算法——二分查找
Posted 诊断协议那些事儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法——二分查找相关的知识,希望对你有一定的参考价值。
文章目录
数据查找算法
我们在使用DTC列表时,会使用升序进行排列,以供查找,常见的查找算法有顺序查找、二分查找、插值查找等,顺序查找也叫线性查找,其基本原理是对于任意一个序列以及一个给定的元素,将给定元素与序列中元素依次比较,直到找出与给定关键字相同的元素,或者将序列中的元素与其都比较完为止,当然此种算法效率偏差。
一、二分查找
二分查找也叫折半查找,是一种效率比较高的查找算法,但是使用它有个前提:必须是顺序存储的线性数据表。首先看两个例子:
输入:nums = [5,13,19,21,37,56,64,75,80,88,92],keyData = 19
输出:2
解释:19出现在nums中,并且下标为2
输入:nums = [5,13,19,21,37,56,64,75,80,88,92],keyData = 23
输出:-1
解释:23在nums中不存在,因此返回-1
二、基本思想
因为整个数组是有序的,假设为升序:
①首先选择数组中间的数据,与需要查找的查找值比较,如果相等,则查找结束,直接返回数组下标。
②如果不相等:
i.如果中间的数字大于查找值,则中间数字向右的所有数字都大于查找值,全部排除。将右值设置为中间位置的前一个!
ii.如果中间的数字小于查找值,则中间数字向左的所有数字都小于查找值,全部排除。将左值设置为中间位置的下一个!
③设置完成后,继续从新区间的中间值开始比较,即继续第一步的内容直至查找完成。
④如果没有查找到,则返回-1.
三、测试代码
使用此设计:数组元素不存在时,选择与其最接近的数组元素下标!如当查找数据小于最小数据时输出数组下标0,当查找数据大于最大数据时,输出最后一个数组下标。
#include<stdio.h>
#define TEMP_ADC_COUNT 11
static const unsigned int TEMP_ADC[TEMP_ADC_COUNT]=
5,13,19,21,37,56,64,75,80,88,92
;
static int ABS(int data)
if(data >= 0)
return data;
else
return (-data);
/* sortedSeq是数组,size是数组的大小,keyData是需要查找的值 */
static int BinarySearch(const unsigned int *sortedSeq,unsigned int size,unsigned int keyData)
unsigned int low = 0,mid,high = size - 1;
if(sortedSeq == NULL || size < 1)
return -1;
if(1 == size)
return 0;
if(sortedSeq[0] >= keyData)
return 0;
if(sortedSeq[high] <= keyData)
return high;
while(low <= high)
mid = low + ((high - low)/2); /* 等价于mid = (low + high)/2 ,防止溢出 */
if(ABS(sortedSeq[mid + 1] - keyData) > ABS(sortedSeq[mid] - keyData))
high = mid - 1;
else
low = mid + 1;
if(ABS(sortedSeq[mid + 1] - keyData) < ABS(sortedSeq[mid] - keyData))
return (mid + 1);
else
return mid;
int main(void)
int temp1,temp2,temp3,temp4,temp5;
temp1 = BinarySearch(TEMP_ADC,TEMP_ADC_COUNT,1);
temp2 = BinarySearch(TEMP_ADC,TEMP_ADC_COUNT,19);
temp3 = BinarySearch(TEMP_ADC,TEMP_ADC_COUNT,23);
temp4 = BinarySearch(TEMP_ADC,TEMP_ADC_COUNT,36);
temp5 = BinarySearch(TEMP_ADC,TEMP_ADC_COUNT,95);
printf("temp1 = %d\\ntemp2 = %d\\ntemp3 = %d\\ntemp4 = %d\\ntemp5 = %d\\n",temp1,temp2,temp3,temp4,temp5);
getchar();
return 0;
输出结果:

当数据位于两者之间时,取数组元素下标较小的!
temp2_1 = BinarySearch(TEMP_ADC,TEMP_ADC_COUNT,16);/* 13 14 15 17 18 19*/
printf("temp2_1 = %d\\n",temp2_1);
输出:temp2_1 = 1 /*13对应下标为1 , 19对应下标为2 */
四、复杂度分析(升序)
我们可以将查找的过程用一棵二叉排序树来表示,二分法也称判定树,根节点即为顺序表的中间元素,根节点的左子树,全是比根节点小的元素,右子树全是比根节点大的元素,每一棵子树同样满足这一性质,如下图所示:
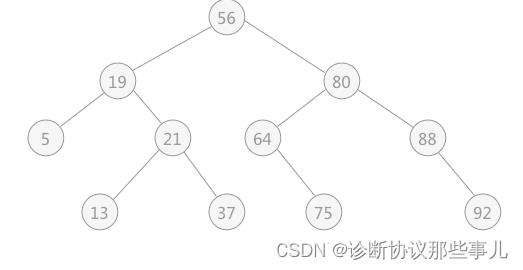
由上图可知,如果想在查找表中查找 21 的位置,只需要进行 3 次比较,依次和 56、19、21 进行比较,而比较的次数恰好是该关键字所在判定树中的层次(关键字 21 在判定树中的第 3 层)。对于具有 n 个结点(查找表中含有 n 个关键字)的判定树,它的层次数至多为: log2(N) + 1
总结
二分查找的缺点很明显,当在1-1000的数组(步进为1)查找2时,会从中间500开始二分,然后循环下去,这样二分次数会比较多,查找的相对路径较深。基于此我们可以优化二分算法——插值查找。
插值查找是根据查找的关键字keyData与查找表中最⼤和最⼩记录的关键字比较后的查找方法, 其核心就是在于插值的计算公式: (keyData - a[low]) / (a[high] - a[low])。举个例子,在1-1000的范围查找2,会判断2和1000的比例k,然后从数组长度*k的位置开始查找。
int InterpolationSearch(const unsigned int *sortedSeq,unsigned int size,unsigned int keyData)
int low, high, mid;
low = 1;
high = size;
while (low <= high)
//插值
mid = low + (high - low) * (keyData - sortedSeq[low]) / (sortedSeq[high] - sortedSeq[low]);
if (keyData < sortedSeq[mid])
//若keyData比sortedSeq[mid]插值小,则将最高下标调整到插值下标小一位;
high = mid - 1;
else if (keyData > sortedSeq[mid])
//若keyData比sortedSeq[mid]插值 大,则将最低下标调整到插值下标大一位;
low = mid + 1;
else
//若相等则说明mid即为查找到的位置;
return mid;
return 0;
以上是关于算法——二分查找的主要内容,如果未能解决你的问题,请参考以下文章