NLP 实战 | 整体设计之数据集/模型管理
Posted 幻灰龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP 实战 | 整体设计之数据集/模型管理相关的知识,希望对你有一定的参考价值。
文章目录
在上一篇 里,我们分析了代码的基础构架。我们从服务拆分和代理、命令行管道、模块依赖局部化、以及本地数据路径管理几个方面分别切入。本节继续分析一些设计上的思路,以及讨论数据管理部分。
团队博客: CSDN AI小组
项目的可拆性
事实上,我们解决的是软件开发中“组合”与“解耦”的问题。一个项目在面对需求增量的压力、数据增量的压力、功能增量压力的情况下,还能保持一致的设计,一致的可测试性,对项目保持健康度非常有用。关于这方面,Google 测试博客上有三篇经典的文章,推荐阅读:
- Hackable Projects - Pillar 1: Code Health
- Hackable Projects - Pillar 2: Debuggability
- Hackable Projects - Pillar 3: Infrastructure
“Hackable” 就是要能在需要时自由地对一个系统的内部进行探测 。也就是上一节说的:“一个程序是一颗树,要保持对这颗树重要节点的可测性”。软件不能是一堆散乱的脚本,因此我们层层组装构造一个系统。但是如果系统是一个铁板一块,内部某个地方出错了不能自由探测,或者探测的成本很高,那么系统就不是 “Hackable” 的。
数据集/模型管理需求
NLP 项目天生是一个管道的数据处理过程:数据获取、数据清洗、数据集构建、模型训练、输出模型、加载模型、提供服务 API,上线部署、测试等等。
这里面有三类不同的数据:
- 训练前的数据集,包含
- 必要的元数据
- 模型训练用的训练集、验证集、测试集
- 训练后的数据:
- 经算法训练后输出的模型数据,比如 SVM 模型数据
- 经算法提取产生的非模型数据,比如 命名实体识别
- 服务应用中产生的数据
- 服务用于清洗历史数据,产生的新结构化数据
- …
NLP 开发过程的上述三类数据不同于增删查系统的数据,增删查的数据一般直接通过数据库系统提供数据状态存储。而 NLP 开发过程中的上述这些数据有这些特征:
- 数据集可能不只是2维表结构,例如可以是一个文件夹,一个文件夹下根据标注分子文件夹;例如是图片数据… 等等。
- 数据训练过程中一般假设处理的数据都在处理节点设备上可本地快速访问,因为数据集一般不会太小。
- 数据集需要在团队不同成员之间同步
- 模型文件也需要在团队不同成员之间同步
- 数据集和模型也可能需要在训练设备和部署设备间同步
数据集/模型同步的方式
如果只有一个人开发,所有的数据都在开发机器上,但是如果要部署,也会遇到开发机器和部署设备间的数据同步。如果是一个团队,团队成员之间需要做数据集/模型同步,同时部署的时候也同样有数据集/模型的同步需求。
我们看下数据同步的朴素方法:
- 通过局域网共享文件夹?对于分布式团队来说,共享文件夹是一个过时的东西。
- 通过聊天工具互传,缺点很明显:每次数据同步都是一个可能 N X N的散乱关系。
- 通过云盘?数据安全是有问题的。
- 挂一个 git 仓库存放?这对 git 服务器和 git 本身都会有问题。
所以,很显然,下面的方式是可以接受的:
- 通过云存储,例如阿里云 OSS
- 直接做 P2P 传输,自动在多节点之间 P2P 传输。
选择云存储的方式最方便。
数据集/模型管理命令
使用集中式云存储的方式大概这样:
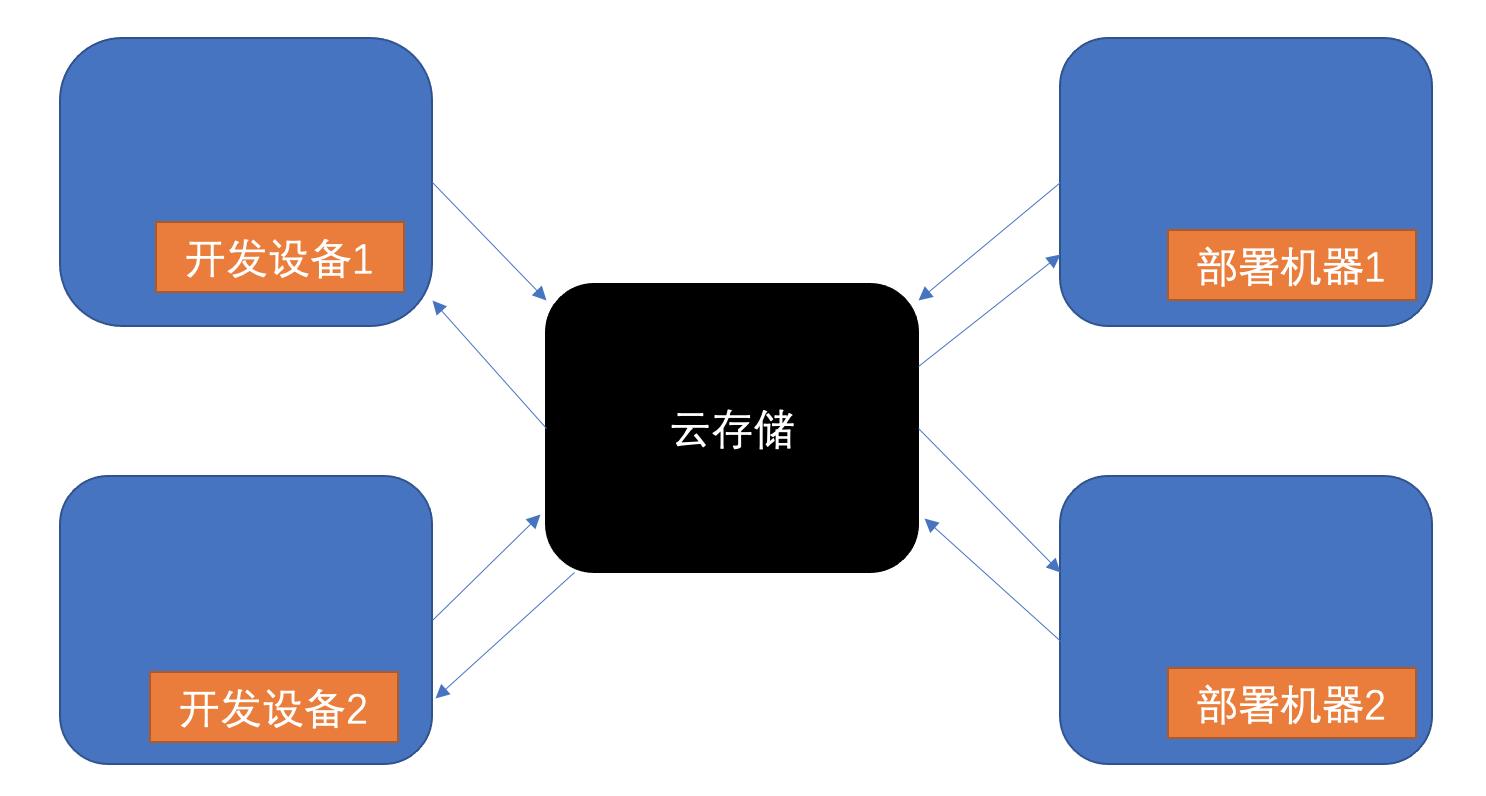
我们的命令行管道发挥了设计上的价值,通过增加两组操作行为即可支持数据集/模型的上传和下载:
## 数据集上传命令路由:dataset.upload.xxx
## xxx 分别路由到对应的上传模块
python main.py -p pro -a dataset.upload.tag
python main.py -p pro -a dataset.upload.title
## 数据集下载命令路由:dataset.download.xxx
## xxx 分别路由到对应的上传模块
python main.py -p pro -a dataset.download.tag
python main.py -p pro -a dataset.download.title
## 模型上传命令路由:model.upload.xxx
## xxx 分别路由到对应的上传模块
python main.py -p pro -a model.upload.tag
python main.py -p pro -a model.upload.title
## 模型下载命令路由:model.download.xxx
## xxx 分别路由到对应的上传模块
python main.py -p pro -a model.download.tag
python main.py -p pro -a model.download.title
其中,上传要解决:
- 自动压缩文件夹,或者文件夹下指定的文件列表
- 如果压缩文件已存在,要支持通过
--reset来做备份+重新压缩 - 上传压缩文件到云存储
其中,下载要解决:
- 从云存储下载文件到本地对应目录
- 解压,但是自动解压要考虑覆盖了本地目录的问题,有两种选择:
- 交互式询问是否覆盖,如果是就覆盖,否则不自动解压
- 不自动解压,而是输出一个解压的 unzip 命令
目前我们采用 不自动解压,而是输出一个解压的 unzip 命令的方式,这里的好处是:
- 输出的 unzip 包含必要的相对路径,这样不需要切换目录,直接在当前命令行路径下执行就可以
- 输出的 unzip 命令包含指定输出目录的 option,减少用户不小心把文件解压到上一层的常见痛点。
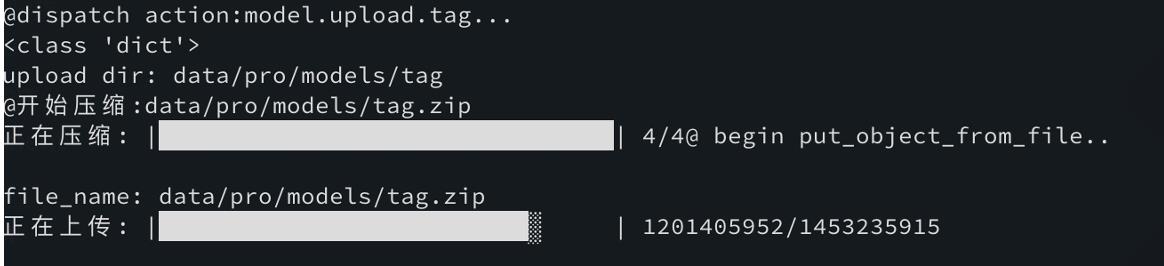
当然,我们使用了 python 的 progress 库来做进度条,非常好用,举例压缩中显示进度条,shutil.make_archive 只支持传入一个logger来回调进度信息,这里用了一个trick,临时偷梁换柱下 logger.info,用来显示progress:
from progress.bar import IncrementalBar
...
bar = None
total_files = count_files_in_dir(self.dir_path)
def progress(*args, **kwargs):
if not args[0].startswith('adding'):
return
nonlocal bar, total_files
if bar is None:
print('@开始压缩:'.format(self.zip_file_path))
bar = IncrementalBar('正在压缩:', max=total_files)
bar.next(1)
old_info = logger.info
logger.info = lambda *args, **kwargs: progress(*args, **kwargs)
shutil.make_archive(self.dir_path, 'zip',
self.dir_path, logger=logger)
logger.info = old_info
bar.finish()
一个实际的例子:
数据集/模型管理的权限和配置管理
有了方便和快速的数据集/模型管理命令,成员之间同步数据集/模型,开发机和部署机之间同步数据集/模型,就开始流畅起来。但是要考虑权限问题。
首先,云存储上使用两个目录+两个不同的账号:
- dev 目录做开发环境用,通过限制IP的方式在团队成员之间开放权限
- pro 目录做部署环境用,只有管理员+部署机器能访问
这解决了开发环境下组内流畅的数据集/模型同步问题,也解决了部署机器流畅的数据集/模型下载问题。但是还是只解决了一半问题。帐号的配置如何管理?
很简单,我们从第一节就提到了配置管理(config)。config 里应该包含帐号配置,但是 config 本身是有不同来源的。例如使用阿波罗的配置管理中心。我们增加一个命令行选项 --cluster
- –cluster dev 获取阿波罗配置中心的 dev 集群配置
- –cluster fat 获取阿波罗配置中心的 fat 集群配置
- –cluster uat 获取阿波罗配置中心的 uat 集群配置
- –cluster pro 获取阿波罗配置中心的 pro 集群配置
实际上,我们只用到了1,3,4 三个配置,分别用来做开发、预部署、部署环境的配置。同时,这里又是有权限管理的:
- 开发成员的IP 加入 --cluster dev 的白名单机制,所有的开发人员可以获取 dev 集群的配置,从而可以访问 dev 环境的云存储
- uat 和 pro 集群配置则只能在部署机上访问。
到这里,我们就解决了数据集/模型管理的几个核心问题:
- 通过命令行 精细地(Hackable) 控制目标数据集/模型的上传/下载
- 通过合理的设计上传/下载执行前后的操作,规避常见的误操作问题
- 通过云存储的帐号隔离,区分开发和部署目录
- 通过集中式配置管理中心,区分不同集群的配置,兼顾流畅性和安全性
数据集/模型的版本化
到这就万事大吉了?并不是,常见的机器学习算法,一遍也在线提供模型下载页面,类库里也会直接按需下载对应的模型文件。但是我们会更进一步做数据集/模型的版本化。
没有做版本化的时候,多人之间同步靠约定,或者通知模式:“这个数据集/模型我已经上传了最新的了,你更新下”。
而使用版本化则是一个现代解决方式:数据集/模型的上传下载应该计算对应的MD5,可以用来做版本号。同时,配置里面指定当前使用那个版本,也就是类似这样:
21ljlefla/
3rlfalmfa/
current/
其中 current/ 应该是一个软链接,链接到使用的版本目录。这样发生变动后的数据集/模型文件都有版本号,明确指定使用的版本号就不容易发生冲突。
关于数据集/模型管理的就先告一段落,我们分析了数据集/模型的各个不同角度,提供了设计并实施。数据集/模型管理就不再成为开发/部署流程中的瓶颈问题。解决开发流程中的痛点问题,我们在迭代速度方面就会获得极大的提升,而这些,并不是 “NLP” 三个字母直接告诉你的。
–end–
以上是关于NLP 实战 | 整体设计之数据集/模型管理的主要内容,如果未能解决你的问题,请参考以下文章
NLP 实战 | 我发现的飞桨(paddlepaddle)大坑