Flink SQL --- 窗口聚合
Posted 宝哥大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink SQL --- 窗口聚合相关的知识,希望对你有一定的参考价值。
文章目录
base flink-1.13.6
一、Window TVF Aggregation
相当于普通分组函数加上窗口函数, 格式:
SELECT ...
FROM <windowed_table> -- relation applied windowing TVF
GROUP BY window_start, window_end, ...
与连续表上的其他聚合不同,窗口聚合不产生中间结果,而只产生最终结果,即窗口末尾的总聚合。此外,窗口聚合在不再需要时清除所有中间状态。
1.1、Windowing TVFs
创建 kafka 表
CREATE TABLE user_log (
user_id VARCHAR,
item_id VARCHAR,
category_id VARCHAR,
behavior VARCHAR,
`ts` TIMESTAMP(3),
proctime as PROCTIME(), -- 处理时间列
WATERMARK FOR ts as ts - INTERVAL '5' SECOND -- 在ts上定义watermark,ts成为事件时间列
) WITH (
'connector' = 'kafka', -- 使用 kafka connector
'topic' = 'user_behavior', -- kafka topic
'scan.startup.mode' = 'latest-offset', -- 从起始 offset 开始读取
'properties.bootstrap.servers' = 'chb1:9092',
'properties.group.id' = 'testGroup',
'format' = 'csv'
);
-- 数据源
1,1004,10004,buy,2022-10-29 10:40:26
5,1002,10003,pv,2022-10-29 10:40:27
2,1001,10001,buy,2022-10-29 10:40:27
6,1002,10004,pv,2022-10-29 10:40:27
窗口聚合案例
-- 滚动窗口聚合
SELECT window_start, window_end, count(1) as pv
FROM TABLE(
TUMBLE(TABLE user_log, DESCRIPTOR(ts), INTERVAL '10' SECONDS))
GROUP BY window_start, window_end;
-- 滑动窗口聚合
SELECT window_start, window_end, count(1) as pv
FROM TABLE(
HOP(TABLE user_log, DESCRIPTOR(ts), INTERVAL '2' SECONDS, INTERVAL '10' SECONDS))
GROUP BY window_start, window_end;
-- 累计窗口聚合
SELECT window_start, window_end, count(1) as pv
FROM TABLE(
CUMULATE(TABLE user_log, DESCRIPTOR(ts), INTERVAL '2' SECONDS, INTERVAL '10' SECONDS))
GROUP BY window_start, window_end;
1.2、GROUPING SETS
SELECT window_start, window_end, category_id, count(1) as pv
FROM TABLE(
TUMBLE(TABLE user_log, DESCRIPTOR(ts), INTERVAL '10' SECONDS))
GROUP BY window_start, window_end, GROUPING SETS(( category_id),());

其他 ROLLUP, CUBE 用法类似。
1.3、级联的窗口聚合
window_start和window_end列是常规的时间戳列,而不是时间属性。因此,它们不能在后续的基于时间的操作中用作时间属性。为了传播时间属性,需要将window_time列添加到GROUP BY子句中。window_time是窗口TVFs生成的第三列,它是指定窗口的时间属性。将window_time添加到GROUP BY子句中,使window_time也成为可以选择的组键。接下来的查询可以使用此列进行后续的基于时间的操作,例如级联窗口–Window TopN.
创建一个滚动窗口聚合
CREATE VIEW window1 AS
SELECT window_start AS `start`, window_end AS `end`, -- window_start和window_end列是常规的时间戳列,而不是时间属性,不能当作时间属性用于后续基于时间的操作
window_time AS rowtime,
category_id, count(1) as pv
FROM TABLE(
TUMBLE(TABLE user_log, DESCRIPTOR(ts), INTERVAL '5' SECONDS))
GROUP BY window_start, window_end, category_id,
window_time; -- 为了传播时间属性,需要将window_time列添加到GROUP BY子句中。
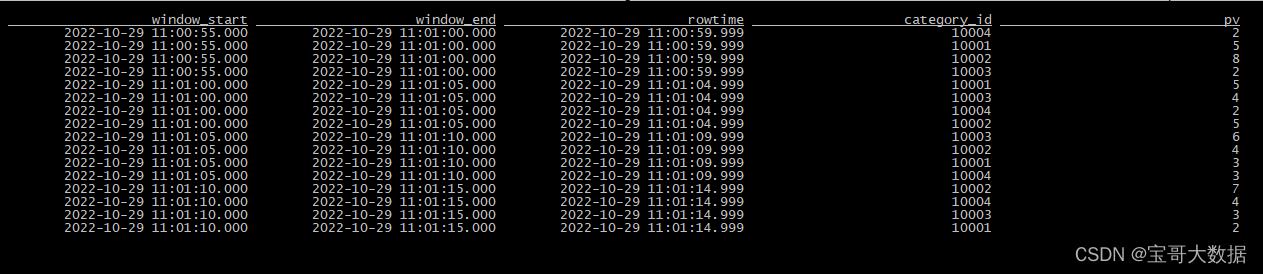
基于上一个窗口的聚合
SELECT window_start, window_end, SUM(pv) as total_pv
FROM TABLE(
TUMBLE(TABLE window1, DESCRIPTOR(rowtime), INTERVAL '10' SECONDS))
GROUP BY window_start, window_end;

二、Group Window Aggregation
Warning: Group Window Aggregation is deprecated. It’s encouraged to use Window TVF Aggregation which is more powerful and effective.
Compared to Group Window Aggregation, Window TVF Aggregation have many advantages, including:
- Have all performance optimizations mentioned in Performance Tuning.
- Support standard GROUPING SETS syntax.
- Can apply Window TopN after window aggregation result.
- and so on.
参考:
https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/sql/queries/window-agg
窗口函数
以上是关于Flink SQL --- 窗口聚合的主要内容,如果未能解决你的问题,请参考以下文章
Flink SQL 分组窗口函数 Group Window 实战
Flink的窗口聚合操作(TimeCount Window)