从Transformer到ViT:多模态编码器算法原理解析与实现
Posted 易烊千玺铁粉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从Transformer到ViT:多模态编码器算法原理解析与实现相关的知识,希望对你有一定的参考价值。
从Transformer到ViT:多模态编码器算法原理解析与实现
Transformer架构是一种使用自注意力机制的神经网络,最初是由谷歌提出的,被广泛应用于自然语言处理和图像处理任务中。它是一种基于注意力机制的深度学习模型,适用于序列到序列的学习任务,例如机器翻译、语音识别、文本摘要等。
多模态Transformer前部分encoder算法是近年来在计算机视觉领域备受瞩目的研究方向之一。它的出现极大地推动了多模态信息的融合与处理,被广泛应用于图像、文本等多种数据类型的处理。
其中,Vision Transformer(ViT)是一种以Transformer为基础的视觉编码器,已经在各种视觉任务中取得了极佳的效果。本篇博客将介绍多模态Transformer前部分encoder算法的原理,重点讲解其在ViT中的实现,同时附带完整的ViT代码实现。如果您对多模态Transformer前部分encoder算法感兴趣,或是对ViT的实现方式想要深入了解,本文或许能为您提供帮助。
下面是vit模型核心架构图,下文是对模型架构各部分做了详细的介绍。
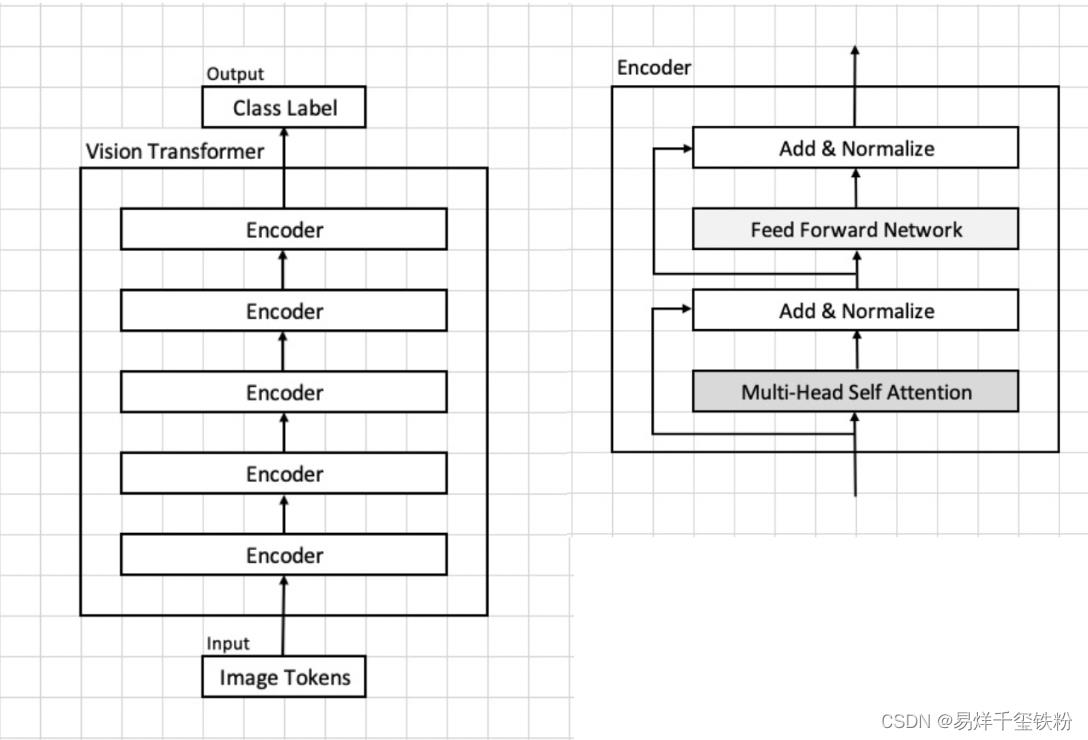
模型架构与算法原理
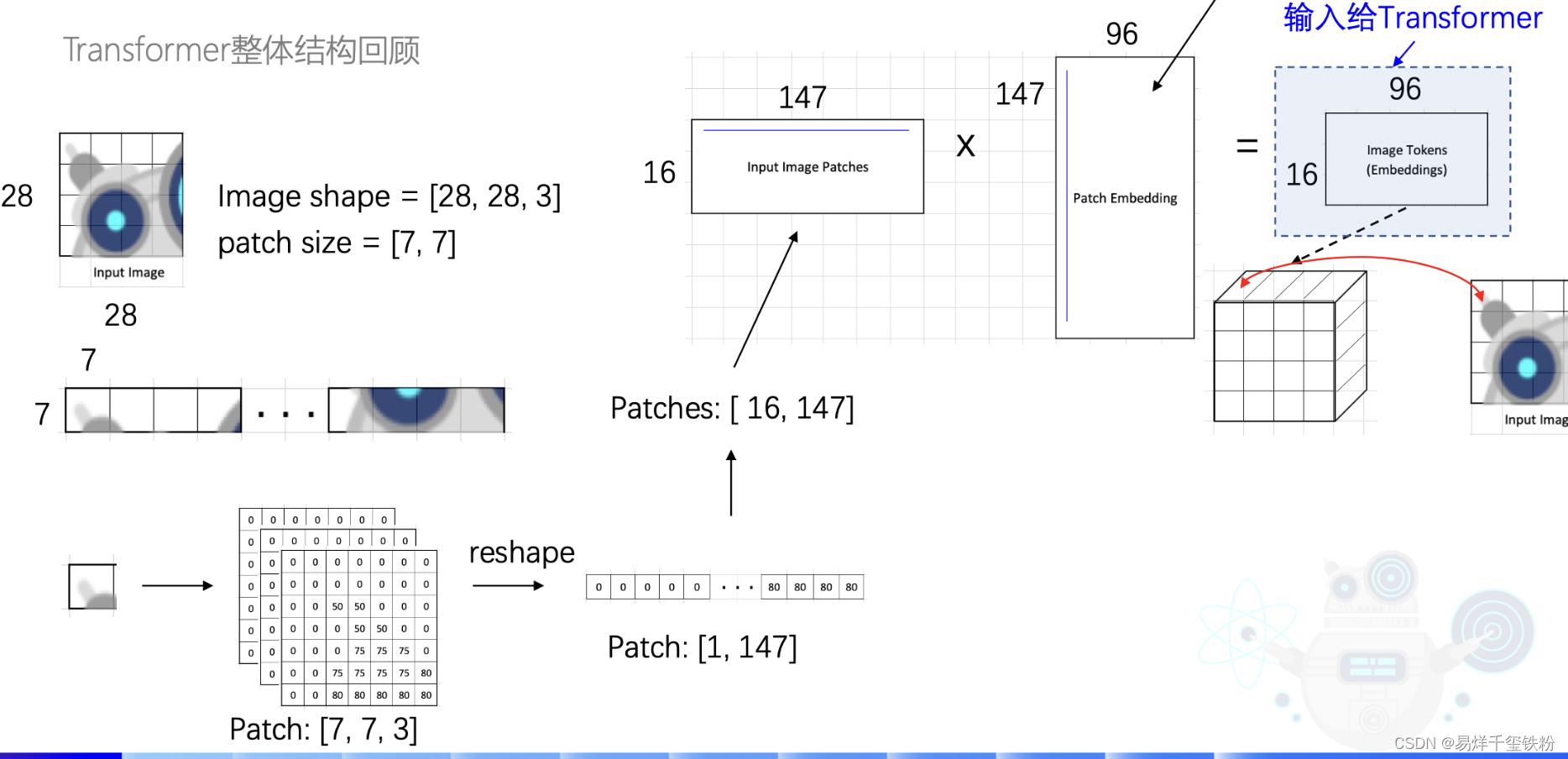
Image Token Embedding
模型输入一个将一张28x28x3的图片,模型先将图片切成一个16块,每一块为7x7。还是3通道的。
再将7x7,3通道的数据,并成一行,[1,7x7x3]=[1,147],
有16块那就是[16,147]。
接着将图片转为特征向量Embedding:
I
m
a
g
e
16
∗
147
Image_16*147
Image16∗147*
W
147
∗
96
W_147*96
W147∗96=
E
m
b
e
d
d
i
n
g
Embedding
Embedding
其中
W
147
∗
96
W_147*96
W147∗96就是要训练的参数,也就是下图中的Patch Embedding,
Multi-head Self-attention流程
依据模型输入的图片转换为的Image token Embedding,我们假设这个图像块集合为
[
x
1
,
x
2
,
.
.
.
,
x
16
]
[x_1, x_2, ..., x_16]
[x1,x2,...,x16],每个图像块的维度为
96
×
16
96 \\times 16
96×16,接着将这个embedding输入到transformer中。
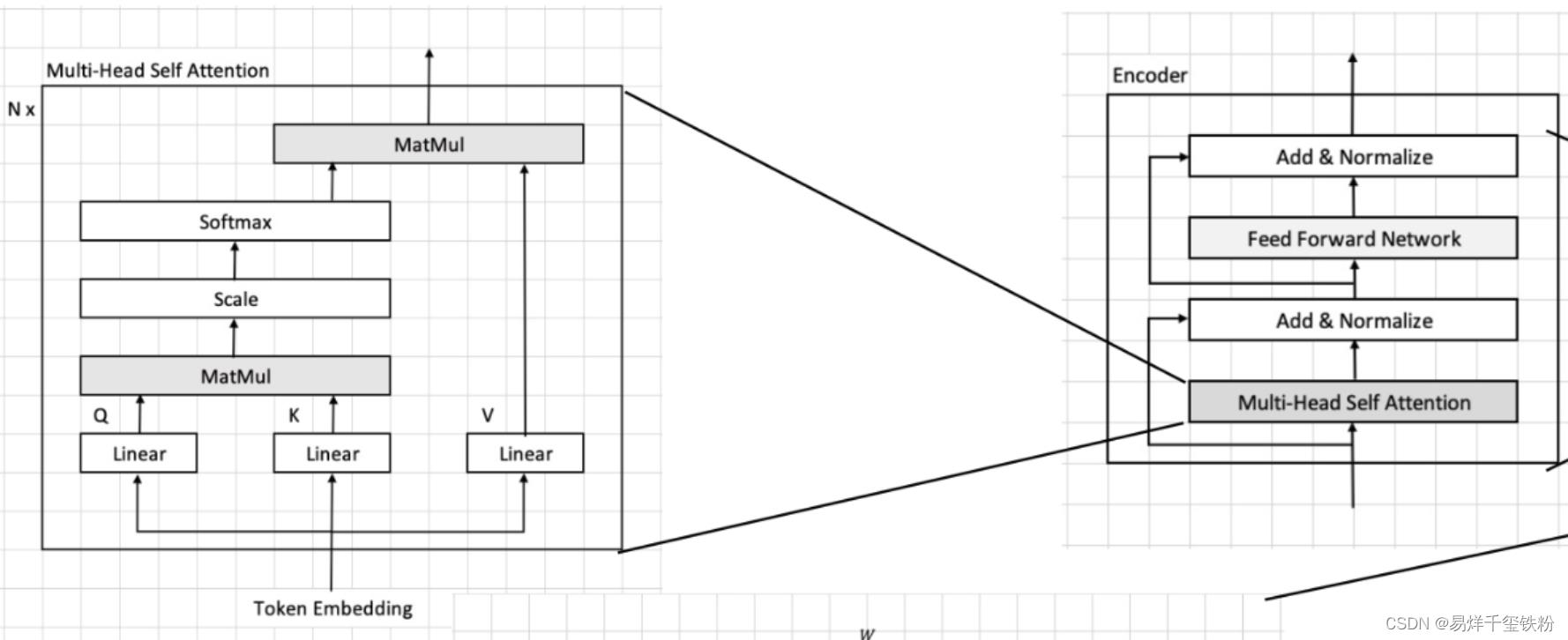
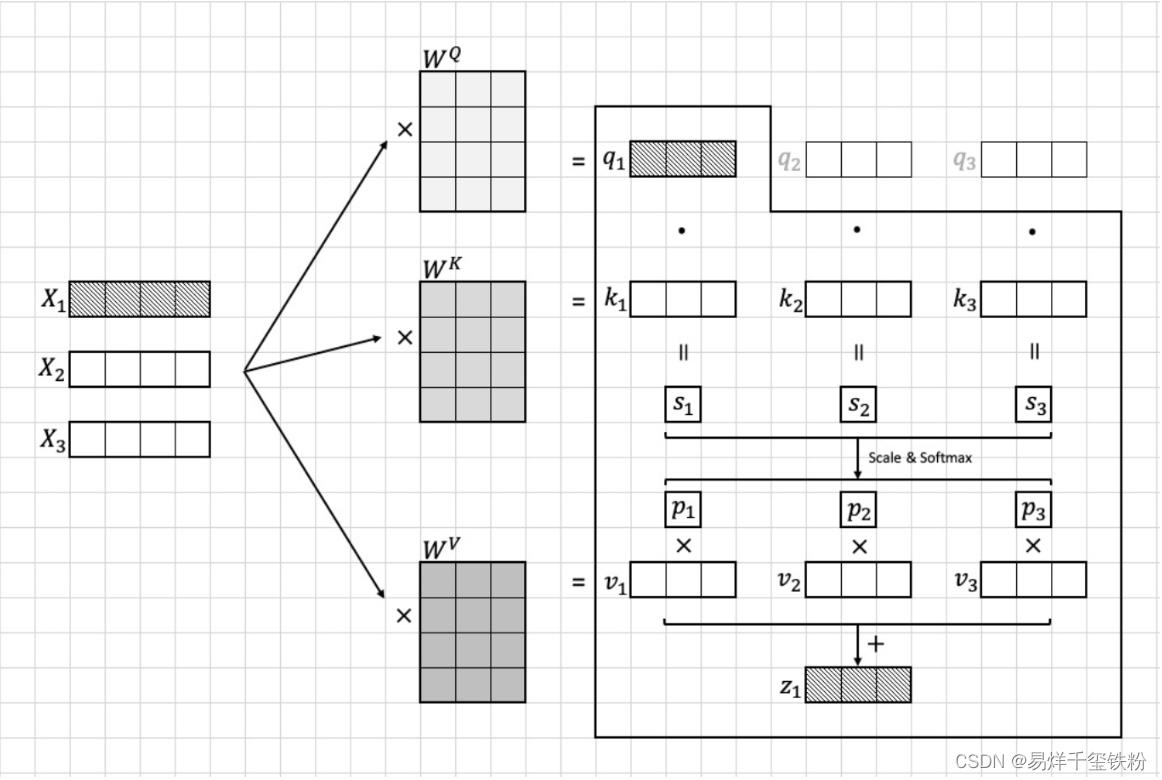
在transformer首先进入到Multi-head Self-attention进行以下四个步骤:线性变换、多头机制、scale和softmax、多头机制。下面我们将逐步说明这些步骤的算法流程。
线性变换
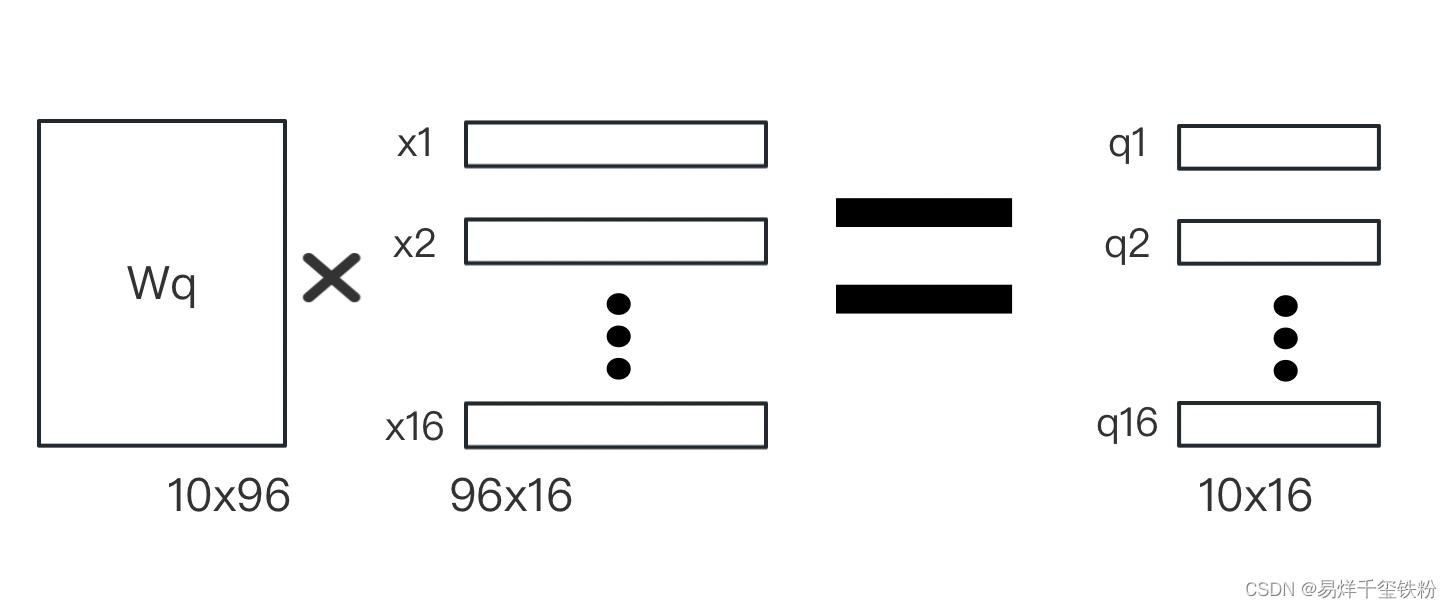
我们首先将每个图像块 x i x_i xi映射到一个10维的向量 z i z_i zi。
这个映射是通过对 x i x_i xi做一个线性变换得到的,具体而言,我们将 x i x_i xi乘以一个 96 × 10 96 \\times 10 96×10的权重矩阵 W q W_q Wq得到一个10维的向量 z i z_i zi:
 z
i
=
W
q
a
i
z_i = W_q a_i
zi=Wqai
z
i
=
W
q
a
i
z_i = W_q a_i
zi=Wqai
其中 z i z_i zi向量包含有 q i , k i , v i q_i,k_i,v_i qi,ki,vi,模型训练需要算出参数有三个变换矩阵 W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv
MatMul
我们计算每个图像块 x i x_i xi与其他所有图像块的注意力分数。具体而言,我们计算每对图像块 ( x i , x j ) (x_i, x_j) (xi,xj)的注意力分数 a i , j a_i,j ai,j,并将其用于加权求和所有图像块的向量表示。
为了计算注意力分数,我们需要先计算每对图像块之间的“相似度”
这个相似度是通过将
q
i
q_i
qi与
k
j
k_j
kj做点积得到的。
其中,
q
i
q_i
qi和
k
j
k_j
kj分别是图像块
i
i
i和图像块
j
j
j通过线性变换得到的向量。这个点积的结果可以看作是两个向量的余弦相似度,用于衡量它们之间的相似程度,
i
∈
[
1
,
16
]
,
j
∈
[
1
,
16
]
i \\in[1,16],j\\in [1,16]
i∈[1,16],j∈[1,16]
s j = q i ⋅ k j s_j = q_i \\cdot k_j sj=qi⋅kj
Scale和softmax
然而,直接计算点积可能会因为向量维度较大而导致计算上的不稳定性,因此我们在计算前先将 q i q_i qi和 k j k_j kj除以一个缩放因子 10 \\sqrt10 10,就是特征的维度10,从而保证点积的值较小,不容易出现计算上的不稳定性,然后在进行softmax函数计算。
具体公式如下:
p j = s o f t m a x ( ∑ i ∑ j q i ⋅ k j 10 ) = q i ⋅ k j 10 ∑ i ∑ j q i ⋅ k j 10 p_j =softmax(\\sum_i\\sum_j\\fracq_i \\cdot k_j\\sqrt10)=\\frac \\fracq_i \\cdot k_j\\sqrt10\\sum_i\\sum_j \\fracq_i \\cdot k_j\\sqrt10 pj=softmax(i∑j∑10qi⋅kj)=∑i∑j10qi⋅kj10qi⋅kj
其中, ⋅ \\cdot ⋅ 表示向量点积运算。注意力分数的分母 10 \\sqrt10 10以上是关于从Transformer到ViT:多模态编码器算法原理解析与实现的主要内容,如果未能解决你的问题,请参考以下文章
从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程
一文梳理视觉Transformer:与CNN相比,ViT赢在哪儿?
2021深度学习的研究方向推荐!TransformerSelf-SupervisedZero-Shot和多模态
Transformer专题Vision Transformer(ViT)原理 + 代码