论文阅读CenterNet
Posted 우 유
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读CenterNet相关的知识,希望对你有一定的参考价值。
论文题目:Objects as Points(CVPR2019)
论文地址:https://arxiv.org/pdf/1904.07850.pdf
发布时间:2019.4.16
机构:UT Austin,UC Berkeley
代码:https://github.com/xingyizhou/CenterNet
【论文】
Intro
1、Object Detection方法大多基于box,列举所有可能的复选框,在进行后处理筛选,低消耗时。One-stage:anchor(slide/possible box)直接分类;two-stage:计算box们的图像特征饼对特征分类,然后NMS对所有可能的box设置IoU阈值去重复处理(导致无法端到端训练),虽然后处理复杂些但是效果还是不错的。
3、related work (总结就是CenterNet不用grouping/post-processing/复杂操作所以简单高效)2、本文CenterNet
①present a new representation for objects: as points.对目标的新表示方式:点
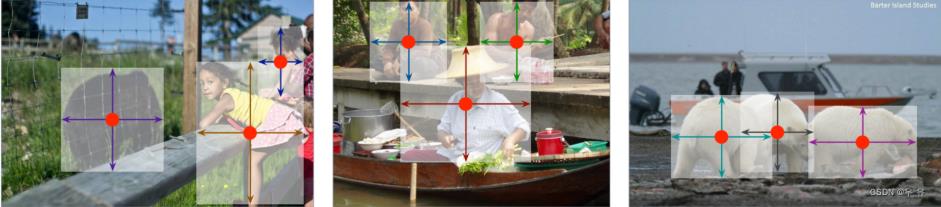
②finds object centers, and regresses to their size.先找到目标中心,再回归其他属性 ③The algorithm is simple, fast, accurate, and end-to-end differentiable without any NMS post-processing.特点 说明: The bounding box size and other object properties are inferred from the keypoint feature at the center.We simply feed the input image to a fully convolutional network that generates a heatmap. Peaks in this heatmap correspond to object centers. Image features at each peak predict the objects bounding box height and weight.(通过一个FC生成热图,选取peaks作为目标物体的中心,然后根据每个peak图片特征去回归其他属性。Anchor-Free ) All outputs are produced directly from the keypoint estimation without the need for IoU-based NMS or other post-processing.
Region Classification(区域分类):区域/特征分类:都是基于RPM
Implicit Anchors(隐式):设定foreground or not的判定阈值,对region再次分类&多分类。CenterNet与之相似但有些不同之处:①定物体只基于位置而不是overlap程度(不用设定筛选阈值了);②一个物体一个预测所以不用NMS筛选重复冗余目标物;③更大的output relution(别人输出步长16它4)。就是一次性定位物体,不用麻烦的后处理(下图)。
Keypoint Estimation(关键点估计):前人工作的CornerNet和ExtremeNet在关键点检测之后都有个grouping stage慢呐。
Monocular 3D(单目三维)目标检测

CenterNet
1、关键点估计
输入图像I,输出位关键点热图Yˆ(1关键点0背景)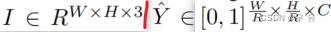
①Keypoint types include C = 17 human joints in human pose estimation, or C = 80 object categories in object detection② We use several different fully-convolutional encoder-decoder networks to predict Yˆfrom an image I: A stacked hourglass network, up convolutional residual networks (ResNet) , and deep layer aggregation (DLA)
2、Objects as Points
use a single network to predict the keypoints Yˆ , offset Oˆ, and size Sˆ.(具体实现方式与细节扒了代码再来)
两个应用的实现细节:
(1)3D检测:标量depth、3D dimension、orientation(add a separate head for each of them)
(2)人体姿态估计:


3、Implementation
(1)experiment with 4 architectures: ResNet-18, ResNet-101, DLA-34 (deformable convolution layers修改) and Hourglass-104 as it is. Hourglass: downsamples the input by 4×, followed by two sequential hourglass modules. Each hourglass module is a symmetric 5-layer down-&up- convolutional network with skip connections.(先下采样4x然后跟2个连续沙漏模块[each对称的5层下5层上卷积with连接]) ResNet:(修改:上采用输出通道并在前加3x3deformable卷积、双线性插值) Deep Layer Aggregation(DLA):是一种具有分层跳跃连接的图像分类网络。(修改:增加特征图分辨率、每个上采样层用3x3deformable卷积代替原来卷积)
(2)训练:input 512x512=>output 128x128、数据增强、epoch/lr/预训练模型、
推理(三种测试增强):不增强、翻转增强、翻转和多尺
Experiments
dataset:MS COCO=118ktrain+5kval+20ktest (附录补充了PascalVOC数据集上的实验)
Metrics:FPS、AP平均精度(不同IoU筛选阈值下)、
1、目标检测
(1)使用下预训练过的模型来测试同一设备上每个模型的运行时间: https://github.com/facebookresearch/Detectron https://github.com/pjreddie/darknet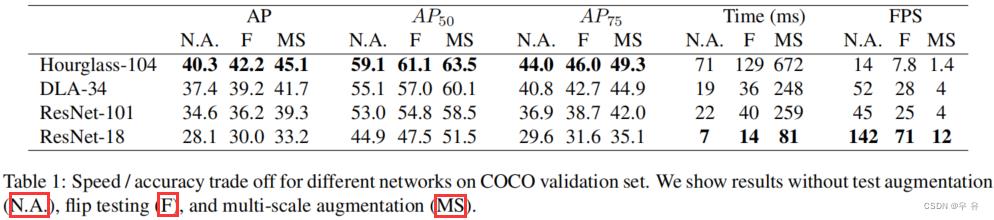
(2)与SOTA的比较
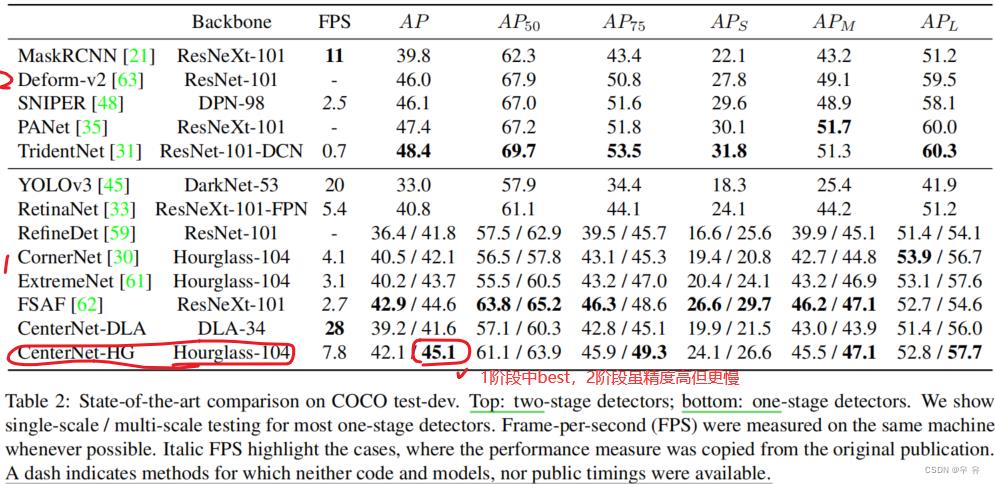
(3)补充实验
①a:不同物体的中心点重合:先统计出现频率再不同方法实验看效果如何(we better)
②NMS在CenterNet中不必要:作为后处理(提升太小0.5%没必要)
③训练与测试的分辨率:train-512x512,test-原图&zero-pad(原图稍好一些512也行384不行)
④c:回归损失:L1比SmoothL1好挺多
⑤b:λsize的敏感度:大AP值下降更快,并给出了解释
⑥d:训练时间:多少epoch时lr下降对训练时长vsAP

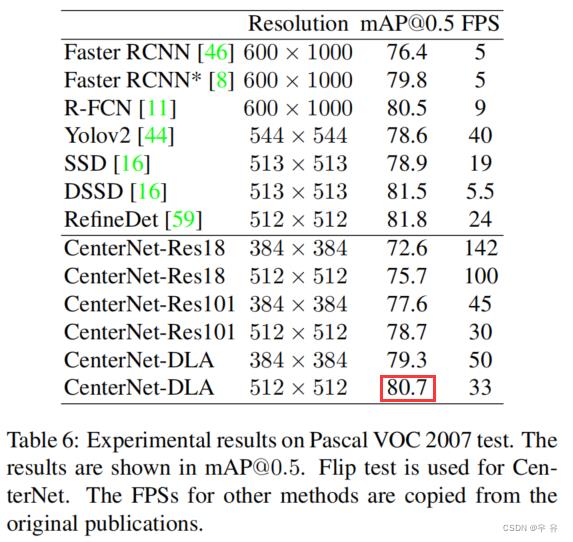
(4)附录中PascalVOC数据集上的实验(小目标检测)
Dataset:16551train+4962test(20个类别)
Metrics:mAP(IoU阈值0.5)
Model:ResNet-18, ResNet-101, DLA-34x2分辨率
2、3D检测
dataset:KITTI驾驶场景
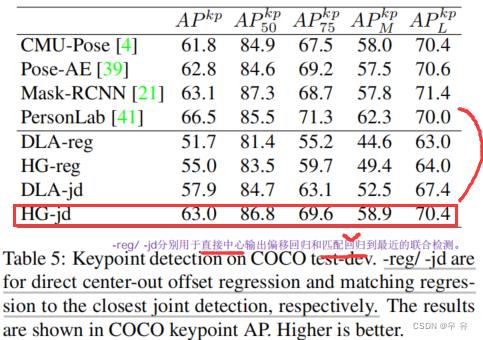
3、姿态估计
dataset:MS COCO(用目标关键点相似性代替box方法中的IoU)
model:DLA34、Hourglass104不同时间收敛;loss权重=1其他超参和目标检测一一致
4、补充的Error Analisis
replacing each output head with its ground truth. For the center point heatmap, we use the rendered Gaussian ground truth heatmap. For the bounding box size, we use the nearest ground truth size for each detection.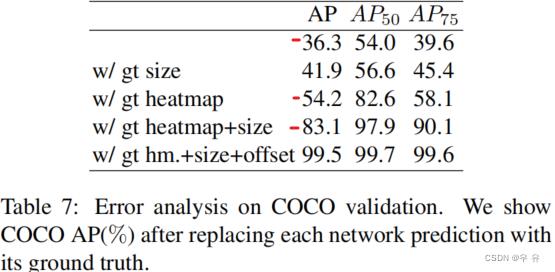
【others翻译、论文解析】
目标检测之CenterNet:属于Anchor-free系列的目标检测,与之前的CornerNet相比较,使用中心点表示物体,从而增强其对内部信息的感知能力。
CenterNet目标检测器是一种关键点估计网络,找到目标的中心,回归出他们的尺寸。同样作为Anchor-free的方法,CenterNet则针对CornerNet对内部语义缺失的问题,提出了对中心点进行估计的方法。
Introduction:本文的方法通过中心点来呈现目标,从而将目标检测问题转换为关键点的估计问题。通过提取得到一个热图,而热图的峰值点即为中心点,利用峰值点位置来预测目标的宽高信息。这种简洁的方法也使得CenterNet能够达到很高的速度。
Related Work:本文的方法接近于anchor-based one-stage的方法,但也有一些不同点。首先,CenterNet是基于位置设置锚点,而非box overlap,且没有进行人工设置阈值做前后景分类。其次,每一个目标上仅有一个正的锚点,因此不需要NMS处理,且仅提取关键点热图的局部峰值点。第三,与传统的目标检测器相比较,使用更大分辨率的输出图像,因此不需要多重锚点。 之前也有基于关键点估计的方法,比如ECCV2018中Detecting Objects as Paired Keypoints所提出的CornerNet就首次应用了以关键点估计为导向的目标检测方法,同时还包括CVPR2019中的Bottom-up Object Detection by Grouping Extreme and Center Points中提出的ExtremeNet。然而这些方法在关键点检测之后都需要一个combinatorial grouping stage。

Implementation:作者实验了四种结构:ResNet-18,ResNet-101,DLA-34,Hourglass-104。其中,利用deformable convolution layers修改ResNet和DLA-34,对Hourglass则按照原样使用。
anchor-free之CenterNet的浅析与实现:CenterNet没有用到什么花里胡哨的东西,不过是将keypoints思想和encoder-decoder结构用在了目标检测任务中来,整篇文章看起来的最大感受就是:干净。每次有小任务的时候,我都会优先考虑用它来做,而不是YOLO,毕竟少了调anchor box的麻烦。【作者也提供了自己的项目代码,但是有改动,ResNet18/SPP/512x512】
CenterNet中的YOLO思想:
(1)检测中心点:YOLO的特色就在于只考虑中心点作为positive samples,在YOLO中,只有中心点所在的网格点会被考虑,其他均视为负例,而CenterNet则没有直接抛弃掉周围的点,而是赋予了更小的权重,权重的计算就是简单的用高斯函数(确定中心点选取的方差用的就是CornerNet的代码,默认两个方差一样,画出来的高斯区域是个圆[向下取整])
从高斯函数可以看出,中心点的权重就是1,周围逐渐降低,达到了“软阈值”的目的。再补充一点,这个阈值是针对中心点的heatmap的,至于offset和wh的学习,只有中心点这一个正样本去回归offset和wh,其他被软化的样本都不会去回归offset和wh,所以,这种“软阈值”的办法只是针对中心点的位置本身的。(根据阈值定中心点,然后根据中心点去回归其他量),CenterNet是在更大分辨率的feature上做检测的。相较于YOLO那种硬阈值确定中心点的方法,在这种大尺度分辨率的feature上做预测,软化要更好。
(2)学习偏差offset:和YOLO一样,由于降采样和feature map坐标是整数,因此在feature map算出来的中心点坐标都是整数,小数点都被舍掉,从而在反解的时候,就会有很大偏差,这种偏差会随着stride的增大和增大,因此,CenterNet也要去学这个偏差,这和YOLO一样,只是YOLO当时并没有去强调这个,而CenterNet在论文里把这个事拿出来说了,还有模有样的。按照CenterNet的官方代码来看,这个offset使用线性输出+L1损失函数来学习的,遵从YOLO的方式,因为offset是在01之间的,因此自然而然地选择了sigmoid函数,也就自然而然地选择了BCE损失函数。
另一方面,CenterNet本身是anchor box free的方法,即不使用任何的先验框,直接回归bounding box的wh,不使用先验框,也就意味着不能像anchor box based的方法那样,通过先验框本身的尺度信息就能自动分配到FPN的各个尺度上去。所以,如果想用FPN的话,就得需要考虑一下如何设定一个决策方式,将各个框分配到各个尺度上去,比如FCOS,FoveaBox等。 不过,CenterNet并不想这么麻烦,因为它把OD问题视为关键点的回归,因此就用了encoder-decoder的方式,在一张很大的feature map上去回归,原文中用的是stride=4的feature map,这么大的feature map其实很精细了,大部分的小目标信息都能回归出来。CenterNet是采用Deconv来做上采样的,不同尺度的特征没有进行融合。其实,这里也可以参考Hourglass的做法, 使用上采样操作+融合来得到大分辨率的feature map.
CenterNet的思想与很多主流检测器RetinaNet、FCOS和YOLO等是不同的。后者们是一种分而治之的方式,即采用多个不同尺度的feature map去检测不同尺度的物体,不同尺度相当于不同的焦距,从而聚焦于不同大小的物体上。// 而CenterNet则是合而治之的方式,我们通过这么大的feature map去回归,既能有小物体,也能有大物体,所有物体的尺度信息都在一个feature map上就OK了,这和TridentNet有异曲同工之妙,只不过TridentNet最后还是分支了。在没有一个可靠的理论解释前,实验结果有很大说服力的,从CenterNet在COCO上的表现就可以看出,这种单级检测的合而治之的方式完全不比的多级检测的分而治之的方式要差,整体的框架还更加简洁。over
在推理的时候,CenterNet也不使用NMS操作,而是用一个 3×3 的maxpooling核去在输出的map上筛选出全是峰值点的map,然后拿这个map和输出的map做对应,就只有峰值点的map了,之所以这么做,是因为筛选的时候,步长为1,那么同一个峰值点会出现在不同的地方,因此,筛选出来的是用不了的,得和原来的输出的map做一下对应才行(作者更爱用5x5的pooling核)。但是,这种方法还是会有冗余,尤其是很大的物体,仅靠这么小的maxpooling核是很容易筛选出多个峰值点的,所以,后面再加上NMS,还是有好处的,从论文中的结果也能看出来,用了NMS不亏,只是,提升可以忽略不计,因为,也就没必要加NMS了。(如果你的数据集中大物体很多,并且你没法容忍重复框,那我还是建议加上NMS)
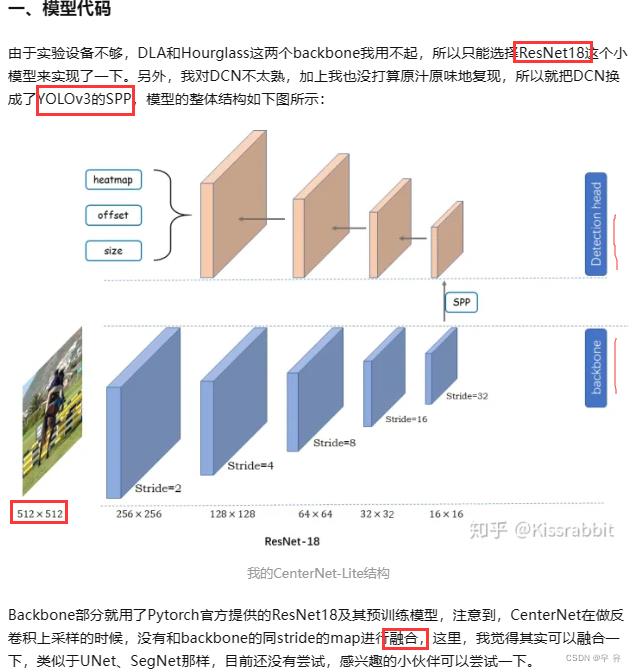
实验过程:①关于两次topk的处理;②ResNet18这一版还是不够强,重复框挺严重的,所以nms抑制一下也是很有必要,时间上的开销几乎可以忽略不计;③Conv2d和DeConv2d以及SPP代码;④label制作☆以及2/2a效果比对⑤
补充内容:
1、NMS(non_max_suppression):IoU 的全称为交并比(Intersection over Union)计算的是 “预测的边框” 和 “真实的边框” 的交集和并集的比值。(通常用于测试阶段) 在预测任务中,会出现很多冗余的预测框,通过NMS操作可以有效的删除冗余检测的结果。非极大值抑制(NMS)顾名思义就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。 IoU 的阈值是一个可优化的参数,一般范围为0~0.5,可以使用交叉验证来选择最优的参数。
对于任意的检测框,设定两个框的IoU阈值作为两者是否合并的评判依据,并执行NMS操作来删除冗余的检测框。(针对单类别)例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。

一个形象的演示 precision是在你认为的正样本中,有多大比例真的是正样本,recall则是在真正的正样本中,有多少被你找到了(可以反应漏检的情况)。[关于mAP说明在link中]
2、Conv2d和DeConv2d以及SPP代码
class Conv2d(nn.Module):
def __init__(self, in_channels, out_channels, ksize, padding=0, stride=1, dilation=1, leakyReLU=False):
super(Conv2d, self).__init__()
self.convs = nn.Sequential(
nn.Conv2d(in_channels, out_channels, ksize, stride=stride, padding=padding, dilation=dilation),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.1, inplace=True) if leakyReLU else nn.ReLU(inplace=True)
)
def forward(self, x):
return self.convs(x)
class DeConv2d(nn.Module):
def __init__(self, in_channels, out_channels, ksize, stride=2, leakyReLU=False):
super(DeConv2d, self).__init__()
# deconv basic config
if ksize == 4:
padding = 1
output_padding = 0
elif ksize == 3:
padding = 1
output_padding = 1
elif ksize == 2:
padding = 0
output_padding = 0
self.convs = nn.Sequential(
nn.ConvTranspose2d(in_channels, out_channels, ksize, stride=stride, padding=padding, output_padding=output_padding),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.1, inplace=True) if leakyReLU else nn.ReLU(inplace=True)
)
def forward(self, x):
return self.convs(x)
class SPP(nn.Module):
"""
Spatial Pyramid Pooling
"""
def __init__(self):
super(SPP, self).__init__()
def forward(self, x):
x_1 = F.max_pool2d(x, 5, stride=1, padding=2)
x_2 = F.max_pool2d(x, 9, stride=1, padding=4)
x_3 = F.max_pool2d(x, 13, stride=1, padding=6)
x = torch.cat([x, x_1, x_2, x_3], dim=1)
return x【代码】
【待阅读】
Cornernet/Centernet代码里面GT heatmap里面如何应用高斯散射核
数据增强N种方法with代码、颜色抖动、数据增强
以上是关于论文阅读CenterNet的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读Objects as Points 又名 CenterNet | 目标检测
论文阅读自然语言模型的尺度法则(CS224N WINTER 2022 Lecture17 推荐阅读整理)
论文阅读自然语言模型的尺度法则(CS224N WINTER 2022 Lecture17 推荐阅读整理)