快速上手搜索引擎的秘密武器——Lucene
Posted Java4ye
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了快速上手搜索引擎的秘密武器——Lucene相关的知识,希望对你有一定的参考价值。
这篇文章介绍下这个 Lucene,下篇写写 ElasticSearch , 然后再继续填 Spring 的坑 🕳
内容的话就很基础啦🐖,希望能帮你快速入门,了解下它
目录
为啥要介绍这个 Lucene 呢?毕竟它是搜索引擎核心中的核心
其实是因为我想体验下这个工具包,试着感受下 ElasticSearch 为啥要封装它?以及他们之间的联系~ 等🐖
Lucene
Lucene 是一个开源的,全文索引工具包。有 索引,搜索,分词 等功能
是 ElasticSearch 和 Apache Solr 的核心。
在 mysql 中,Innodb 和 MyISAM 的索引结构都是 B+树, 而到了 Lucene , 就不得不说下这个倒排索引了。
倒排索引
这个就是通过 value ——> Key ,感觉有点像 MySQL 的回表操作🐖,但是这里还有 分词,文档 等概念。
比如我们平时在 百度,Google ,电商平台等中进行搜索时,就是通过这个 关键字 找到相应的 文档 内容出来
概念
下面会介绍下这些概念 👇
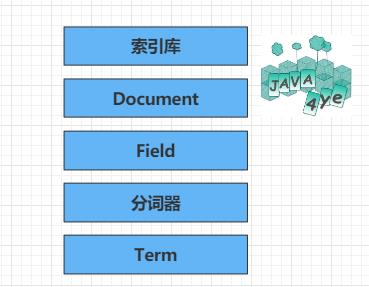
他们之间的关系就用这个来表示啦,这个也是本文的重点🐖
下面开始一一介绍啦😄
文档
对应 Document 对象 👇
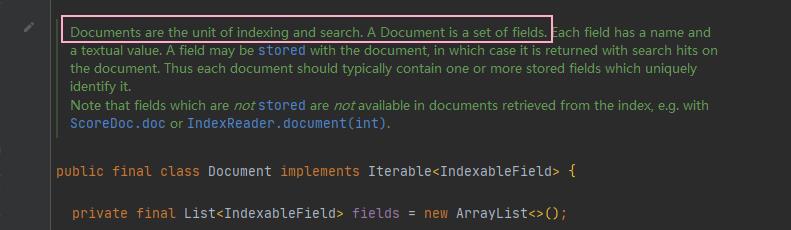
文档 是 Lucene 内部的数据结构,索引文档时,会按照一定规则去创建索引,生成倒排索引文件。
查询时就直接搜索到对应的索引文件,获取数据,效率非常高!
它是搜索和索引的单位,也是字段的集合。
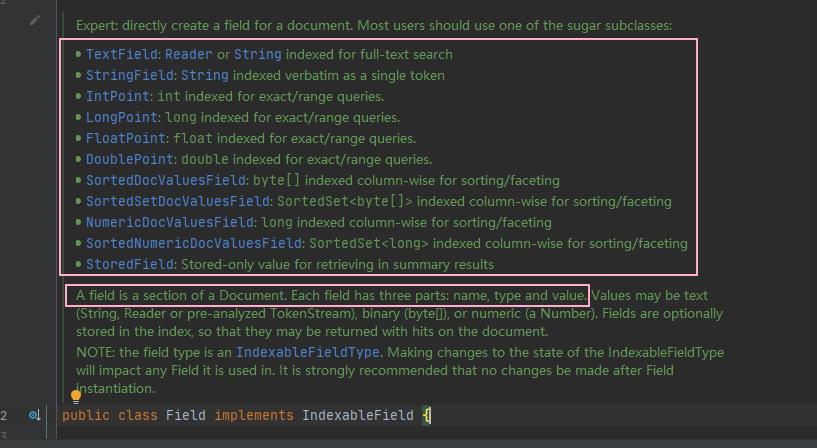
字段
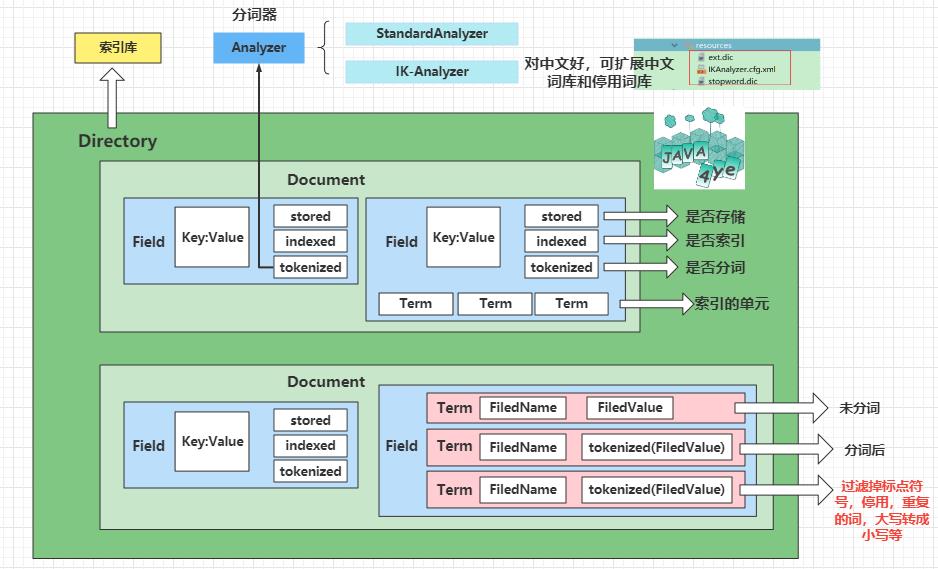
对应 Field 对象 👇 ,由三部分组成 :name,type,value
- name :字段域名, 可以看作我们创建的 Model 的属性名称,如 name,age,id 等等,在同个索引库中是唯一的
- value : 字段值, 存储文档的部分内容,如
name:Java4ye这个 Field 中的值 Java4ye - type : 字段类型,如 是否分词,索引,存储 等
词汇
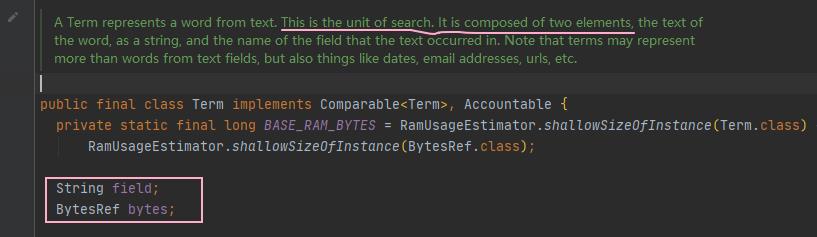
对应 Term 对象 👇 ,由两部分组成 :name,value
- name :Field 的名称 ,即 字段域名
- value : Field 中文档的部分内容 ,即 字段值
如果还不清楚,那么再看看下面这里你就懂啦~
分词
这个是超级核心! 🐖
分词的目的是为了索引,索引的目的是为了搜索,就像查字典一样🐖
分词的过程是先分词,再过滤(过滤掉标点符号,停用,重复的词,大写转成小写等)
比如这个标准分词器 : StandardAnalyzer 👇
通过注释可以发现它会进行 停用词,大写转成小写 的过滤操作。

中文分词器推荐 IK-Analyzer
小结
那么到了这里,咱们再把上面的知识点串一串~ 😄
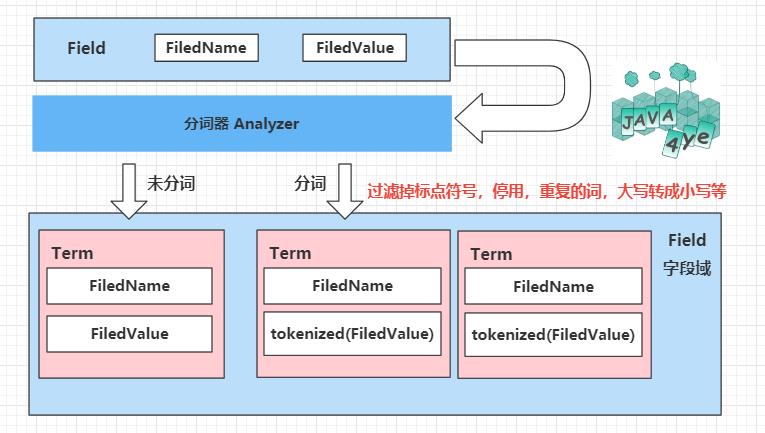
通过咱们这个分词器,会对字段域中的 value 进行分词,当然你也可以根据需求选择不分词。
不分词就一个 Term ,分词后会产生很多 Term,Term 的 name 就是这个 字段域的名称, Value 就是分出来的词。
比如 对 desc:nice to meet you 的字段域进行过分词。会出现这四个单词:nice,to,meet,you
索引库
差点漏了这个~
可以看到里面有 段的概念 Segment 和 锁🔒 等
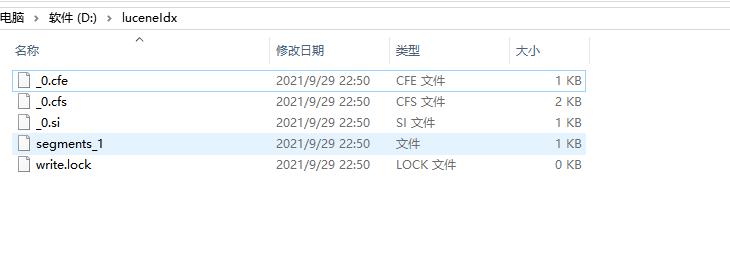
把整个文件夹看到一个 Index,Segment 就是里面的 sub-index。
当创建索引时,不是立刻就刷到磁盘的,需要先写入缓冲区,然后等满了,或者关闭了,手动 flush 等操作才一起写入磁盘,这也是它为什么是 近实时而非实时查询 的原因 🐖
查询时其实就是在 Segment 中查找,需要对多个 Segment 进行合并,搜索,找到相应的 docID ,再去存放数据的文件中获取并返回。
Luke
下载地址:
https://github.com/DmitryKey/luke
这里用这个 Luke 工具演示下 👇
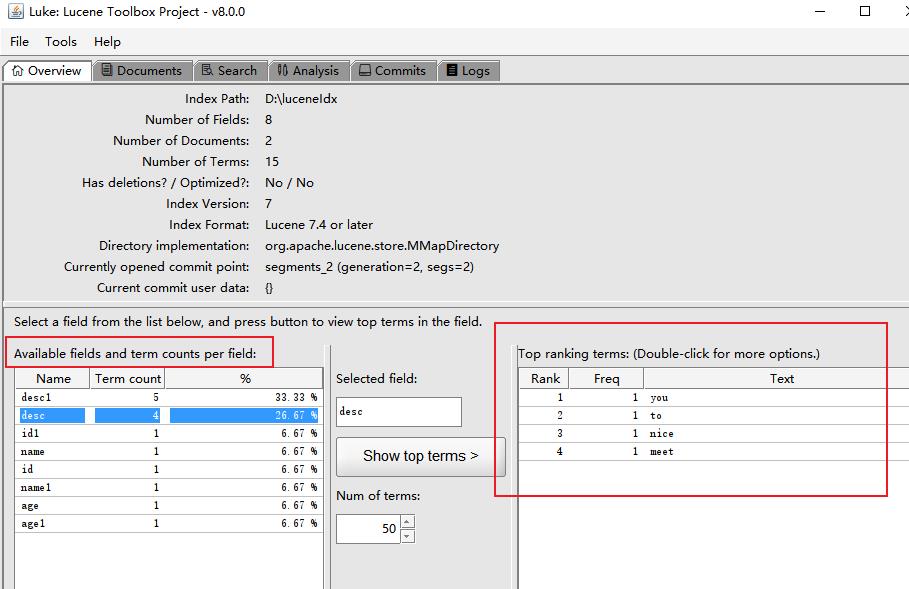
可以看到 desc 字段域分词后有四个 Term 。
上面介绍完了这些概念,这里就来开始实践啦,将这些概念串联起来,代码同样可以在 Github 上获取 👇
https://github.com/Java4ye/springboot-demo-4ye
全文检索流程
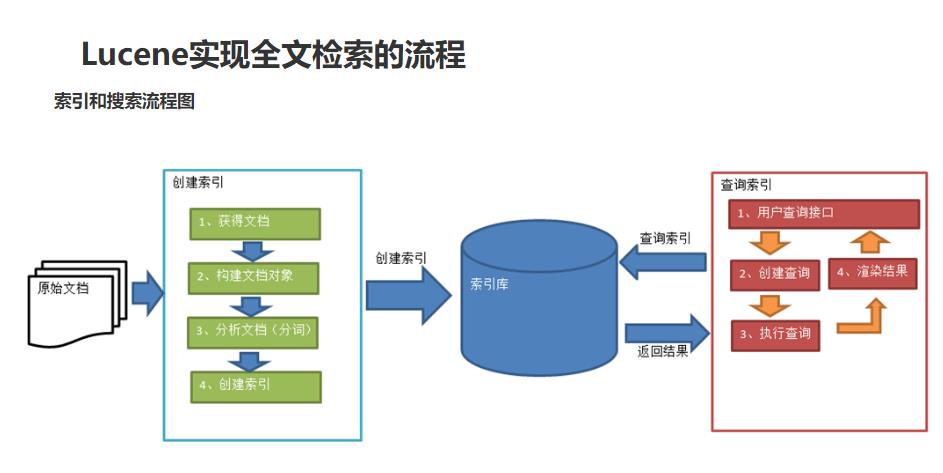
这里就两个操作👉 创建索引 和 查询索引 ,操作步骤写代码里啦,就不多说了🐖
创建索引

查询索引
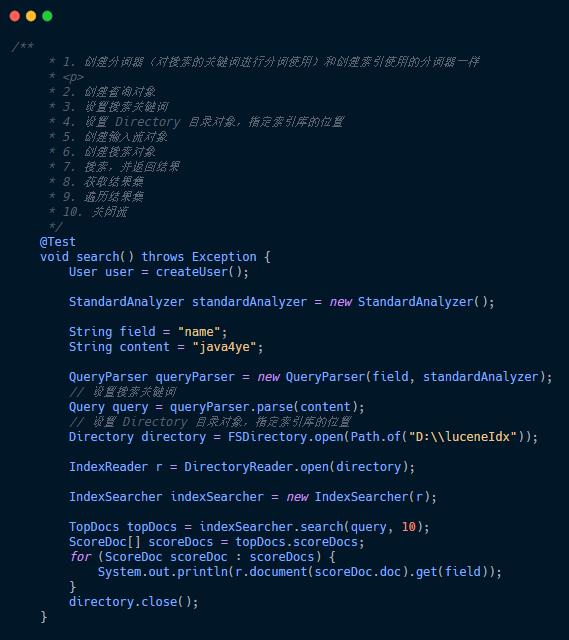
奇怪的收获
由于项目中引入了 ElasticSearch , 它的底层核心又是 Lucene ,所以这里我没有再去引入 Lucene , 而是直接使用,结果却成了踩坑的开始🐖
这里可以看到 Lucene 是8.5.1 版本的,这样 Lulke 工具是运行不了的 ,会报错,但是 Lucene8.0 版本可以运行,所以得重新引包。
为啥报错呢?
可以看到作者在说这个工具不维护了🐖
而 Lucene 也早就捐献给 Apache 了

同时我还发现了 Luke 工具使用到这个 JavaSPI 机制。
还有 Lucene 底层关键字的数据结构是 跳跃表 ( Redis 也用到了), FST 状态机。
FST, 全称Finite State Transducer, 中文翻译: 有限状态转换器或有限状态传感器。
FST 最重要的功能是可以实现 Key 到 Value 的映射,相当于 HashMap<Key,Value>。FST 的内存消耗要比HashMap 少很多,但 FST 的查询速度比 HashMap 要慢。FST 在 Lucene 中被大量使用,例如:倒排索引的存储,同义词词典的存储,搜索关键字建议等
跳跃表 不支持模糊查询 ,FST 支持模糊查询
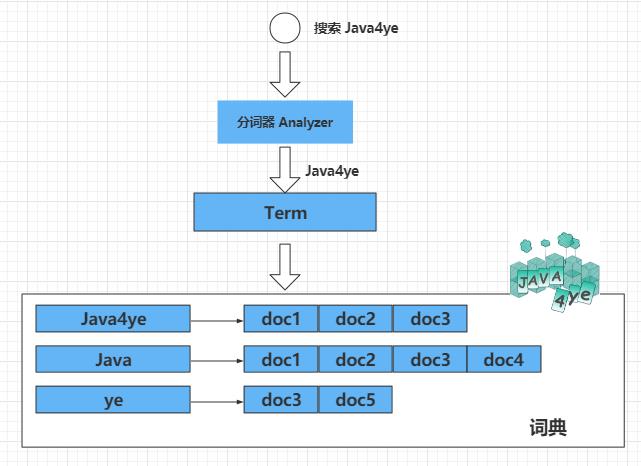
搜过过程
大概就是这样,通过这个词,去找到对应的文档id,再获取文档出来,依据权重啥的排序。
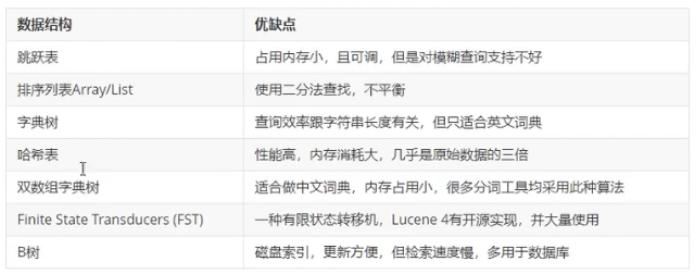
词典数据结构有这么多种👇
最后
本文就分享到这里啦🐖
往细了看,可以发现这里涉及到很多 IO原理,以及底层数据结构的知识,编码上目前就粗略认识到这个 JavaSPI 的使用。
快去敲下代码,了解这些概念吧,这样是不是也能有个基础版的搜索引擎了 哈哈😝
👉 https://github.com/Java4ye/springboot-demo-4ye
喜欢的话可以 点赞 & 关注 并 星标 下公众号 Java4ye 支持下 4ye 呀😝,这样就可以第一时间收到更文消息啦🐷
我是4ye 咱们下期应该……很快再见!! 😆
以上是关于快速上手搜索引擎的秘密武器——Lucene的主要内容,如果未能解决你的问题,请参考以下文章