大道至简浅谈自然语言处理(NLP)学习路线:N-Gram模型,一文带你理解N-Gram语言模型
Posted 尚拙谨言
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大道至简浅谈自然语言处理(NLP)学习路线:N-Gram模型,一文带你理解N-Gram语言模型相关的知识,希望对你有一定的参考价值。
大家好,我是尚拙谨言。欢迎来到大道至简专栏之自然语言处理学习路线。在本系列往期文章中,我介绍过学习自然语言处理技术的技术路线,也就是你大概需要先学会哪些基本知识。没看过的朋友可以回到那篇看一下,链接在文章开头。那么,本篇开始,我们就针对这一系列基础进行进一步介绍。
另外,之所以我把这一系列博客的撰写前置到另外一个【大道至简】机器学习系列,是因为最近chatGPT实在太火了,如果你还没有了解这一领域的技术,真的就落后了。可能有的小伙伴说:“我又不是搞NLP的,我是搞图像的。”那你就大错特错了,可以说chatGPT的诞生,严格上来讲,影响的不仅仅是某个特定技术领域,大家都知道,它是一个大模型,这个大模型已经能够涵盖住诸如机器翻译、图像、问答、推荐、搜索等许多领域,也就是说它是个多模态或者说它已经开辟了多模态融合技术的新路线。除此之外,它又一次为大家打开了强化学习思想的大门,而且这一新兴的训练思想被验证是有效的!所以,chatGPT在我看来,其意义不仅仅是chatGPT(一句废话),更大的意义在于它是一个新的技术思想的开门人:大模型+多模态+强化学习。
而不得不承认,chatGPT其属性仍然是NLP技术的范畴,所以,想要懂chatGPT,NLP我们又不得不学,学习NLP,接下来及其以后我介绍的这些NLP基础知识又不得不学,所以可以说,我即将写的这些文章,是我们掌握前沿技术的敲门砖。
这一节要聊的是一个比较容易理解和掌握的非常经典和基础的技术:N-Gram语言模型。我们直接步入正文。
目录
一、什么是语言模型
你现在在看我的文章,这是一些文字,但是这些文字实质上是以像素点的形式呈现给你的,所以不要以为这些文字是计算机理解的元素,它不过是一些像素点组合出的可视化图像而已。可是我们现在有很多时候不仅仅是想让文字呈现在我们计算机屏幕上这么简单,更多的是想让计算机接收到一些文字信息后能够在它“心里”对这些文字信息进行理解、分析和处理,怎么办呢?这个时候,语言模型就派上用场了。我们知道,计算机接收到的所有类型的信息,本质上都是转化成“0、1”这两个数进行存储或者处理的,语言文字也不例外。事实上,0和1这两个数更偏向计算机底层所用,我们大多数情况下,都是会将不同长度不同组合方式的0-1串转化成更直观的一些整数、浮点数等,但总之都是“数”。所以,语言模型本质上就是要将来自客观世界的文字实体通过一定的逻辑处理,处理成能够很好的代表这些文字信息的“数字”,而这里的“逻辑处理”的工具,就是所有我们所了解的自然语言处理领域的模型。
从大的方向上说,语言模型的“样子”可以分为两种,一种是传统的基于概率统计学的统计模型,它是一些计算好的统计数字,可能是浮点数,也可能是整数,如果是浮点数,它可能是0~1之间的频率或者概率,如果是整数,它基本上就是一些字词出现的频数。另一种是进阶的基于神经网络的函数模型,模型中的参数也是浮点数,可能有正的有负的,每个数字没有人类可理解的直观意义,它们表达了能够计算语言特征的算子,它们是某些高阶的,存在客观意义的函数参数,基于神经网络的语言模型,它本质上是一系列矩阵,这些矩阵可以类比成y=ax+b中的a和b,最简单的理解就是x为某个字词,经过函数计算后输出为y,那么这个y就是一个能够非常好的表达这个字词的且计算机能够理解和处理的向量,只不过对于神经网络来说,其要表达的函数远不止y=ax+b这么简单,但是本质上是一样的。
二、N-Gram
介绍完了语言模型的本质,我们可以介绍N-Gram了,那么这个N-Gram就是传统的基于概率统计的语言模型。它是个什么东西呢?我们思考这么一件事:
一天,你偶然遇见了一个许久未见的老友,见面时,老友开口第一句话是说“好久不见!最近过得还好吗?”,现在我们来看下这句话,当你的老友说“好久”二字的时候,你的脑海里已经大概率猜出他后面会说“不见”二字?当他说“最近过”的时候,你脑海里又大概率猜到他是想说“得还好吗”,也就是你听到“好久”或者“最近过”的时候,你就知道十有八九“好久”后接的是“不见”,“最近过”后面接的是“得还好吗”。为什么呢?是因为在你的大脑库中,你已经存储了海量的先验知识,这其中就包括“好久不见”和“最近过得还好吗”这两句话。加上当时场景的加持,经验上来说,你就是这么猜到的,而且很准。为什么说需要有场景的加持?因为“好久”后面仍然可以是“好久”或者“没吃了”、“没去了”等,“最近过”后面也可以是“得不怎么样”、“去了吗”等,但是相比于当时的环境(和许久未见的老友偶然相遇)来说,“最近过得还好吗”以及“好久不见”出现的概率显然要高一些。对于环境的加持这一部分概念,不是本章的重点,但是是自然语言处理的重点,即所谓的“上下文”,这个以后我们再讲。
不知道各位对上述例子是否有所体会。其实N-Gram的思想就来源于淳朴的人类的语言习惯。由于CSDN公式里不支持中文,所以我这边再举个例子:假如有这么一句话“artificial intelligence is crazy”。好了,现在你把自己想象成一台计算机,这个时候交给你两个任务:第一个任务是当我说出artificial的时候,你要猜出我要说的是啥。第二个任务是当你听到artificial intelligence is crazy的时候你要判断这句话是不是一句正常的人类语言。
我们来看下你会怎么做。首先,你需要阅读大量的文章,从这些文章中,你学习到以下信息:
| 出现的组合 | 出现次数 |
| 总词数 | 1000 |
| artificial | 500 |
| artificial intelligence | 90 |
| artificial xxx | 10 |
| artificial intelligence is | 70 |
| artificial intelligence xxx | 10 |
| artificial intelligence is crazy | 50 |
| artificial intelligence is xxx | 10 |
从上述表格可以看出,在所有与artificial组合成的二元词的情况中,artificial intelligence出现的次数最多,因此你就认为artificial后接intelligence的可能性最大,那么你就会告诉我,当你听到artificial后,大概率你就会接着听到intelligence。而当你听到artificial intelligence后,你又知道了在所有与artificial intelligence组合而成的三元词组中,artificial intelligence is出现的次数最多,同样你就猜到你会听到artificial intelligence is这句话,同样在所有和arithmetic intelligence is组合而成的四元词组中,artificial intelligence is crazy的次数最多,所以你就判断出我说了artificial这个词后,我大概率要说的是artificial intelligence is crazy。这样一来,第一个任务你就完成了。
那么第二个任务呢?让你判断artificial intelligence is crazy是不是一句符合人类语言逻辑的正常的话,这个事儿本质是啥?事实上,要判断一句话是不是一句符合语言逻辑的话,就是让你判断这句话能够出现的概率是多少。也就是说,你需要从你的先验知识中(也就是你看过的大量的文章),计算出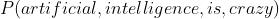 ,看看这个概率值究竟高不高,如果很高(大于某个阈值),说明在你的知识体系中,这句话出现的次数最多,那么你就认为它是一句你曾经在许多文章中见过的正常的句子,这里假设你见过的文章都是标准的符合人类语言逻辑的语言。相反如果很低,说明你从没见过这样的说话方式,你就会觉得这句话不伦不类胡说八道,于是你就会对这句话的意思表示很困惑,这就涉及到一个很重要的概念:困惑度,这个我们后面讲,先来看看上面提到的P咋求。
,看看这个概率值究竟高不高,如果很高(大于某个阈值),说明在你的知识体系中,这句话出现的次数最多,那么你就认为它是一句你曾经在许多文章中见过的正常的句子,这里假设你见过的文章都是标准的符合人类语言逻辑的语言。相反如果很低,说明你从没见过这样的说话方式,你就会觉得这句话不伦不类胡说八道,于是你就会对这句话的意思表示很困惑,这就涉及到一个很重要的概念:困惑度,这个我们后面讲,先来看看上面提到的P咋求。
还记得概率论中的条件概率计算公式吗?P(A|B)=P(A, B)/P(B)->P(A, B)=P(A|B)P(B),所以P有如下计算方式:

【字体有点小,请点击放大😂】
说人话就是:artificial intelligence is crazy同时出现的概率等于artificial出现的概率乘以当artificial出现时intelligence出现的概率乘以当artificial intelligence出现时is出现的概率……,这就是n-gram语言模型的基本思想。
三、齐次马尔科夫假设&N-Gram的实际计算方法
现在考虑一个问题,我们上面举的例子是非常简单的,特别是article intelligence is crazy也才4个词,所以对于P的计算没啥大问题。但是我们指导,P是概率,是个小于1的整数,如果我们的文本不止4个字,而是100个,1000个上万个,那如果计算P的话,相当于很多个小数相乘,到最后无限趋近于0啊(这个问题大家先记住,后面会说明),不仅如此,计算前好多个词出现的情况下当前词出现的概率,每次都要把前那么多个词的数算一遍,算起来好麻烦,怎么办?天无绝人之路,马尔科夫替我们想了一个好办法,这个办法就一个字:假设!
假设什么呢?马尔科夫他说,我们在计算前后具有关联性的序列的条件概率的时候,我们假设序列的当前状态的出现只依赖于前一个状态,和再前面的状态没有关系,这样一来,问题就简单多了,灵活一点,基于这个假设,我们还可以假设:当前状态只依赖于前两个状态,还可以假设只依赖于前三个状态……,那么这个假设中只和前n个状态有关的“n”,就是我们n-gram中的“n”。现在我们取n=2来变换一下公式:

那么为什么可以假设当前状态只依赖于前n个状态呢?其实从动态规划的角度来想,那是因为前一状态事实上已经包含了当初计算前一状态时,前一状态的前一状态的信息了。所以我们在计算当前状态时,没必要那么啰嗦的把之前所有的状态都考虑一遍。当然这只是通俗的理解,具体的还得问马尔科夫本人。
现在我们就可以根据上述变换后的公式来进行具体计算了,假如我们有如下语料库:
1. artificial intelligence is crazy
2. artificial is not intelligence and stupid
4. artificial intelligence is useless
5. chatGPT is not intelligence
我们来求一下P,注意,实际计算中,我们是要在句子的前后加上首字符和尾字符标识符的,这与上述理论公式中有些许不同。
先计算artificial作为句首出现的次数:
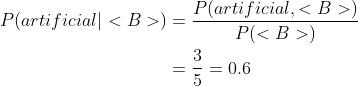
<B>表示某个词作为句子的开头。
随后计算 P(intelligence|artificial):
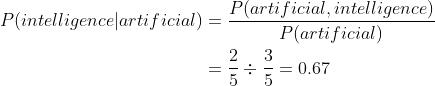
计算P(is|intelligence):

计算P(crazy|is):
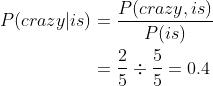
计算P(<E>|crazy):
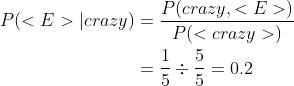
<E>是一句话的结尾标识符,P(<E>|crazy)表示crazy作为一句话末尾出现的概率。所以:

不知道各位有没有发现,像上面这样计算,仍然存在多个概率值连乘容易趋近于0的问题,那么该如何解决这个问题呢?数学上有个很好用的工具:log。我们先把n=2时的n-gram表达式写出来:
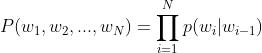
现在加入log变换一下:
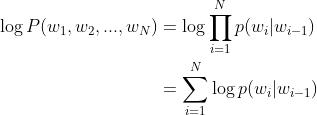
这样一来,我们就把连乘形式换成连加的形式了,求起来方便多了有木有。
四、困惑度
经过上面一番瞎扯,估计有的小伙伴就要问了,说了半天,N-Gram语言模型究竟是个啥?是那个公式吗?显然不是,这里我们总结一下N-Gram语言模型的工作流程:
(1)先给个大量语料库,定义一下N的值,N=1,叫做Uni-Gram,N=2,叫做Bi-Gram,N=3,叫做Tri-Gram,这三种Gram是最常见的,除非特殊情况,否则N别再往下加了,那样计算量会非常之大,得不偿失。而且通过我自己就实验过,N取过大,模型的表现很多时候并不会更好,通常N取2就够了。
(2)对语料库中的文本进行分词,再按照N的值计算N个词出现的概率值,比如N=1,是一元模型,最简单了,每个词都是相互独立的,直接计算其出现的概率即可;N=2时,先计算N=1的情况,再按照条件概率计算N=2的情况,即我们在第三节中介绍的;N=3时,依次计算N=1、N=2、N=3的情况,以此类推。
(3)计算完所有词在N的情况下的概率值,把它存成一个文件,那么这个文件,就是我们的模型了。
(4)在使用的时候,我们先加载这个模型,然后给一测试的句子,把这句话分个词,然后将分词结果按照N的值(这里的N值必须和模型文件的N一致)去模型文件中寻找对应词的概率值,这里注意一个细节,假如我们的N是3,那么优先找N=3时的那些概率值,如果模型文件中没找到测试语句中包含的三个词组成的gram怎么办?比如你的测试语句中有“春天 的 味道”,但是在模型文件中并没有找到这三个词连着的情况,这个时候,我们就要用回退机制,即退而求其次,找N=2的情况中是否有“春天 的”这种情况,如果有,就用这种情况的概率值,如果没有,就继续找N=1的情况中是否还有“春天”这个词的概率值,由此也可以看出,我们的模型文件实际上存储了N,N-1,N-2,……,1这些情况下的gram的概率值。那么如果说N=1的情况仍然没有找到,也就是你的训练语料中压根就没有“春天”这个词,怎么办?这个时候,我们就用到平滑机制了。也就是说,我们可以强制性的让所有的n-gram至少出现1次,即在计算每个n-gram的概率值时,分子上+1,分母加|V|,|V|表示语料库中词(无重复)的总数,这种方法被称为Laplace smoothing,但是这种平滑方法在语料库词量很大时容易造成分母过大,使得概率过于稀疏,所以还有一种方法是分子上加k,分母加上k|V|,压缩一下|V|,这种方法叫做Add-K,当然,还有一些其它的平滑方法,这里不做重点介绍了,感兴趣可以自行查阅。
值得一提的是,上述提到测试语句在模型文件中缺省的问题,在NLP领域叫做OOV(未登录词)问题,这种问题不仅在N-Gram中存在,在其它就算是神经网络语言模型也都是存在的。OOV问题的解决方案有很多,比如扩充词典、直接忽略、用特定标记表示等,总之,问题的本质就是训练集不够丰富,其解决方法很有学问,具体的方法本文不做重点介绍,大家感兴趣可自行查阅资料。
(6)我们把测试语句中各个词在模型文件中找到的概率值相加,就是测试语句的概率值了。
补充:事实上,当样本量足够大的时候,根据大数定律,频率会依概率收敛到某个值,换句话说,概率可用频率表示。即:
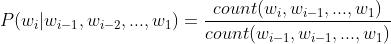
好了,现在我们说明了如何统计出一个N-Gram模型,也说明了如何拿它进行测试,那么一个完整的流程还缺少一个模型检验,就是判断一个模型的好坏。这个时候,我们就需要用到困惑度(perplexity)的概念,困惑度的计算也是个很有学问的问题,这里我们就介绍一个简单的N-Gram的困惑度计算方法。
当给模型一个测试语句时,如果模型从未见过它,那么模型就会对这句话表示很困惑,直观上讲,困惑度越大,说明这句话越“不像人话”,如果明明一句话很符合逻辑,但模型偏偏很困惑,那说明你的模型表现不是很好。具体地,困惑度有如下计算公式:
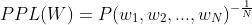
PPL不仅能衡量一句话的好坏,也能衡量一个模型的好坏,当衡量一句话的好坏时,直接将句子的概率值套用上述公式即可,PPL越大,句子越差,反之句子越好。当衡量一个模型的好坏时,我们通常会拿不怎么好的测试集和好的测试集分别对模型进行对比测试,如果模型在两种测试集上表现的相当,说明模型不是很好。
至此,关于N-Gram的基本介绍都讲解完毕。现在N-Gram基本都用于一些简单的场景,例如语音识别中判断语音识别出的句子正不正确,还有黑产文本攻击时过滤机器生成的文本等,随着语言大模型的到来,这种模型已经很难判断出一句话是否为机器生成的了,因为模型生成出的语言已经和人类的说话风格没有区别了。但是N-Gram仍然是我们入门自然语言处理很好的基础知识,大家还是需要好好了解一下。
总的来说,N-Gram语言模型简单、直接,高效,容易理解,有很多现成开源工具已经能够很好地帮我们实现N-Gram模型生成,这里推荐SRILM和KenLM,具体使用方法很简单,大家自行尝试,此外,N-Gram语言模型又很粗糙,仅仅是对训练语料做一些统计计算,根本们无法考虑语义信息,而且当语料库很大时计算量大,模型文件也会很庞大,同时也说明了N-Gram强依赖于语料库,泛化能力很差,语料库只要没出现过的,它就无法很好地给出正确的PPL值。
所以接下来,我们将会介绍更加“智能”的基于神经网络的语言模型,拭目以待~
参考文档:
【1】语言模型(一)—— 统计语言模型n-gram语言模型_知了爱啃代码的博客-CSDN博客
【2】https://www.cnblogs.com/miners/p/14984990.html
以上是关于大道至简浅谈自然语言处理(NLP)学习路线:N-Gram模型,一文带你理解N-Gram语言模型的主要内容,如果未能解决你的问题,请参考以下文章