NLP 实战 | 整体设计之代码篇
Posted 幻灰龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP 实战 | 整体设计之代码篇相关的知识,希望对你有一定的参考价值。
在 上一篇 里,我们对基于 NLP 技术构建的服务做了整体性的构建。我们看到 NLP 的实战决不仅仅是单纯的算法或模型问题,立足于算法/模型,但整体性的工程构建工作也需要持续更新,同时模型和算法相关的实际开发也不仅仅是某个单一模型或者某个超大预训练模型就能解决问题,更多地,我们总是需要系统的解决方案。
团队博客: CSDN AI小组
微服务
上一篇我们讨论了项目的统一命令行设计和项目目录结构的整体设计。实际上这是两个自底向上的基建工作。本次我们直接自顶向下看下最后的构架是怎样的。
模型和算法最终都要转成一个个服务,设计上会是一个微服务到severless演进的过程。具体来说,基于算法和模型形成的子服务会被动态组合部署到不同的节点上。
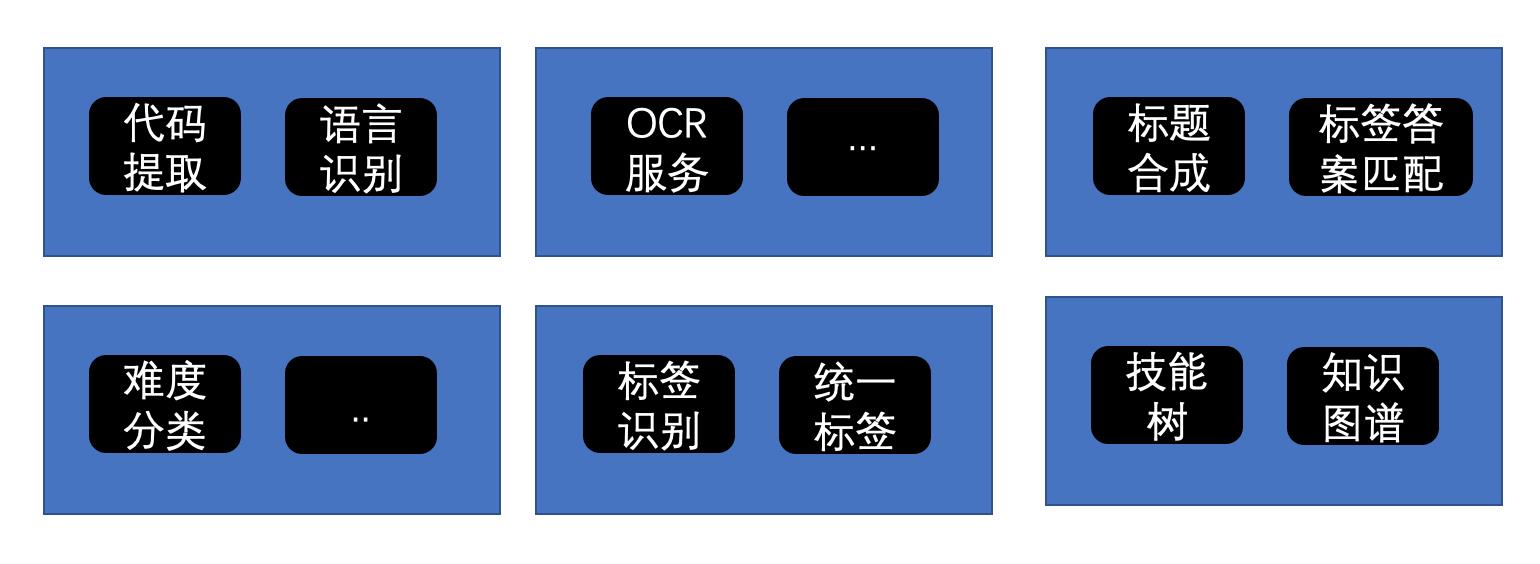
这是一个渐进式演进的过程。一开始只考虑服务的自由独立部署以及服务之间的依赖关系即可。有了主干,就可以逐渐把部署、网关、集群监控、日志服务等等基建一步步地补齐。
一开始我们只需做到项目可以把一整组服务整组启动:
python main.py -p pro -a server.ask
接着支持项目可以在不同的设备上只启动某个子服务
python main.py -p pro -a server.ask.title
python main.py -p pro -a server.ask.tag
此时,解决服务间的依赖问题,例如 A服务依赖B服务的模块,而B服务的模块是一个有成本的模块(例如需要加载模型,有耗时的计算),直接代码级别复用则服务A和B没有做到隔离。
因此,定义服务的“Runtime” 就是必要的:
- 第一篇文章里定义的所有代码运行都可见的
config+options,分别代表环境配置和命令行参数 - 每个服务都运行在一些公共组件之上
- 服务之间通过代理调用
- 我们暂时不做单个服务的多实例,如果有多实例,则需要一个集中式调度器(selector)。
解决了设计问题,实现上每个服务都要提供一个Client给其他服务调用。
一个微服务A的Client 实现需要考虑:
- 首先,A的本地实现
- 提供一个从服务A走Rest API调用接口的Proxy实现(接口与A的本地实现保持一致)
- 根据当前环境配置
config里是否包含A服务的host- 如果存在,则调用基于 Rest API 的Proxy实现
- 否则调用本地模块实现
这样,当B服务依赖A的时候,直接调用AClient即可。环境配置config会决定它实际上调用的是谁。我们只需提供不同的配置,即可测试不同的调用。
此处我们暂时不用考虑服务Client的自动生成问题,一开始全手工加即可。以后我们逐渐加上自动化代码生成是自然而然的过程。
当然,每个服务都会有统一的端口分配,因此为了方便测试,命令行参数增加一个--port选项,启动不同服务时,可以通过更改端口来测试,例如
python main.py -p pro -a test.title --port xxxx
一个程序是一棵树,永远保持对这颗树重要节点的自由测试是程序良构的重要基础。再次说明了我们在上一篇里提到的统一命令行设计的优点。
微服务的部分就先谈到这里。下面是一个服务Client的实际例子:
class OCRClient:
'''OCR客户端,如果config里配置了ocr_server,就从服务获取 '''
def __init__(self, config, options) -> None:
self.config = config
self.options = options
self.ocr_server = None
self.ocr_local = None
def load(self):
if self.config.get('ocr_server') is not None:
self.ocr_server = self.config['ocr_server']
else:
from server.ocr.img2text.paddle_ocr import PaddleImageText
self.ocr_local = PaddleImageText()
self.ocr_local.load()
def extract(self, url):
if self.ocr_server is not None:
return self.extract_from_server(url)
else:
return self.extract_from_local(url)
def extract_from_local(self, url):
assert self.ocr_local
return self.ocr_local.extract(url)
def extract_from_server(self, url):
assert self.ocr_server
headers = 'Content-Type': 'application/json'
try:
data = json.dumps('url': url)
r = requests.post(self.ocr_server, data=data, headers=headers)
ret = json.loads(r.text)
if ret['err'] != 'success':
return
'err': ErrorCode.FAILED
else:
return
'err': ErrorCode.SUCCESS,
'code_text': ret['code_text']
except Exception as e:
return 'err': ErrorCode.FAILED
命令行路由
前端有路由,后端HTTP服务有路由,命令行为什么不应该有路由?我们在上一节提到了命令行指定行为表达式的设计:
python main.py -p pro -a test.code.svm
这里的test.code.svm 在内部就会由 src/test/__init__.py 来负责路由。设计上每个一级操作目录下的__init__.py负责路由。路由器的实现就是一个AK-47的够用即可的设计:
# command_line.py
def dispatch(config, options, actions, targets):
''' 分发命令行 action '''
action_len = len(actions)
action_len = len(actions)
if action_len < 2:
return
index = 1
next = targets
while action_len >= index:
if type(next) == type():
if index == action_len:
if next.get('run') != None:
next['run']()
break
action = actions[index]
if next.get(action) != None:
next = next[action]
index += 1
else:
next()
index += 1
break
使用的时候也很简单:
# test/__init__.py
def dispatch(config, options, actions):
'''
## 测试命令分发
* 分支节点会执行节点下的 run 子节点的函数
* 叶子节点直接执行对应函数
node main.py -p pro -a test.code 会执行 dispatch_code
node main.py -p pro -a test.code.extract 会执行 dispatch_code_extract
'''
command_line.dispatch(config, options, actions,
'answer': lambda: dispatch_answer(config, options),
'tag': lambda: dispatch_tag(config, options),
'title': lambda: dispatch_title(config, options),
'skill_tree': lambda: dispatch_skill_tree(config, options),
'ocr': lambda: dispatch_ocr(config, options),
'code':
"run": lambda: dispatch_code(config, options),
"classifier": lambda: dispatch_code_classifier(config, options),
"extract": lambda: dispatch_code_extract(config, options),
"svm": lambda: dispatch_code_svm(config, options),
,
"html_parser": lambda: dispatch_html_parser(config, options),
'component':
"qdl": lambda: dispatch_qdl(config, options),
)
类库依赖的局部化
在一个仓库里集成所有的服务,不同的服务有不同的库依赖。一种典型的问题是:
- 小明开发A服务
- 小军开发B服务
此时如果小明的A服务因为依赖问题在小军的环境下不能正确执行,但是小军其实不关心A此时是否正常,只想测试B服务而已。
这个问题也通过一致的整体设计解决:
- 在上一节提到命令行路由,路由器实现不应该在全局直接 import 所有依赖,例如
test/__init__.py不能在开头就把所有子服务测试依赖的模块都加载进来。 - 而应该在路由分发函数
dispatch_xxx里局部化动态import被分发的模块
这个设计不仅仅在命令行路由分发这里使用。
例如服务的HTTP分发:
- Flask 的HTTP 接口层调用全部转发给
Service模块, - 而
Service模块内的不同接口的分发器同样局部化动态import被分发的模块
例如一个分类器的不同模型实现:
- 同样一个服务,常常有不同的模型实现,这一般通过
工厂模式(Factory)创建对象,工厂的实现可以很简单的事一个函数或者一个类,无论哪一种都可以对实际创建模块进行依赖局部化
实际的代码例子:
class QueryManager:
def __init__(self, config, options, query_type=SENTENCE_TRANSFORM_QUERY_TYPE) -> None:
self.query_type = query_type
self.config = config
self.options = options
...
def create_query(self, tag_id):
if self.query_type == BERT_QUERY_TYPE:
from .bert_serving_query import BertQuery
return BertQuery(self.config, self.options, tag_id)
elif self.query_type == SENTENCE_TRANSFORM_QUERY_TYPE:
from .sentence_transformer_query import SentenceTransformerQuery
return SentenceTransformerQuery(self.config, self.options, tag_id)
elif self.query_type == SIMHASH_QUERY_TYPE:
from .simhash_query import SimHashQuery
return SimHashQuery(self.config, self.options, tag_id)
else:
return SimHashQuery(self.config, self.options, tag_id)
模型单例化
我们做了服务的切分,让服务可以一整组启动,也可以单个启动。但是即使只是一个子服务,内部也可能存在同一个模型被多次加载的可能:
- 例如服务接口每次被调用时,创建一个子模块去处理,处理完了不持有,这可以让python干净地垃圾回收一整个子模块的内存占用。但是如果模块内有模型加载,就会导致重复加载的情况。
- 例如服务A调用了服务BClient,但是BClient内部调用的是A的本地实例,可能导致模型重复加载。
在设计上,让模型总是使用单例模式加载是解决这个问题的好办法,单例的设计比较简单(Keep it simple, stupid):
class ModalManager:
def __init__(self) -> None:
self.modelInfos =
def register(self, key, model_creator):
'''注册一个模型,提供模型的创建函数'''
if self.modelInfos.get(key) is not None:
return
'err': ErrorCode.ALREAY_EXIST
else:
obj = model_creator()
print(obj)
self.modelInfos[key] =
'load': False,
'obj': obj
return
'err': ErrorCode.SUCCESS
def load(self, key):
'''加载模型,只会加载一次'''
if self.modelInfos.get(key) is not None:
modelInfo = self.modelInfos[key]
if not modelInfo['load']:
modelInfo['obj'].load()
return modelInfo['obj']
else:
raise Exception(
"model: is not register into g_model_manager".format(key)
)
g_model_manager = ModalManager()
上面这个模型管理器,解决的两个问题:
- 通过
register让模型类的创建只会创建一次 - 通过
load让模型的加载只会发生一次
一个实际的例子是:
class SGDText2PL:
def __init__(self) -> None:
# 使用 g_model_manager 做单例
self.model_key = 'code_2pl_svm'
g_model_manager.register(self.model_key, lambda: SGDText2PLImpl())
def load(self):
try:
self.model = g_model_manager.load(self.model_key)
return
'err': ErrorCode.SUCCESS
except Exception as e:
logger.error('load SGDText2PL model failed:', str(e))
logger.error(traceback.format_exc())
return
'err': ErrorCode.NOT_FOUND
def classify(self, code_text):
return self.model.classify(code_text)
再看一个例子,可以看到还是挺灵活的:
## 先定义一个模型包装类
class SentenceTransformerModel:
def __init__(self, pretrained_model):
self.pretrained_model = get_pretrained_model_distiluse_path()
self.transformer = None
def load(self):
if self.transformer:
return
self.transformer = SentenceTransformer(self.pretrained_model)
def get(self):
return self.transformer
## 在别的地方使用:
self.model_key = 'answer_sentence_transform'
g_model_manager.register(
self.model_key,
lambda: SentenceTransformerModel(pretrained_model)
)
client = g_model_manager.load(self.model_key).get()
路径管理
任何一个项目都可能会有很多不同的本地路径依赖。AI 相关的项目更是如此,上一篇我们提到了src/data目录用来存放本地的不同类型的数据,并且是有层次结构:
- datasets: 数据集子目录
- questions: 问题子目录
- tags: 标签子目录
- models: 模型子目录
- test: 测试子目录
首先一个常见的问题是,要正确的配置.gitignore 使得data目录下只提交应该提交的文件。例如做算法的过程中很容易在data的各个子目录下创建不同的临时文件,压缩包等等,一不小心你就提交了不该提交的文件。
一个疑问是:“data 目录非要放仓库下么?” 这个是未必的,另外一种常见的设计是:
- 统一在系统的根目录下提供一个
/xxx/目录,xxx通常是项目的代号。 - 在
/xxx/目录下分配各种预先定义的目录层次结构,例如:/xxx/datasets/xxx/models/xxx/tags
这种设计的好处是,源代码目录下不需要管理数据目录,数据目录通过一个编写好的setup 或者 install 命令去初始化即可。
这是一个好的设计,因此以后会考虑切换到这个方式,目前是放在src/data下,这有其好处:
- 通过合理配置
.gitignore可以解决只提交应该提交的文件 - 如果不是大文件,小的配置或者公共数据的直接git版本化管理也会便利很多。
其次,我们谈下如何正确配置.gitigonre,一种常见的错误是只用排除某种文件的方式配置:
src/data/*.zip
这样配置data下创建随意的其他文件都可能被误提交。正确的做法是:
- 先把data整个排除
- 再把需要的子目录用
.gitignore的exclude例外模式加回来。
一个例子:
src/data/*
!src/data/dev
!src/data/fat
!src/data/pre
!src/data/pro
!src/data/readme.md
同样的, src/data/*/ 子目录下可以反复应用这个规则:
src/data/*/datasets/*
!src/data/*/datasets/book
!src/data/*/datasets/keywords
!src/data/*/datasets/questions
!src/data/*/datasets/stopwords
!src/data/*/datasets/tags
!src/data/*/datasets/codes
最后,项目提供了一个统一的common.path模块管理这些路径,包含初始化和函数,杜绝路径的硬编码。
def init_path(env):
global data_env
data_env = env
depend_dirs = [
'config',
# test dir
'data//test'.format(data_env),
'data//test/tag'.format(data_env),
...
]
for depend_dir in depend_dirs:
os.makedirs(depend_dir, exist_ok=True)
def get_data_root():
return 'data/'.format(data_env)
def get_datasets_root():
return 'data//datasets'.format(data_env)
def get_models_root():
return 'data//models'.format(data_env)
def get_test_root():
return 'data//test'.format(data_env)
...
本篇到此结束
–end–
以上是关于NLP 实战 | 整体设计之代码篇的主要内容,如果未能解决你的问题,请参考以下文章