一、前言
关于RCU的文档包括两份,一份讲基本的原理(也就是本文了),一份讲linux kernel中的实现。第二章描述了为何有RCU这种同步机制,特别是在cpu core数目不断递增的今天,一个性能更好的同步机制是如何解决问题的,当然,再好的工具都有其适用场景,本章也给出了RCU的一些应用限制。第三章的第一小节描述了RCU的设计概念,其实RCU的设计概念比较简单,比较容易理解,比较困难的是产品级别的RCU实现,我们会在下一篇文档中描述。第三章的第二小节描述了RCU的相关操作,其实就是对应到了RCU的外部接口API上来。最后一章是参考文献,perfbook是一本神奇的数,喜欢并行编程的同学绝对不能错过的一本书,强烈推荐。和perfbook比起来,本文显得非常的丑陋(主要是有些RCU的知识还是理解不深刻,可能需要再仔细看看linux kernel中的实现才能了解其真正含义),除了是中文表述之外,没有任何的优点,英语比较好的同学可以直接参考该书。
二、为何有RCU这种同步机制呢?
前面我们讲了spin lock,rw spin lock和seq lock,为何又出现了RCU这样的同步机制呢?这个问题类似于问:有了刀枪剑戟这样的工具,为何会出现流星锤这样的兵器呢?每种兵器都有自己的适用场合,内核同步机制亦然。RCU在一定的应用场景下,解决了过去同步机制的问题,这也是它之所以存在的基石。本章主要包括两部分内容:一部分是如何解决其他内核机制的问题,另外一部分是受限的场景为何?
1、性能问题
我们先回忆一下spin lcok、RW spin lcok和seq lock的基本原理。对于spin lock而言,临界区的保护是通过next和owner这两个共享变量进行的。线程调用spin_lock进入临界区,这里包括了三个动作:
(1)获取了自己的号码牌(也就是next值)和允许哪一个号码牌进入临界区(owner)
(2)设定下一个进入临界区的号码牌(next++)
(3)判断自己的号码牌是否是允许进入的那个号码牌(next == owner),如果是,进入临界区,否者spin(不断的获取owner的值,判断是否等于自己的号码牌,对于ARM64处理器而言,可以使用WFE来降低功耗)。
注意:(1)是取值,(2)是更新并写回,因此(1)和(2)必须是原子操作,中间不能插入任何的操作。
线程调用spin_unlock离开临界区,执行owner++,表示下一个线程可以进入。
RW spin lcok和seq lock都类似spin lock,它们都是基于一个memory中的共享变量(对该变量的访问是原子的)。我们假设系统架构如下:
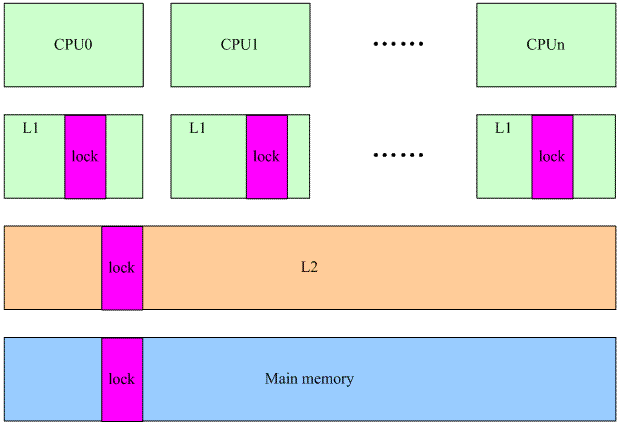
当线程在多个cpu上争抢进入临界区的时候,都会操作那个在多个cpu之间共享的数据lock(玫瑰色的block)。cpu 0操作了lock,为了数据的一致性,cpu 0的操作会导致其他cpu的L1中的lock变成无效,在随后的来自其他cpu对lock的访问会导致L1 cache miss(更准确的说是communication cache miss),必须从下一个level的cache中获取,同样的,其他cpu的L1 cache中的lock也被设定为invalid,从而引起下一次其他cpu上的communication cache miss。
RCU的read side不需要访问这样的“共享数据”,从而极大的提升了reader侧的性能。
2、reader和writer可以并发执行
spin lock是互斥的,任何时候只有一个thread(reader or writer)进入临界区,rw spin lock要好一些,允许多个reader并发执行,提高了性能。不过,reader和updater不能并发执行,RCU解除了这些限制,允许一个updater(不能多个updater进入临界区,这可以通过spinlock来保证)和多个reader并发执行。我们可以比较一下rw spin lock和RCU,参考下图:

rwlock允许多个reader并发,因此,在上图中,三个rwlock reader愉快的并行执行。当rwlock writer试图进入的时候(红色虚线),只能spin,直到所有的reader退出临界区。一旦有rwlock writer在临界区,任何的reader都不能进入,直到writer完成数据更新,立刻临界区。绿色的reader thread们又可以进行愉快玩耍了。rwlock的一个特点就是确定性,白色的reader一定是读取的是old data,而绿色的reader一定获取的是writer更新之后的new data。RCU和传统的锁机制不同,当RCU updater进入临界区的时候,即便是有reader在也无所谓,它可以长驱直入,不需要spin。同样的,即便有一个updater正在临界区里面工作,这并不能阻挡RCU reader的步伐。由此可见,RCU的并发性能要好于rwlock,特别如果考虑cpu的数目比较多的情况,那些处于spin状态的cpu在无谓的消耗,多么可惜,随着cpu的数目增加,rwlock性能不断的下降。RCU reader和updater由于可以并发执行,因此这时候的被保护的数据有两份,一份是旧的,一份是新的,对于白色的RCU reader,其读取的数据可能是旧的,也可能是新的,和数据访问的timing相关,当然,当RCU update完成更新之后,新启动的RCU reader(绿色block)读取的一定是新的数据。
3、适用的场景
我们前面说过,每种锁都有自己的适用的场景:spin lock不区分reader和writer,对于那些读写强度不对称的是不适合的,RW spin lcok和seq lock解决了这个问题,不过seq lock倾向writer,而RW spin lock更照顾reader。看起来一切都已经很完美了,但是,随着计算机硬件技术的发展,CPU的运算速度越来越快,相比之下,存储器件的速度发展较为滞后。在这种背景下,获取基于counter(需要访问存储器件)的锁(例如spin lock,rwlock)的机制开销比较大。而且,目前的趋势是:CPU和存储器件之间的速度差别在逐渐扩大。因此,那些基于一个multi-processor之间的共享的counter的锁机制已经不能满足性能的需求,在这种情况下,RCU机制应运而生(当然,更准确的说RCU一种内核同步机制,但不是一种lock,本质上它是lock-free的),它克服了其他锁机制的缺点,但是,甘蔗没有两头甜,RCU的使用场景比较受限,主要适用于下面的场景:
(1)RCU只能保护动态分配的数据结构,并且必须是通过指针访问该数据结构
(2)受RCU保护的临界区内不能sleep(SRCU不是本文的内容)
(3)读写不对称,对writer的性能没有特别要求,但是reader性能要求极高。
(4)reader端对新旧数据不敏感。
三、RCU的基本思路
1、原理
RCU的基本思路可以通过下面的图片体现:

RCU涉及的数据有两种,一个是指向要保护数据的指针,我们称之RCU protected pointer。另外一个是通过指针访问的共享数据,我们称之RCU protected data,当然,这个数据必须是动态分配的 。对共享数据的访问有两种,一种是writer,即对数据要进行更新,另外一种是reader。如果在有reader在临界区内进行数据访问,对于传统的,基于锁的同步机制而言,reader会阻止writer进入(例如spin lock和rw spin lock。seqlock不会这样,因此本质上seqlock也是lock-free的),因为在有reader访问共享数据的情况下,write直接修改data会破坏掉共享数据。怎么办呢?当然是移除了reader对共享数据的访问之后,再让writer进入了(writer稍显悲剧)。对于RCU而言,其原理是类似的,为了能够让writer进入,必须首先移除reader对共享数据的访问,怎么移除呢?创建一个新的copy是一个不错的选择。因此RCU writer的动作分成了两步:
(1)removal。write分配一个new version的共享数据进行数据更新,更新完毕后将RCU protected pointer指向新版本的数据。一旦把RCU protected pointer指向的新的数据,也就意味着将其推向前台,公布与众(reader都是通过pointer访问数据的)。通过这样的操作,原来read 0、1、2对共享数据的reference被移除了(对于新版本的受RCU保护的数据而言),它们都是在旧版本的RCU protected data上进行数据访问。
(2)reclamation。共享数据不能有两个版本,因此一定要在适当的时机去回收旧版本的数据。当然,不能太着急,不能reader线程还访问着old version的数据的时候就强行回收,这样会让reader crash的。reclamation必须发生在所有的访问旧版本数据的那些reader离开临界区之后再回收,而这段等待的时间被称为grace period。
顺便说明一下,reclamation并不需要等待read3和4,因为write端的为RCU protected pointer赋值的语句是原子的,乱入的reader线程要么看到的是旧的数据,要么是新的数据。对于read3和4,它们访问的是新的共享数据,因此不会reference旧的数据,因此reclamation不需要等待read3和4离开临界区。
2、基本RCU操作
对于reader,RCU的操作包括:
(1)rcu_read_lock,用来标识RCU read side临界区的开始。
(2)rcu_dereference,该接口用来获取RCU protected pointer。reader要访问RCU保护的共享数据,当然要获取RCU protected pointer,然后通过该指针进行dereference的操作。
(3)rcu_read_unlock,用来标识reader离开RCU read side临界区
对于writer,RCU的操作包括:
(1)rcu_assign_pointer。该接口被writer用来进行removal的操作,在witer完成新版本数据分配和更新之后,调用这个接口可以让RCU protected pointer指向RCU protected data。
(2)synchronize_rcu。writer端的操作可以是同步的,也就是说,完成更新操作之后,可以调用该接口函数等待所有在旧版本数据上的reader线程离开临界区,一旦从该函数返回,说明旧的共享数据没有任何引用了,可以直接进行reclaimation的操作。
(3)call_rcu。当然,某些情况下(例如在softirq context中),writer无法阻塞,这时候可以调用call_rcu接口函数,该函数仅仅是注册了callback就直接返回了,在适当的时机会调用callback函数,完成reclaimation的操作。这样的场景其实是分开removal和reclaimation的操作在两个不同的线程中:updater和reclaimer。
四、参考文档
1、perfbook
2、linux-4.1.10\Documentation\RCU\*