小目标分割论文阅读TPAMI-《Small-Object Sensitive Segmentation Using Across Feature Map Attention》
Posted 为啥不能叫小明了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小目标分割论文阅读TPAMI-《Small-Object Sensitive Segmentation Using Across Feature Map Attention》相关的知识,希望对你有一定的参考价值。
论文信息
paper:Small-Object Sensitive Segmentation Using Across Feature Map Attention
code:https://github.com/ShengtianSang/AFMA
内容
背景
要解决的问题:小目标分割困难——图像分割领域中,常采用卷积和池化等操作来捕获图像中的高级语义特征,但同时降低了图像/特征的分辨率,造成图像中的一些小对象(小目标)信息丢失,从而使模型很难从这些低分辨率的特征图中恢复出小目标的信息。
小目分割先前的研究工作:
- 提升输入图像分辨率或生成高分辨率的特征图 ,缺点是增加训练和测试时间;(PS:个人测试过,通常情况下不好使)
- 更改模型结构,如加入skip connections, hypercolumns, feature pyramids, dilated convolution等结构,用多个低层次特征层的特征来加强高层次的小分辨的特征层的特征;缺点:集成多尺度表示的策略不能保证同一对象的特征对齐,且特征对语义分割的解释性不强
- 后处理 ,如马尔可夫随机场和基于条件随机场的后处理,参考文献 。 缺点:后处理是分割模型训练的一个独立部分,网络不能根据后处理输出来调整模型权重;
- 修改损失函数 改变损失函数的优点是它不会给分割模型引入额外的计算成本。但对语义分割来说,小目标分割的改进还不够具有可解释性。
作者的思想:(用同一类别中的大目标信息补偿小目标丢失的信息)
我们提出了一种新的小目标敏感分割策略,不依赖于增加数据规模,扩大图像/特征大小,或修改网络结构。考虑到同一物体类别往往具有相似的成像特征,利用同一类别内大小物体之间的关系来补偿特征传播带来的信息损失。
具体做法:提出了跨特征映射注意(Across Feature Map Attention, AFMA),它通过计算中间特征块与图像块之间的相互关系矩阵来表示同一类别对象的相似度。然后利用这种关系来增强小目标的分割。
作者的贡献:
- 提出了一种新的方法,即Across Feature Map Attention,来充分利用同一类别对象之间的关系,增强小目标的分割。
- 据我们所知,我们是第一个提出了用不同层次特征图之间的关系来表征注意力的方法。
- 与以往应用数据增强或多尺度处理的方法不同,我们的AFMA提供了更多可解释的特性(见论文4.4和4.5节)。
- 提出的AFMA是轻量级的,可以很容易地集成到各种架构中。例如,DeepLabV3、Unet、Unet++、MaNet、FPN、PAN、LinkNet和PSPNet,实现了2.5%、4.7%、3.0%、3.0%、2.5%、5.0%、4.0%和2.9%的改进,但只增加了不到0.1%的参数。
方法
AFMA为一种即插即用模块,可应用到现有的大部分分割模型中(插入在Encoder部分,输出作用在decoder的最终输出部分)。其应用如下图所示。(a)给出了通用的分割模型中使用AFMA模块的示意,(b)为AFMA 作用于具体的不同语义分割模型(文中实验采用的模型)的示意图。

AFMA模块的具体结构如下图所示:

(a)构造部分(模块插入)
- 1 和 2.分别对输入图像和特征图(第i层)做卷积,将其通道数分别变为1和Nc(分割物体的类别数)
- 3 和 4.分别对1和2的输出划分为相同尺寸的patch(不够整除时,特征图右、下方补0)。
- 5.将步骤3、4 获得的patch进行展平,使用点积(矩阵乘)操作计算得到的特征图,得到大小为 H W d 2 × H 1 W 1 d 2 × N c \\fracHWd^2\\times \\fracH_1W_1d^2\\times N_c d2HW×d2H1W1×Nc的 AFMA。该 AFMA 保存的是原始图像图像块(可能包含小物体)和特征图特征块(可能包含大物体)之间的关系。
(b)使用部分(模块使用)
-
6.采用平均池化将Decoder部分的输出调整至 步骤2 的尺寸
-
7.对6的输出划分patch,同 步骤4 相同,其中每个patch的特征块包含的是模型原始结果的“压缩”结果。
-
8.对步骤7的patch进行展平,并采用矩阵乘的方式计算与AFMA的结果,该结果表示原始输出可能包含的小物体信息。
-
9.对步骤8的结果进行reshape,恢复至原来的尺寸,将其与Decoder部分的输出相加作为最终的预测结果。
(c)模块的金标准构造
- 10.构造金标准的AFMA仅采用ground truth完成,同步骤6相同,采用平均池化操作,将ground truth的尺寸调整至 步骤2 的尺寸;对原始和采样后的ground truth进行patch操作,然后采用步骤5的方式计算得到金标准的AFMA。示意图如下图所示。

训练损失:分割部分采用交叉熵损失,AFMA模块采用MSE损失。
实验
实验细节:
数据集:CamVid and Cityscape
小目标定义:CamVid:sign symbol, pedestrian, pole, bicyclist。Cityscape:pole, traffic
light, traffic sign, person, rider, motorcycle, bicycle。
结果:
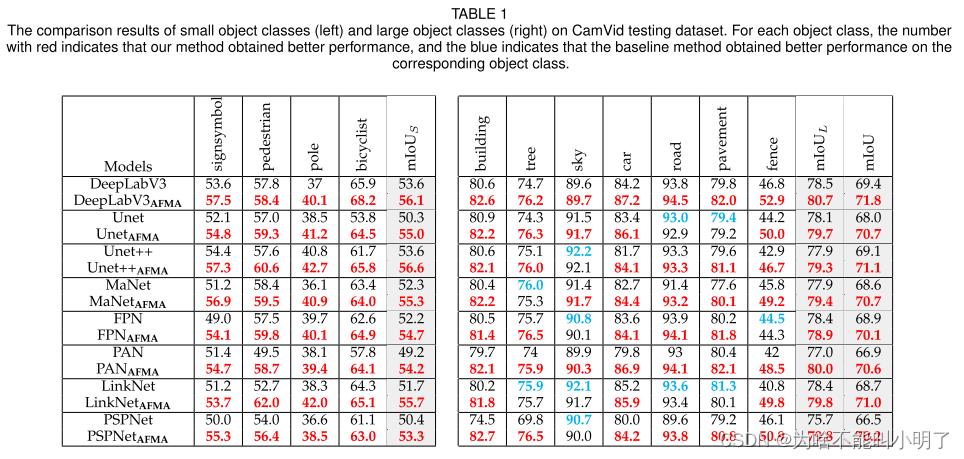
在两个数据集上行的实验结果分别如下图所示:
CamVid数据集的结果
Cityscape数据集的结果


不同关注深度的AFMA在CamVid数据集上的测试结果:

文中做作者也给出了一些错分的案例(详见论文4.8部分):
例子1:CamVid数据集中,bicyclist定义为骑着自行车的人(bicyclist = human + bycycling),作者所提的方法独立计算了骑自行车者的人和自行车的AFMA,从而使骑自行车的人与行人有更多的相似之处,而自行车与汽车有更多的关联,如下图(a)(b)。
例子2:AFMA丢失了一些局部关系,产生了局部偏见,如下图(c)所示,基线方法将树枝上的天空分割成与ground truth相同的树。而AFMA在此区域上添加了包含天空的图像patch上的关系,从而将此区域划分为天空。
例子3:标签不一致(未被标记的)小物体会导致分割错误,如下图(d)和(e)。作者所提的方法对测试集中没有标记的远处的小树和远处的小电线杆进行了分割。

讨论
1. Why not directly resize the input image to obtain AFMA?
作者通过实验发现,直接调整输入图像的大小计算AFMA的性能要比所提的方法低得多。这可能是因为feature map比调整后的图像patch(同样大小)具有更大的感受野和更丰富的语义信息。
2. The shape/size of the image/feature patch.
作者在文中提到,AFMA对于 image/feature patch的shape/size有一定的偏好,如在计算AFMA时,汽车类别可能倾向于正方形的图像/特征块,而柱子类的对象可能倾向于细长矩形图像/特征块。
3. What if an image only has one object for a given class?
作者的方法利用对象之间的关系来补偿小对象的信息损失。因此,标准的应用场景为一个图像中同一类的物体至少存在两个。但是,在某些场景中,图像中可能只有一个特定类型的对象。作者的实验所采用的两个数据中单独出现的对象很少。为此作者额外补充了一些单对象分割的实验。在肝脏分割(LiTS5)、皮肤损伤(skin lesions Analysis Towards Melanoma Detection)和鸟类(the CaltechUCSD birds)这三个数据集上进行实验验证。PAN分割模型加入AFMA后在皮肤病灶分割上提高了1.9%的mIoU, MaNet分割模型加入AFMA后在鸟类分割上提高了3.6%的mIoU。作者认为这是因为AFMA可以增强目标物体与其他图像patch之间的不相关关系,从而消除目标物体的假阳性预测。
以上是关于小目标分割论文阅读TPAMI-《Small-Object Sensitive Segmentation Using Across Feature Map Attention》的主要内容,如果未能解决你的问题,请参考以下文章
论文速递TPAMI2022 - 自蒸馏:迈向高效紧凑的神经网络
TPAMI 2022 | RC-Explainer:图神经网络的强化因果解释器