2023网络爬虫 -- 获取动态加载数据
Posted web安全工具库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2023网络爬虫 -- 获取动态加载数据相关的知识,希望对你有一定的参考价值。
1、爬取的网址
http://www.kfc.com.cn/kfccda/storelist/index.aspx2、要爬取的内容,输入关键字,点击查询,获取餐厅名称和餐厅地址
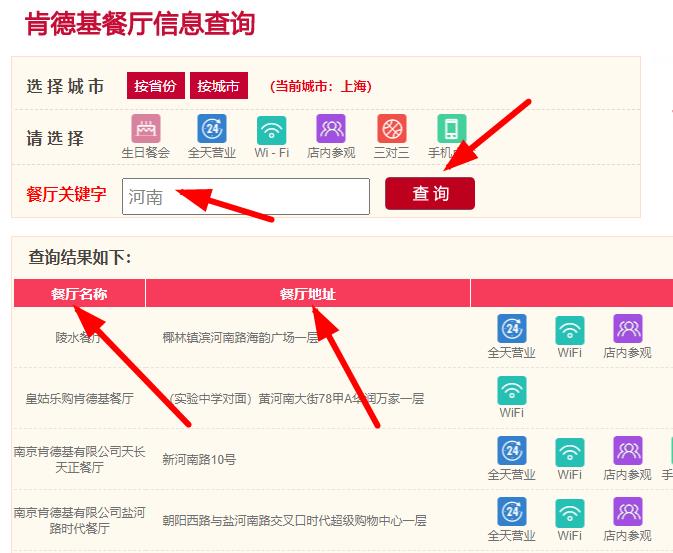
3、F12,打开开发者工具,点击查询,抓包

4、点击标头,查看请求网址,是post请求,查看载荷也就是提交的参数
http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword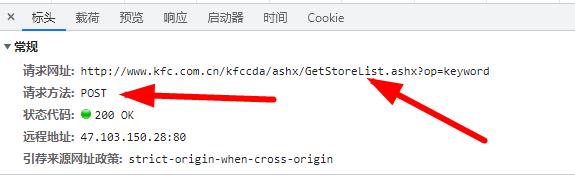
5、表单数据就是我们要提交的数据

6、导入requests包
import requests7、头和提交的参数
头="User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/86.0.4240.198 Safari/537.36"参数="cname":"","pid":"","keyword": "河南","pageIndex": "1","pageSize": "10",8、要获取的网址
网页="http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword"9、post请求,提交参数需要data
响应=requests.post(网页,headers=头,data =参数)10、获取JSON数据
响应内容=响应.json()11、将数据存储
withopen("kfc.txt","w",encoding="utf-8") as 数据:for i in 响应内容['Table1']: 店名=i['storeName'] 地址=i["addressDetail"] 数据.write(店名+"餐厅"+":"+地址+"\\n")12、存储结果
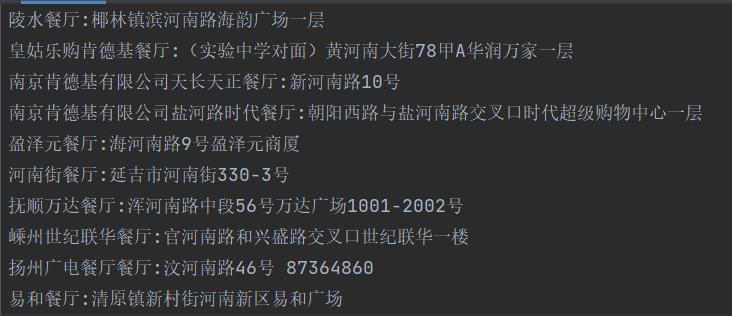
以上是关于2023网络爬虫 -- 获取动态加载数据的主要内容,如果未能解决你的问题,请参考以下文章
2017.07.28 Python网络爬虫之爬虫实战 今日影视2 获取JS加载的数据