ETL工具之Kettle开发教程第一节-入门
Posted Elcker
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ETL工具之Kettle开发教程第一节-入门相关的知识,希望对你有一定的参考价值。
ETL简介
概念
ETL是数据抽取(Extract)、转换(Transform)、装载(Loading)的缩写。
数据抽取
数据抽取是指从数据源获取所需数据的过程。数据抽取过程会过滤掉目标数据集中不需要的源数据字段或数据记录。
数据抽取可以采用PULL和PUSH两种方式:
-
PUSH就是指由源系统按照双方定义的数据格式,主动将符合要求的数据抽取出来,形成接口数据表或数据视图供ETL系统使用。
-
PULL则是由ETL程序直接访问数据源来获取数据的方式。
数据转换
数据转换(Transform)是按照目标表的数据结构,对一个或多个源数据的字段进行翻译、匹配、聚合等操作得到目标数据的字段。
数据装载
把源数据通过数据转换目标数据,就可以直接通过数据加载工具加载到目标数据库中。
数据加载工作一般分为3步进行 :
-
Pre-Load:删除索引
-
Load :将转换后的源数据加载到目标数据库的表中
-
Post-Load:重新生成索引;清理临时文件
数据交互方式
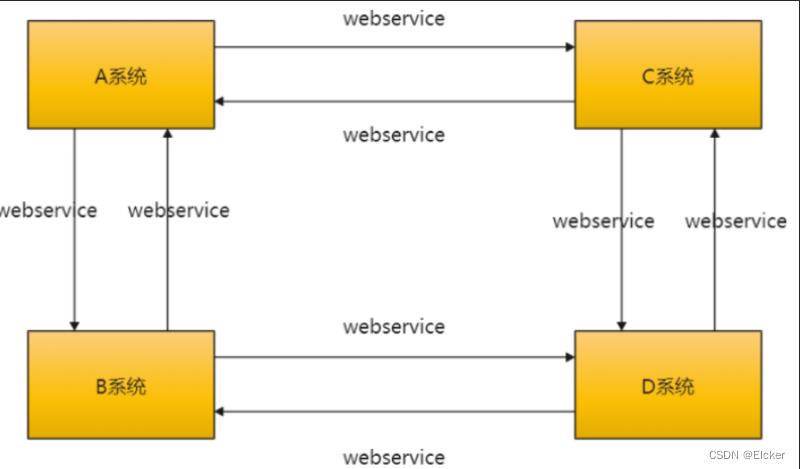
随着企业的发展,目前的业务线越来越复杂,各个业务系统独立运营。一旦业务系统之间进行数据交互,只能通过传统的webservice接口之间进行数据通信。该种方式对人力成本、时间成本要求比较高。也就是说:需要成熟的开发人员才能编写响应的
webservice 接口进行数据通信。而 ETL
的诞生就解决了此类问题,企业不需要技术很好、很成熟的开发人员一样可以完成该任务。而且可以比优秀的开发人员完成的更好,致使人力成本更低。这些都是企业所迫切需要的,有此诞生了
ETL。
传统数据交互
ETL数据交互
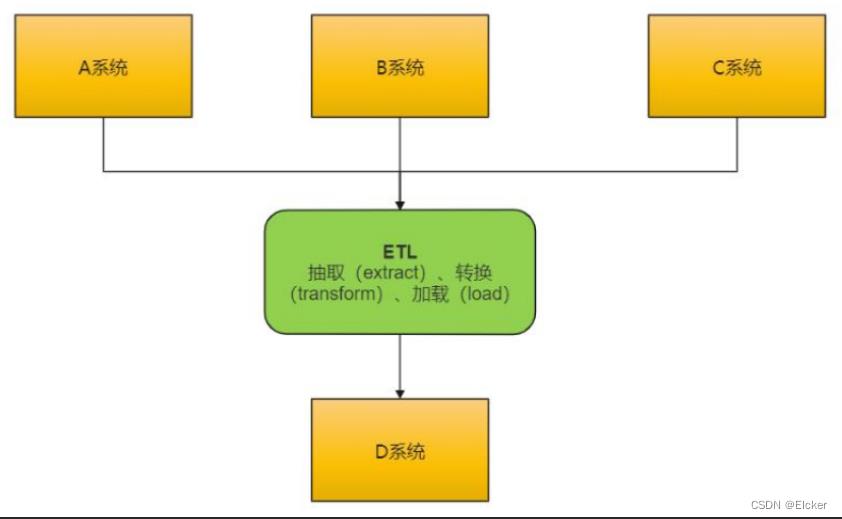
工作流程
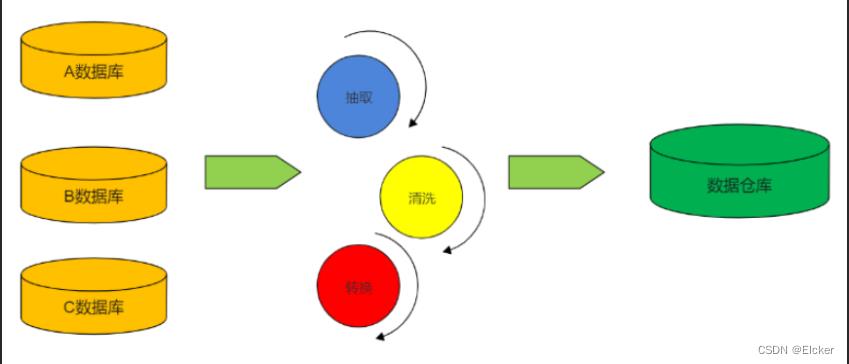
ETL 工作流程:先抽取、然后加载到目标数据库中、在目标数据库中完成转换操作。
操作步骤
ETL 处理分为五大模块,分别是:数据抽取、数据清洗、库内转换、规则检查、
数据加载。各模块可灵活进行组合,形成 ETL 处理流程。
简单介绍一下各个模块之间的主要功能。
-
数据抽取 确定数据源,需要确定从哪些源系统进行数据抽取
定义数据接口,对每个源文件及系统的每个字段进行详细说明,确定数据抽取的方法:是主动抽取还是由源系统推送?是增量抽取还是全量抽取?是按照每日抽取还是按照每月抽取?
-
数据清洗与转换
数据清洗 主要将不完整数据、错误数据、重复数据进行处理
数据转换:
1)空值处理:可捕获字段空值,进行加载或替换为其他含义数据,或数据分流问题库
2)数据标准:统一元数据、统一标准字段、统一字段类型定义 ;
3)数据拆分:依据业务需求做数据拆分,如身份证号,拆分区划、出生日期、性别等
4)数据验证:时间规则、业务规则、自定义规则
5)数据替换:对于因业务因素,可实现无效数据、缺失数据的替换
6)数据关联:关联其他数据或数学,保障数据完整性
-
数据加载
将数据缓冲区的数据直接加载到数据库对应表中,如果是全量方式则采用 LOAD 方式,如果是增量则根据业务规则 MERGE 进数据库
ETL同纬度工具
市面上常用的ETL工具有很多,比如Sqoop,DataX, Kettle, Talend 等,作为一个大数据工程师,我们最好要掌握其中的两到三种,
| 比较维度\\产品 | DataPipeline | kettle | Oracle Goldengate | informatica | talend | DataX | |
|---|---|---|---|---|---|---|---|
| 设计及架构 | 适用场景 | 主要用于各类数据融合、数据交换场景,专为超大数据量、高度复杂的数据链路设计的灵活、可扩展的数据交换平台 | 面向数据仓库建模传统ETL工具 | 主要用于数据备份、容灾 | 面向数据仓库建模传统ETL工具 | 面向数据仓库建模传统ETL工具 | 面向数据仓库建模传统ETL工具 |
| 使用方式 | 全流程图形化界面,应用端采用B/S架构,Cloud Native为云而生,所有操作在浏览器内就可以完成,不需要额外的开发和生产发布 | C/S客户端模式,开发和生产环境需要独立部署,任务的编写、调试、修改都在本地,需要发布到生产环境,线上生产环境没有界面,需要通过日志来调试、debug,效率低,费时费力 | 没有图形化的界面,操作皆为命令行方式,可配置能力差 | C/S客户端模式,开发和生产环境需要独立部署,任务的编写、调试、修改都在本地,需要发布到生产环境;学习成本较高,一般需要受过专业培训的工程师才能使用; | C/S客户端模式,开发和生产环境需要独立部署,任务的编写、调试、修改都在本地,需要发布到生产环境; | DataX是以脚本的方式执行任务的,需要完全吃透源码才可以调用,学习成本高,没有图形开发化界面和监控界面,运维成本相对高。 | |
| 底层架构 | 分布式集群高可用架构,可以水平扩展到多节点支持超大数据量,架构容错性高,可以自动调节任务在节点之间分配,适用于大数据场景 | 主从结构非高可用,扩展性差,架构容错性低,不适用大数据场景 | 可做集群部署,规避单点故障,依赖于外部环境,如Oracle RAC等; | schema mapping非自动;可复制性比较差;更新换代不是很强 | 支持分布式部署 | 支持单机部署和集群部署两种方式 | |
| 功能 | CDC机制 | 基于日志、基于时间戳和自增序列等多种方式可选 | 基于时间戳、触发器等 | 主要是基于日志 | 基于日志、基于时间戳和自增序列等多种方式可选 | 基于触发器、基于时间戳和自增序列等多种方式可选 | 离线批处理 |
| 对数据库的影响 | 基于日志的采集方式对数据库无侵入性 | 对数据库表结构有要求,存在一定侵入性 | 源端数据库需要预留额外的缓存空间 | 基于日志的采集方式对数据库无侵入性 | 有侵入性 | 通过sql select 采集数据,对数据源没有侵入性 |
KETTLE
历史
Kettle 是 PDI 以前的名称,PDI 的全称是Pentaho Data Integeration,Kettle 本意是水壶的意思,表达了数据流的含义。
Kettle 的主作者是 Matt ,他在 2003 年就开始了这个项目,在 PDI 的代码里就可以看到最早的日期大概在2003年4月。 从版本2.2开始, Kettle 项目进入了开源领域,并遵守 LGPL 协议。
在 2006年 Kettle 加入了开源的 BI(Business Intelligence) 组织 Pentaho, 正式命名为PDI, 加入Pentaho 后Kettle 的发展越来越快了,并有越来越多的人开始关注它了。
简介
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
作为Pentaho的一个重要组成部分,现在在国内项目应用上逐渐增多。
Kettle :Kettle is an acronym for “Kettle E.T.T.L. Environment”. This means it has been designed to help you with your ETTL needs: the Extraction, Transformation, Transportation and Loading of data
Kettle 是”Kettle E.T.T.L. Envirnonment”只取首字母的缩写,这意味着它被设计用来帮助你实现你的ETTL 需要:抽取、转换、装入和加载数据;翻译成中文名称应该叫水壶,名字的起源正如该项目的主程序员MATT 在一个论坛里说的哪样:希望把各种数据放到一个壶里然后以一种指定的格式流出。
整体结构图
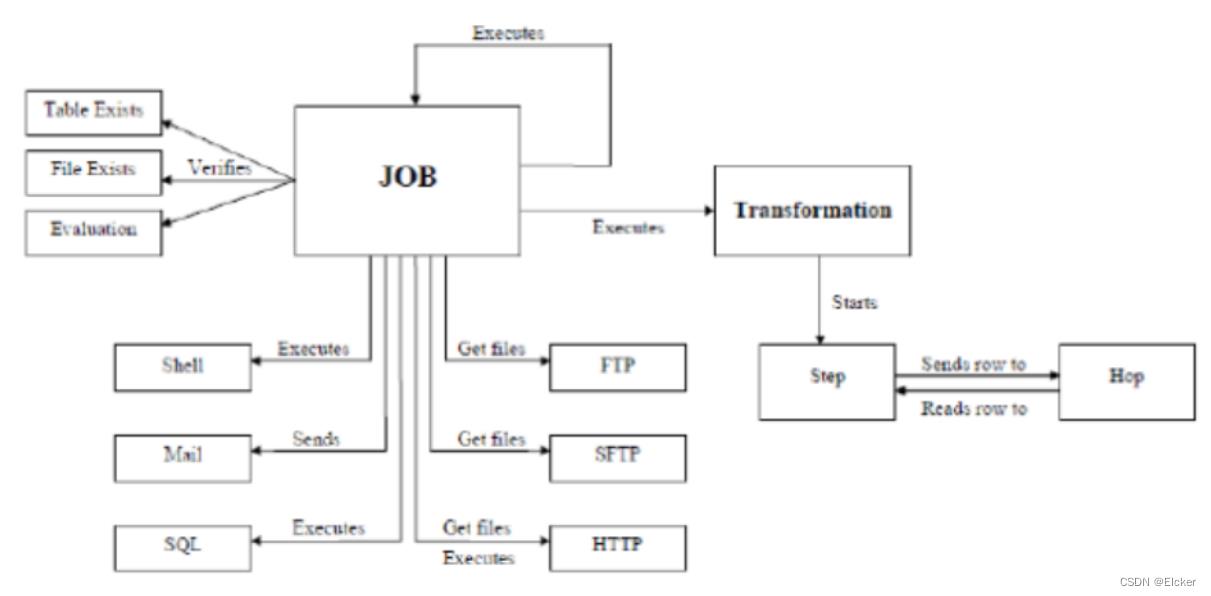
核心设计
-
Transformation (转换) :完成针对数据的基础转换。
-
Job (作业) :完成整个工作流的控制。
2者区别
- 作业是步骤流,转换是数据流。这是作业和转换最大的区别。
- 作业的每一个步骤,必须等到前面的步骤都跑完了,后面的步骤才会执行;而转换会一次性把所有控件全部先启动(一个控件对应启动一个线程),然后数据流会从第一个控件开始,一条记录、一条记录地流向最后的控件;
KETTLE核心概念
资源库
资源库是用来保存转换任务的,用户通过图形界面创建的的转换任务可以保存在资源库中。资源库可以是各种常见的数据库,用户通过用户名/密码来访问资源库中的资源,默认的用户名/密码是
admin/admin,资源库并不是必须的,如果没有资源库,用户还可以把转换任务保存在 xml
文件中。资源库可以使多用户共享转换任务,转换任务在资源库中是以文件夹形式分组管理的,用户可以自定义文件夹名称。
功能描述
➢ 目录管理
➢ 数据源管理
➢ 子服务器管理
➢ 集群管理
数据源
提供数据库连接
注意事项
➢ 不同的数据库在界面选择不同的类型
➢ 添加该数据库的驱动包至 lib 目录
➢ 不要频繁变更数据源名称(名称所对应的数据库 ip、用户、密码、端口、service_name 信息可以更改)
➢ 调整数据库连接池初始、最大值大小。
转换 Transformation
转换(transaformation)负责数据的输入、转换、校验和输出等工作。Kettle 中使用转换完成数据 ETL
全部工作。转换由多个步骤(Step)组成,如文本文件输入,过滤输出行,执行SQL脚本等。各个步骤使用跳(Hop)(连接箭头)
来链接。跳定义了一个数据流通道,即数据由一个步骤流(跳)向下一个步骤。在
Kettle中数据的最小单位是数据行(row),数据流中流动其实是缓存的行集(RowSet)。
步骤
步骤(控件)是转换里的基本的组成部分,可以理解为组件/控件
几个关键特性:
-
步骤需要有一个名字,这个名字在同一个转换范围内唯一
-
每个步骤都会读、写数据行(唯一例外是 “生成记录”步骤,该步骤只写数据
-
步骤将数据写到与之相连的一个或多个输出跳(hop),再传送到跳的另一端的步骤。
-
大多数的步骤都可以有多个输出跳。–个步骤的数据发送可以被设置为分发和复制,分发是目标步骤轮流接收记录,复制是所有的记录被同时发送到所有的目标步骤
跳(Hop)
连接转换步骤或者连接 Job(实际上就是执行顺序)的连线。跳实际上是两个步骤之间的被称之为行集的数据行缓存,行集的大小可以在转换的设置里定义。当行集满了,向行集写数据的步骤将停止写入,直到行集里又有了空间。当行集空了,丛行集读取数据的步骤停止读取,直到行集里又有可读的数据行
Transformation hop
主要表示数据的流向。从输入,过滤等转换操作,到输出
Job hop
可设置执行条件:
无条件执行 不论上一个作业项执行成功还是失败,下一个作业项都会执行。这是一种蓝色的连接线,上面有一个锁的图标。
当上一个 Job 执行结果为 true 时执行 当上一个作业项的执行结果为真时,执行下一个作业项。通常在需要无错误执行的情况下使用。这是一种绿色的连接线,上面有一个对钩号的图标。
当上一个 Job 执行结果为 false 时执行,当上一个作业项的执行结果为假或者没有成功执行是,执行下一个作业项。这是一种红色的连接线,上面有一个红色的停止图标。



元数据
每个步骤在输出数据行时都有对字段的描述,这种描述就是数据行的元数据。
并行
跳的这种基于行集缓存的规则允许每个步骤都是由一个独立的线程运行,这样并发程度最高。这一规则也允许数据以最小消耗内存的数据流的方式来处理。在数据仓库里,我们经常要处理大量数据,所以这种高并发低消耗的方式也是
ETL 工具的核心需求。对于 kettle
的转换,不能定义一个执行顺序,因为所有步骤都以并发方式执行:当转换启动后,所有步骤都同时启动,从它们的输入跳中读取数据,并把处理过的数据写到输出跳,直到输入跳里不再有数据,就中止步骤的运行。当所有的步骤都中止了,整个转换就中止了。
JOB
作业可以调度设计好的转换,也可以执行一些文件处理(比较,删除等),还可以 ftp 上传,下载文件,发送邮件,执行 shell
命令等。**负责定义一个完成整个工作流的控制,比如将转换的结果发送邮件给相关人员。因为转换(transformation)
以并行方式执行,所以必须存在一个串行的调度工具来执行转换,这就是Kettle 中的作业。
Kettle安装部署
下载
安装
1)安装 jdk1.8
2)下载kettle压缩包,并解压缩到任意本地路径即可
3)双击Spoon.bat,启动图形化界面工具,
Kettle目录说明

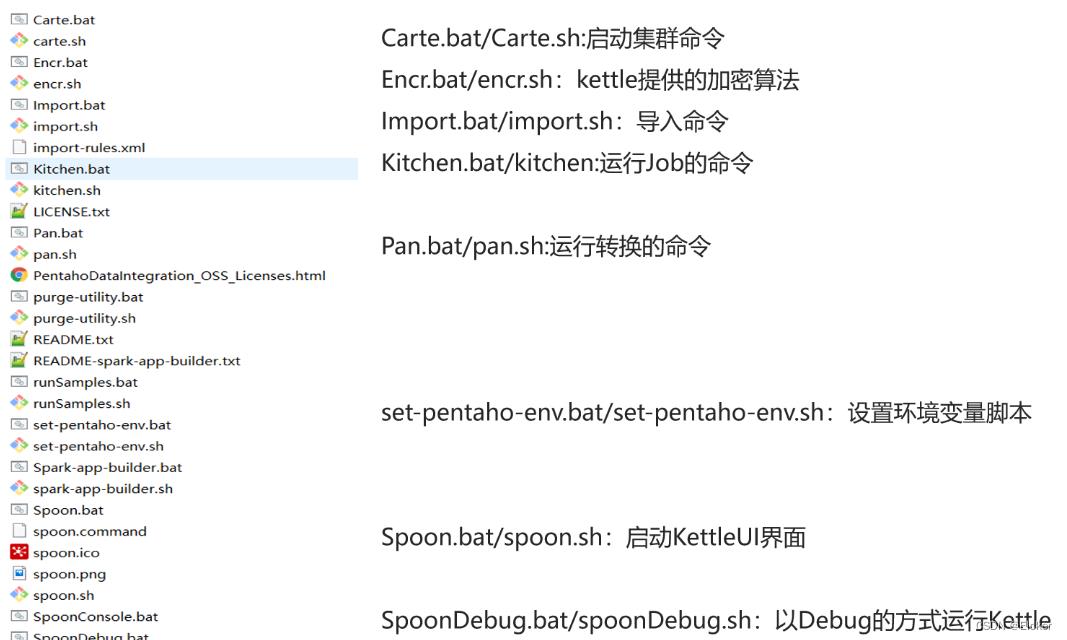
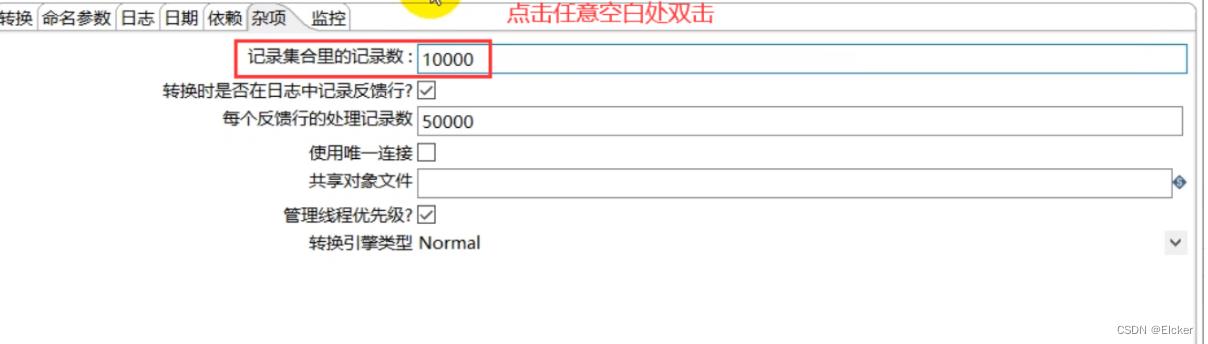
界面

好了,本章的介绍就到这里了,更多内容参见我的博客!
以上是关于ETL工具之Kettle开发教程第一节-入门的主要内容,如果未能解决你的问题,请参考以下文章