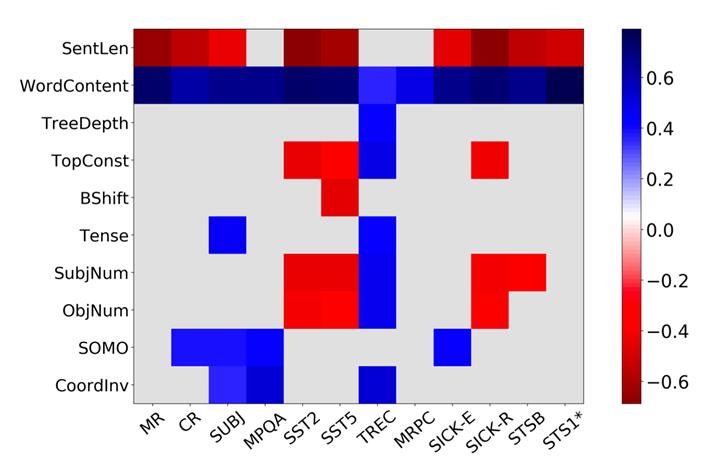
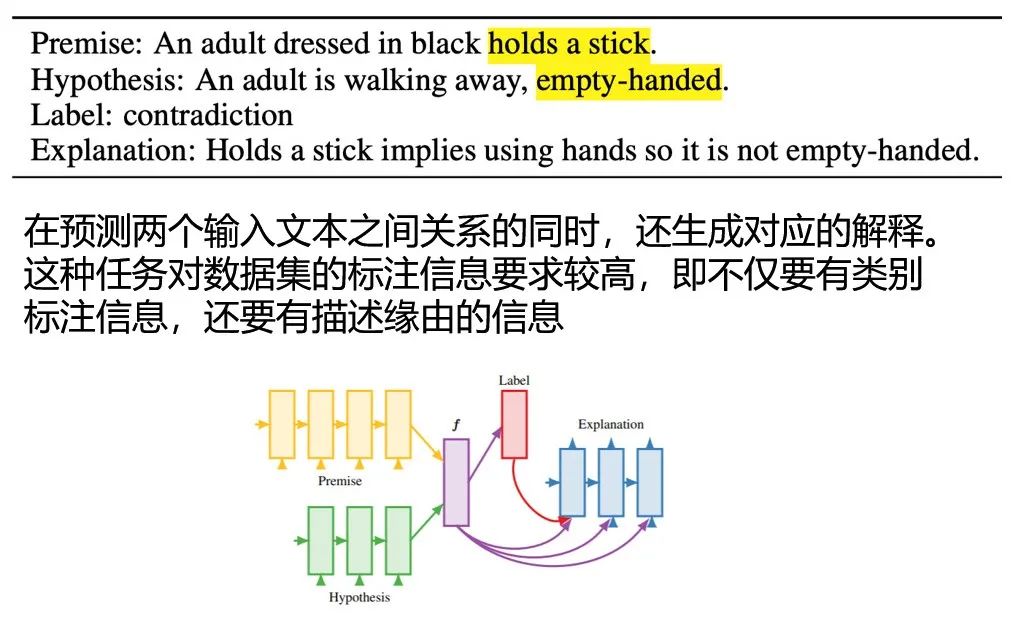
另外,Peters et al(2018) [3] 比较了在训练RNN、LSTM、Transformer等不同模型时的行为差异,确认了非监督双向语言模型的有效性,并通过分析得出底层网络的功能为捕捉短语信息,而高层能够发掘更复杂的语义信息。 Tang et al (2018) [4]重点比较了自注意力模型与CNN、RNN的不同的适用场景。分析得到,自注意力、RNN结构模型相较于CNN有更强的长程依赖捕捉能力,而自注意力优势则在于特征提取的能力。 2.2. 解释模型预测的行为 梯度方法 直观上,训练时的梯度大小反映了对应位置的参数或数据的重要程度,因此,通过分析输入数据梯度的大小,可以知晓不同模型预测过程中所关注的数据,从而理解输入特征对于结果预测的贡献。
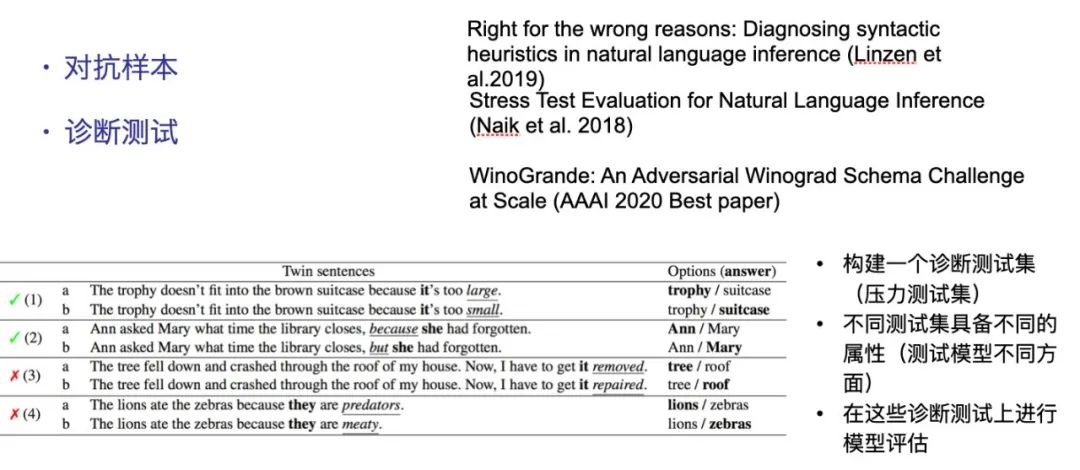
芝加哥大学的Mukund et al (2017) [5] 发现存在模型在得到正确解答的情况下,错误地依赖了无关的输入特征,表明深度网络存在一定归因错误的问题。 注意力方法
[1] Conneau, Alexis, et al. "What you can cram into a single vector: Probing sentence embeddings for linguistic properties." arXiv:1805.01070 (2018).
[2] Karpathy, Andrej, Justin Johnson, and Li Fei-Fei. "Visualizing and understanding recurrent networks." arXiv:1506.02078 (2015).[3] Peters, Matthew E., et al. "Dissecting contextual word embeddings: Architecture and representation." arXiv:1808.08949 (2018).[4] Tang, Gongbo, et al. "Why self-attention? a targeted evaluation of neural machine translation architectures." arXiv:1808.08946 (2018).[5] Mudrakarta, Pramod Kaushik, et al. "Did the model understand the question?." arXiv:1805.05492(2018).[6] Jain, Sarthak, and Byron C. Wallace. "Attention is not explanation." arXiv:1902.10186 (2019).[7] Wiegreffe, Sarah, and Yuval Pinter. "Attention is not not explanation." arXiv:1908.04626 (2019).[8] Camburu, Oana-Maria, et al. "e-snli: Natural language inference with natural language explanations." Advances in Neural Information Processing Systems. 2018.[9] Qian, Peng, Xipeng Qiu, and Xuanjing Huang. "Bridging lstm architecture and the neural dynamics during reading." arXiv:1604.06635 (2016).[10] Qian, Peng, Xipeng Qiu, and Xuan-Jing Huang. "Analyzing linguistic knowledge in sequential model of sentence." Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016.[11] Zhong, Ming, et al. "Searching for Effective Neural Extractive Summarization: What Works and What's Next." arXiv:1907.03491 (2019).[12] Zheng, Xiaoqing, et al. "Evaluating and enhancing the robustness of neural network-based dependency parsing models with adversarial examples." Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020.[13] Xing, Xiaoyu, et al. "Tasty Burgers, Soggy Fries: Probing Aspect Robustness in Aspect-Based Sentiment Analysis." arXiv:2009.07964 (2020).[14] Li, Linyang, et al. "Bert-attack: Adversarial attack against bert using bert." arXiv:2004.09984 (2020).[15] Fu, Jinlan, et al. "Rethinking Generalization of Neural Models: A Named Entity Recognition Case Study." AAAI. 2020.智源社区 发起了一个读者讨论欢迎针对文章提出问题 ~