深入理解 Linux 的 RCU 机制
Posted 腾讯云加社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解 Linux 的 RCU 机制相关的知识,希望对你有一定的参考价值。
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~
作者:梁康
RCU(Read-Copy Update),是 Linux 中比较重要的一种同步机制。顾名思义就是“读,拷贝更新”,再直白点是“随意读,但更新数据的时候,需要先复制一份副本,在副本上完成修改,再一次性地替换旧数据”。这是 Linux 内核实现的一种针对“读多写少”的共享数据的同步机制。
不同于其他的同步机制,它允许多个读者同时访问共享数据,而且读者的性能不会受影响(“随意读”),读者与写者之间也不需要同步机制(但需要“复制后再写”),但如果存在多个写者时,在写者把更新后的“副本”覆盖到原数据时,写者与写者之间需要利用其他同步机制保证同步。
RCU 的一个典型的应用场景是链表,在 Linux kernel 中还专门提供了一个头文件(include/linux/rculist.h),提供了利用 RCU 机制对链表进行增删查改操作的接口。本文将通过一个例子,利用 rculist.h 提供的接口对链表进行增删查改的操作,来讲述 RCU 的原理,以及介绍 Linux kernel 中相关的 API(基于 Linux v3.4.0 的源码)。
增加链表项
Linux kernel 中利用 RCU 往链表增加项的源码如下:
#define list_next_rcu(list) (*((struct list_head __rcu **)(&(list)->next))) static inline void __list_add_rcu(struct list_head *new, struct list_head *prev, struct list_head *next) { new->next = next; new->prev = prev; rcu_assign_pointer(list_next_rcu(prev), new); next->prev = new; }
list_next_rcu() 函数中的 rcu 是一个供代码分析工具 Sparse 使用的编译选项,规定有 rcu 标签的指针不能直接使用,而需要使用 rcu_dereference() 返回一个受 RCU 保护的指针才能使用。rcu_dereference() 接口的相关知识会在后文介绍,这一节重点关注 rcu_assign_pointer() 接口。首先看一下 rcu_assign_pointer() 的源码:
#define __rcu_assign_pointer(p, v, space) \\ ({ \\ smp_wmb(); \\ (p) = (typeof(*v) __force space *)(v); \\ })
上述代码的最终效果是把 v 的值赋值给 p,关键点在于第 3 行的内存屏障。什么是内存屏障(Memory Barrier)呢?CPU 采用流水线技术执行指令时,只保证有内存依赖关系的指令的执行顺序,例如 p = v; a = *p;,由于第 2 条指令访问的指针 p 所指向的内存依赖于第 1 条指令,因此 CPU 会保证第 1 条指令在第 2 条指令执行前执行完毕。但对于没有内存依赖的指令,例如上述 __list_add_rcu() 接口中,假如把第 8 行写成 prev->next = new;,由于这个赋值操作并没涉及到对 new 指针指向的内存的访问,因此认为不依赖于 6,7 行对 new->next 和 new->prev 的赋值,CPU 有可能实际运行时会先执行 prev->next = new; 再执行 new->prev = prev;,这就会造成 new 指针(也就是新加入的链表项)还没完成初始化就被加入了链表中,假如这时刚好有一个读者刚好遍历访问到了该新的链表项(因为 RCU 的一个重要特点就是可随意执行读操作),就会访问到一个未完成初始化的链表项!通过设置内存屏障就能解决该问题,它保证了在内存屏障前边的指令一定会先于内存屏障后边的指令被执行。这就保证了被加入到链表中的项,一定是已经完成了初始化的。
最后提醒一下,这里要注意的是,如果可能存在多个线程同时执行添加链表项的操作,添加链表项的操作需要用其他同步机制(如 spin_lock 等)进行保护。
访问链表项
Linux kernel 中访问 RCU 链表项常见的代码模式是:
rcu_read_lock(); list_for_each_entry_rcu(pos, head, member) { // do something with `pos` } rcu_read_unlock();
这里要讲到的 rcu_read_lock() 和 rcu_read_unlock(),是 RCU “随意读” 的关键,它们的效果是声明了一个读端的临界区(read-side critical sections)。在说读端临界区之前,我们先看看读取链表项的宏函数 list_for_each_entry_rcu。追溯源码,获取一个链表项指针主要调用的是一个名为 rcu_dereference() 的宏函数,而这个宏函数的主要实现如下:
#define __rcu_dereference_check(p, c, space) \\ ({ \\ typeof(*p) *_________p1 = (typeof(*p)*__force )ACCESS_ONCE(p); \\ rcu_lockdep_assert(c, "suspicious rcu_dereference_check()" \\ " usage"); \\ rcu_dereference_sparse(p, space); \\ smp_read_barrier_depends(); \\ ((typeof(*p) __force __kernel *)(_________p1)); \\ }) 第 3 行:声明指针 _p1 = p; 第 7 行:smp_read_barrier_depends(); 第 8 行:返回 _p1;
上述两块代码,实际上可以看作这样一种模式:
rcu_read_lock(); p1 = rcu_dereference(p); if (p1 != NULL) { // do something with p1, such as: printk("%d\\n", p1->field); } rcu_read_unlock();
根据 rcu_dereference() 的实现,最终效果就是把一个指针赋值给另一个,那如果把上述第 2 行的 rcu_dereference() 直接写成 p1 = p 会怎样呢?在一般的处理器架构上是一点问题都没有的。但在 alpha 上,编译器的 value-speculation 优化选项据说可能会“猜测” p1 的值,然后重排指令先取值 p1->field~ 因此 Linux kernel 中,smp_read_barrier_depends() 的实现是架构相关的,arm、x86 等架构上是空实现,alpha 上则加了内存屏障,以保证先获得 p 真正的地址再做解引用。因此上一节 “增加链表项” 中提到的 “__rcu” 编译选项强制检查是否使用 rcu_dereference() 访问受 RCU 保护的数据,实际上是为了让代码拥有更好的可移植性。
现在回到读端临界区的问题上来。多个读端临界区不互斥,即多个读者可同时处于读端临界区中,但一块内存数据一旦能够在读端临界区内被获取到指针引用,这块内存块数据的释放必须等到读端临界区结束,等待读端临界区结束的 Linux kernel API 是synchronize_rcu()。读端临界区的检查是全局的,系统中有任何的代码处于读端临界区,synchronize_rcu() 都会阻塞,知道所有读端临界区结束才会返回。为了直观理解这个问题,举以下的代码实例:
/* `p` 指向一块受 RCU 保护的共享数据 */ /* reader */ rcu_read_lock(); p1 = rcu_dereference(p); if (p1 != NULL) { printk("%d\\n", p1->field); } rcu_read_unlock(); /* free the memory */ p2 = p; if (p2 != NULL) { p = NULL; synchronize_rcu(); kfree(p2); }
用以下图示来表示多个读者与内存释放线程的时序关系:
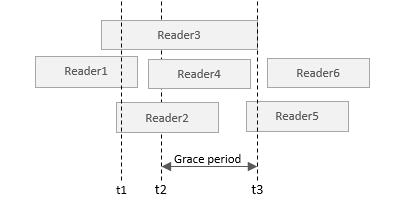
上图中,每个读者的方块表示获得 p 的引用(第5行代码)到读端临界区结束的时间周期;t1 表示 p = NULL 的时间;t2 表示 synchronize_rcu() 调用开始的时间;t3 表示 synchronize_rcu() 返回的时间。我们先看 Reader1,2,3,虽然这 3 个读者的结束时间不一样,但都在 t1 前获得了 p 地址的引用。t2 时调用 synchronize_rcu(),这时 Reader1 的读端临界区已结束,但 Reader2,3 还处于读端临界区,因此必须等到 Reader2,3 的读端临界区都结束,也就是 t3,t3 之后,就可以执行 kfree(p2) 释放内存。synchronize_rcu() 阻塞的这一段时间,有个名字,叫做 Grace period。而 Reader4,5,6,无论与 Grace period 的时间关系如何,由于获取引用的时间在 t1 之后,都无法获得 p 指针的引用,因此不会进入 p1 != NULL 的分支。
删除链表项
知道了前边说的 Grace period,理解链表项的删除就很容易了。常见的代码模式是:
p = seach_the_entry_to_delete(); list_del_rcu(p->list); synchronize_rcu(); kfree(p); 其中 list_del_rcu() 的源码如下,把某一项移出链表: /* list.h */ static inline void __list_del(struct list_head * prev, struct list_head * next) { next->prev = prev; prev->next = next; } /* rculist.h */ static inline void list_del_rcu(struct list_head *entry) { __list_del(entry->prev, entry->next); entry->prev = LIST_POISON2; }
根据上一节“访问链表项”的实例,假如一个读者能够从链表中获得我们正打算删除的链表项,则肯定在 synchronize_rcu() 之前进入了读端临界区,synchronize_rcu() 就会保证读端临界区结束时才会真正释放链表项的内存,而不会释放读者正在访问的链表项。
更新链表项
前文提到,RCU 的更新机制是 “Copy Update”,RCU 链表项的更新也是这种机制,典型代码模式是:
p = search_the_entry_to_update(); q = kmalloc(sizeof(*p), GFP_KERNEL); *q = *p; q->field = new_value; list_replace_rcu(&p->list, &q->list); synchronize_rcu(); kfree(p);
其中第 3,4 行就是复制一份副本,并在副本上完成更新,然后调用 list_replace_rcu() 用新节点替换掉旧节点。源码如下:
其中第 3,4 行就是复制一份副本,并在副本上完成更新,然后调用 list_replace_rcu() 用新节点替换掉旧节点,最后释放旧节点内存。list_replace_rcu() 源码如下:
static inline void list_replace_rcu(struct list_head *old, struct list_head *new) { new->next = old->next; new->prev = old->prev; rcu_assign_pointer(list_next_rcu(new->prev), new); new->next->prev = new; old->prev = LIST_POISON2; }
References
[1] What is RCU, Fundamentally?
[2] https://www.kernel.org/doc/Documentation/RCU/checklist.txt
[3] https://www.kernel.org/doc/Documentation/RCU/whatisRCU.txt
[4] https://www.kernel.org/doc/Documentation/memory-barriers.txt
[5] LINUX内核之内存屏障
相关阅读
以上是关于深入理解 Linux 的 RCU 机制的主要内容,如果未能解决你的问题,请参考以下文章