从Transformer到BEVFormer(注意力机制在CV中的使用)
Posted liu liu liu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从Transformer到BEVFormer(注意力机制在CV中的使用)相关的知识,希望对你有一定的参考价值。
Transformer
RNN:Recurrent Neural Network
在讲Transformer之前,先看看RNN(循环神经网络)的不足之处。下图是RNN结构示例:
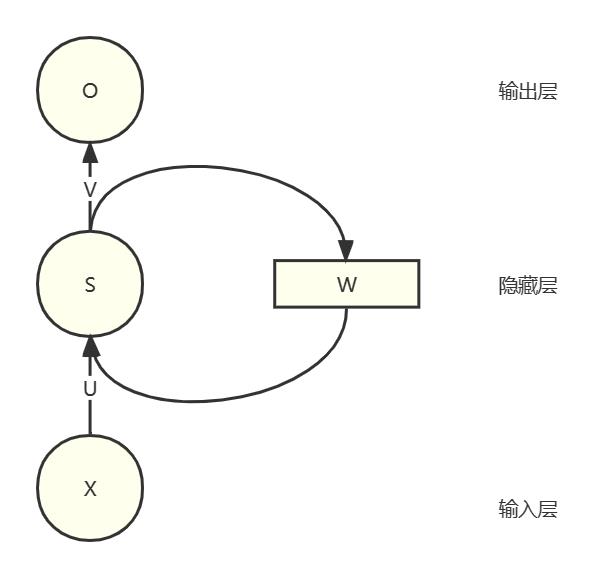
X表示输入的向量,经过输入层到隐藏层的权重矩阵U后和隐藏层的权重矩阵W后,得到隐藏层的特征向量s,s经过隐藏层到输出层的权重矩阵V后得到最后的输出向量o。所谓的循环神经网络的关键在于权重矩阵W,它包含了上一时刻的输入x,当前时刻隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一时刻隐藏层的值s。
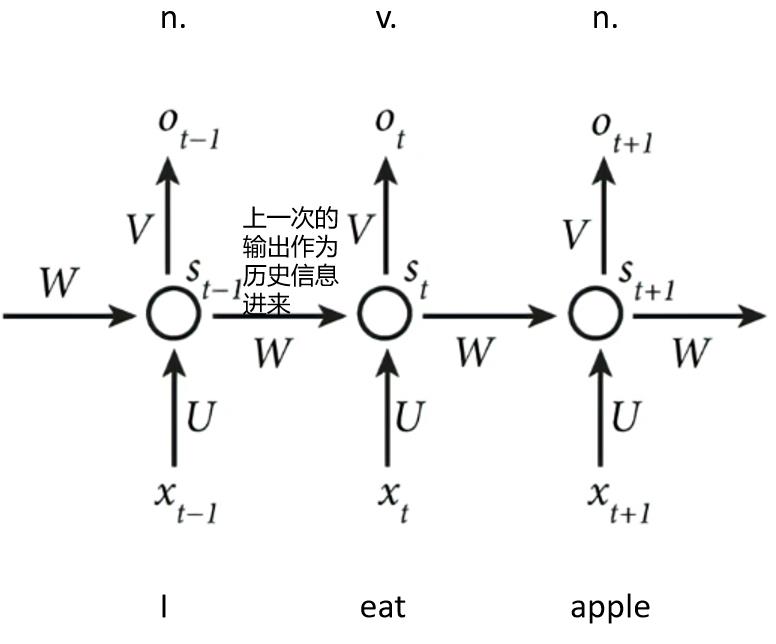
以识别词性为例,在识别eat的词性时,上一时刻的输入I在隐藏层的向量同时输入进来,使网络推断词性有了结合上文的能力。
这种机制主要有两个缺点:
时序神经网络按时序进行计算,使得任务在训练时无法并行。
早期的St很有可能丢掉,若不丢掉,内存开销大。
Transformer过程详解:
Transformer在做什么?以机器翻译为例:英文翻译为中文。

具体来说,Transformer中的编码器解码器架构如下图所示:
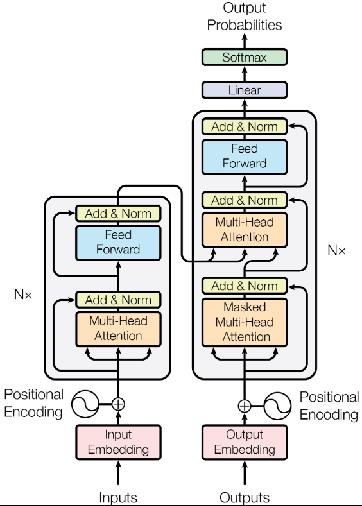
左侧为N个Encoder,右侧为N个Decoder。
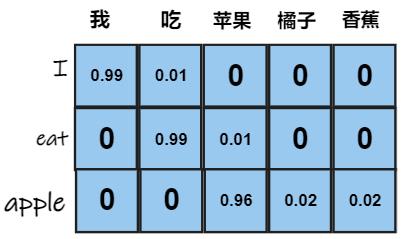
训练时,左侧Encoder端输入的是I eat apple,右侧Decoder端输入的是翻译结果 我 吃 苹果。每一个单词都被编码为一个C维的向量,所以左侧和右侧的输入都是一个3*C的矩阵。最后的输出是经过softmax变换后的三个向量,向量的维度表示分类的数量,即[序列长度,类别数量]。最后通过多分类交叉熵损失计算损失更新参数即可。以五个分类为例,输出如下图所示:
预测时,Encoder的输入即为要翻译的句子:I eat apple。Decoder的输入即为模型上一时刻的输出。何为模型上一时刻的输出?如下图所示:
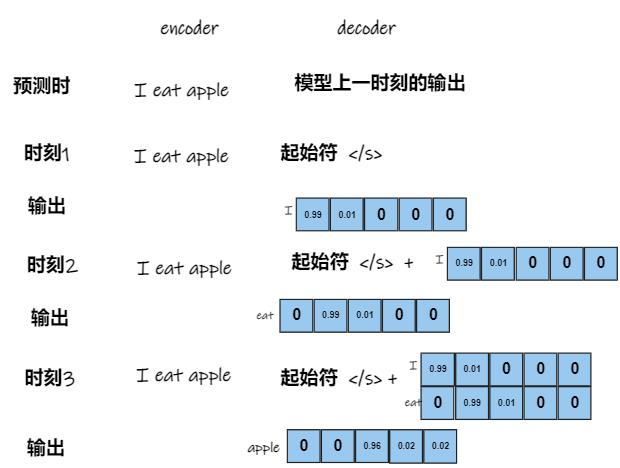
输入输出明确了,下面讲注意力机制的实现细节,还是以I eat apple 翻译为例。
左侧编码器
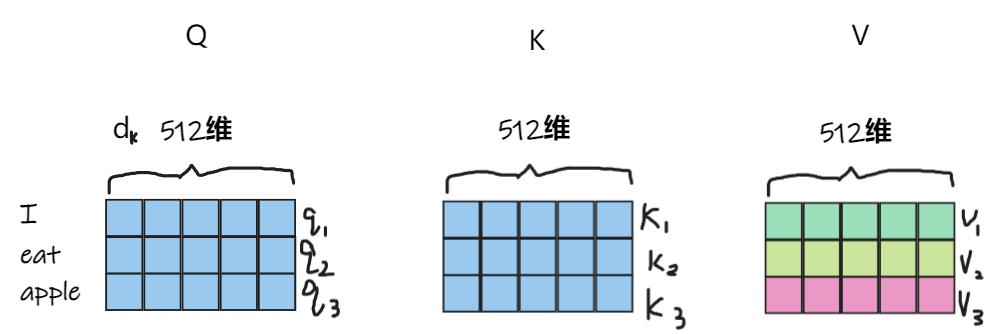
编码器输入:I eat apple编码成三个词向量,每一个的维度dk=512维。然后将各个词在句子中的位置进行位置编码,每一个词的位置编码也是一个512维的向量。然后和最开始的词向量对应的维度相加,合成三个512维包含了位置编码的词向量。即3*512的矩阵。下一步,将该矩阵复制三份,分别作为Encoder中的自注意力机制中的Q,K,V,如下图所示。
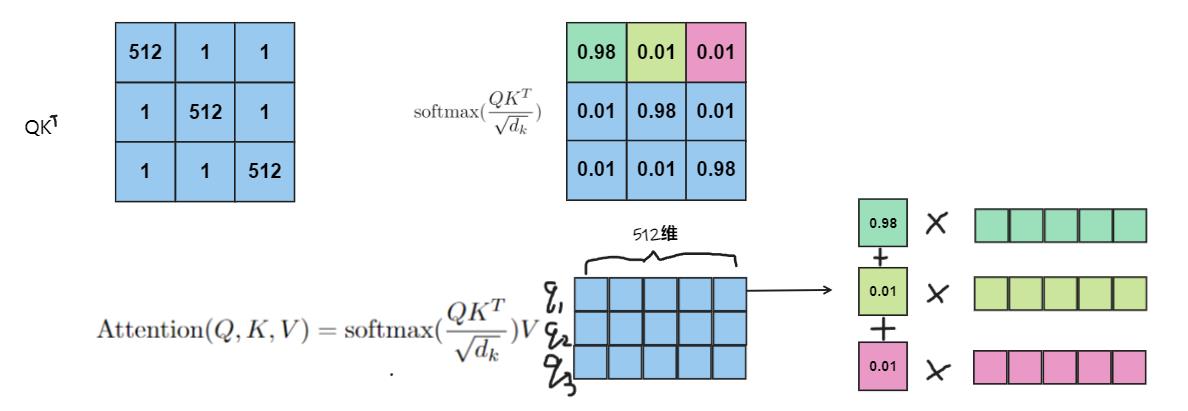
通过q1,q2,q3分别和k1,k2,k3计算相似度(经过softmax后的向量点积),以相似度作为权值,从V矩阵中拿取每一个query所关注的特征向量(根据相似度从v1,v2,v3中按比例拿取)。该过程如下图所示,这里以q1获取特征为例:
这里解释一下为什么在softmax里面要除 :
:
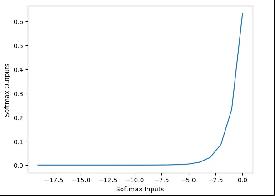
除以根号dk是为了消除维度带来的数据影响,比如dk分别为16和1024,那么两次带来的值差异很大,处理dk就是为了消除这种差异。如下图所示,如果softmax输入的值很大,那么它的输出就会无限接近于1,其他值就会无限接近0,这就导致通过交叉熵计算损失时,接近收敛,无法更新模型中的参数,所以除以根号dk是为了消除维度带来的数据影响。
何为多头注意力机制?
为了让一个query学习一些不同方面的信息,有一些不一样的计算特征的方法,将query,key投影(投影矩阵W是可学习的)到低维,投影h次,做h次的注意力函数,然后把每次的输出拼接在一起,再投影回高维,得到最终的输出。多头注意力机制的公式如下:

为了更加形象的理解多头注意力机制的工作过程,还是以I eat apple翻译为例,通过8个注意力头,展示多头注意力的过程。
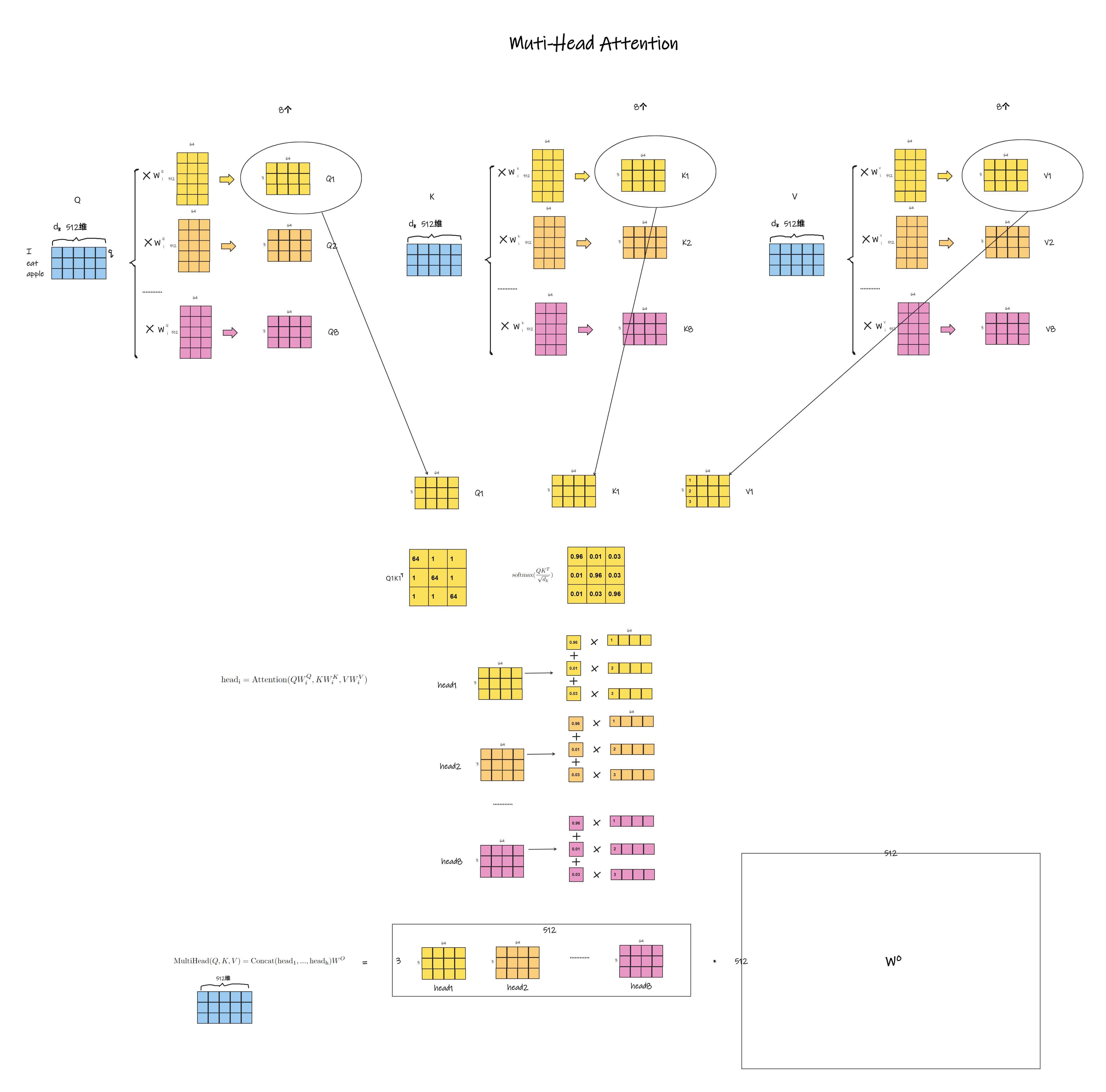
通过多头注意力机制获得提取后的3*512的特征,进行归一化处理(避免在后面激活时数据落在激活函数的饱和区),输入FFN(全连接层+ReLU+全连接层)如下公式,得到Decoder所需要的K矩阵和V矩阵(两个一样的3*512的矩阵)。
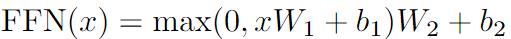
右侧解码器
以训练时为例,右侧解码器的输入为翻译的结果:我 吃 苹果 三个512维的词向量,并且和各个词向量的位置编码进行相加。通过Masked多头自注意力机制,得到三个512维的向量作为query,去左侧编码器生成的K和V矩阵中通过注意力机制进行查询。在作者设计的网络中,编码器和解码器的过程重复六次,目的应该是更好的提取特征。最后的结果经过全连接层和softmax得到每个词对应每个意思的概率,通过交叉熵损失函数来更新网络中的参数。
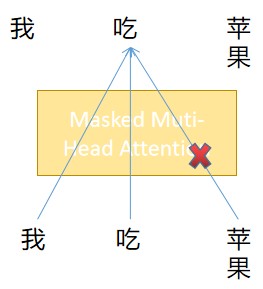
何为Masked多头注意力机制?
因为在训练时要模拟真实的预测流程,还是以I eat apple翻译为例,右侧的输入直接就是 我 吃 苹果 三个已经翻译好的词向量,在翻译eat->吃 的过程中,要保证第三个翻译好的词“苹果”不影响“吃”的翻译过程。即将之后时刻的输入Mask掉,从而保证训练和预测时候的行为是一致的。
以上就是Transformer的过程,它在训练时的词向量可以并行输入,大大提高了训练速度。
DETR:Object Detection with Transformers
DETR的总流程
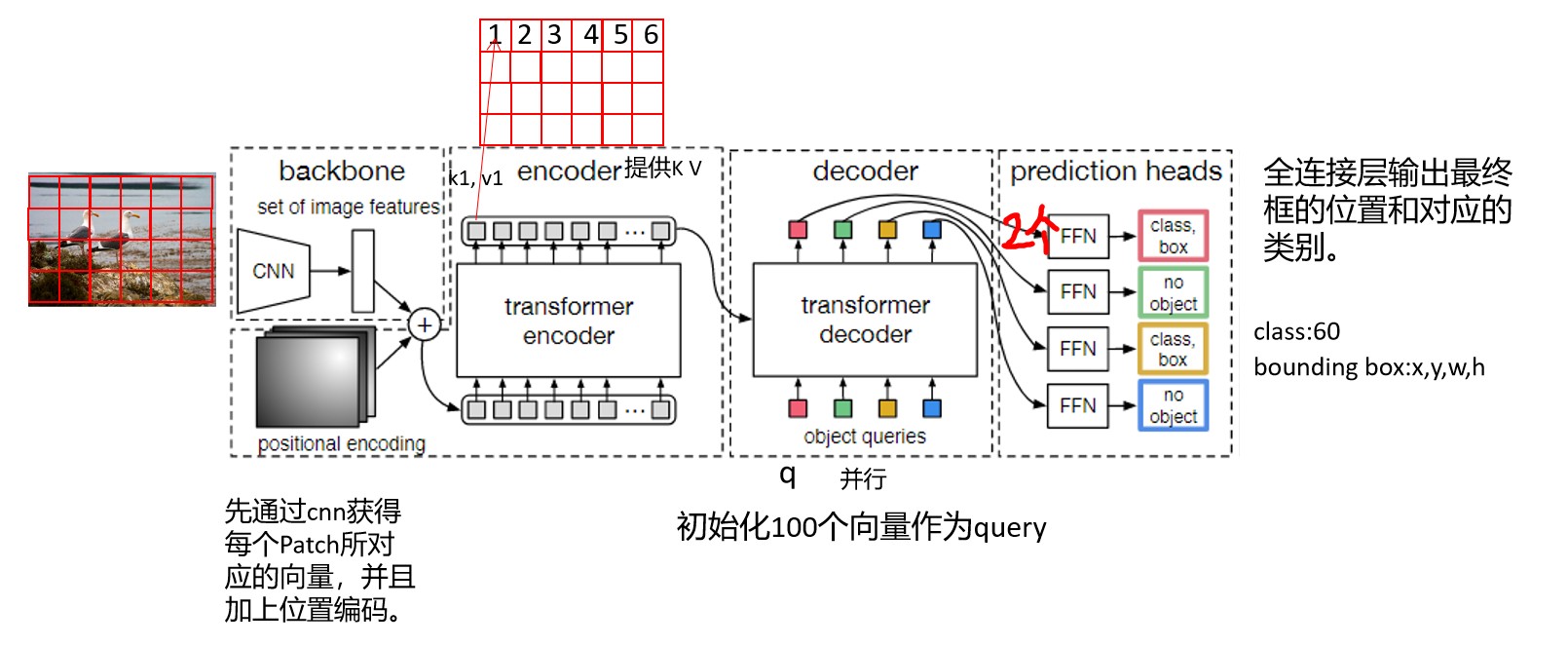
上图为DETR的总流程:先将图片分成若干个Patch,通过CNN编码成一个个向量并且和各个Patch所在的位置编码进行结合(对应项相加)。然后通过自注意力机制获得的各个Patch向量作为K,V,供后面的query进行查询。初始化若干个query (以100个为例),初始化方法:全0+位置编码。有了query,就可以向encoder提供的K,V进行查询特征。最后经过两个全连接层,输出最终框的位置和对应的类别(60分类就是60维的向量)。下图是query从K,V中查询的示例。

中间图中红色点代表query所在的位置,两侧图中的黄色部分代表不同位置的query所要重点关注的地方。从图中可以看出通过注意力机制的Encoder可以将不同实体区分开来。
DETR的网络架构如下图所示:
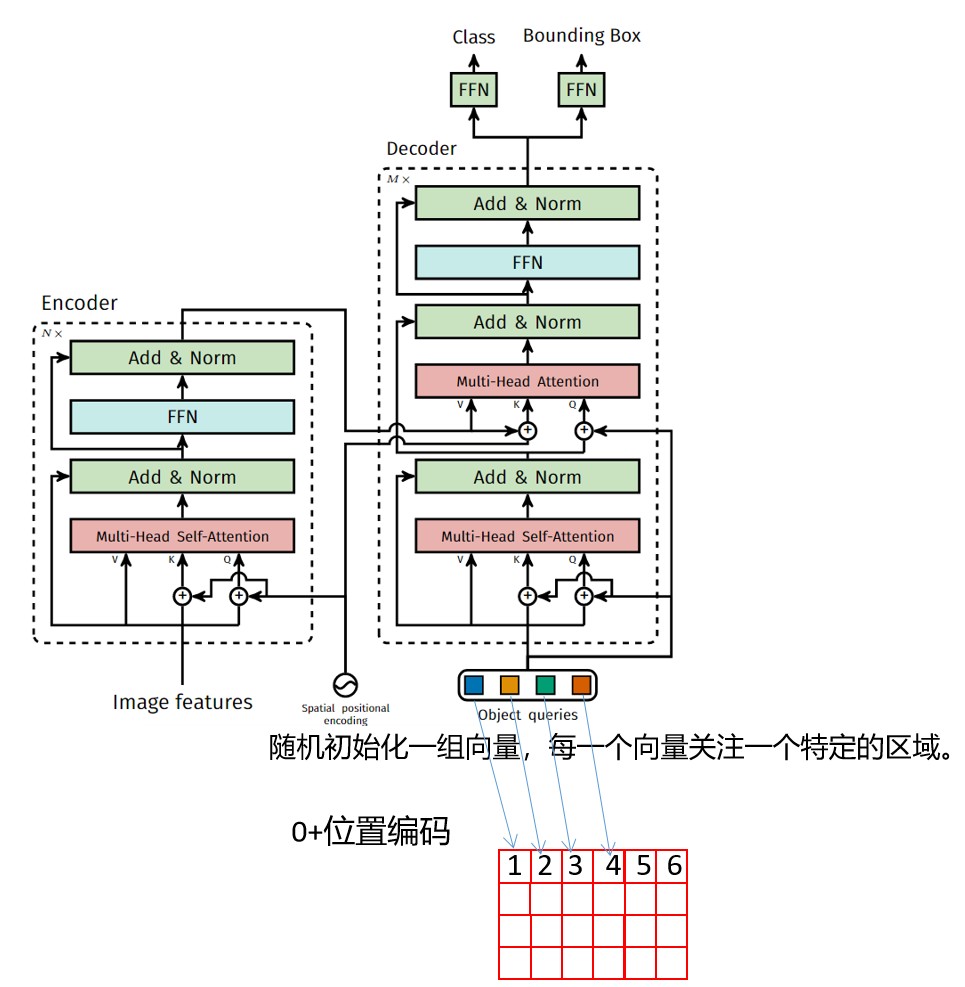
DETR存在的问题
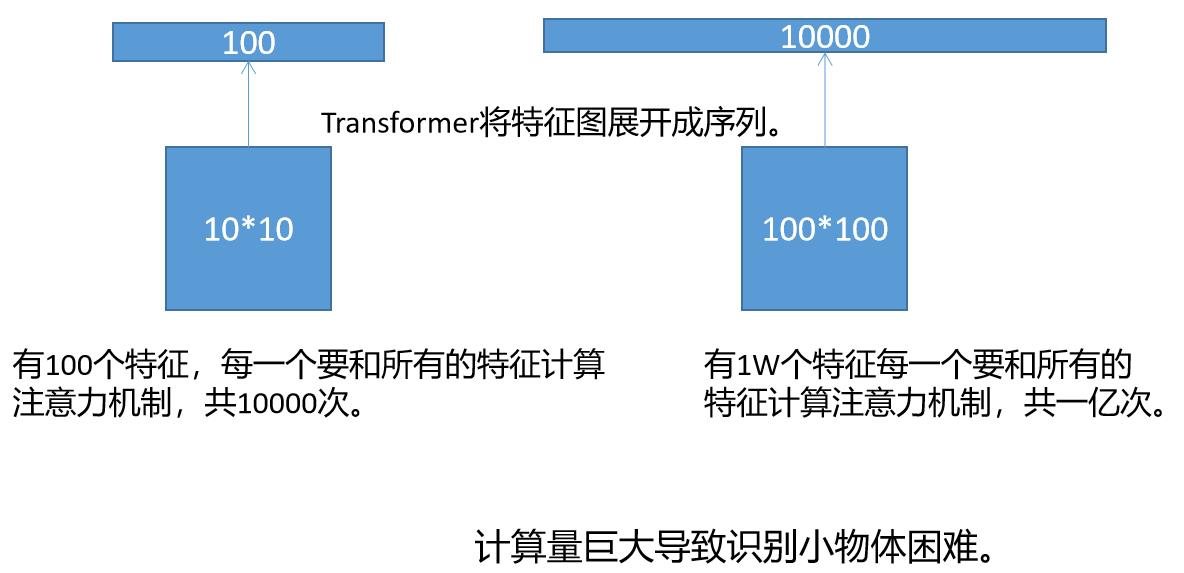
如果用10*10的特征图表示一张图片,即一张图片划分成100个Patch,那么就有100个特征向量,每一个特征向量要和所有的特征向量计算注意力机制,所以计算一次注意力机制要100*100=10000次。
如果用100*100的特征图表示一张图片,即一张图片划分成10000个Patch,那么就有10000个特征向量,每一个特征向量要和所有的特征向量计算注意力机制,所以计算一次注意力机制要10000*100000=1亿次。由此可见,每一个Patch的边长缩小10倍,计算量要增加一万倍。因为识别小物体有恰恰需要划分更小的Patch,因此DETR的小物体识别能力有限。
Deformable DETR
Deformable DETR 解决了传统DETR识别小物体困难的问题。如下图所示,query:zq不再是和K矩阵中所有的key计算相似度,而是找几个该query最有可能关注的key(这里以3为例),来提取这几个key所对应value的特征。

Deformable DETR的流程:
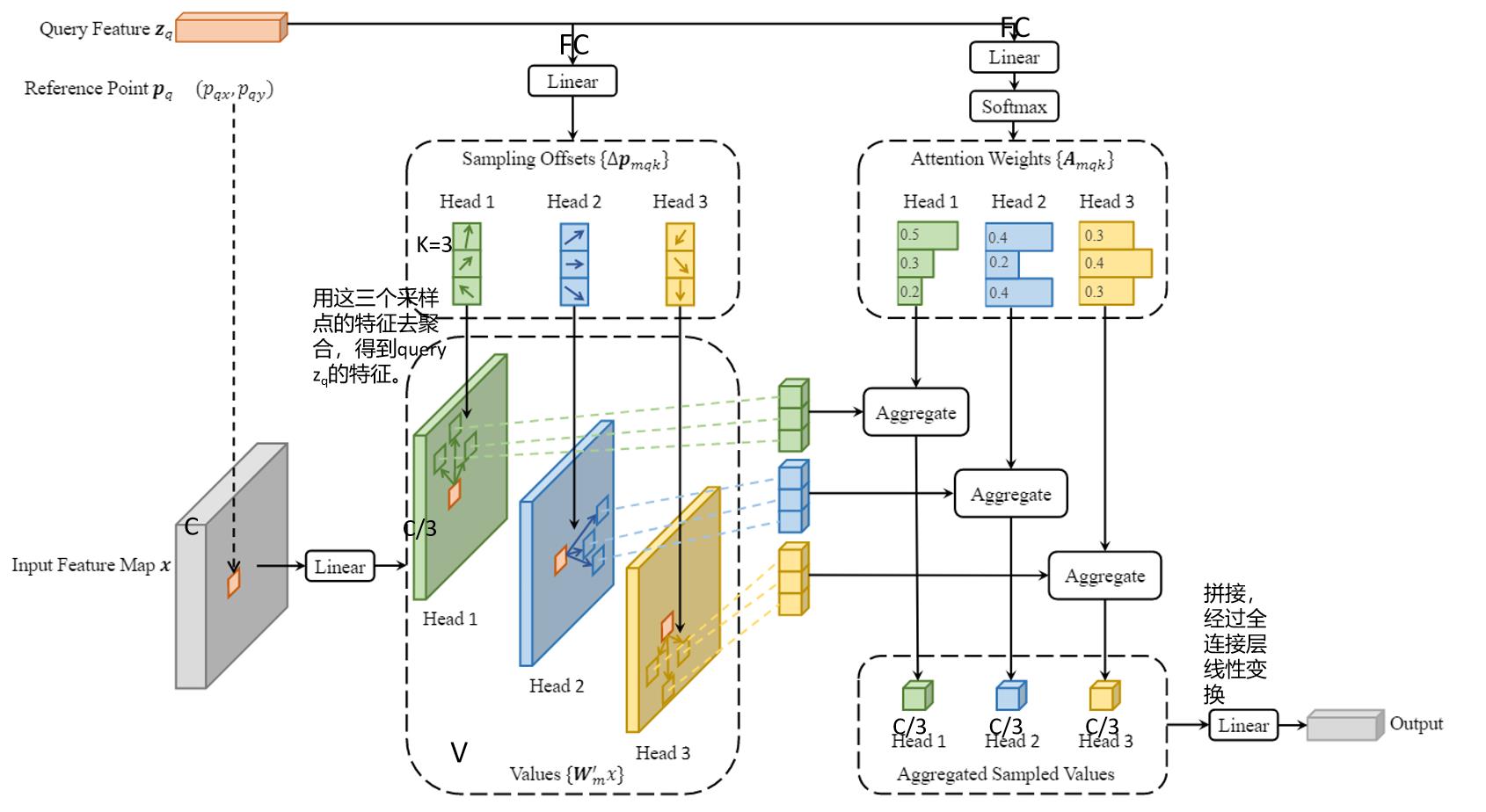
首先,query:zq(维度为C)对应到输入的特征图上就是灰色特征图上的黄色方块的位置,该特征图通过多头注意力机制投影成3个维度为C/3,供query进行查询。最上面的query:zq经过第一个全连接层获得了三个输出,Head1、Head2、Head3,在每一个Head中都有三个二维向量,表示该query应该关注点的相对位置(相对这个query的偏移量)。query通过另一个全连接层和softmax预测出这3个关注点所对应的权重,根据权重和对应点的位置从对应head的特征图中进行特征提取,最后三个head提取的特征进行拼接。这里一个query找三个参考点只是作者举例,实际应用中应该找更多一些的点。
BEVFormer :Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
BEVFormer所做的事情就是根据汽车行驶时的环视图像,构造一个鸟瞰图的特征空间,叫做BEV特征空间,该特征空间可以连接不同的分类头进行目标检测等任务。
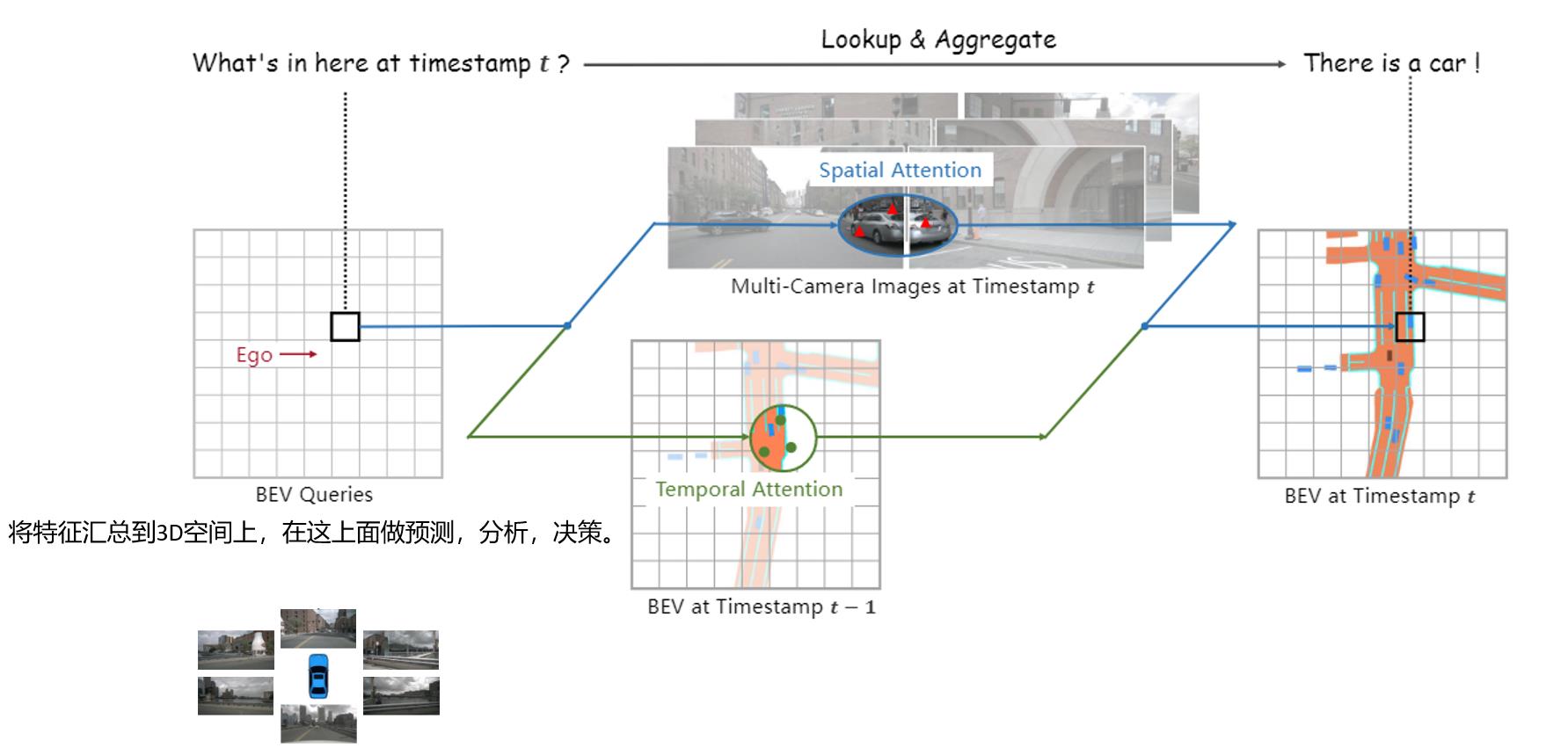
BEV特征空间的特征提取结合了空间注意力机制和时间注意力机制。时间注意力机制是从上一时刻的BEV特征空间中提取特征,这样可以或得这一时刻被遮挡,上一时刻未被遮挡的空间中的物体信息。空间注意力机制即为从当前时刻的六张图片中提取特征。
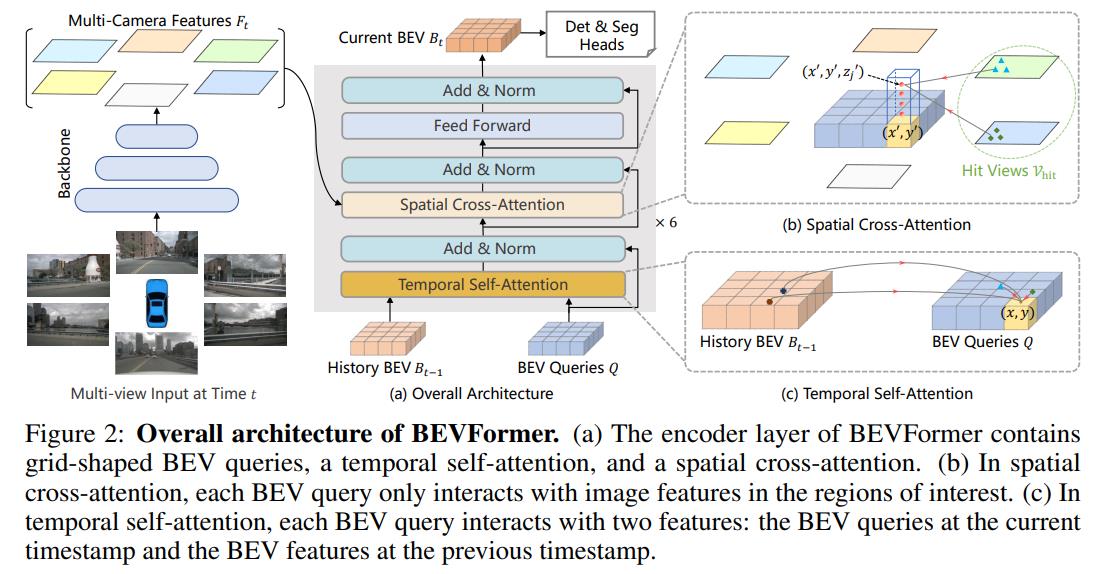
时间注意力机制
时间注意力机制即从历史BEV特征中提取有用信息。通过引入历史信息,可以检测被遮挡物体。
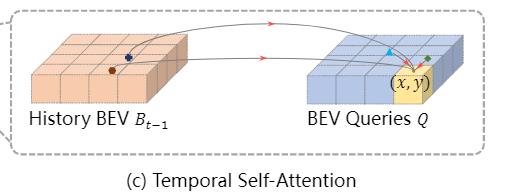
首先利用自身运动将Bt-1与当前时刻t的Q对齐,使同一网格的特征对应真实世界的相同位置得到B‘t-1。通过Deformable Attn从上一时刻特征图中提取特征。

空间注意力机制
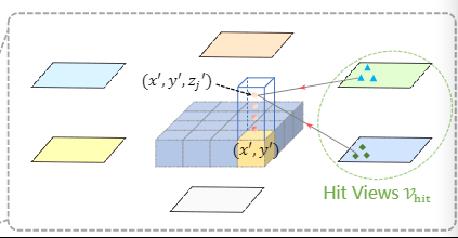
Vhit:特征空间中右边的特征只有右边的两个视图能体现,称这两个视图为Vhit。

参考文献
Transformer:1706.03762.pdf (arxiv.org)
DETR:2005.12872.pdf (arxiv.org)
Deformable DETR:https://arxiv.org/pdf/2010.04159.pdf
BEVFormer:https://arxiv.org/pdf/2203.17270.pdf
以上是关于从Transformer到BEVFormer(注意力机制在CV中的使用)的主要内容,如果未能解决你的问题,请参考以下文章
BEVFormer-accelerate:基于 EasyCV 加速 BEVFormer
从Transformer到ViT:多模态编码器算法原理解析与实现
从Transformer到ViT:多模态编码器算法原理解析与实现