Flink DataStream API
Posted CDHong.it
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink DataStream API相关的知识,希望对你有一定的参考价值。
Flink 系列教程传送门
第四章 Flink 窗口和水位线
第五章 Flink Table API&SQL
第六章 新闻热搜实时分析系统
一、DataStream API是什么?
Flink 中的 DataStream 程序是对数据流(例如过滤、更新状态、定义窗口、聚合)进行转换的常规程序。数据流的起始是从各种源(例如消息队列、套接字流、文件)创建的。结果通过 sink 返回,例如可以将数据写入文件或标准输出(例如命令行终端)。Flink 程序可以在各种上下文中运行,可以独立运行,也可以嵌入到其它程序中。任务执行可以运行在本地 JVM 中,也可以运行在多台机器的集群上。
DataStream API 得名于特殊的 DataStream 类,该类用于表示 Flink 程序中的数据集合。可以简单理解为包含重复项的不可变数据集合。这些数据可以是有界的,也可以是无界的,但用于处理它们的API是相同的。
DataStream 在用法上类似于常规的 Java 集合,但在某些关键方面却大不相同。它们是不可变的,这意味着一旦它们被创建,你就不能添加或删除元素。你也不能简单地察看内部元素,而只能使用 DataStream API 操作来处理它们,DataStream API 操作也叫作转换(transformation)。
通过在 Flink 程序中添加 source 创建一个初始的 DataStream。然后基于 DataStream 派生新的流,并使用 map、filter 等 API 方法把 DataStream 和派生的流连接在一起。

二、Source 数据源
Source 是程序从中读取其输入的地方。可以用 StreamExecutionEnvironment.addSource(sourceFunction) 将一个 source 关联到程序。Flink 也自带了许多预先实现的 source functions,也可以通过实现 SourceFunction 接口编写自定义的非并行 source,也可以通过实现 ParallelSourceFunction 接口编写自定义的并行 sources。
基于文件的Source
readTextFile(path)- 读取文本文件,遵守 TextInputFormat 规范的文件,逐行读取并将它们作为字符串返回。readFile(fileInputFormat, path)- 按照指定的文件输入格式读取(一次)文件。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val data: DataStream[String] = senv.readTextFile("file:///path/to/file") // env.readTextFile("hdfs://node01:9000/input/words.txt")
data.print()
env.execute("测试Source")基于套接字的Source
socketTextStream(hostname: String, port: Int, delimiter: Char = '\\n', maxRetry: Long = 0)- 从套接字读取。元素可以由分隔符分隔。Netcat官网下载地址
// 在Linux系统中是通过 nc -lk 端口号
// 在Window系统中是通过 nc -l -p 端口号
val data: DataStream[String] = senv.socketTextStream("localhost", 9999)基于集合的Source
fromCollection(Collection)- 从Seq[T]或者Iterator[T]中创建数据流。集合中的所有元素必须属于同一类型。fromCollection(Iterator, Class)- 从迭代器创建数据流。class 参数指定迭代器返回元素的数据类型。fromElements(T ...)- 从给定的对象序列中创建数据流。所有的对象必须属于同一类型。
val data: DataStream[Any] = env.fromElements(1, 100, "hello", 'a')
val data:DataStream[String]=senv.fromCollection(List("hello","flink","scala"))自定义的Source
addSource/fromSource- 实现一个新的SourceFunction、RichSourceFunction、ParallelsourceFunctioninterface实现类- 实现
SourcePunction:是非并行的,不能指定并行度,即不能用setParallelism(num)算子,socketTextStreamFunction就是实现的SourceFunction - 实现
ParallelSourceFunction:是并行化的Source所以能指定并行 - 实现
RichSourceFunction:实现了SourceFunction,还继承了AbstractRichFunction,所以比SourceFunction增加了open、close方法和getRuntimeContext()上下文对象
- 实现
自定义随机Source
自定义数据源需要实现SourceFunction或者其对应的子接口,主要重写两个关键方法:
run():使用运行时上下文对象SourceContext向下游发送数据,用于编写产生数据的核心业务逻辑cancel():方法是取消数据读取时调用,用于和run方法配置使用,判断用户使用取消数据读取
object MyRandomEventSource
// 模拟用户点击的行为
// ID、Name、URL、ClickTime
case class UserClick(name: String, url: String, clickTime: Long)
// 在这里模拟生成用户的点击行为数据
class MyRandomEventSource extends RichSourceFunction[UserClick]
private val names = Array("张三丰", "张无忌", "赵敏", "貂蝉", "刘皇叔")
private val urls = Array("/index", "/about", "/pro_detail", "/pro?id=1", "/pro?id=2")
private var running: Boolean = true // 程序的运行状态
// 程序执行的时候会调用
override def run(ctx: SourceFunction.SourceContext[UserClick]): Unit =
while (running)
val randName = names(Random.nextInt(names.length))
val randUrl = urls(Random.nextInt(urls.length))
// 收集产生的数据发送到调用
ctx.collect(UserClick(randName, randUrl, System.currentTimeMillis()))
// 每隔1-5秒钟随机产生一条数据
// [0,5) + 1 [1,6)
Thread.sleep((Random.nextInt(5) + 1) * 1000)
// 用户手动关闭程序会调用
override def cancel(): Unit = running = false
自定义mysql Source
富函数类(Rich Function),是 DataStream API 提供的一个函数类的接口,所有 Flink 函数类都有其 Rich 版本。它与常规函数的不同在于,可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
open()方法是 rich function 的初始化方法,当一个算子例如 map 或者 filter被调用之前 open()会被调用。run()方法是读取数据时调用,编写核心处理业务逻辑。cancel()方法是取消数据读取时调用,用于和run方法配置使用,判断用户使用取消数据读取。close()方法是生命周期中的最后一个调用的方法,做一些清理工作。getRuntimeContext()方法提供了函数的 RuntimeContext 的一些信息,例如函数执行的并行度,任务的名字,以及 state 状态。
自定义MySQL 数据源,读取MySQL中的表数据
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>初始化MySQL数据表
drop table tbl_student;
create table tbl_student(id int primary key auto_increment, name varchar(16), age int(3)) default charset = 'utf8';
insert into tbl_student(name,age) values('张三',18),('李四',28),('王五',22),('赵六',26),('田七',19);
select * from tbl_student;自定义非并行MySQL Source
// 定义实体样例类 Student 对接数据库表
object Entity
case class Student(id: Int, name: String, age: Int)
// 这里使用非并行Source
class MySQLSource extends RichSourceFunction[Student]
var conn: Connection = _ // 数据库连接对象,用于接收open方法中的初始化对象
var ps: PreparedStatement = _
var rs: ResultSet = _
var isRunning = true // 是否持续从数据源中读取数据的标识
// 初始化方法, 用于初始化MySQL数据库连接
override def open(parameters: Configuration): Unit =
// 加载驱动
Class.forName("com.mysql.jdbc.Driver")
// 获取连接
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test_db?useSSL=false", "root", "root")
// 读取数据时调用,用于读取MySQL中的数据
override def run(sourceContext: SourceFunction.SourceContext[Student]): Unit =
// 预处理SQL
ps = conn.prepareStatement("select id, name, age from tbl_student")
// 执行SQL获取结果
rs = ps.executeQuery()
// 循环读取集合中数据
while (isRunning && rs.next())
val student = Student(rs.getInt("id"), rs.getString("name"), rs.getInt("age"))
// 把读取到的数据发送出去
sourceContext.collect(student)
// 取消数据读取时调用
override def cancel(): Unit = isRunning = false
object TestMySQLSource
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
val data = env.addSource(new MySQLSource())
data.print()
env.execute("MySQL Source")
Kafka Source
Kafka Source 提供了构建类来创建 KafkaSource 的实例。FlinkKafkaConsumer 已被弃用并将在 Flink 1.17 中移除,请改用 KafkaSource。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.14.5</version>
</dependency>Kafka Source 案例演示
object TestSource
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 构建Kafka Source
val kafkaSource: KafkaSource[String] = KafkaSource.builder().setBootstrapServers("localhost:9092")
.setTopics("test")
.setGroupId("my-group")
// timestamp(1657256176000L)(从时间戳大于等于指定时间戳(毫秒)的数据开始消费) latest(从最末尾位点开始消费)
.setStartingOffsets(OffsetsInitializer.earliest()) // 默认值 earliest() 从最早位点开始消费
.setValueOnlyDeserializer(new SimpleStringSchema())
.build()
// 关联Source
// val props = new Properties()
// props.setProperty("bootstrap.servers", "localhost:9092")
// props.setProperty("group.id", "consumer-group")
// env.addSource(new FlinkKafkaConsumer[String]("test", new SimpleStringSchema(), props))
// WatermarkStrategy.noWatermarks() 水印策略,不使用水印
val data = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "Kafka Source")
data.print()
env.execute("Flink Kafka Source")

三、Transformation 算子
Transformation(转换)算子就是将一个或多个 DataStream 转换成新的 DataStream,在应用程序中可以将多个数据转换算子合并成一个复杂的数据流(Dataflow)拓扑。
常用算子
Map算子(DataStream → DataStream):map算子接收一个函数作为参数,并把这个函数应用于DataStream的每个元素,最后将函数的返回结果作为结果DataStream中对应元素的值,即将DataStream的每个元素转换成新的元素。
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
val source = env.fromCollection(List(1, 2, 3, 4))
source.map(x => x * 2).print("lambda")
source.map(new MyMap).print("function")
source.map(new MapFunction[Int, Int]
override def map(t: Int): Int = t * 10
).print("function2")
env.execute()
class MyMap extends MapFunction[Int, Int]
override def map(t: Int): Int = t * 10
FlatMap算子(DataStream → DataStream):与map()算子类似,但是每个传入该函数func的DataStream元素会返回0到多个元素,最终会将返回的所有元素合并到一个DataStream
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val source = env.fromCollection(List(1, 2, 3, 4, 5))
source.flatMap(item => List(item,item)).print("lambda1")
val source1 = env.fromElements("flink spark link", "flink spark link", "flink spark link")
source1.flatMap(item => item.split(" ")).print("lambda2")
source1.flatMap(new FlatMapFunction[String, String]
override def flatMap(value: String, out: Collector[String]): Unit =
for (item <- value.split(" "))
out.collect(item)
).print("function")
env.execute()KeyBy算子(DataStream → KeyedStream):KeyedStream实际上是一种特殊的DataStream,因为其继承了DataStream。KeyedStream用来表示根据指定的key进行分组的数据流。
keyBy算子主要作用于元素类型是元组或数组的DataStream上。使用该算子可以将DataStream中的元素按照指定的key(字段)进行分组,具有相同key的元素将进入同一个分区中(不进行聚合),并且不改变原来元素的数据结构。在逻辑上将流划分为不相交的分区,在内部是通过哈希分区实现的。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val source = env.fromElements((1, 2), (1, 6), (1, 9), (1, 7), (2, 1), (2, 2), (2, 10), (3, 1))
source.keyBy(item => item._1).print("lambda")
// source.keyBy(new KeySelector[Tuple2[Int, Int], Int]
source.keyBy(new KeySelector[(Int, Int), Int]
override def getKey(value: (Int, Int)): Int = value._1
).print("function")
source.keyBy(item => "default") // 所有的数据分为一组(default),求最大的那个元素
.maxBy(1)
.print()
env.execute()Aggregation算子(KeyedStream → DataStream) :常用的聚合算子有sum()、max()、min()、max_by()、min_by()等,这些聚合算子统称为Aggregation。Aggregation算子作用于KeyedStream上,并且进行滚动聚合。与keyBy算子类似,可以使用数字或字段名称指定需要聚合的字段。
max_by()和min_by()与min()和max()的区别在于,后者的只计算指定字段的值,其他字段会保留最初第一个数据的值,而前者会返回包含计算字段的整条数据。
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val source = env.fromElements((1, 2), (1, 6), (1, 9), (1, 7), (2, 1), (2, 2), (2, 10), (3, 1))
source.keyBy(item => item._1)
// .sum(1) // 按索引位置
.sum("_2") // 按字段名
.print()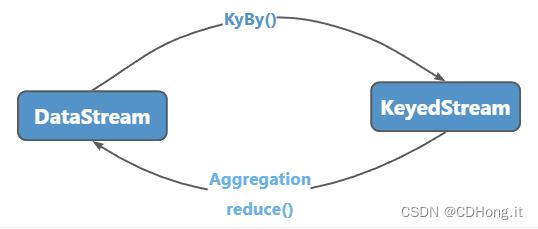
keyBy算子会将DataStream转换为KeyedStream,而Aggregation算子会将KeyedStream转换为DataStream。
Reduce算子(KeyedStream → DataStream):从MapReduce开始,我们对reduce()操作就不陌生,它可以对已有的数据进行规约处理,把每一个新输入的数据和当前已经规约的数据进行聚合计算。
reduce算子主要作用于KeyedStream上,对KeyedStream数据流进行滚动聚合,即将当前元素与上一个聚合值进行合并,并且发射出新值。
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val source = env.fromElements((1, 2), (1, 6), (1, 9), (1, 7), (2, 1), (2, 2), (2, 10), (3, 1))
source.keyBy(item => item._1)
// 聚合规则:将每一组中元组的第二个字段进行累加,第一个字段保持不变。注意聚合后数据类型与聚合前保持一致(Int, Int)
.reduce((state, data) => (state._1, state._2 + data._2))
.print()
source.keyBy(item => "default") // 一个组中求最大的元素
.reduce((state,data) => if (state._2 > data._2) state else data)
.print()
env.execute()[案例] 读取CSV文件分组统计学生信息
使用流处理API读取指定数据文件students.csv,加载数据转换为样例对象Student,根据对象中的clazz班级字段进行分组,获取每个班级中年龄最小的学生信息。📎student.csv
object TestTransform
case class Student(id: Int, name: String, age: Int, clazzNo: Int)
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
val source = env.readTextFile("D:\\\\WorkSpace\\\\IDEA\\\\flink_demo\\\\src\\\\main\\\\resources\\\\student.csv", "utf-8")
source
.map(line => val arr = line.split(","); Student(arr(0).toInt, arr(1), arr(2).toInt, arr(3).toInt) )
.keyBy(_.clazzNo)
.min("age") // .min(2)
.print()
env.execute()
四、Sink 输出
Flink使用Data Sinks 将DataStream 转发到文件、套接字、外部系统或打印它们。Flink 自带了多种内置的输出格式,这些格式相关的实现封装在 DataStreams 的算子里:
print() / printToErr()- 在标准输出/标准错误流上打印每个元素的 toString() 值。 可选地,可以提供一个前缀(msg)附加到输出。这有助于区分不同的 print 调用。如果并行度大于1,输出结果将附带输出任务标识符的前缀。writeToSocket- 根据 SerializationSchema 将元素写入套接字。addSink/sinkTo- 调用自定义 Sink Function。Flink 捆绑了连接到其他系统(例如 JDBC、Apache Kafka)的连接器。
注意,DataStream 的 write*() 方法主要用于调试目的。它们不参与 Flink 的 checkpointing,这意味着这些函数通常具有至少有一次语义。刷新到目标系统的数据取决于 OutputFormat 的实现。这意味着并非所有发送到 OutputFormat 的元素都会立即显示在目标系统中。此外,在失败的情况下,这些记录可能会丢失。
为了将流可靠地、精准一次地传输到文件系统中,请使用 StreamingFileSink构建。此外,通过 .addSink(...) 方法调用的自定义实现也可以参与 Flink 的 checkpointing,以实现精准一次的语义。
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.fromElements("a", "b", "c", "d", "e")
.map(_.concat("-hello\\n"))
.writeToSocket("localhost", 6666, new SimpleStringSchema())
env.execute()输出到文件
FileSink为批处理和流处理提供了一个统一的Sink,它可以将分区文件写入Flink支持的文件系统且保证精确一次的状态一致性,大大改进了之前流式文件输出的方式。
它的主要操作是将数据写入桶(buckets),每个桶中的数据都可以分割成一个个大小有限的分区文件,这样一来就实现真正意义上的分布式文件存储。
FileSink支持行编码(Row-encoded)和批量编码(Bulk-encoded,比如Parquet)格式。这两种不同的方式都有各自的构建器(builder),可以使用以下静态方法创建:
- 行编码接收器:
FileSink.forRowFormat(basePath, rowEncoder) - 批量编码接收器:
FileSink.forBulkFormat(basePath, bulkWriterFactory)
在创建行或批量编码Sink时,我们需要传入两个参数,用来指定存储桶的基本路径(basePath)和数据的编码逻辑(rowEncoder 或bulkWriterFactory)。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>$flink.version</version>
</dependency>case class Student(id: Int, name: String, age: Int, clazzNo: Int)
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val source = env.readTextFile("input/student.csv")
val result = source
.map(line => val arr = line.split(","); Student(arr(0).toInt, arr(1), arr(2).toInt, arr(3).toInt) )
.keyBy(_.clazzNo)
.minBy("age") // .min(2)
// 文件系统
val fileSink: FileSink[String] = FileSink
.forRowFormat(new Path("output/sink"), new SimpleStringEncoder[String]())
.withRollingPolicy( // 文件滚动策略,用于在以下 3 个条件中的任何一个下滚动进行中的部件文件
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(15)) // 至少包含15分钟的数据
.withInactivityInterval(Duration.ofMinutes(5)) // 最近5分钟没有收到数据
.withMaxPartSize(MemorySize.ofMebiBytes(1024)) // 文件大小已达到 1 MB(写入最后一条记录后)
.build())
.build()
// 结果转为字符串写到文件中
result.map(item=>item.toString).sinkTo(fileSink)
env.execute()
批量编码接收器的创建方式与行编码接收器类似,但是需要指定的是BulkWriter.Factory。 逻辑定义如何添加和刷新新元素,以及如何添加一批记录以便进一步编码。Flin内置了四个BulkWriterFactory:
- ParquetWriterFactory:用于为 Avro 数据创建 Parquet 编写器工厂。若要在应用程序中使用 Parquet 批量编码器,需要添加
flink-parquet_2.12依赖。 - AvroWriterFactory:将数据写入 Avro 文件,若要在应用程序中使用 Avro 编写器,需要添加
flink-avro依赖。 - SequenceFileWriterFactory:在应用程序中使用SequenceFile批量编码器,需要添加
flink-sequence-file依赖。 - OrcBulkWriterFactory:将数据能够以ORC格式进行批量编码,需要添加
flink-orc_2.12依赖。
输出到Kafka
KafkaSink 可将数据流写入一个或多个 Kafka topic。
在构建 KafkaSink 时是必须指定的:
- Bootstrap servers, setBootstrapServers(String)
- 消息序列化器(Serializer), setRecordSerializer(KafkaRecordSerializationSchema)
- 如果使用DeliveryGuarantee.EXACTLY_ONCE 的语义保证,则需要使用 setTransactionalIdPrefix(String)
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.14.5</version>
</dependency>case class Student(id: Int, name: String, age: Int, clazzNo: Int)
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val source = env.readTextFile("E:\\\\WorkSpace\\\\IDEA\\\\demo\\\\src\\\\main\\\\resources\\\\student.csv")
val result = source
.map(line => val arr = line.split(","); Student(arr(0).toInt, arr(1), arr(2).toInt, arr(3).toInt) )
.keyBy(_.clazzNo)
.minBy("age") // .min(2)
// 定义KafkaSink
val kafkaSink = KafkaSink.builder()
.setBootstrapServers("192.168.157.130:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("test-topic")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE) // 语义保证
.build()
// 写出数据到Kafka中
result.map(item=>item.toString).sinkTo(kafkaSink)
env.execute()

输出到Redis
Redis是一个开源的内存式的数据存储,提供了像字符串(string)、哈希表(hash)、列表(list)、集合(set)、排序集合(sorted set)、位图(bitmap)、地理索引和流(stream)等一系列常用的数据结构。因为它运行速度快、支持的数据类型丰富,在实际项目中已经成为了架构优化必不可少的一员,一般用作数据库、缓存,也可以作为消息代理。
Flink没有直接提供官方的Redis连接器,不过Bahir 项目还是担任了合格的辅助角色,为我们提供了Flink-Redis 的连接工具。但版本升级略显滞后,目前连接器版本为 1.l,支持的Scala版本最新到2.11。由于我们的测试不涉及到Scala的相关版本变化,所以并不影响使用。在实际项目应用中,应该以匹配的组件版本运行。
百度网盘下载地址:Redis-x64-3.2.100.zip 密码:6666 AnotherRedisDesktopManager
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.12</artifactId>
<version>1.1.0</version>
</dependency>case class Student(id: Int, name: String, age: Int, clazzNo: Int)
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val source = env.readTextFile("E:\\\\WorkSpace\\\\IDEA\\\\demo\\\\src\\\\main\\\\resources\\\\student.csv")
val result = source
.map(line => val arr = line.split(","); Student(arr(0).toInt, arr(1), arr(2).toInt, arr(3).toInt))
.keyBy(_.clazzNo)
.minBy("age") // .min(2)
// Redis Sink
val conf = new FlinkJedisPoolConfig.Builder().setHost("192.168.157.130").build()
result.addSink(new RedisSink[Student](conf, new MyRedisMapper))
env.execute()
class MyRedisMapper extends RedisMapper[Student]
override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.HSET,"stu")
override def getKeyFromData(t: Student): String = t.id.toString
override def getValueFromData(t: Student): String = t.age.toString
输出到MySQL
Flink 提供了 JDBC Connector。该连接器可以向 JDBC 数据库写入数据。添加下面的依赖以便使用该连接器(同时添加 JDBC 驱动)。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.12</artifactId>
<version>1.14.5</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
create table student(id int,name varchar(25),age int(3),clazz int(2))default charset=utf8;
case class Student(id: Int, name: String, age: Int, clazzNo: Int)
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val source = env.readTextFile("E:\\\\WorkSpace\\\\IDEA\\\\demo\\\\src\\\\main\\\\resources\\\\student.csv")
val result = source
.map(line => val arr = line.split(","); Student(arr(0).toInt, arr(1), arr(2).toInt, arr(3).toInt) )
.keyBy(_.clazzNo)
.minBy("age") // .min(2)
// 创建JDBC Sink
val jdbcSink = JdbcSink.sink[Student](
"insert into tbl_student(id,name,age,clazz_no) values(?,?,?,?)",
// (ps: PreparedStatement, t: Student) =>
// 这里不能使用箭头函数,否则会报:The implementation of the RichOutputFormat is not serializable. The object probably contains or references non serializable fields.
new JdbcStatementBuilder[Student]
override def accept(ps: PreparedStatement, t: Student): Unit =
ps.setInt(1, t.id)
ps.setString(2, t.name)
ps.setInt(3, t.age)
ps.setInt(4, t.clazzNo)
,
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/test_db?useSSL=false")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("root")
.build()
)
// 数据写入到JDBC Sink中
result.addSink(jdbcSink)
env.execute()
在Scala中,输入插入ps不能使用箭头lambda的方式设置占位数据,需要通过原始的匿名接口类实现
JdbcStatementBuilder与Hadoop依赖冲突,导致jar缺少,需要手动加入缺少jar
commons-compress
[案例] Flink整合Kafka计算实时单词数量
Flink集成了通用的Kafka连接器,用于消费Kafka中的数据或向Kafka中写入数据。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.14.5</version>
</dependency>案例代码
object StreamKafkaWordCount
def main(args: Array[String]): Unit =
// 创建流处理执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从kafka中读取数据
val kafkaSource = KafkaSource.builder()
.setBootstrapServers("localhost:9092")
.setTopics("test01")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest()) // 默认值 earliest() 从最早位点开始消费
.setValueOnlyDeserializer(new SimpleStringSchema())
.build()
// 添加数据源,不指定水印策略
val dataStream = env.fromSource(kafkaSource,WatermarkStrategy.noWatermarks(), "Kafka Source")
// 转换Kafka流数据
val result = dataStream.flatMap(line => line.split(" "))
.filter(word=>word.nonEmpty)
.map(word=> (word,1))
.keyBy(item=>item._1)
.sum(1)
// 数据结果到控制台
result.print()
// 触发任务执行
env.execute("StreamKafkaWordCount")
启动服务-数据测试
root@LenovoX:~ $ zookeeper-server-start.sh -daemon $KAFKA_HOME/config/zookeeper.properties
root@LenovoX:~ $ kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
root@LenovoX:~ $ kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test01 1
Created topic test01.
root@LenovoX:~ $ kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test01
>flink flink spark java hive
>flink spark java hive以上是关于Flink DataStream API的主要内容,如果未能解决你的问题,请参考以下文章