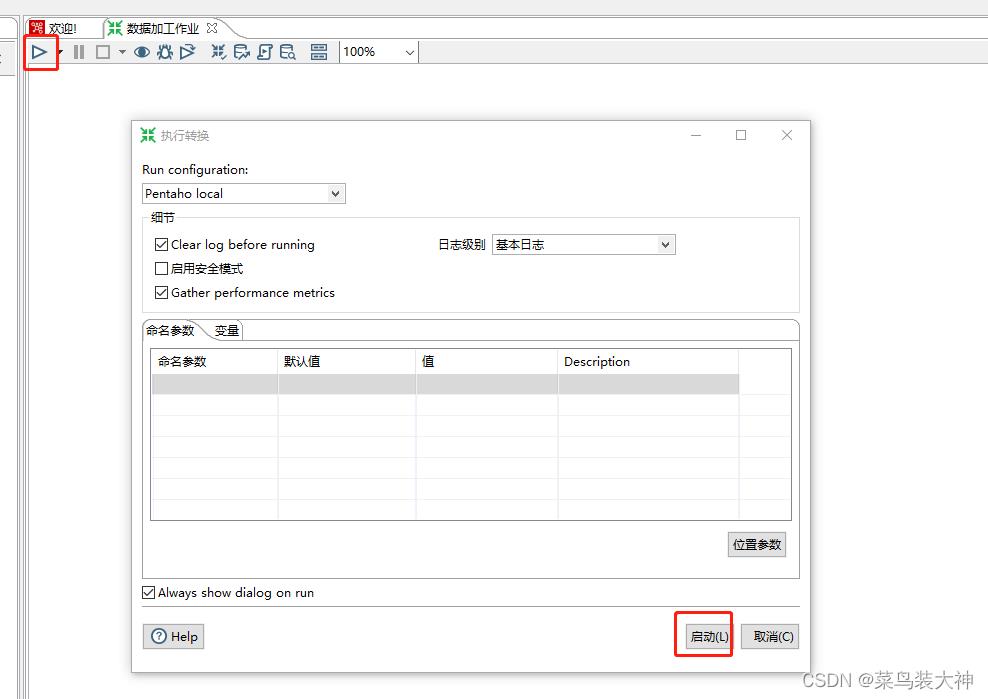
然后启动转化 生成一个转化文件保存好.ktr结尾
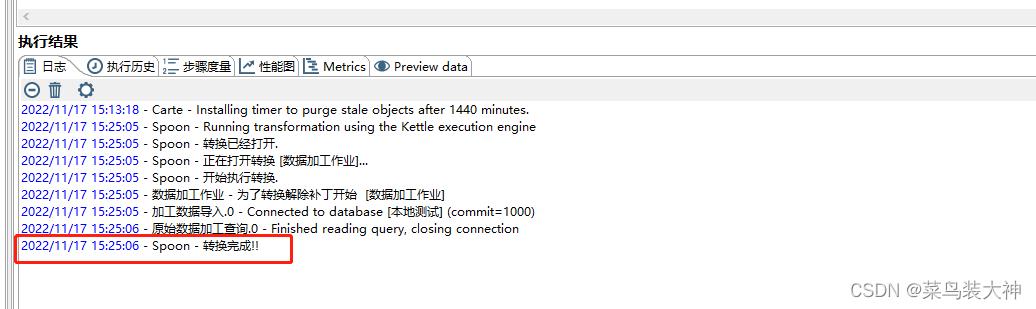
大概就是这样一个流程 ,然后去看你需要转移的表中数据是否新增成功就可以了。
以上就是在windows上的操作流程。
在linux上去操作同样简单
把我们之前下载好的安装包转移到所需要的目录下

记住 数据库连接驱动也要放在lib里面 否则会出问题。
然后进入 data-integration目录下给文件赋予权限
chmod 777 kitchen.sh
chmod 777 import.sh
chmod 777 spoon.sh然后在linux下启动kettle
./kitchen.sh
会出现这样的报错
报错java.lang.UnsatisfiedLinkError: Could not load SWT library. Reasons。
说明缺少可以加载lib包的环境,这也可能是导致无法读取到xml数据库配置的原因。
WARNING: no libwebkitgtk-1.0 detected, some features will be unavailable
Consider installing the package with apt-get or yum.
e.g. 'sudo apt-get install libwebkitgtk-1.0-0'
根据提示完成libwebkitgtk的安装。
在centos版本中使用的命令为:
yum install epel-release
yum install webkitgtk
或者手动下载
yum -y install gtk2.i686 gtk2-engines.i686 PackageKit-gtk-module.i686 PackageKit-gtk-module.x86_64 libcanberra-gtk2.x86_64 libcanberra-gtk2.i686然后继续执行./kitchen.sh
证明安装成功了
然后把你在windows上创建的转化拉到你的linux服务器上的相应位置上
在data-integration目录下执行
./pan.sh -file=/kettle/kjb/test.ktr然后去看你的数据库是否有新增 如果有的话 说明ktr也生效了 是ok的
那么接下来 假如你有一个场景是需要定时执行这个转化的 可以做一个.sh脚本
touch test.sh
vim test.sh
#!/bin/bash
export JAVA_HOME=/analysisTools/jdk1.8.0_261
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:/$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
TIME=$(date "+%Y%m%d")
/kettle/data-integration/pan.sh -file=/kettle/kjb/test.ktr >> /kettle/kettle.log &脚本中需要引入java环境变量
然后给你的脚本赋予执行权限
chmod 777 test.sh然后./test.sh执行,检查是否成功,成功则加入linux定时器
crontab -e
添加你的定时任务
#每天凌晨0点10分执行 10 0 * * *
10 0 * * * /bin/sh /kettle/test.sh然后重启定时器配置
systemctl reload crond.service //重新载入配置
systemctl status crond.service //查看状态这样就可以实现定时任务了
Kettle手册(六)- Hop小记
参考技术A 在我们前面,使用Kettle过程中,控件与控件之间的连线,这里,我们详细介绍下它,它在Kettle中叫Hop(跳)。在转换中,一般情况,控件和控件之间只有一个Hop,当然,如果需要的话,我们拖了2个控件出来,像这样:
Kettle会提示你,下面的信息,让你选择,数据发送的方式
目标步骤轮流接收记录,其实就是你一条,我一条,轮着接收数据,这个我们试一下就知道了,
我们执行下,看看这个结果试试,我们再步骤度量中,可以看到,a.txt和b.txt分别写入的数量
所有记录同时发送到所有的目标步骤,这个看起来就简单多了,比如上面的例子,2个文本文件会接收到同样的所有的数据,我们也试一下
结果文件的话,就是2个节点,接收到的数据都是一样的
在作业中,Hop主要用来控制流程
有3种状态,一个锁,一个绿色的对号,一个红色的叉号
简单来说,
以上是关于kettle使用过程记录(详细)的主要内容,如果未能解决你的问题,请参考以下文章