性能达1.5+倍!昇腾AI助力分子动力学模拟研究
Posted 华为云开发者联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能达1.5+倍!昇腾AI助力分子动力学模拟研究相关的知识,希望对你有一定的参考价值。
摘要:在异构计算架构CANN的助力下,AI预测性能达到现有产品的1.5+倍,可预测规模较传统方法提升10000+倍,为光伏材料、新能源电池、半导体材料研究带来巨大的商业应用价值。
本文分享自华为云社区《性能达1.5+倍!昇腾AI助力分子动力学模拟研究》,作者:昇腾CANN。
研究背景
分子动力学是一套分子模拟方法,主要依靠牛顿力学来模拟分子体系运动,是研究微观世界的有效手段。但传统研究手段的时间复杂度较高,仅限于研究数千量级原子的小型系统,在应用中存在普遍局限性。而深势科技提出的DeePMD-kit可将AI技术成功应用于分子动力学模拟,并实现了上亿原子体系的模拟,目前该项技术已经发展成为端到端的开源解决方案,以科学智能(AI for Science)为分子动力学的行业应用带来了更多可能。
而昇腾AI凭借超强算力及完整软件栈配套,为科学智能提供了天然土壤,通过昇腾AI硬件及异构计算架构CANN,借助软硬件协同能力充分释放硬件算力,为DeePMD的大规模分子动力学模拟提供了高性能解决方案。
基于CANN自定义DeePMD高性能算子
对诸如DeePMD之类的神经网络模型进行加速的关键之一是对网络中的算子进行深度优化,从而发挥出硬件的澎湃算力,而作为专门面向AI场景的异构计算架构,CANN正是搭起了上层深度学习框架和底层AI硬件的桥梁。
基于CANN的算子编程接口,开发人员在DeePMD网络中开发相关的自定义算子,其中涉及到数据排序、读取与存储等离线操作,也涉及矩阵、标量的计算,这些自定义算子不但对精度有较高的要求,而且也很大程度上决定了模型整体的性能。
CANN能够高效协同昇腾不同异构单元自定义高性能算子,充分释放AI Core、AI CPU和Vector Core的异构算力。比如将离散的距离计算和排序部署在AI CPU上,将可以并行的矩阵、标量的计算部分部署在AI Core上,以发挥出每个计算单元的能力,充分发挥硬件计算性能。
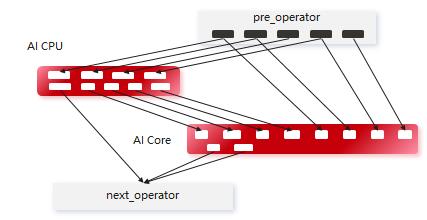
高效协同昇腾不同异构单元自定义高性能算子
基于CANN的DeePMD融合规则及网络优化
算子融合也是网络性能优化重点之一,也是业界常用手段,在DeePMD原生实现中,算子融合就作为性能工程的主要手段之一。
而在DeePMD网络性能优化中,算子开发人员进一步结合网络特点,借助CANN设计新的融合规则,包括PAD算子支持动静合一、Mul支持NZ+ND和ND+NZ、MatMul + Add + TanhGrad支持Buffer融合等,这些融合在整网性能提升中起到了关键作用。同时借助CANN的智能调优工具AOE,自动化完成子图调优、算子调优,以及TransData消除等一系列优化,极大提升了模型调优效率。
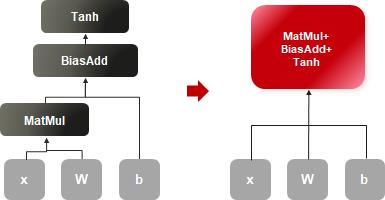
DeePMD网络融合示例
此外项目优化了整网混合精度推理流程,将半精度和单精度混合使用,有效减少内存占用,充分释放硬件算力,进一步加速模型执行,在确保分子模拟精度的前提下带来最大性能收益。在不同场景对分子模拟的物理性质与仿真结果对比测试中,以铜拉伸应力应变模拟实验为例可以看到,昇腾AI基础软硬件平台的实验结果已经非常近似实际数据。

昇腾AI基础软硬件平台上铜的拉伸应力应变模拟结果
昇腾AI的整体优化解决方案使DeePMD-kit工具在分子动力学模拟计算上取得1.5+倍现有产品的性能提升成果,助力分子动力学服务成功商用。未来,昇腾AI将继续以超强算力和软硬协同能力助力科学计算进入科学智能新阶段,携手更多伙伴凝心聚力,共同向上发展,构筑科学智能领先格局,全面迈进数智时代。
以上是关于性能达1.5+倍!昇腾AI助力分子动力学模拟研究的主要内容,如果未能解决你的问题,请参考以下文章
AI星海中的“中国空间站”:昇腾如何助力鹏城云脑Ⅱ实现全球领航