Elasticsearch:通过例子快速入门
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:通过例子快速入门相关的知识,希望对你有一定的参考价值。
Elasticsearch 是业界最流行的开源企业搜索引擎,应用广泛。 在我们的手机里的 App 背后的搜索引擎好多都是 Elasticsearch,比如我们熟知的抖音,滴滴,美团,携程,点评,银行 app,保险,证券,交友,健康宝等等。如果你想初步了解 Elasticsearch,请阅读我之前的文章 “Elasticsearch 简介”。 我们还学习了如何在 Python 中使用 Elasticsearch。 索引 laptops-demo 已创建并填充了一些示例数据,本文中的查询将基于这些数据。 如果你还没有读过这篇文章,建议先读一读。 但是,如你已经对 Elasticsearch 有所了解,则可以毫无问题地继续阅读本文。

安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的两篇文章来进行安装:
针对一些还没有对 Elasticsearch 及 Kibana 有所认识的开发者来说,我强烈建议参考文章 “Elasticsearch:如何在 Docker 上运行 Elasticsearch 8.x 进行本地开发” 来进行一键安装。我们先不考虑安全的问题。请参考文章中的 “使用 Docker Compose 运行 Elasticsearch 和 Kibana” 章节来进行一键安装 Elasticsearch 及 Kibana。
准备数据
我们有如下的两种方法写入数据:
1)针对有一定 Python 开发经验的开发者来说,你可以参考文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x” 把我们所需要的数据写入到 Elasticsearch 中。
2)在 Kibana 的 Dev Tools 中打入如下的命令:
PUT laptops-demo
"settings":
"index":
"number_of_replicas": 1
,
"analysis":
"filter":
"ngram_filter":
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 15
,
"analyzer":
"ngram_analyzer":
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"ngram_filter"
]
,
"mappings":
"properties":
"id":
"type": "long"
,
"name":
"type": "text",
"analyzer": "standard",
"fields":
"keyword":
"type": "keyword"
,
"ngrams":
"type": "text",
"analyzer": "ngram_analyzer"
,
"brand":
"type": "text",
"fields":
"keyword":
"type": "keyword"
,
"price":
"type": "float"
,
"attributes":
"type": "nested",
"properties":
"attribute_name":
"type": "text"
,
"attribute_value":
"type": "text"
我们到地址 https://github.com/liu-xiao-guo/py-elasticsearch8 下载 aptops_demo.json 文件。然后在电脑上打入如下的命令:
curl -s -H "Content-Type: application/x-ndjson" -XPOST "http://localhost:9200/_bulk" --data-binary "@laptops_demo.json"上面的有些字段的类型可能对初学的开发者并不熟悉。我们先可以不管这些。在我的这篇文章 “Elastic:开发者上手指南” 中的很多文章都有介绍。
这样我们就完成了数据的写入部分了。我们可以通过如下的命令来查看文档的个数:
GET laptops-demo/_count
"count": 200,
"_shards":
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
Dev Tools 操作
我们在 Dev Tools 中可以向 Elasticsearch 发送 REST API 请求并完成我们许多的指令。
创建一个索引
我们可以使用如下的命令来创建一个索引:
PUT /test-index你只能运行此命令一次,否则,你将看到资源已存在的错误。 请注意,前导正斜杠 (/) 是可选的,你可以省略它并且结果相同。
检查集群中的索引
我们可以通过如下的命令来检查集群中的索引:
GET _cat/indices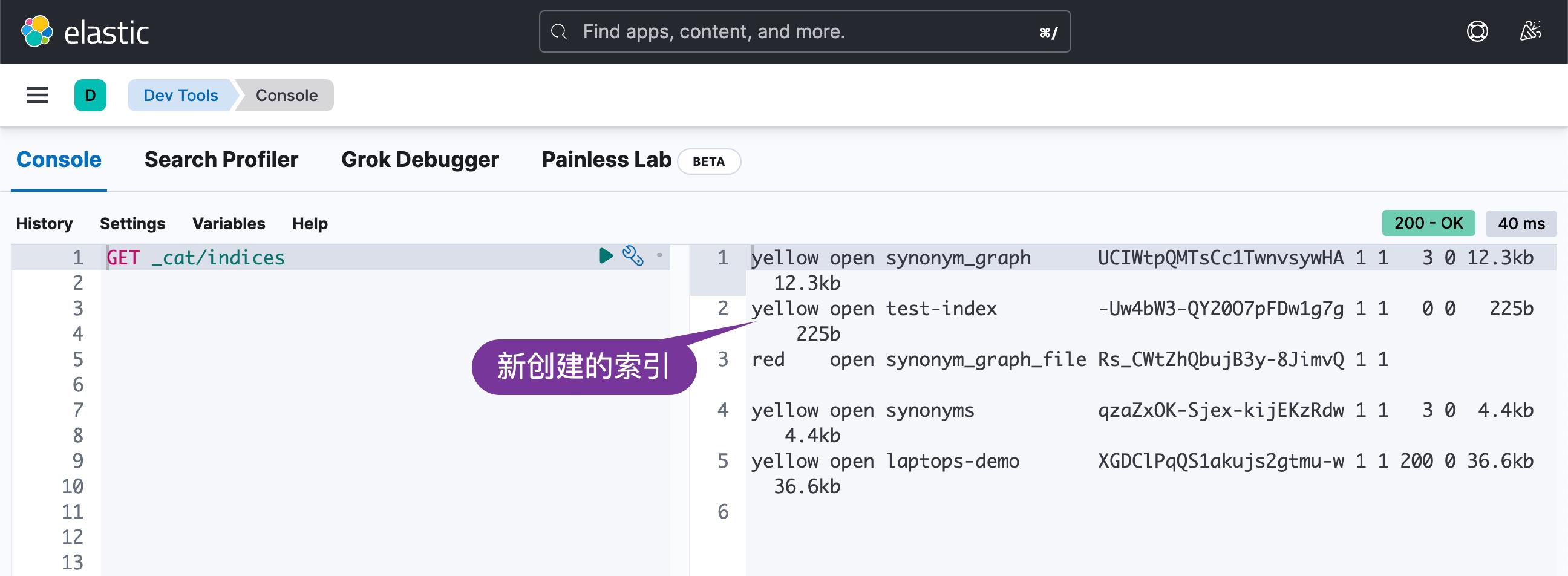
更新索引的设置
我们可以通过如下命令来更新一个索引的设置:
PUT test-index/_settings
"settings":
"number_of_replicas": 2
你需要指定 _settings 端点,否则你将看到使用现有名称创建索引的相同错误。
删除索引
我们通过如下的命令来删除一个索引:
DELETE test-index针对文档的创建(create)、读取(read)、更新(update)和删除(delete)这些 CRUD 操作的基本 Elasticsearch 查询。
在 Elasticsearch 中,索引就像一张表,文档就像一行数据。 但是,与 mysql 等关系型数据库中的列式数据不同,Elasticsearch 中的数据是 JSON 对象。
创建一个文档
PUT test-index/_doc/1
"name": "John Doe"
如果索引尚不存在,此查询将自动创建索引。 此外,还会创建一个带有 name 字段的新文档。
读取一个文档
GET test-index/_doc/1更新一个文档
通过如下的命令添加一个叫做 age 的字段:
POST test-index/_update/1
"doc":
"age": 30
请注意,你必须使用 POST 命令来更新文档。 要更新的字段在 doc 字段中指定。更新完后,我们可以使用如下的命令来进行查看:
GET test-index/_doc/1
"_index": "test-index",
"_id": "1",
"_version": 2,
"_seq_no": 1,
"_primary_term": 1,
"found": true,
"_source":
"name": "John Doe",
"age": 30
我们可以更新一个已有的字段,比如:
POST test-index/_update/1
"doc":
"name": "liuxg"
我们再次查询:
GET test-index/_doc/1
"_index": "test-index",
"_id": "1",
"_version": 3,
"_seq_no": 2,
"_primary_term": 1,
"found": true,
"_source":
"name": "liuxg",
"age": 30
删除一个文档
DELETE test-index/_doc/1现在我们对 Elasticsearch 索引和文档的 CRUD 操作有了一些感受。 我们可以看到,编写 Elasticsearch 查询就像使用 GET、POST、PUT 和 DELETE 方法发出 RESTful API 请求一样。 但是,主要区别在于我们可以将 JSON 对象传递给 GET 方法,这在常规 REST GET 方法中是不允许的。
查询索引
要检查索引中的所有文档,请运行以下命令:
GET laptops-demo/_search它是以下的简短版本:
GET laptops-demo/_search
"query":
"match_all":

从上面我们可以看出来有 200 个文档被搜索到了。你应该能够看到从 JSON 文件添加的所有文档。 现在索引和文档都准备好了,我们可以开始搜索了。
我们已经知道如何检查索引中的所有文档。 默认情况下,返回所有可能难以阅读的字段。 要仅显示特定字段,我们可以指定 _sources 关键字:
GET laptops-demo/_search
"query":
"match_all":
,
"_source": ["name"]
如果你根本不想看到来源,你可以将 _source 设置为 false:
GET laptops-demo/_search
"query":
"match_all":
,
"_source": false
事实上,在最新的 Elasticsearch 发布版中,我们更倾向于如下的一种方式来获取我们想要的字段:
GET laptops-demo/_search
"fields": [
"name",
"price"
],
"query":
"match_all":
,
"_source": false
我们使用 fields 来指定想要返回的字段。
顾名思义,match_all 匹配所有内容。 要根据某些条件进行搜索,我们可以使用匹配关键字。 例如,要搜索名称中包含 Apple 的所有笔记本电脑:
GET laptops-demo/_search
"query":
"match":
"name": "Apple"
从上面的映射我们知道,name 字段是一个 text 字段,会被解析。 简单来说,分析就是将文本字符串小写,拆分成t oken,去掉标点符号。 你可以在此链接上阅读有关分析的更多信息。
要查看如何分析文本,我们可以使用 _analyze 端点:
GET laptops-demo/_analyze
"text": "Apple MackBook!",
"analyzer": "standard"
这里我们使用 standard 分析器,如上所述,它将小写文本,将其拆分为标记并删除标点符号:
"tokens": [
"token": "apple",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
,
"token": "mackbook",
"start_offset": 6,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 1
]
更多关于 Elasticsearch analyzer 的文章,请阅读 “Elasticsearch: analyzer”。
由于我们在索引的设置中定义了一个特殊的分析器 ngram_analyzer ,让我们使用这个分析器来分析我们的文本,看看我们会得到什么:
GET laptops-demo/_analyze
"text": "Apple MackBook!",
"analyzer": "ngram_analyzer"
我们可以看到生成了一堆N-gram:
"tokens": [
"token": "ap",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
,
"token": "app",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
,
"token": "appl",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
,
"token": "apple",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
,
"token": "ma",
"start_offset": 6,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 1
,
"token": "mac",
"start_offset": 6,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 1
,
"token": "mack",
"start_offset": 6,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 1
,
"token": "mackb",
"start_offset": 6,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 1
,
"token": "mackbo",
"start_offset": 6,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 1
,
"token": "mackboo",
"start_offset": 6,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 1
,
"token": "mackbook",
"start_offset": 6,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 1
]
这些 N-grams 对于输入即搜索或自动完成很有用,让我们尝试通过部分输入进行搜索:
GET laptops-demo/_search
"query":
"match":
"name.ngrams": "Appl"
在此查询中,你还可以获得所有 Apple 笔记本电脑。 如果你在 name 字段而不是 name.ngrams 字段中按 Appl 搜索,你将找不到任何内容,因为 name 字段由standard 分析器分析,因此没有 N-gram。
你可能想知道 name 字段和 name.ngrams 字段之间的关系是什么。 嗯,这就是所谓的多字段(multi-fields),就是为了不同的目的,用不同的方式索引同一个字段。 由于始终分析文本字段,因此我们经常为其添加一些额外的字段。 例如,keyword 类型字段通常被添加到文本字段中。 keyword 类型意味着文本将按原样处理,不会被分析。 同一字段的多个字段可以用不同的分析器进行分析。 在本文中,使用 standard 分析器分析 name 字段,使用自定义 ngram_analyzer 分析 name.ngrams 字段,这在不同情况下很有用。
我们已经学习了如何使用匹配查询来搜索文本字段。 还有 long、float 等其他类型的字段,这些字段类似于文本字段的关键字类型,不做分析。 如果我们不想在搜索中分析查询输入,我们可以使用 term 查询:
GET laptops-demo/_search
"query":
"term":
"name.keyword":
"value": "Apple MacBook Model 131"
通过这个查询,我们得到了名字恰好是 “Apple MacBook Model 131” 的笔记本电脑。 如果我们将查询中的任何单词更改为小写或删除任何单词,我们将一无所获。 这是因为,对于 term 查询,我们按原样搜索查询字符串,不会对其进行分析。 Elasticsearch 搜索引擎中存储的文本字段数据不是原始字符串,而是上面用分析器演示的一堆 token。这种搜索也通常被称之为精确匹配。
如果我们想搜索多个值(原样),我们可以使用 terms 查询。 例如,如果我们要搜索 id 为 1、10 和 100 的笔记本电脑:
GET laptops-demo/_search
"query":
"terms":
"id": [
1,
10,
100
]
我们可以使用 range 查询来搜索包含具有给定范围的术语的文档。 例如,让我们搜索价格在 10,000 到 20,000 Kr 之间的笔记本电脑。
GET laptops-demo/_search
"query":
"range":
"price":
"gte": 10000,
"lte": 20000
我们已经知道如何通过 ID 更新和删除单个文档。 有时我们需要更新或删除许多满足某些条件的文件。 在这种情况下,我们可以使用 update_by_query 和 delete_by_query:
POST laptops-demo/_update_by_query
"script":
"source": "ctx._source.price += params.increase",
"lang": "painless",
"params" :
"increase" : 2000
,
"query":
"match":
"brand": "Apple"
在此示例中,我们将所有 Apple 笔记本电脑的价格提高 2,000 Kr。
关键点:
- 在 query 部分,我们使用常规搜索查询来查找需要更新的文档。
- 在script 部分,我们指定如何处理查询找到的结果。 在这里,我们正在进行脚本更新。
- lang 指定要使用的语言。 在 Elasticsearch 中,默认的脚本语言称为 painless,我会说这是一个奇怪的名字。 由于它是要使用的默认语言,因此你可以省略此字段。
- params 指定将在脚本中使用的参数。
- source 指定要运行的源代码。 源码中 ctx 为上下文数据,ctx._source.price 代表查询到的每个文档的 price 字段。
更多关于脚本的学习,你可以参考文章 “Elastic:开发者上手指南” 中的 “Painless 编程” 部分。
对于delete_by_query,就简单多了,因为我们不需要指定源代码来运行。 让我们删除 id 为 1、11、111 的笔记本电脑,仅用于演示目的。
POST laptops-demo/_delete_by_query
"query":
"terms":
"id": [
1,
11,
111
]
默认情况下,查询结果按相关性得分降序排列。 我们也可以按照我们指定的一些字段对结果进行排序。 例如,让我们搜索所有 Apple MacBook 并按价格降序对结果进行排序:
GET laptops-demo/_search
"query":
"match":
"name": "Apple MacBook"
,
"sort": [
"price":
"order": "desc"
]
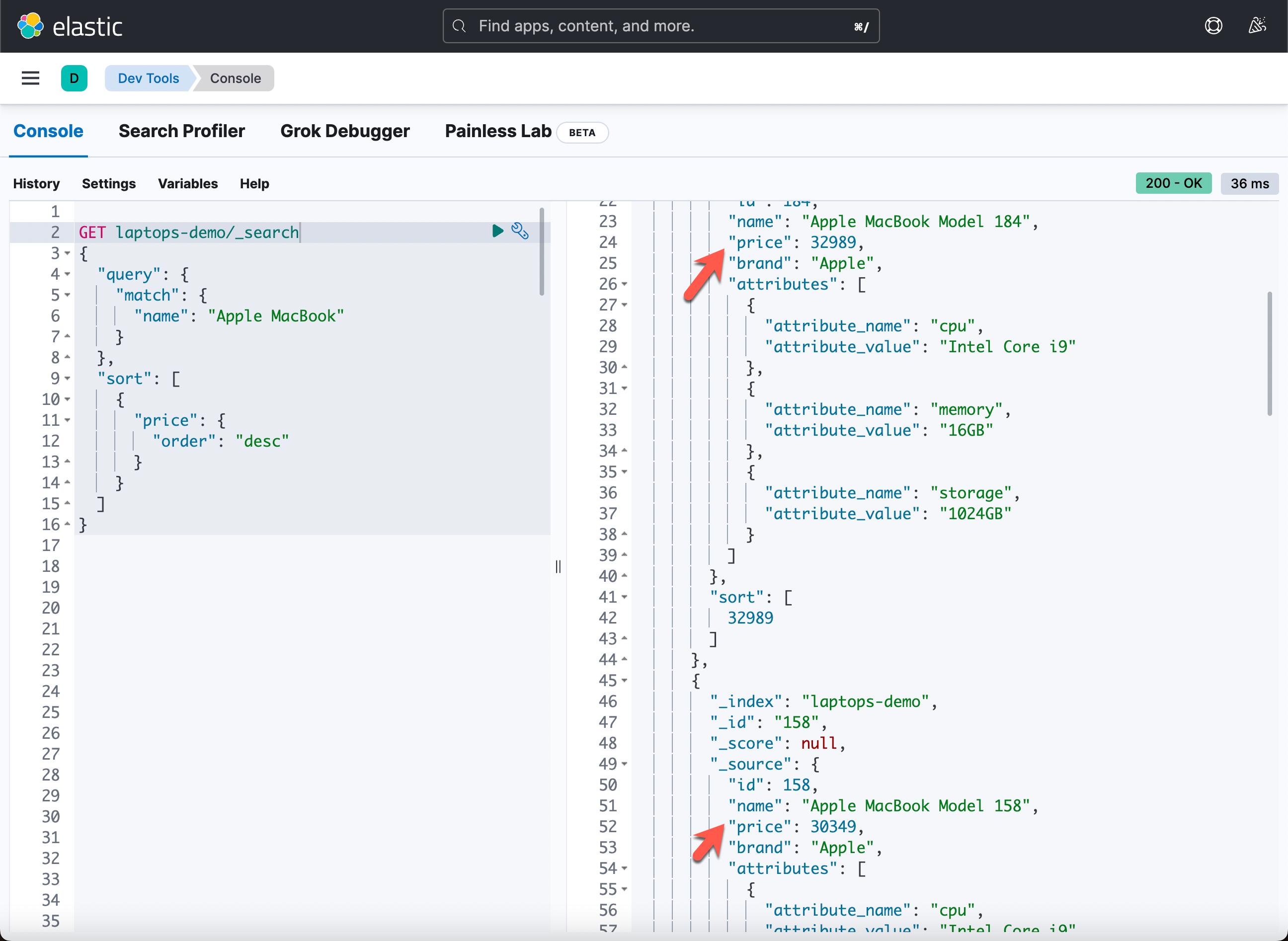
sort 字段需要一个对象列表,这意味着我们可以按多个字段排序。
让我们检查一个更高级的排序示例。 让我们将 Apple 笔记本电脑放在其他品牌之前,然后按 price 升序排列。 为了这个排序目的,我们需要写一些 painless 脚本:
GET laptops-demo/_search
"sort": [
"_script":
"type": "number",
"script":
"lang": "painless",
"source": """
if (doc['brand.keyword'].value == 'Apple')
return 1;
else
return 0;
"""
,
"order": "desc"
,
"price":
"order": "asc"
]
_script 关键字指定我们将按脚本返回的结果排序。 注意,我们不能直接按布尔条件排序,而是需要将布尔结果转化为数值,然后再按它们排序。 type 字段指定从脚本返回的结果的类型,这里我们希望返回一个 number。
在 source 字段指定的 painless 脚本中,doc 变量包含了当前文档的所有字段。 对于常规字段,可以通过 doc['fieldname'].value 访问该值。 对于 keyword 等多字段,可以通过 doc['fieldname.keyword'].value 访问值。
到目前为止,我们只使用了一个查询。 如果我们希望文档满足多个条件,我们可以使用 bool 查询,它使用一个或多个布尔子句构建,包括 must、should、filter 和 must_not。 这就是 Elasticsearch 查询可能变得非常复杂的地方。
默认情况下,Elasticsearch 按相关性分数对匹配结果进行排序,相关性分数衡量每个文档与查询的匹配程度。 相关性分数是一个正浮点数,在搜索 API 的 _score 元数据字段中返回。 _score 越高,文档越相关。 每种查询类型都会以不同方式计算相关性分数。 布尔子句可以在所谓的查询或过滤器上下文中运行。
- must:子句(query)必须出现在匹配的文档中,并将有助于得分。
- should:子句(query)应该出现在匹配的文档中,也就是说它实际上可能出现也可能不出现。 我们可以通过 minimum_should_match 字段指定应该出现多少个 should 子句,如下所示。
must 和 should 查询在查询上下文中执行。 除了决定文档是否匹配之外,查询子句还在 _score 元数据字段中计算相关性分数。
- filter:子句(query)必须出现在匹配的文档中。 但是,与 must 不同的是,查询的分数将被忽略。
- must_not:子句(查询)不得出现在匹配文档中。
filter 和 must_not 查询在过滤器上下文中执行,其中忽略评分并考虑缓存子句,这可以使以后使用相同子句的搜索更快。
作为演示,让我们找到满足以下条件的 Apple 笔记本电脑:
- brand 字段必须包含“Apple”。
- name 应包含 “MacBook” 或 “Pro”,或两者(如果有)。
- price 不得低于 5,000 Kr 或高于 50,000 Kr。
- memory 必须是 8GB。
这是要使用的查询:
GET laptops-demo/_search
"query":
"bool":
"must":
"match":
"brand": "Apple"
,
"should": [
"match":
"name": "MacBook"
,
"match":
"name": "Pro"
],
"must_not":
"range":
"price":
"gt": 50000,
"lt": 5000
,
"filter":
"nested":
"path": "attributes",
"query":
"bool":
"must": [
"match":
"attributes.attribute_name": "memory"
,
"match":
"attributes.attribute_value": "16GB"
]
,
"minimum_should_match": 1
这个演示可能看起来很愚蠢,因为我们在文档中没有很多字段。 在实际情况下,一个文档中可以有几十个字段,布尔查询可以变得非常强大。 本例中使用的 nested 查询将在稍后介绍。简单一句话,如果是针对一个数组来进行查询,需要同时满足其中的两个及以上的属性的查询,我们需要使用到 nested 数据类型。比如,我们需要查询 attribute 的名称为 memory,并且它的值也为 16G,那么我们在这种情况下需要使用到 nested 数据类型。需要特别指出的是 nested 目前在 Kibana 中支持的不是很好。不能使用 nested 字段来进行可视化。
到目前为止,我们还没有解释 laptops-demo 索引的属性字段。 attributes 字段的特殊之处在于它是一个 nested 字段,包含 attribute_name 和 attribure_value 字段作为子字段。 nested 类型是对象数据类型的特殊版本,它允许对象数组以一种可以彼此独立查询的方式进行索引。 我们应该始终为 nested 字段创建映射,如本例所示,因为 Elasticsearch 没有内部对象的概念。 因此,它将对象层次结构扁平化为字段名称和值的简单列表。 如果你查询展平的对象,你将得不到预期的结果。
要查询 nested 字段,我们可以使用 nested 查询。 让我们找出内存为 16GB 的所有笔记本电脑:
GET laptops-demo/_search
"query":
"nested":
"path": "attributes",
"query":
"bool":
"must": [
"match": "attributes.attribute_name": "memory" ,
"match": "attributes.attribute_value": "16GB"
]
关键点:
- nested 关键字指定我们正在查询 nested 字段。
- path 指定 nested 字段的名称,在本例中为 attributes。
- bool 表示我们正在使用布尔查询,因为我们希望 attribute_name 和 attribute_value 字段都满足某些条件。
- must 表示子查询必须全部出现在文档中。
- match 表示全文搜索,因为 attribute_name 和 attribute_value 字段都是文本字段。 如果其中一些不是文本字段,我们需要使用 term、terms 或 range 查询。
Elasticsearch 不仅仅是一个搜索引擎,它还提供了非常强大的分析功能。 在 Elasticsearch 中,分析通常是通过 aggregations 来完成的,聚合将我们的数据汇总为指标、统计数据或其他分析。
你可以通过指定搜索 API 的 aggs 参数来运行聚合作为搜索的一部分。 最常见的聚合类型是 terms 聚合,它是一种基于多桶值的聚合,其中桶(bucket)是动态构建的 —— 每个唯一值一个。 请注意,此处的术语字段与查询中使用的字段不同。 terms in aggs 表示聚合方法是多桶聚合,而 terms in query 表示返回在给定字段中包含一个或多个确切术语的文档。 terms 查询与 term 查询相同,只是你可以搜索多个值。
让我们计算每个品牌的产品数量。 请注意,术语聚合应该是 keyword 类型的字段或任何其他适合桶聚合的数据类型,例如离散数值。
GET laptops-demo/_search
"aggs":
"brand-count-agg":
"terms":
"field": "brand.keyword"
默认情况下,搜索结果显示在聚合结果之前,这会使后者难以阅读。 如果我们只想看到聚合结果,我们将 size 设置为 0,这意味着不会显示任何查询结果。
GET laptops-demo/_search
"size":0,
"aggs":
"brand-count-agg":
"terms":
"field": "brand.keyword"
我们也可以在聚合前指定搜索条件。 例如,我们只统计价格超过 20,000 Kr 的笔记本电脑。
GET laptops-demo/_search
"size": 0,
"aggs":
"brand-count-agg":
"terms":
"field": "brand.keyword"
,
"query":
"range":
"price":
"gte": 20000
当你有更多要求时,聚合可能会变得复杂。 可以基于多个字段进行聚合,通过正则表达式过滤值,写一些脚本在聚合前转换数据等。如果你想有更高级的聚合,可以查看官方文档。更多关于聚合的文章,请参阅文章 “Elastic:开发者上手指南” 中的 “Aggregations” 章节。
我们在本文中介绍了很多关于 Elasticsearch 的内容。 如果你已经了解了基本知识和查询,那么你可以开始在工作中编写自己的查询。 但是,还有很多东西需要学习,本文无法涵盖。 这篇文章的目的是给大家一个大概的介绍,如何在不同的场合使用 Elasticsearch 查询,让大家可以快速上手或初步对 Elasticsearch 有所了解。 我希望你喜欢这篇文章。
以上是关于Elasticsearch:通过例子快速入门的主要内容,如果未能解决你的问题,请参考以下文章