跟随袁博老师学数据分析-清华大学-数据挖掘:理论与算法
Posted 超级可爱的夹心小朋友
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了跟随袁博老师学数据分析-清华大学-数据挖掘:理论与算法相关的知识,希望对你有一定的参考价值。
视频:P15-18
特征选择:
熵:泛指某些物质系统状态的一种量度,某些物质系统状态可能出现的程度。
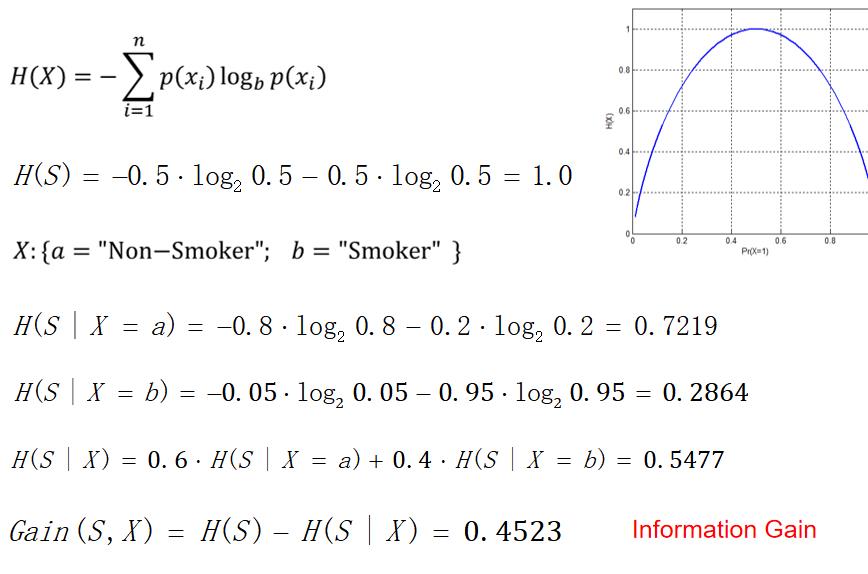
信息增益:当知道一个额外属性之后,对系统的不确定性降低多少就是信息的增益,例子:猜一个人是男人还是女人,此时是男是女的概率各百分之五十,熵为1,当提供另一个额外信息,这个人抽烟,抽烟这个属性的男女比例不一样,男女抽烟比例如下图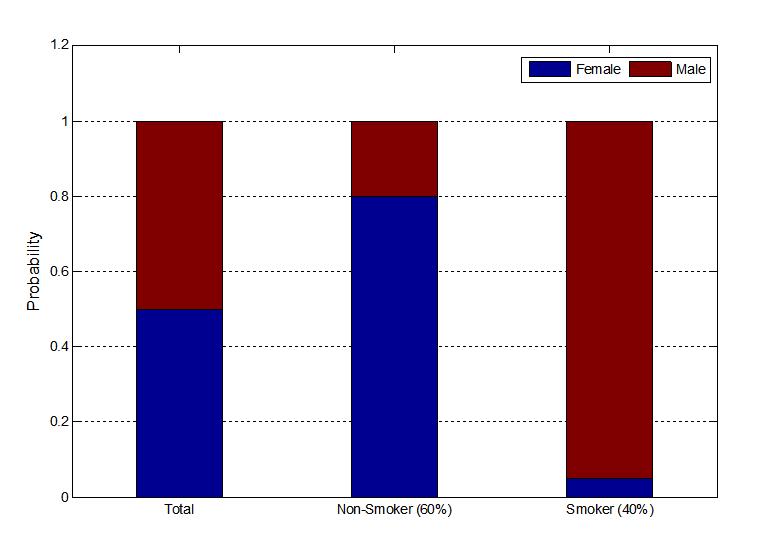
在特征选择的过程中也会遇到组合爆炸的问题:例如20个属性里面选5个就会有15504种可能性。
选择分支结构,branch and bound
一个个比较,最好的属性叠加在一起
正向选择,依次增加,在第一个最好的属性里叠加第二个属性,在两个属性最好的那一个为出发点再叠加第三个属性。
方向选择,依次减少。
特征提取:降维:投影
数据满足高斯分布,协方差大意味着信息有价值,选取区分度大的特征项
一种类别:PCA主成分分析法:计算矩阵的特征值特征向量,挑选大的特征值对应的特征向量
两种类别:LDA线性判别分析:可分度要大,属性之间不重合。
以上是关于跟随袁博老师学数据分析-清华大学-数据挖掘:理论与算法的主要内容,如果未能解决你的问题,请参考以下文章