Redis Stream 流的深度解析与实现高级消息队列一万字
Posted 刘Java
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis Stream 流的深度解析与实现高级消息队列一万字相关的知识,希望对你有一定的参考价值。
详细介绍了 Redis 5.0 版本新增加的数据结构Stream的使用方式以及原理,如何实现更加可靠的消息队列。
文章目录
Stream 概述
基于Reids的消息队列实现有很多种,比如基于PUB/SUB(订阅/发布)模式、基于List的 PUSH和POP一系列命令的实现、基于Sorted-Set的实现。虽然它们都有各自的特点,比如List支持阻塞式的获取消息,Pub/Sub支持消息多播,Sorted Set支持延时消息,但它们有太多的缺点:
- Redis List没有消息多播功能,没有ACK机制,无法重复消费等等。
- Redis Pub/Sub消息无法持久化,只管发送,如果出现网络断开、Redis 宕机等,消息就直接没了,自然也没有ACK机制。
- Redis Sorted Set不支持阻塞式获取消息、不允许重复消费、不支持分组。
Redis Stream 则是 Redis 5.0 版本新增加的数据结构。Redis Stream 主要用于实现消息队列(MQ,Message Queue),可以说是目前最新Redis版本(6.2)中最完美的消息队列实现。
Redis Stream 有如下功能:
- 提供了对于消费者和消费者组的阻塞、非阻塞的获取消息的功能。
- 提供了消息多播的功能,同一个消息可被分发给多个单消费者和消费者组;
- 提供了消息持久化的功能,可以让任何消费者访问任何时刻的历史消息;
- 提供了强大的消费者组的功能:
- 消费者组实现同组多个消费者并行但不重复消费消息的能力,提升消费能力。
- 消费者组能够记住最新消费的信息,保证消息连续消费;
- 消费者组能够记住消息转移次数,实现消费失败重试以及永久性故障的消息转移。
- 消费者组能够记住消息转移次数,借此可以实现死信消息的功能(需自己实现)。
- 消费者组提供了PEL未确认列表和ACK确认机制,保证消息被成功消费,不丢失;
Redis Stream基本上可以满足你对消息队列的所有需求。
2 Stream基本结构
Redis Stream像是一个仅追加内容的消息链表,把所有加入的消息都一个一个串起来,每个消息都有一个唯一的 ID 和内容,它还从 Kafka 借鉴了另一种概念:消费者组(Consumer Group),这让Redis Stream变得更加复杂。
Redis Stream的结构如下:
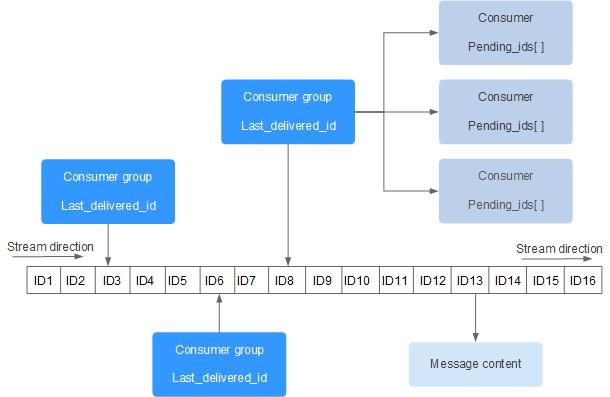
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 XADD 指令追加消息时自动创建。
- Consumer Group:消费者组,消费者组记录了Starem的状态**,使用 XGROUP CREATE 命令手动创建,在同一个Stream内消费者组名称唯一。一个消费组可以有多个消费者(Consumer)同时进行组内消费,所有消费者共享Stream内的所有信息,但同一条消息只会有一个消费者消费到,不同的消费者会消费Stream中不同的消息,这样就可以应用在分布式的场景中来保证消息消费的唯一性。
- last_delivered_id:游标,用来记录某个消费者组在Stream上的消费位置信息**,每个消费组会有个游标,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。创建消费者组时需要指定从Stream的哪一个消息ID(哪个位置)开始消费,该位置之前的数据会被忽略,同时还用来初始化 last_delivered_id 这个变量。这个last_delivered_id一般来说就是最新消费的消息ID。
- pending_ids:消费者内部的状态变量,作用是维护消费者的未确认的消息ID。pending_ids记录了当前已经被客户端读取,但是还没有 ack (Acknowledge character:确认字符)的消息。 目的是为了保证客户端至少消费了消息一次,而不会在网络传输的中途丢失而没有对消息进行处理。如果客户端没有 ack,那么这个变量里面的消息ID 就会越来越多,一旦某个消息被ack,它就会对应开始减少。这个变量也被 Redis 官方称为 PEL (Pending Entries List)。
3 存储数据
使用XADD命令添加消息到Stream末尾,Stream的每个消息不仅仅是一个字符串,而是由一个或多个字段值对组成。XADD也是唯一可以向Stream中添加数据的 Redis 命令,但还有其他命令,例如 XDEL 和 XTRIM,可以从Stream中删除数据。
完整的XADD语法为: XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|ID field value [field value ...]
第一必须的参数是key的名字,如果key对应的Stream不存在,则自动创建,key后面添加NOMKSTREAM命令可以禁止自动创建Stream。
一条消息由一组字段值对组成,它基本上是一个小dict字典。键值对将会按照用户给定的顺序存储,读取Stream的命令(如 XRANGE 或 XREAD)保证返回字段和值的顺序与 XADD 添加的顺序完全相同。
第二个必须的参数是表示Stream中当前消息的唯一ID,Stream中每一个消息都有一个唯一的ID,XADD命令返回的也是添加的消息的ID。如果命令中指定的ID参数是*字符,那么XADD 命令将自动生成一个唯一的ID。
在key和 ID 之后,后面的必须的参数就是组成我们的消息的键值对。
如下案例,向名为xx的Stream中插入一条消息:
127.0.0.1:6379> XADD xx * name xiaoming age 22
"1624458068086-0"
使用XLEN即可查看Stream中的消息数目:
127.0.0.1:6379> XLEN xx
(integer) 1
3.1 Entry ID
自动生成的ID格式为:
<millisecondsTime>-<sequenceNumber>
即当前“毫秒时间戳-序列号”,它表示当前的消息是在毫秒时间戳millisecondsTime产生的,并且是该毫秒内产生的第sequenceNumber+1条消息。这种格式的ID满足自增的特性,支持范围查找。
ID也可以由客户端自己定义,但是形式必须是 “整数-整数”,最小 ID 为 0-1,而且后面加入的消息的 ID 必须要大于前面的消息 ID,如果不大于,那么会返回异常:
127.0.0.1:6379> XADD xx 123-123 name xiaoming age 22
(error) ERR The ID specified in XADD is equal or smaller than the target stream top item
由此之前使用了自动生成的ID,那么后面手动指定的ID也一定要比此前自动生成的ID更大才行,比如:
127.0.0.1:6379> XADD xx 1624458068096-0 name xiaoming age 22
"1624458068096-0"
3.2 数量限制
如果消息积累太多,那么Stream 链表会很长,对内存来说是一个大问题。而XDEL指令又不会真正的删除消息,它只是给消息做了个标志位。
我们可以通过一些指定对Stream进行真正的修剪,限制其最大长度。单独使用XTRIM指令也能对Stream进行限制,它能指定MAXLEN参数,用于指定Stream的最大长度,消息之后长度超过MAXLEN时,会自动将最老的消息清除,确保最多不超过指定长度。
添加3个Stream元素:
127.0.0.1:6379> XADD yy * a1 b1
"1624460262356-0"
127.0.0.1:6379> XADD yy * a2 b2
"1624460267913-0"
127.0.0.1:6379> XADD yy * a3 b3
"1624460273296-0"
127.0.0.1:6379> XRANGE yy - +
1) 1) "1624460262356-0"
2) 1) "a1"
2) "b1"
2) 1) "1624460267913-0"
2) 1) "a2"
2) "b2"
3) 1) "1624460273296-0"
2) 1) "a3"
2) "b3"
使用XTRIM限制最多两个:
127.0.0.1:6379> XTRIM yy MAXLEN = 2
(integer) 1
127.0.0.1:6379> XRANGE yy - +
1) 1) "1624460267913-0"
2) 1) "a2"
2) "b2"
2) 1) "1624460273296-0"
2) 1) "a3"
2) "b3"
可以看到,最老的元素被淘汰掉了。XADD指令也有XTRIM的功能,它能在添加元素的同时对元素数量进行控制,它的可选参数MAXLEN,当添加消息之后长度超过MAXLEN时,会自动将最老的消息清除,确保最多不超过指定长度。
127.0.0.1:6379> XADD yy MAXLEN 2 * a4 b4
"1624460537583-0"
127.0.0.1:6379> XRANGE yy - +
1) 1) "1624460273296-0"
2) 1) "a3"
2) "b3"
2) 1) "1624460537583-0"
2) 1) "a4"
2) "b4"
使用 MAXLEN 选项精确修剪的花销是很大的,Stream 为了节省内存空间,采用了一种特殊的结构表示,而这种结构的调整是需要额外的花销的。所以我们可以使用“~”来表示非精确修剪,它会基保证至少会有指定的N条数据,也可能会多一些。
例如,以下列形式调用 XADD:
ADD mystream MAXLEN ~ 1000 * ... entry fields here ...
上面的命令将添加一个新元素,但也会驱逐旧元素,以便Stream将仅包含 1000 个元素,或最多多几十个元素。
4 获取数据
从Stream中获取数据的方式很多:
- 最基本的就是单个客户端阻塞或者非阻塞的获取消息。
- Redis Stream还支持消费者组的方式获取,消费者组中的每个消费者将消费到不同的消息,这借鉴了kafka的消费者组的特性。
- 基于自增ID的特性,Redis Stream还支持按时间范围获取消息,还支持使用游标迭代消息以增量检查所有未确定的历史消费记录。
Redis Stream通过不同的命令支持上述所有查询模式。
4.1 范围查询
使用XRANGE 和XREVRANGE命令实现消息的正向和逆向的范围查询。
要按范围查询Stream,我们只需要指定两个 ID,一个开始和一个结束。还有两个特殊的ID:- 和 + ,分别表示可能的最小和最大 ID。
如下案例,查询Stream中的全部消息:
127.0.0.1:6379> XRANGE xx - +
1) 1) "1624458068086-0"
2) 1) "name"
2) "xiaoming"
3) "age"
4) "22"
2) 1) "1624458068096-0"
2) 1) "name"
2) "xiaoming"
3) "age"
4) "22"
返回是一个包含两项的元素数组:ID 和字段键值对列表。
由于ID的第一部分是unix时间戳,因此特别适合范围查找,并且ID支持不传递序列值部分,这是允许的。如果没有传递序列值,那么范围的开头将假定ID的序列值为 0,而在结束部分将假定ID序列之为最大值可用序列号。
127.0.0.1:6379> XRANGE xx 1624458068086 1624458068087
1) 1) "1624458068086-0"
2) 1) "name"
2) "xiaoming"
3) "age"
4) "22"
XRANGE 最后支持一个可选的 COUNT 选项,通过该选项指定返回前 N 个消息。
127.0.0.1:6379> XRANGE xx - + COUNT 1
1) 1) "1624458068086-0"
2) 1) "name"
2) "xiaoming"
3) "age"
4) "22"
默认情况下,范围包含两个端点,可以在第一个ID前使用“(”来排除第一个端点值匹配。
127.0.0.1:6379> XRANGE xx 1624458068086 1624458068096
1) 1) "1624458068086-0"
2) 1) "name"
2) "xiaoming"
3) "age"
4) "22"
2) 1) "1624458068096-0"
2) 1) "name"
2) "xiaoming"
3) "age"
4) "22"
使用“(”之后:
127.0.0.1:6379> XRANGE xx (1624458068086 1624458068096
1) 1) "1624458068096-0"
2) 1) "name"
2) "xiaoming"
3) "age"
4) "22"
由于 XRANGE 的复杂度是 O(log(N)) 来寻找,然后 O(M) 来返回 M 个元素,因此在很少计数的情况下,该命令具有对数时间复杂度,这意味着迭代的每一步都很快。所以 XRANGE 也可以作为的流迭代器,不需要 XSCAN 命令(Redis没有提供XSCAN)。
命令 XREVRANGE 与 XRANGE 等效,但以相反的顺序返回元素,两个ID参数顺序也是相反的,因此 XREVRANGE 的实际用途是检查Stream中的最后一项是什么:
127.0.0.1:6379> XREVRANGE xx + - COUNT 1
1) 1) "1624458068096-0"
2) 1) "name"
2) "xiaoming"
3) "age"
4) "22"
4.2 独立消费消息
通常我们想要的是订阅到达Stream的新消息,而不是不想按Stream中的范围访问消息。也就是生产-消费模式,这个概念可能与 Redis Pub/Sub或 Redis 阻塞列表有关,但在使用Stream的方式上存在根本差异。
一个Stream可以有多个客户端(消费者)等待数据。默认情况下,每个新消息都将交付给在给定Stream中等待数据的每个消费者。这种行为不同于每个消费者将获得不同的消息的阻塞列表,但是,交付给多个消费者的能力类似于 Pub/Sub。
在Pub/Sub 中,消息一经推出就被丢弃,无论如何都不会存储,而在使用阻塞列表时,当客户端收到消息时,消息会从列表中弹出(有效地删除),但Stream以完全不同的方式工作。所有的消息都无限期地存储在Stream中(除非用户明确要求删除消息):不同的消费者会通过记住收到的最后一条消息的 ID 来指导什么是最新消息。
XREAD命令提供侦听到达一个或者多个Stream的新消息的能力,仅返回 ID 大于调用者传递的最后接收到的ID的消息。
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
4.2.1 非阻塞使用
如果不使用 BLOCK 选项,则该命令是同步的,可以认为与 XRANGE 有点相关:它将返回流内的一系列项目,但是即使我们只考虑同步用法,它与 XRANGE 相比也有两个根本区别:
- 如果我们想同时从多个key中读取,可以在调用此命令传递多个Stream的key。这是 XREAD 的一个关键功能,因为尤其是在使用 BLOCK 进行阻塞时,能够通过单个连接侦听多个key是一项重要功能。
- XRANGE 常用于返回两个ID 范围中的一系列消息,但 XREAD 更适合获取从某个ID开始的一系列消息,该消息可能我们目前获取的任何其他消息的ID都大,即从前向后消费最新的消息。XREAD常用于用于迭代Stream的消息,所以我们传递给 XREAD 的通常是我们上一次从该Stream接收到的最后一个消息的ID。
XREAD的简单使用如下,有两个流 xx和 yy,并且我想从它们包含的第一个元素开始从这两个流中读取数据,可以像下面的示例一样调用 XREAD:
127.0.0.1:6379> XREAD STREAMS xx yy 0 0
1) 1) "xx"
2) 1) 1) "1624458068086-0"
2) 1) "name"
2) "xiaoming"
3) "age"
4) "22"
2) 1) "1624458068096-0"
2) 1) "name"
2) "xiaoming"
3) "age"
4) "22"
2) 1) "yy"
2) 1) 1) "1624460273296-0"
2) 1) "a3"
2) "b3"
2) 1) "1624460537583-0"
2) 1) "a4"
2) "b4"
命令中的STREAMS 选项是必须的,并且必须是最终选项,因为该选项后面就是要获取对应Stream的起始ID:
STREAMS key_1 key_2 key_3 ... key_N ID_1 ID_2 ID_3 ... ID_N
上面的案例中,我们编写的起始ID都是0(不完整的ID是有效的,规则和XRANGE一样),因此我们希望从Stream xx和Stream yy中获取的所有消息的ID都大于0-0(不会包含传递的ID)。
我们也可以在之前添加COUNt N选项,表示最多从每一个Stream中返回N个消息:
127.0.0.1:6379> XREAD COUNT 1 STREAMS xx yy 0 0
1) 1) "xx"
2) 1) 1) "1624458068086-0"
2) 1) "name"
2) "xiaoming"
3) "age"
4) "22"
2) 1) "yy"
2) 1) 1) "1624460273296-0"
2) 1) "a
在上面的示例中,我们收到的流 xx和yy收到的最后一个消息的ID为 1624458068086-0和1624460273296-0,因此下一次迭代时,我们传递的ID就是最后一条消息的ID:
127.0.0.1:6379> XREAD COUNT 1 STREAMS xx yy 1624458068086-0 1624460273296-0
1) 1) "xx"
2) 1) 1) "1624458068096-0"
2) 1) "name"
2) "xiaoming"
3) "age"
4) "22"
2) 1) "yy"
2) 1) 1) "1624460537583-0"
2) 1) "a4"
最终,当Stream被迭代(顺序消费)完毕时,调用不会返回任何消息,而只是一个空数组,如果想要随时获取最新推动的消息,那么我们必须不断地重试该操作,因此该命令也支持阻塞模式。
4.2.2 阻塞的使用
上面的非阻塞使用方式和XRANGE似乎没有太大的区别,有趣的部分是我们可以通过指定 BLOCK 可选参数轻松地将 XREAD 转换为阻塞命令,该命令能够根据指定的Stream和 ID 进行阻塞,并在请求的key之一接受数据后自动解除阻塞。
重要的是,如果存在多个使用此命令等待相同Stream的相同ID范围的客户端,那么每个消费者都将获得一份数据副本,这与使用阻塞列表的弹出操作时发生的情况不同,阻塞列表中每一个消费者将获得不同的消息。
可以指定阻塞的超时时间,单位是毫秒,如果传递0,则表示永久阻塞直到任何一个的Stream有数据返回。超时时间过了之后如果没有如何条件的消息到达,该命令自动返回null。
即使传递了 BLOCK 命令,但至少在传递的Stream之一中有符合数据可以立即返回时,该命令将同步执行,就像缺少 BLOCK 选项一样。
另外,当阻塞时,有时我们只想接收从阻塞那一刻开始通过 XADD 添加到流中的消息,我们对已添加消息的历史记录不感兴趣。对于此需求,我们可以使用特殊的“$”ID 向流发出信号,表明我们只需要最新的消息,这也通常是最常用的。Redis会默认检查Stream中目前最大的消息的ID,并在 XREAD 命令行中使用该ID。
如下案例,我们阻塞的监听xx和yy两个Stream,都是采用“$”监听最新的数据,且超时时间为10000毫秒,即10秒。
127.0.0.1:6379> XREAD BLOCK 10000 STREAMS xx yy $ $
1) 1) "yy"
2) 1) 1) "1624506208518-0"
2) 1) "a5"
2) "b5"
(2.88s)
当使用“$”监听最新的数据之后,下一个指令的ID就应该传递这次返回的最大的ID。
与阻塞列表操作类似,从等待数据的客户端的角度来看,阻塞Stream读取是公平的,因为语义是 FIFO 风格。当新项目可用时,第一个阻塞给定Stream的客户端将是第一个解除阻塞的客户端。
XREAD 除了 COUNT 和 BLOCK 之外没有其他选项,因此它是一个非常基本的命令,具有特定目的,可以直接使用消费者监听一个或多个流。使用消费者组 API 可以获得更强大的使用流的功能,但是通过消费者组读取是由名为 XREADGROUP 的不同命令实现的。
4.3 消费者组
4.3.1 基本概念
XREAD可以实现一个消费者监听多个Stream,当有数据到达的时候,满足条件的数据将会返回给买一个消费者同样的副本,实现消息的多播。但有时候,我们可能需要的不是为多个不同的消费者或者客户端提供相同的消息流,而是从同一Stream中向许多客户端提供不同的消息子集。
这样的一个明显有用的案例是处理缓慢的消息,通过将Stream中不同的消息路由到准备好接收Stream的不同线程来扩展消息处理的能力。
我们想要的是不同的消费者消费Stream中的不同的数据,这看起来和阻塞列表有些相似的。为了实现这一点,Redis Stream使用了一个称为消费者组(consumer groups)的概念。这个名字明显借鉴了kafka,但是从实现的角度来看,Redis 消费者组与 Kafka消费者组没有任何关系。kafka的消费者组中的消费者还需要和分区对应,而Redis的消费者组中的消费者相当于直接从Stream中获取消息。
一个消费者组就像一个从一个Stream中获取数据的伪消费者,实际上服务于多个消费者,将获取的消息分发到多个不同的消费者,并且提供了一定的保证:
- 每条消息都提供给不同的消费者,因此不可能将相同的消息传递给同一个组内的多个消费者。
- 在消费者组中,消费者通过名称进行标识,该名称是实现消费者的客户端必须提供的区分大小写的字符串。因此,即使在断开连接后,流消费者组仍保留所有消费者的状态,客户端可以再次声明为同一个消费者。
- 每个消费者组中都有第一个没有消费的 ID 的概念:last_delivered_id,这样当消费者请求新消息时,它可以只提供以前未传递的消息。
- 消费消息需要使用特定命令进行显式确认,即ack。这表示此消息已正确处理,因此可以从消费者组中移除。
- 消费者组跟踪所有当前未ack的消息,即已传递给消费者组的某个消费者但尚未确认为已处理的消息。由于此功能,在访问Stream的消息历史记录时,每个消费者只会看到传递给它的消息。
一个消费者组也可以被理解Stream的一种状态记录,或者说Stream的一种辅助数据结构,很明显单个Stream可以有多个消费者组,这些消费者组可以具有不同的消费者集。
实际上,甚至可以在同一个流中让客户端在没有消费者组的情况下通过 XREAD 读取,而客户端在不同的消费者组中则通过 XREADGROUP 命令读取。
消费者组的相关命令:
XGROUP用于创建、销毁和管理消费者组。XREADGROUP用于通过消费者组从Stream中读取消息。XACK允许消费者将待处理消息标记为已正确处理。
4.3.2 创建消费者组
XGROUP命令的功能非常强大,命令模版为:
XGROUP [CREATE key groupname ID|$ [MKSTREAM]] [SETID key groupname ID|$] [DESTROY key groupname] [CREATECONSUMER key groupname consumername] [DELCONSUMER key groupname consumername]
XGROUP命令用于管理与Stream数据结构关联的消费者组。能够做的事:
- 创建与流关联的新消费者组。
- 销毁一个消费者组。
- 从消费者组中删除特定消费者。
- 将消费者组的last_delivered_id设置为其他值。
通过XGROUP CREATE可以创建某个Stream的消费者组,必须传递起始消息 ID 参数用来初始化 last_delivered_id 变量,这样消费者组才能知道当第一个消费者连接时接下来要提供什么消息,即刚创建组时的最后一条消息 ID 是什么。
一个简单的示例如下:
127.0.0.1:6379> XGROUP CREATE yy mygroup 0
OK
如果我们提供“ ” 作 为 I D , 那 么 表 示 只 有 从 现 在 开 始 到 达 S t r e a m 中 的 新 消 息 才 会 提 供 给 组 中 的 消 费 者 。 如 果 我 们 指 定 0 , 那 么 表 示 消 费 者 组 将 消 费 S t r e a m 历 史 记 录 中 的 所 有 消 息 , 从 第 一 条 开 始 。 我 们 也 可 以 可 以 指 定 任 何 其 他 有 效 I D , 只 需 要 直 到 消 费 者 组 将 开 始 传 递 大 于 指 定 的 I D 的 消 息 。 因 为 “ ”作为ID ,那么表示只有从现在开始到达Stream中的新消息才会提供给组中的消费者。如果我们指定 0 ,那么表示消费者组将消费Stream历史记录中的所有消息,从第一条开始。我们也可以可以指定任何其他有效 ID,只需要直到消费者组将开始传递大于指定的 ID 的消息。因为“ ”作为ID,那么表示只有从现在开始到达Stream中的新消息才会提供给组中的消费者。如果我们指定0,那么表示消费者组将消费Stream历史记录中的所有消息,从第一条开始。我们也可以可以指定任何其他有效ID,只需要直到消费者组将开始传递大于指定的ID的消息。因为“”表示流中当前最大的消息ID,所以指定“$”将产生仅消费新消息的效果。
XGROUP CREATE 还支持自动创建Stream(如果它不存在),使用可选的 MKSTREAM 子命令作为最后一个参数:
127.0.0.1:6379> XGROUP CREATE yyy mygroup $ MKSTREAM
OK
4.3.3 从消费者组消费
我们可以使用 XREADGROUP 命令通过消费者组读取消息。
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
XREADGROUP 与 XREAD 非常相似,提供相同的 BLOCK 阻塞选项,否则为同步命令。但是,必须始终指定一个强制性选项,即 GROUP, 并且有两个参数:消费者组的名称和尝试读取的消费者的名称。选项 COUNT 也受支持并且与 XREAD 中的选项相同。
消费者名称是客户端用来在组内标识自己的字符串。Redis发现新名字的消费者时,它会在对应的消费者组内自动创建,不同的客户端应该选择不同的消费者名称。
Stream yy中有4条数据:
127.0.0.1:6379> XRANGE yy - +
1) 1) "1624516905844-0"
2) 1) "a3"
2) "b3"
2) 1) "1624516910389-0"
2) 1) "a4"
2) "b4"
3) 1) "1624516914709-0"
2) 1) "a5"
2) "b5"
4) 1) "1624516919774-0"
2) 1) "a6"
2) "b6"
我们创建一个消费者并且消费消费者组mygroup中的一条消息:
127.0.0.1:6379> XREADGROUP GROUP mygroup c1 COUNT 1 STREAMS yy >
1) 1) "yy"
2) 1) 1) "1624516905844-0"
2) 1) "a3"
2) "b3"
上面的命令中。在 STREAMS 选项之后,请求的 ID 是特殊 ID “>”。这个特殊的 ID 只在消费者组的上下文中有效,它的意思是:获取到目前为止,从未传递给其他消费者的消息,并且会更新last_delivered_id,通常都是传递这个参数。
ID也可以指定0、其他ID或者不完整的ID(时间戳部分),但这样的话,Stream只会返回已传递给当前消费者并且没有被XACK确定的历史消息,即该消费者内部的 以上是关于Redis Stream 流的深度解析与实现高级消息队列一万字的主要内容,如果未能解决你的问题,请参考以下文章 Redis Stream 流的深度解析与实现高级消息队列一万字