哈工大刘挺:自然语言处理中的可解释性问题!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哈工大刘挺:自然语言处理中的可解释性问题!相关的知识,希望对你有一定的参考价值。
“知其然,亦知其所以然”是现代计算机科学家针对神经网络可解释性问题追逐努力的方向和梦想。针对自然语言处理中的可解释性问题,哈尔滨工业大学刘挺教授在2022北京智源大会报告中做了详尽的解读。首先介绍了自然语言处理中的可解释性概念,分类及研究可解释性的必要性,重点介绍了可解释自然语言处理中的三种方法,包括白盒透明模型的设计、黑盒事后解释方法以及灰盒融合可解释要素方法。最后,刘挺教授提出了可解释性的白盒模型设计以及可解释性评估等未来发展的挑战和研究方向。(注:本文由第三方整理,未经本人审阅)

刘挺,哈尔滨工业大学教授,哈工大计算学部主任兼计算机学院院长、自然语言处理研究所所长
整理:路啸秋
NLP中的可解释性
可解释的人工智能(Explainable AI,XAI),是一种以人类可理解的方式解释人工智能系统输出结果的能力。可解释性的成功不仅取决于算法,同时还要借鉴哲学、认知心理学、人机交互等多学科的思想,令使用者及开发者更好地理解人工智能背后的决策和推理机制。
如今,大多数端到端的深度学习模型都是黑盒。开发者很难得知AI系统做出某个决策的依据,难以辨析影响方法成败的关键因素。因而,开发者难以进行针对性的调整,修改神经网络的架构,从而使决策过程更加准确。而可解释的AI可以在做出决策的同事给出相应的依据,明确AI方法的适用场景,使决策结果是可控可反馈的,增强用户对人工智能系统的信赖度。
深度学习已经取得了巨大成功,但深度学习的进一步应用遇到了伦理、用户信任以及纠错等方面的挑战,尽管黑盒系统因其优越的性能得到广泛应用,但也因为其决策难以被理解所以在应用中受到限制。
可解释性是衡量人工智能系统性能的重要指标。在司法、医疗、金融等重要领域中,不可知、不可控的人工智能技术会引发争议。可解释性的研究能够提升人工智能技术的可信度,实现更加可控的推理决策。
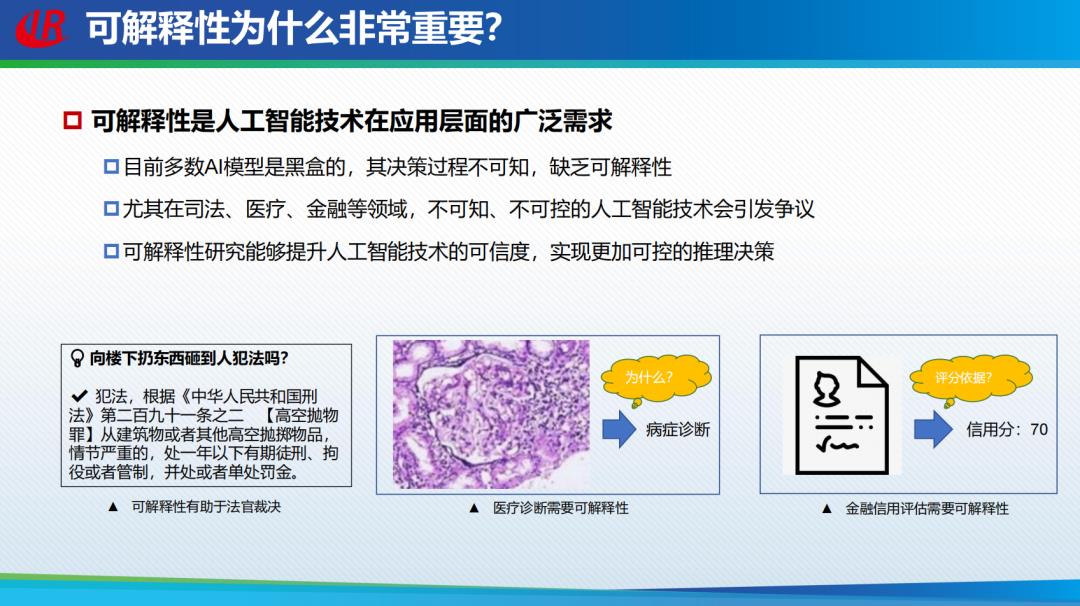
可解释AI在国际上受到了越来越大的关注,越来越多的国际相关组织机构将可解释性AI作为重要的技术发展战略。例如,美国DARPA在2017年开展了可解释人工智能计划,2019年谷歌发布了《可解释人工智能白皮书》等。在我国,《新一代人工智能发展规划》提到了可解释人工智能的研究。今年5月16号,国家自然科学基金委也提出了「可解释、通用的下一代人工智能方案」重大研究计划。
可解释人工智能系统主要由被「解释的对象」、「解释者」以及「解释受众」三部分组成。被解释的对象即人工智能体的决策机制;解释者为负责提供解释的一方,一般会由机器自我解释,也有一部分是事后解释,包括第三方的解释系统或者人类专家;解释的受众是听取解释并试图理解的一方,包括AI系统开发者、AI使用者和受影响者、AI系统监管者等。
模型的解释可以分为两大类:
(1)透明模型,即自解释或直接解释。在做出决策或预测的过程中直接产生一些信息,呈现给用户一种解释。此时,解释和模型的预测同时产生。例如,决策树和基于规则的模型都是透明的模型。
(2)事后解释,对于预测结果需要执行额外的操作才能够解释当前系统做出决策的原因。比如利用可解释模型对复杂模型的部分输出进行建模,形成替代模型,使用可解释的替代模型解释输出。

可解释自然语言处理可以简称为XNLP,指能以可解释、可理解、人机交互的方式,与自然语言处理系统的开发者、使用者、决策者等,达成清晰有效的交流沟通。在取得人类信任的同时,满足各类应用场景对智能体决策机制的监管要求。
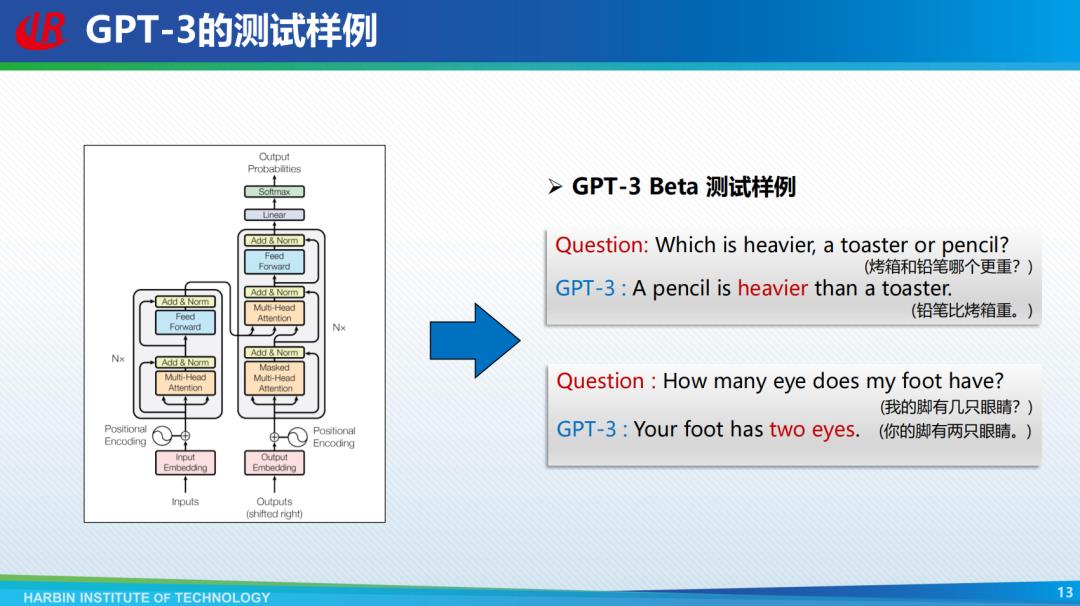
传统的自然语言处理方法具有可解释性,可称之为白盒技术。应用白盒技术便于用户与系统之间的交互、有利于开发者对系统的修改纠错。而深度学习模型以语言嵌入作为特征,尽管显著提高了模型的性能,但模型难以解释,可称之为黑盒技术。应用黑盒技术更容易获取更优秀的结果,但是在涉及财产和生命安全等因素的领域难以更广泛地应用。例如,性能极其优异的深度学习模型GPT-3会在如下所示的预测任务中出现错误,而研究者难以分析其做出错误决策的原因。
计算机视觉领域可以通过注意力机制,利用“高亮”显示与标签相关的图像区域;而自然语言处理领域除了注意力机制“高亮”显示与标签相关的文本片段之外,还可以通过输出“解释文本”辅助理解决策原因,比如或者利用结构化的知识图谱、符号推理给出推理路径,用推理路径来进行解释。

白盒透明模型设计
白盒透明模型的设计主要方法首先是特征重要性,提取特征过程当中已经埋下了后续对系统进行解释的一个非常好的伏笔。其次是溯源,比如问奥巴马的女儿有多大,基于知识图谱进行推理得到的奥巴马的女儿是18岁,那么把知识图谱推理路径展示出来就成为一个很好的解释。
刘挺老师所在实验室针对白盒系统的设计做了一个基于神经自然逻辑的多项选择问答系统,尝试用神经网络的方法执行符号推理,本质推理还是在符号层面进行推理,具有天然的可解释性。但由于符号推理本身存在一些问题,需要用神经网络的语义的表示方法去注入,使符号推理的任务更可行更强大。
系统主要针对多项选择问题,例如把grandPaOf进行拆分,可以等价推出关系是祖孙的关系,但是库里面只有grandfather这样的关系词,可以通过语义的相似度计算,把grandpa和grandfather进行合并。系统采用自然逻辑进行推理,自然逻辑是一种基于语义单调性的逻辑,有7种基本的语义关系,可以直接在文本上通过插入、删除和替换单词进行扩展、推理。比如所有动物需要水,经过操作,动物是反向蕴含狗,所有动物都需要水,所有狗也都需要水,就可以进行这样的推理。
同时系统希望采用证据推理来支持问答的任务,比如说问啮齿动物吃植物吗?有一个支持的答案或者叫证据就是松鼠是吃松子的,松鼠是啮齿动物,松子是一种植物,就可以用自然逻辑通过增删改等等方式进行替换,把推理路径找出来,这个解释自然也就成立。但在找推理路径尤其各种概念合一的过程当中,又是需要神经网络的帮助,用神经网络去进行嵌入式语义表示,更好刻画上下文,更准确的判断单词与单词之间的语义关系。


黑盒事后解释方法
黑盒事后解释是当前最主要的NLP解释方法。
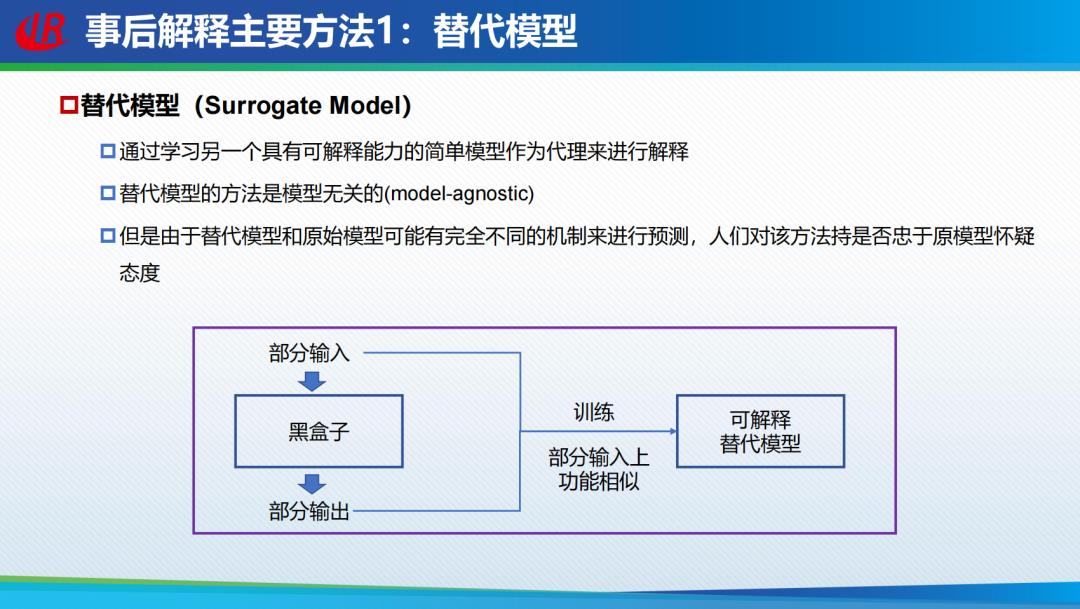
「替代模型」是一种主流的黑盒事后解释方法,它通过学习另一个具有可解释能力的简单模型作为代理来进行解释,让替代模型的输入输出尽可能模拟原来黑盒的模型。但是这种方法的可行性也受到了一些学者的质疑。
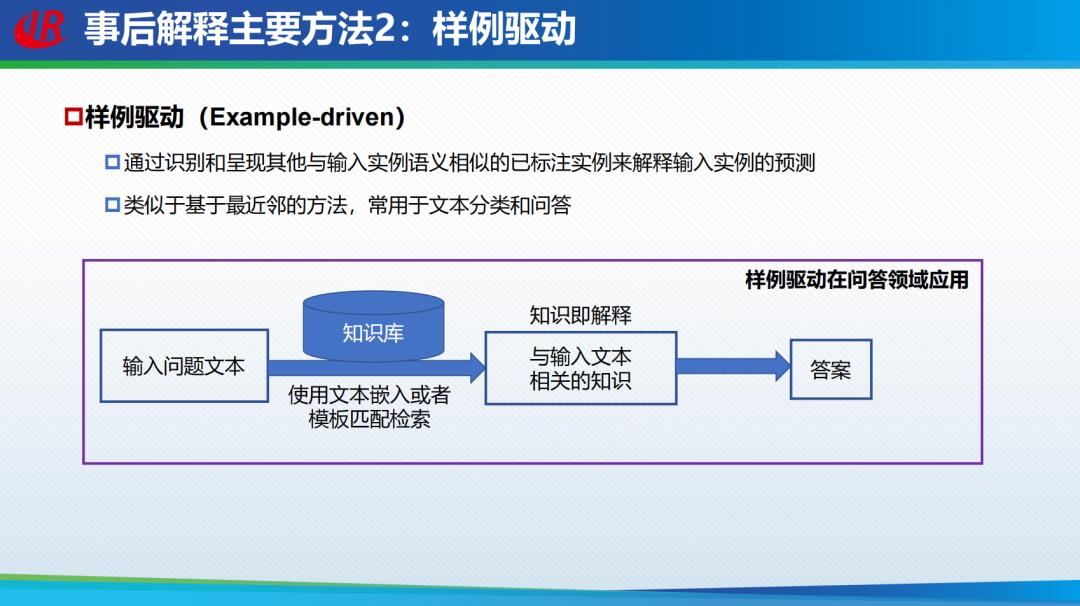
第二种方法叫做「样例驱动」,通过识别和呈现其它与输入实例语义相似的已标注好原因或者解释的文本的实例解释对输入实例的预测,样例驱动常用于问答系统,类似于基于最近邻的方法。
第三种方法为注意力机制,例如机器翻译系统,通过注意力机制发现高亮的不同,亮度的区别确实于与注意力的强弱相对应,解释单词的翻译依据。但目前可解释性与注意力的对应关系尚无定论。

第四种方法为探针方法,指使用模型的编码表征来训练一个分类器,该分类器用于探索编码表征中是否掌握某些语言学知识,如词性信息、句法信息、语义信息等。若分类器在探针任务上表现良好,则可认为机器掌握了相关的语言学知识,可以有理有据地进行问答。
群体情绪原因发现
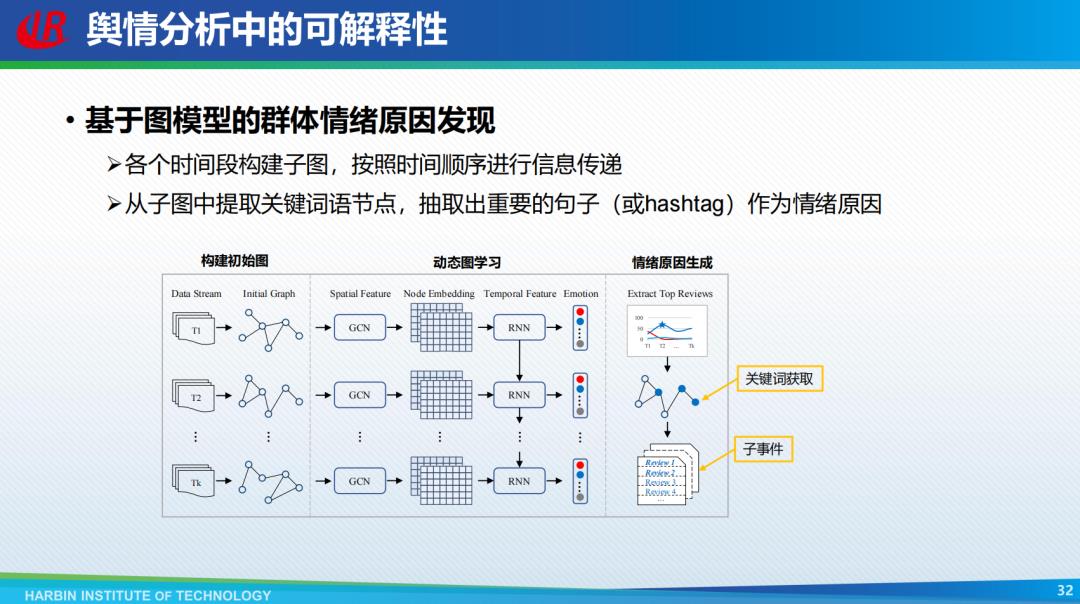
「群体情绪原因发现」是黑盒事后解释的典型案例。舆论分析中的群体情绪感知需要具备可解释性,对政府进行危机储值具有重要的意义。采用基于图模型的群体原因发现技术,从各个时间段构建子图,按照时间顺序进行信息传递,从子图中提取关键词语节点,抽取出重要的句子或者标签作为情绪原因。
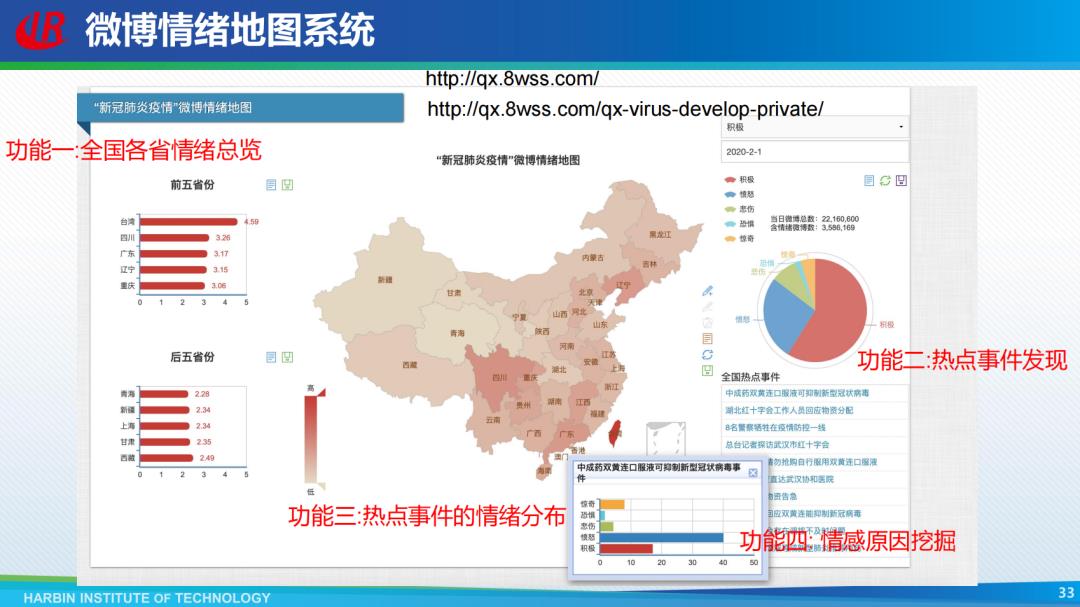
根据疫情期间每天获取的上千万条与疫情相关的微博,研究者们对微博上各地的情绪分布进行统计,绘制出了如下图所示的微博情绪地图。
基于注意力机制的解释
基于注意力机制为阅读理解任务提供可解释性也属于「事后解释方法」。这里面主要探讨注意力机制是否能够解释预训练模型的运行机制。研究者采用了一个包含四部分的注意力矩阵,Q2 代表问题到问题;P2 代表篇章理解;Q2P是从问题到篇章;寻找答案的线索;P2Q是对答案进行验证。研究者分别对这几个部分进行注意力机制的分析。
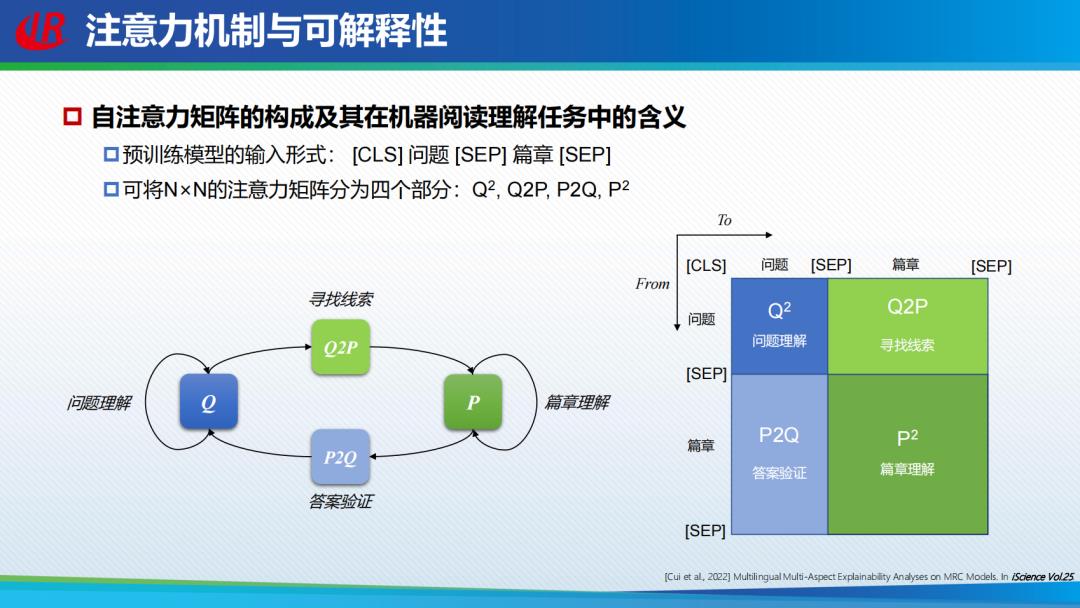
一般来说,高注意力对系统的影响比较大,比如说特殊的符号,对角线的元素。但在阅读理解问题上,研究者们发现去掉单个符号影响不大,去掉多个特殊的符号在英文上性能下降比较明显,然而中文上下降不是太明显,去掉对角的元素反而可以提升阅读理解的准确率。P2Q和P2P仍然是影响结果重要性的最主要的注意力区域。
探针方法
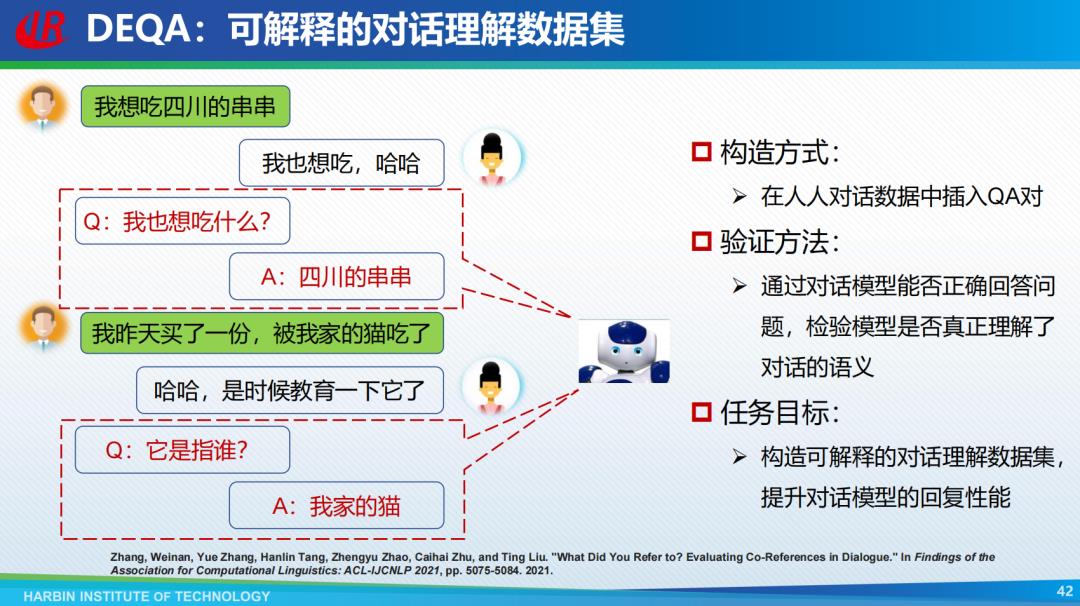
研究者们使用探针方法,实现对话理解中的可解释性认证。对话当中蕴含丰富的语言现象,传统对话系统无法理解对话中的省略和指代等现象,模型产生回复的过程不可解释。而刘挺教授团队在人人对话数据中插入QA对,通过对话模型能否正确地回答问题来检验模型是否真正理解对话的语义。并由此提出了一个DEQA数据集,通过可解释的QA方式验证了主流模型无法正确理解对话中语义的问题。
解释要素的注入
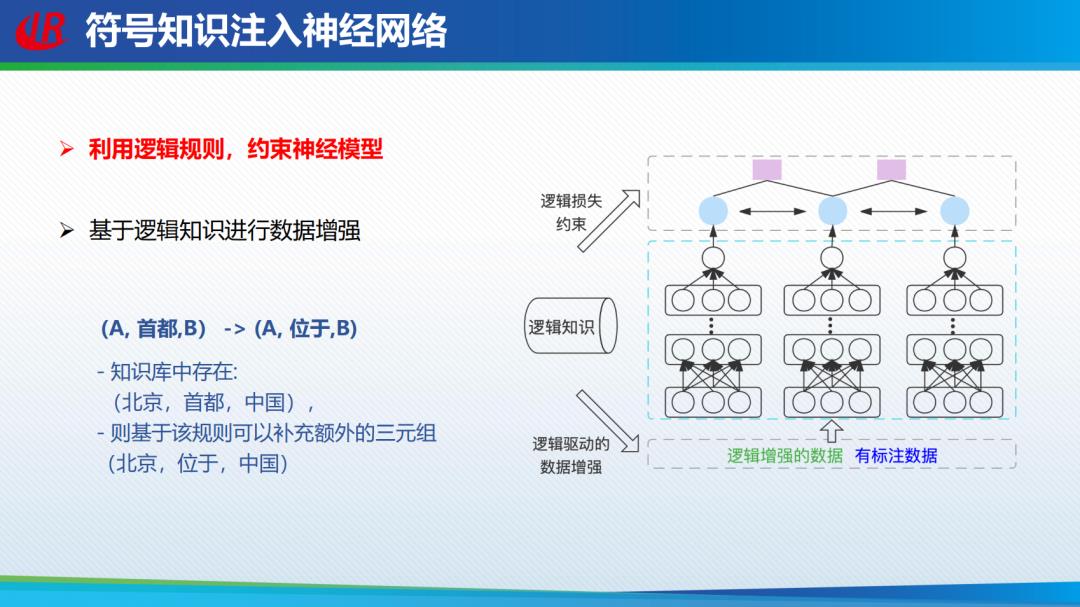
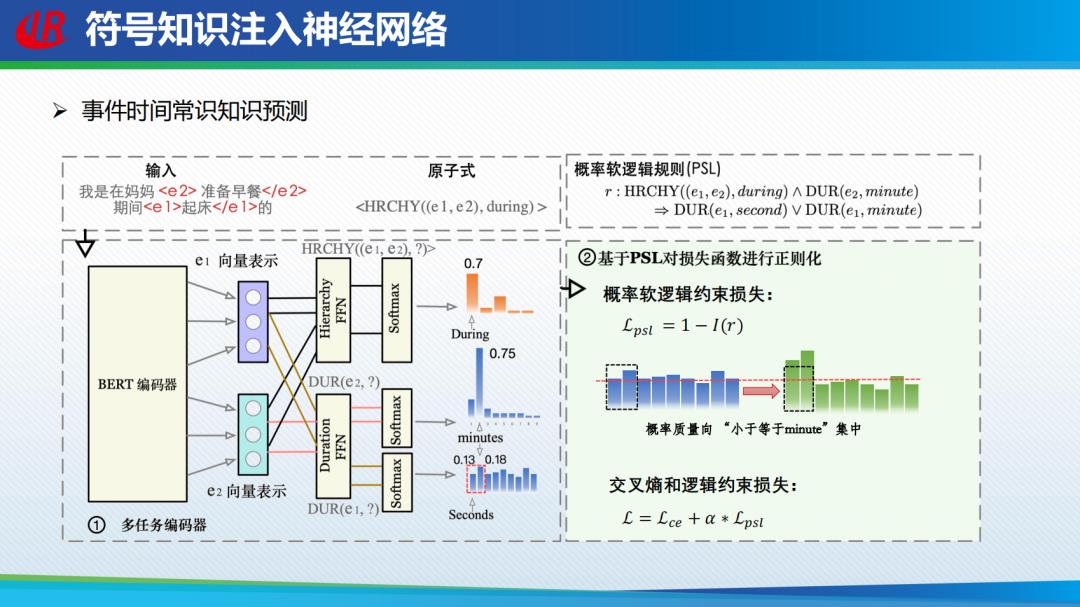
刘挺教授团队将符号知识注入神经网络,实现事件、时间、常识的知识预测。通过逻辑的推理可以扩大神经网络的训练集,同时利用逻辑规则在上层约束神经网络。从文本中无监督抽取的时间常识可能存在报告偏差,常见的情况在文本中并未显式提及,自然文本中几乎不会有类似的表达,预训练等大模型会在文本表达中对非寻常现象加以强调。刘挺教授介绍的方法通过利用不同维度间的时间常识知识之间的约束关系降低报告误差。
无监督文本生产解释
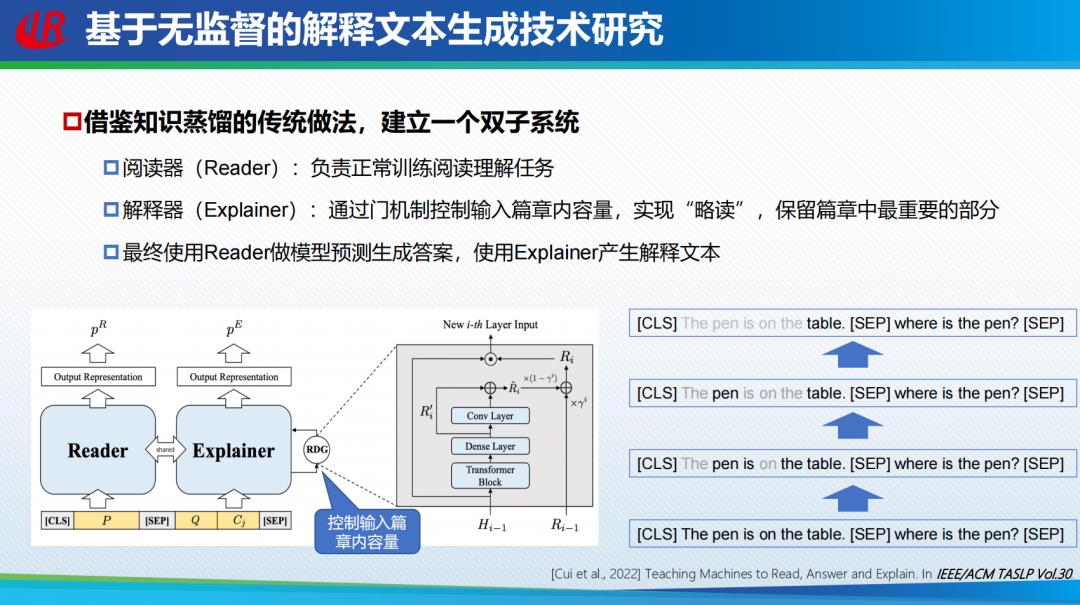
刘挺教授团队针对阅读理解构建自解释系统,提出了一个基于迭代式动态门限机制的无监督字解释方法。通过借鉴知识蒸馏的传统做法,建立一个双子系统。阅读器负责正常训练阅读理解任务,解释器通过门机制控制输入篇章的内容量保留篇章中最重要的部分,进而使用阅读器做模型预测生成答案,使用解释器产生解释文本。最终得到的实验结果相比传统方法获得了更高的答题准确率,因此不需要以答题准确率为代价换取可解释性,在人工评价指标上也取得了较好的效果。
可解释性的评价
针对可解释性评价的挑战,刘挺教授团队也提出了两个针对可解释性评价的数据集,分别是可解释性阅读理解数据集ExpMRC和可解释的因果推理数据集。
灰盒融合可解释要素方法
灰盒方法的主要思想是在构建系统的时候嵌入可解释的要素。刘挺教授首先介绍了基于神经-符号相结合的可解释性自然语言理解。符号表示有可程序化化可解释性强等优点,而神经AI表示能力和适应能力强,刘挺教授团队尝试将两者的优点结合在一起,构造了一个名为ExCAR的因果逻辑增强的可解释因果推理框架,例如从量化宽松到房价上涨找到推理路径,利用神经逻辑网络和条件马尔可夫还原背后的因果决策机制。

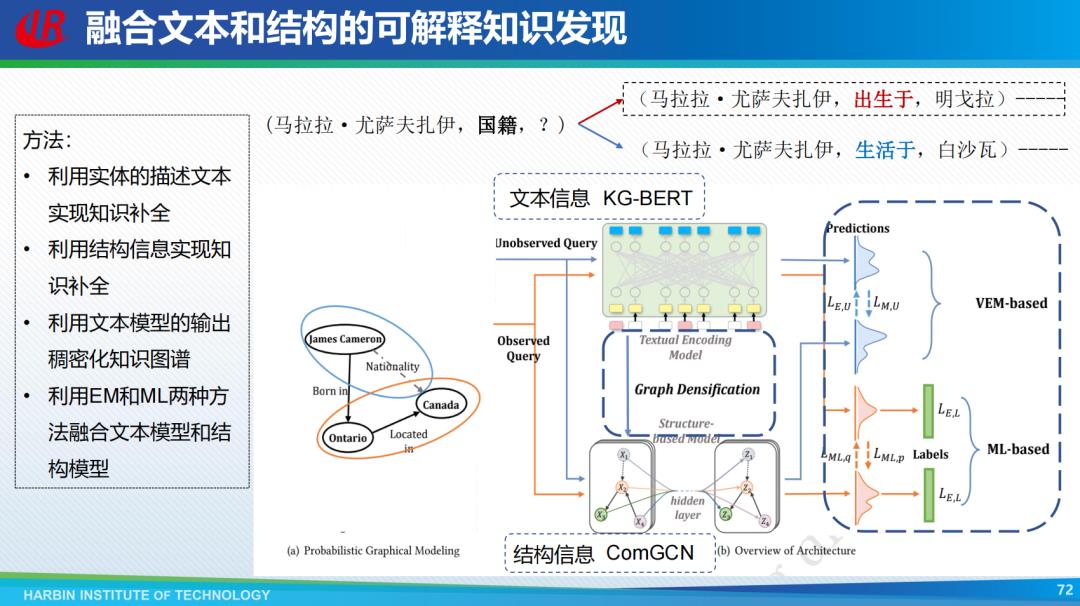
基于规则挖掘的知识发现,一般用表示学习、强化学习去进行知识的发现,利用实体的描述文本和结构信息实现知识不全;利用文本模型的输出稠密化知识图谱;利用EM和ML两种方法融合文本模型和结构模型,进而实现基于分层推理的知识发现。
总结和展望
刘挺教授本次报告向大家分享了白盒、黑盒以及灰盒等可解释性方法,也介绍一些评价的方法和数据集。刘挺教授认为,可解释人工智能未来的发展趋势是神经网络和符号系统相互结合、推理规则与预训练模型的相互结合以及可解释规则证据的归纳和可视化。另外,如何设计面向自然语言处理的白盒模型是一项很大的挑战。现在多数工作仍然集中于黑盒的事后解释以及如何利用可解释要素提出灰盒方法,难点在于多数NLP模型基于神经网络模型,而神经网络模型本身的可解释性仍然是未解难题。除此以外,可解释性的评价需要更加综合、全面地进行评估,结合脑科学的学科发展对可解释性进行进一步的探索也是未来重要的研究方向。

整理不易,点赞三连↓
以上是关于哈工大刘挺:自然语言处理中的可解释性问题!的主要内容,如果未能解决你的问题,请参考以下文章