猿创征文|[Zookeeper]快速上手Zookeeper.Zookeeper的初识别,安装,znode节点的理解,常用命令,Wacher机制,ACL权限控制及上述功能在idea的代码实现
Posted 天海奈奈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了猿创征文|[Zookeeper]快速上手Zookeeper.Zookeeper的初识别,安装,znode节点的理解,常用命令,Wacher机制,ACL权限控制及上述功能在idea的代码实现相关的知识,希望对你有一定的参考价值。
目录
Access Control List权限控制列表粒度细: 5种权限.
CREATE :可以创建一个子节点READ :可以从节点获取数据并列出其子节点WRITE :可以为节点设置数据
一,初识别zookeeper
1 Zookeeper的诞生
目的:
解决单点时的问题,创建无单点问题的分布式协调框架,精力集中在处理业务逻辑。
背景:
名称就是Zookeeper动物园管理员,由于当时雅虎很多项目都以动物来命名,可以说是相当贴切了。作用就是协调大家让大家步伐一致。诞生了Zookeeper用来做分布式协调。
2 为什么需要Zookeeper
1 单点系统是不可靠的,外界不可控因素过多,发生故障我们不容易提供稳定服务。
2 Zookeeper具有高可用性且对外提供数据一致。
3 什么是Zookeeper
官网 : Apache ZooKeeper
Zookeeper提供分布式应用程序的分布式协调服务。服务的对象是分布式的应用城西,自身也是分布式的,它的主要作用是协调服务。简单理解为可靠的对外提供一致服务的数据库
不会因为某一个节点的宕机而不可用。
4 Zookeeper的特点和作用
1,同一个客户端发送请求生效是有顺序的。
2,对Zookeeper集群操作时保证在所有集群中的操作是一致的,不会出现有的成功有的不成功。
3,不管连接到那个Zookeeper服务器,提供的数据都是一致的。
4,一旦生效能保证任务会一直保留。
5,同步速度块
5 架构图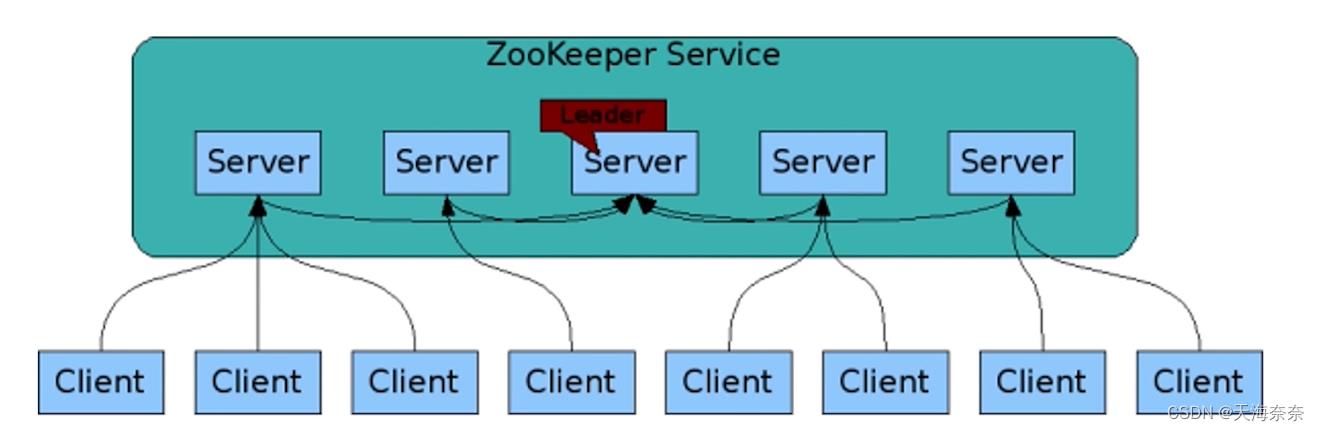
服务连接到leader,协调不同的server进行工作,五个server下面的client链接的时候也把压力进行了分散,不同的客户端链接的是不同的服务器,一个服务器对外提供的能力是有限的,不同于点服务器的模式,他提高了服务器的能力并保证数据是一致的。
Leader server会把写相关的请求处理掉,同步到其他上面去。
6 应用场景
分布式锁 :
与单机锁的差别不大,只是部署在分布式上面的,应用的是他节点的唯一性。
配置中心:
应用到舰监听的能力也就是Wacher
服务的注册与发现 :
dubbo就能用Zookeeper来保存与服务变化相关的信息
分布式唯一ID
二 安装与配置
Linux 环境下
先登录到虚拟机,这里用的是Xshell 直接虚拟机里终端操作也差不多
1 找到下载地址Index of /zookeeper
这里以3.6.3为例,点击进去
2 开始下载
我们下载第一个最大的,右键复制链接回到命令台
输入:wget 把复制的链接右键粘贴上去 回车

等待下载完成,虽说不快但也能接受,三分钟刚好看看下面该怎么做

解压:
下载完成后进行解压缩 输入 tar zxvf 把上面提供的 apache-zookeeper-3.6.3-bin.tar.gz复制下来,回车。
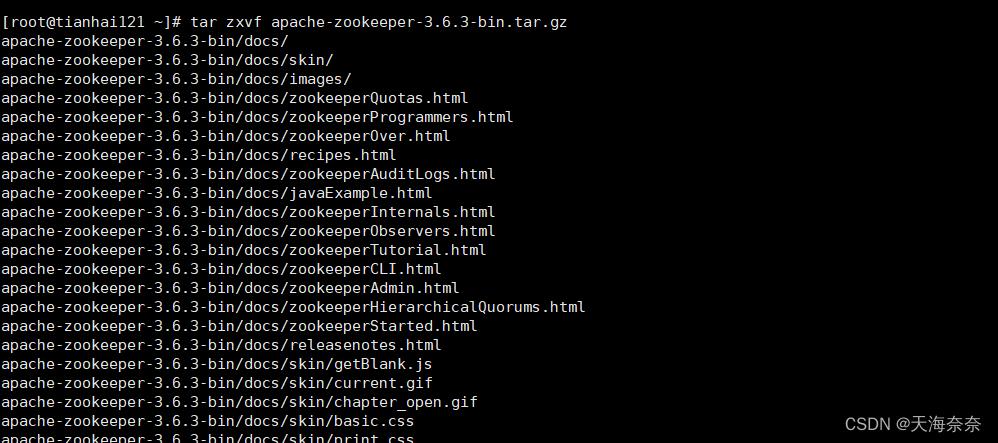
解压缩完成后,输入ls

看到这个解压的文件夹已经存在了
3 调整配置文件
我们现在进入这个文件夹

输入cp conf/zoo_sample.cfg conf/zoo.cfg
复制完成后打开zoo.cfg,先输入cd conf 进入到conf 再输入vim zoo.cfg

# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
ticktime: 时间单元,比如我们设置超时时间是设置几个时间单元这里就是一个单元有多久
clientPort=2181 : 这就是对外提供的端口号,默认就是2181
没啥改的,看一眼记一下这配置文件就好。esc + : +q 退出即可
4 启动
输入 cd.. 返回上级目录
输入./bin/zkServer.sh start 如果想关闭,输入./bin/zkServer.sh stop 到此lunix下的安装与调整配置文件以及如何启动就讲完了。linux下想要启动的话需要有java环境。

Windows环境下
其实操作都是一样的,不同的是windows下启动我们执行的是bin下的zkServer.cmd
这个文件
三 zookeeper的基本数据类型
zookeeper的基本数据类型的结构是树形结构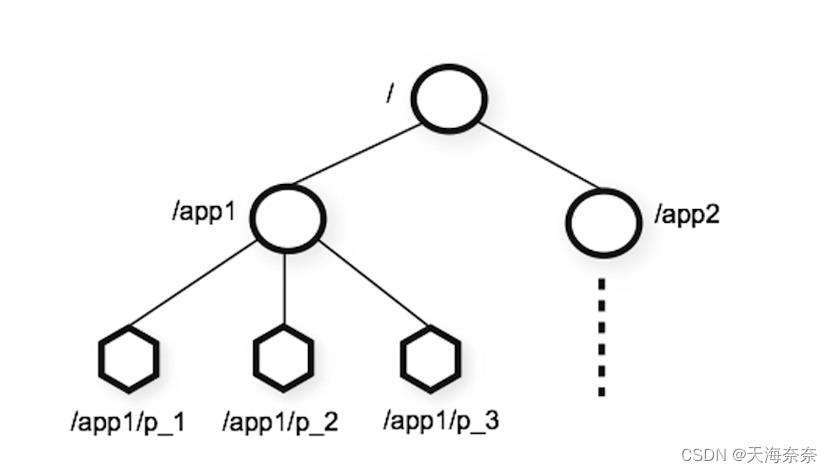
节点的特征:
可以存储数据,但是数据要尽量的简洁
是树形结构,有父子节点之分
有版本号的概念,可以用来防止误操作
可以在节点上防止监听器去感知节点的变化
节点的类型:
持久节点 如果在创建之初我们将它设置为持久节点,就算我们断网了这个节点也是存在的
临时节点 如果客户端断了,过一段时间节点就会被清理掉。
顺序节点 如果使用了顺序这个特性zookeeper会在这个节点后面加10位的数字 相当于计数器
eg:0000000001 0000000002,且可以保证同一个父节点下这个顺序是唯一的 既可以应用在持久节点也可以应用在临时节点。
节点的选择:
如果只是一次性的操作就选择临时节点
如果想长久地保存一些信息就使用
四 常用命令及演示
启动:
输入cd apache-zookeeper-3.6.3-bin 回车后输入./bin/zkServer.sh start
看到启动成功后输入: ./bin/zkCli.sh -server 127.0.0.1:2181

 末行出现SyncConnected证明我们连接成功
末行出现SyncConnected证明我们连接成功
1 help :输入help会给我们一些命令的提示
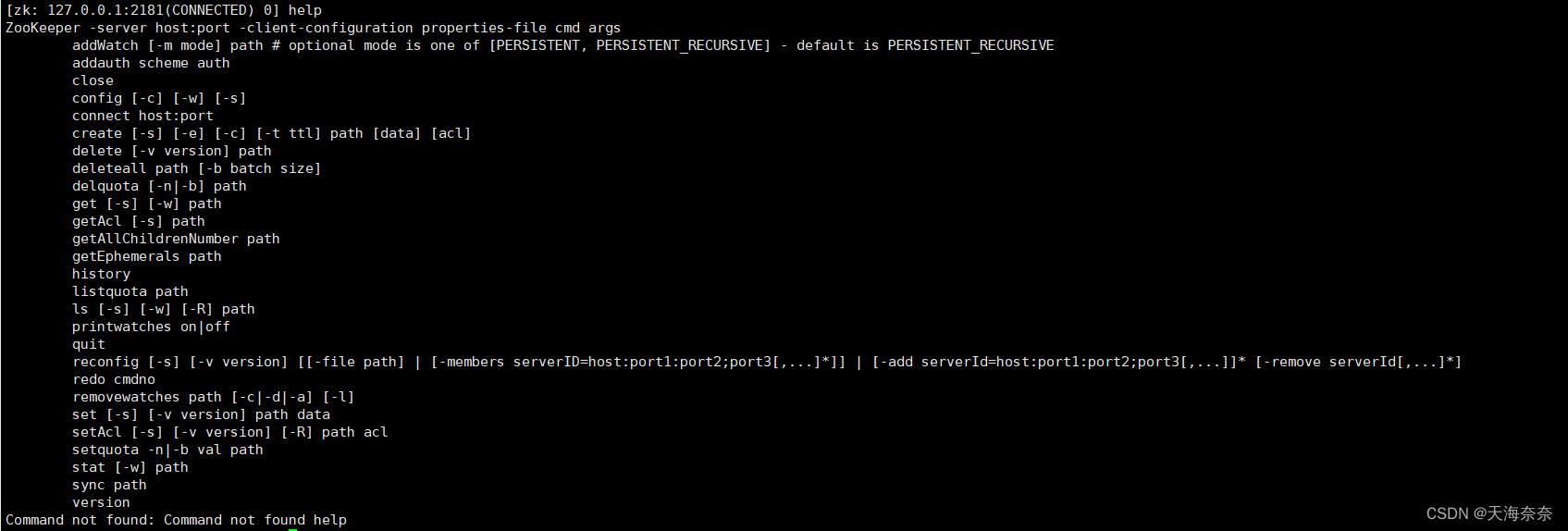
2 creat :
create [-s] [-e] [-c] [-t ttl] path [data] [acl] 带括号的是可选参数,可加可不加 path是必须假的代表节点路劲
3 delete
delete [-v version] path : version 是版本号,只有符合这个版本的才会被删除,不然会删除失败
4 get:
get [-s] [-w] path :获取查询
5 set
set [-s] [-v version] path data :修改
6 演示:
我们先看一下原始的目录结构,可以看到根目录下只有zookeeper 文件夹 他有两个子文件夹 config, quota 这是系统默认生成的。

结构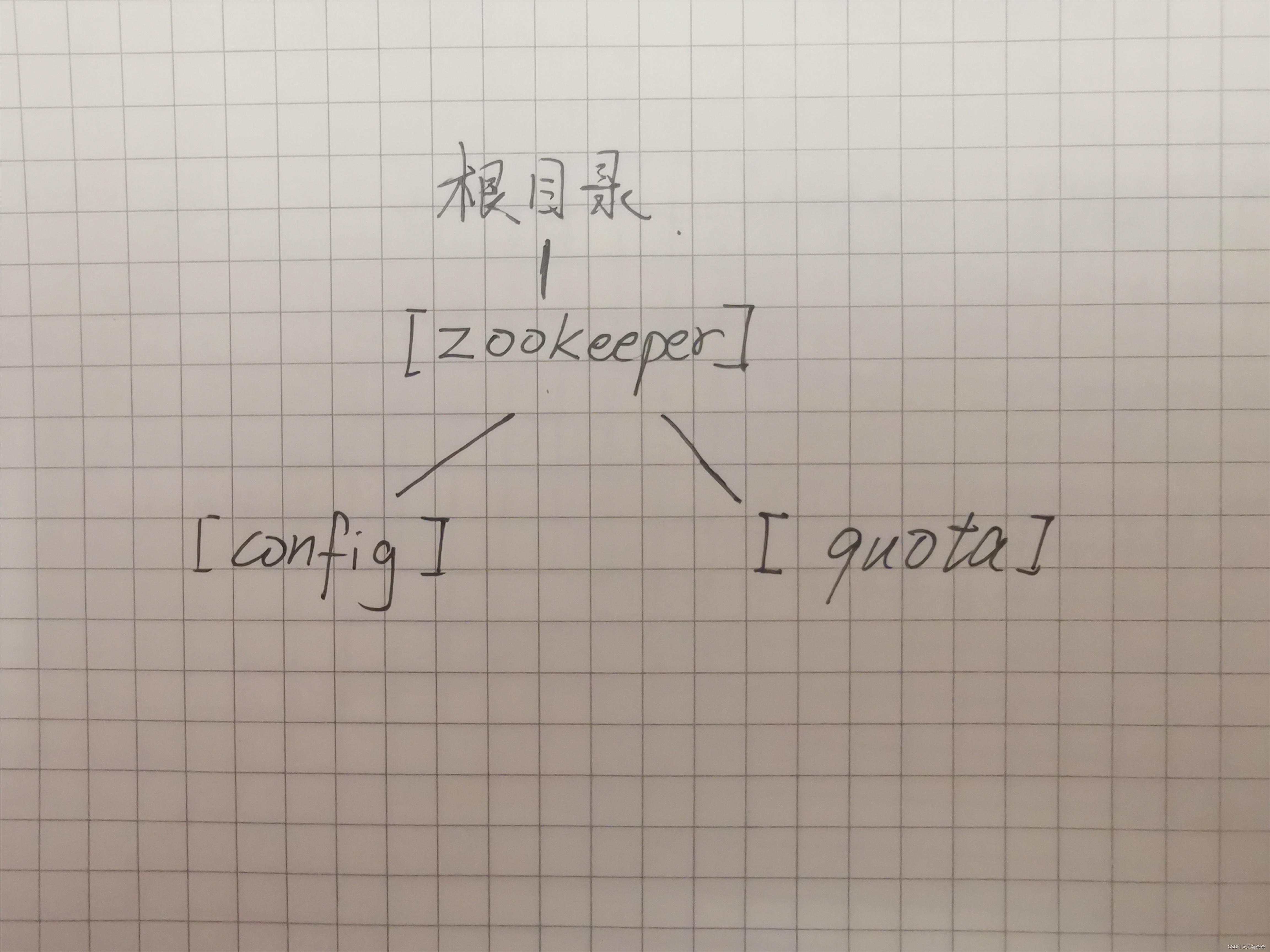
现在我们试一下创建两个结点 并给结点附值
输入
create /java1 hellojava1
create /java1/zk1 hellozk1
create /java2 hwllojava2
create /java2/zk2 hellozk2
再以递归的方式 看看目录中都有哪些文件 输入 ls -R /
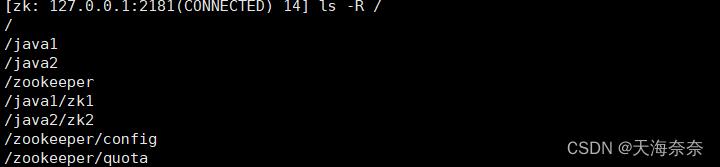
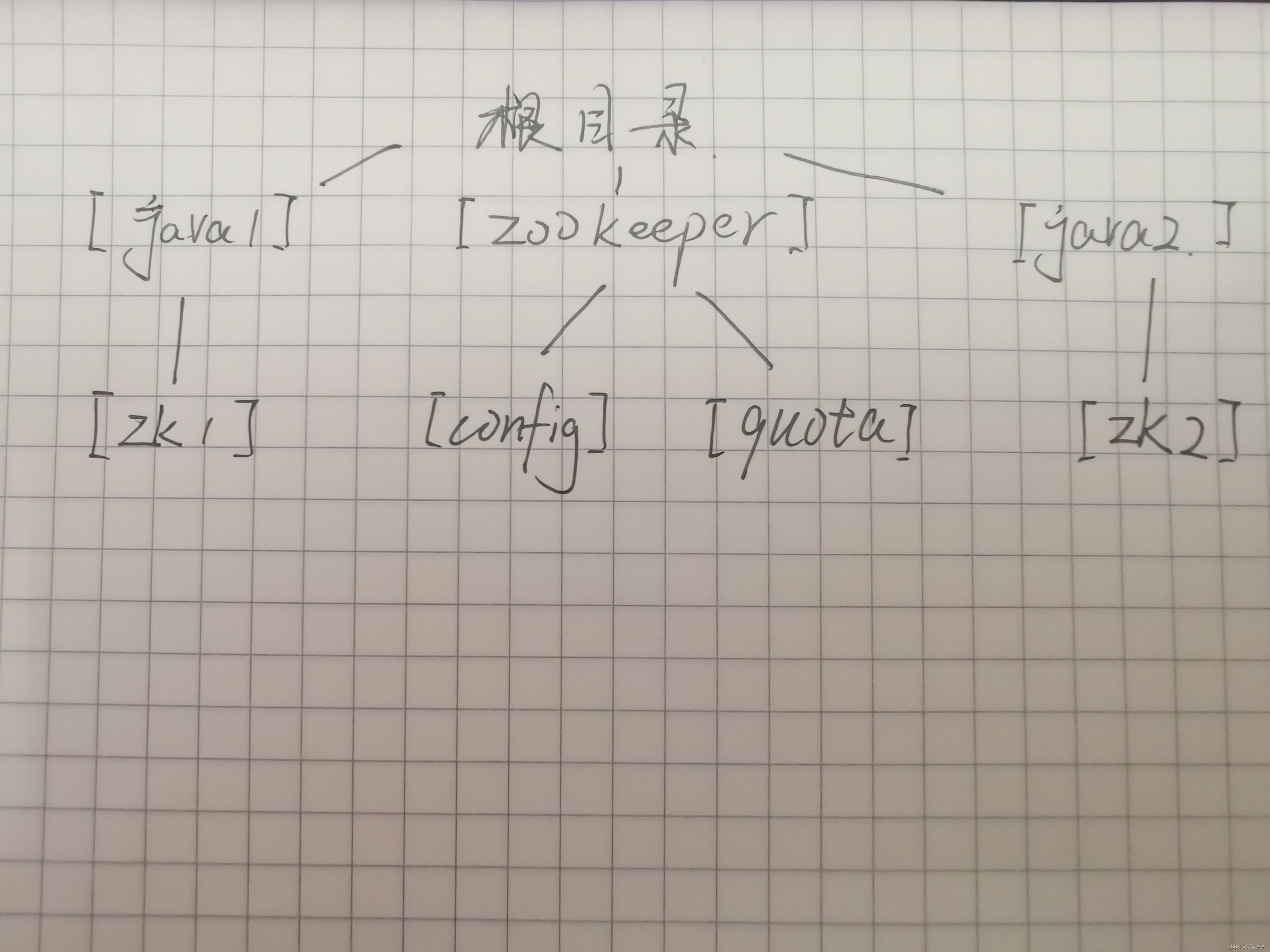 我们创建在子目录中创建两个节点,两个节点还有自己的子节点
我们创建在子目录中创建两个节点,两个节点还有自己的子节点
使用get来查看节点的数据 输入 get /java1

现在来演示set 的用法
我们把java2/zk2 的hellozk2改为hellochange
是用delete来删除节点,删除节点是要保证删除节点下没有其他节点 演示删除java2
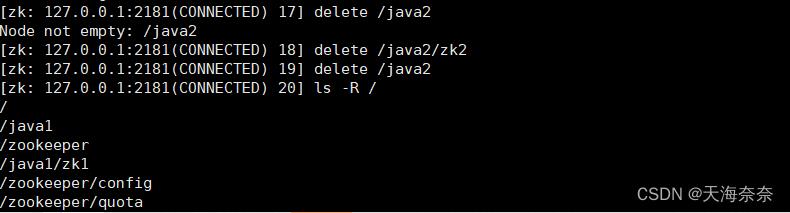
可以看到java2这个节点就被删除了
五 高级命令
与版本号相关的命令
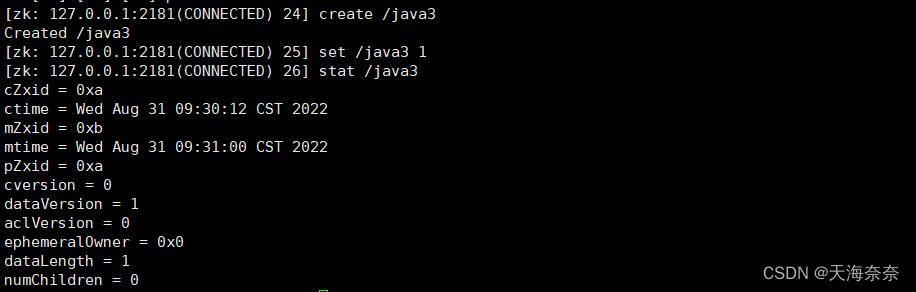
新建一个节点java3 看到内部版本数据dataVersion=1 此1非彼1
这时候假设有两个客户端想要改变这个节点的数据。
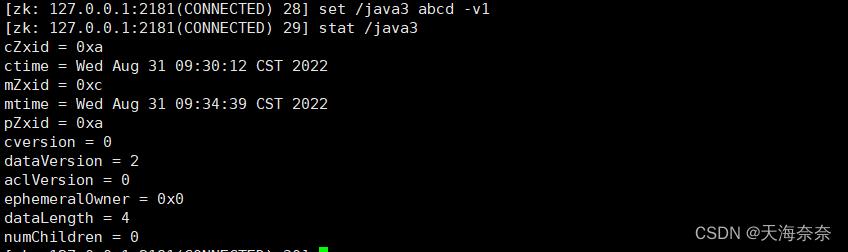
第一个人根据当前节点版本把值进行了修改,修改后版本发生了变化
此时第二个客户端如果还想通过版本号1来进行修改就不会成功

这就是乐观锁的思想,与版本好相关的操作不仅仅有set。
顺序节点与临时节点
我们看java3 节点的属性 ephemeralOwner = 0x0 这个代表持久节点。服务退出重进它是会一直存在的。
那么临时节点如何创建呢 输入 :create /java4 -e
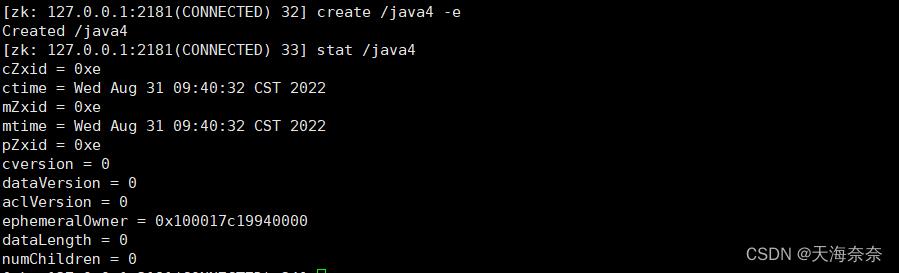
ephemeralOwner = 0x100017c19940000 这就代表它是临时节点 如果退出后重连,过一段时间这个节点就会被清除。
顺序节点
输入: create /java5 create /java5/abc -s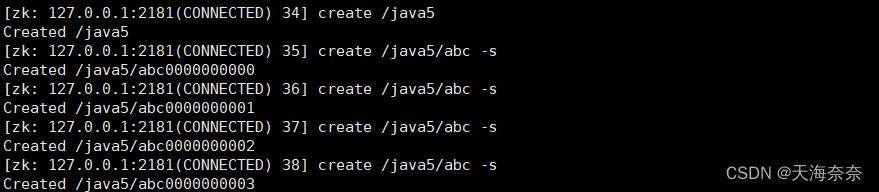
新建在父节点下面的子节点后面会有10位的数字 保证数据的唯一性。-s 建立的节点也是持久节点,-s 与 -e 是可以一起使用的。
六 watcher机制
类似于监视器、触发器、监督者
使用场景:通知,例如配置中心更新数据
事件类型
NodeCreated节点创建
NodeDeleted节点删除
NodeDataChanged节点数据修改
NodeChildrenChanged子节点变更
七 ACL
Access Control List权限控制列表
粒度细: 5种权限.
CREATE :可以创建一个子节点
READ :可以从节点获取数据并列出其子节点
WRITE :可以为节点设置数据
DELETE :可以删除子节点
ADMIN :可以设置权限
八 代码实操
客户端型
打开idea 创建一个maven工程
名字随便取一个就叫zk-test吧,组件一改
我们要使用zookeeper那我们就引入依赖
<dependencies>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.0</version>
</dependency>
</dependencies>首先来测试下连接和断开
/**
* 连接到zk
*/
public class FirstConnect
public static void main(String[] args) throws IOException, InterruptedException
ConnectWatcher connectWatcher = new ConnectWatcher();
//第一步指定zookeeper的属性,
ZooKeeper zooKeeper = new ZooKeeper(zkConstant.ZK_HOST, zkConstant.CONNECT_TIMEOUT, connectWatcher);
System.out.println("客户顿开始连接zk服务器");
States states = zooKeeper.getState();
System.out.println(states);
System.out.println("11111");
Thread.sleep(2000);
System.out.println(states);
Thread.sleep(2000);
zooKeeper.close();
ZooKeeper()第一个参数是地址 第二个参数是连接 的超时时间,第三个参数是监听器。
的超时时间,第三个参数是监听器。
常量类:
public class zkConstant
public static final String ZK_HOST = "127.0.0.1:2181";//本机地址
public static final Integer CONNECT_TIMEOUT = 8000;//超时时间
watcher 监听类
/**
* 连接Watcher
*/
public class ConnectWatcher implements Watcher
@Override
public void process(WatchedEvent watchedEvent)
System.out.println("ConnectWatcher被调用");
//根据state去判断
if (watchedEvent.getState() == Event.KeeperState.SyncConnected)
System.out.println("连接成功");
if (watchedEvent.getState() == Event.KeeperState.Closed)
System.out.println("连接断开");
由于连接是有延迟的我们一起动先打印一次状态,延迟两秒在打印一次状态,延迟两秒退出。连接和退出时监听器会打印连接和断开。
运行结果:
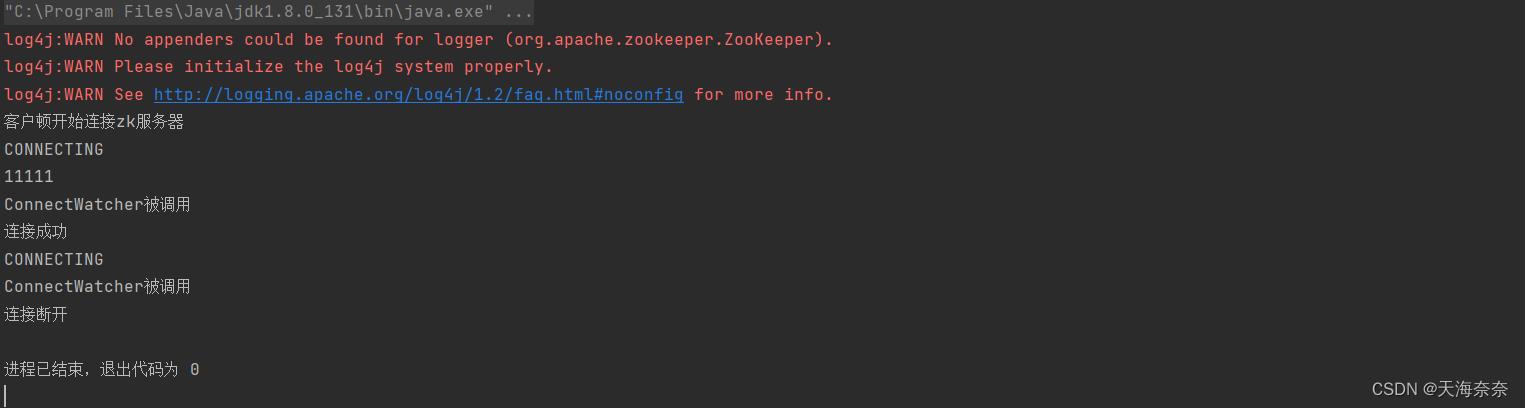
实现节点的增删改查
/**
* 描述: 对节点的增删改查
*/
public class ZkCRUD
public static void main(String[] args) throws IOException, InterruptedException, KeeperException
ConnectWatcher connectWatcher = new ConnectWatcher();
//第一步指定zookeeper的属性,
ZooKeeper zooKeeper = new ZooKeeper(zkConstant.ZK_HOST, zkConstant.CONNECT_TIMEOUT, connectWatcher);
System.out.println("客户顿开始连接zk服务器");
States states = zooKeeper.getState();
System.out.println(states);
Thread.sleep(2000);
System.out.println(states);
//对节点进行增删改查
//第一个参数是地址,第二个参数是byte数组,第三个参数是acl 我们选择对所有都开放,第四个参数是节点类型 这里选择临时节点
zooKeeper.create(zkConstant.PATH_1,"firstOne".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL);
Thread.sleep(2000);
//由于数据时byte数组
byte[] bytes = null;
bytes = zooKeeper.getData(zkConstant.PATH_1,null,null);
System.out.println(new String((bytes)));
Thread.sleep(2000);
//改
zooKeeper.setData(zkConstant.PATH_1,"secondOne".getBytes(),-1);//-1是任意版本都可以
Thread.sleep(2000);
bytes = zooKeeper.getData(zkConstant.PATH_1,null,null);
System.out.println(new String(bytes));
//删
zooKeeper.delete(zkConstant.PATH_1,-1);
Thread.sleep(2000);
zooKeeper.close();
我们在改,删时第二个参数watcher用的是null,如果我们要使用监听且有我们自定义的监听就用true。
原生客户端操作起来略显复杂,不支持重连重试
使用Apache Curator
引入依赖
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>/**
* 描述: 用Curator来操作ZK
*/
public class CuratorTests
public static void main(String[] args) throws Exception
String connectString = "127.0.0.1:2181";
String path = "/curator1";//节点路径
//重试机制
ExponentialBackoffRetry retry = new ExponentialBackoffRetry(1000, 10);
//新建客户端
CuratorFramework client = CuratorFrameworkFactory.newClient(connectString, retry);
client.start();
//监听
client.getCuratorListenable().addListener((CuratorFramework c, CuratorEvent event) ->
switch (event.getType())
case WATCHED:
WatchedEvent watchedEvent = event.getWatchedEvent();
if (watchedEvent.getType() == EventType.NodeDataChanged)
System.out.println(new String(c.getData().forPath(path)));
System.out.println("触发节点更改事件");
);
String data = "test";
String data2 = "test2";
//增
client.create().withMode(CreateMode.EPHEMERAL).forPath(path, data.getBytes());
//查
byte[] bytes = client.getData().watched().forPath(path);
System.out.println(new String(bytes));
//改
client.setData().forPath(path, data2.getBytes());//watched是一次性监听事件,重复调用也不会触发
client.setData().forPath(path, data2.getBytes());//watched是一次性监听事件,重复调用也不会触发
client.setData().forPath(path, data2.getBytes());//watched是一次性监听事件,重复调用也不会触发
Thread.sleep(2000);
client.delete().forPath(path);
Thread.sleep(2000);
//永久监听
String pathNew = "/curatorForEver";
client.create().withMode(CreateMode.EPHEMERAL).forPath(pathNew, data.getBytes());
NodeCache nodeCache = new NodeCache(client, pathNew);
nodeCache.start();
nodeCache.getListenable().addListener(new NodeCacheListener()
@Override
public void nodeChanged() throws Exception
ChildData currentData = nodeCache.getCurrentData();
if (currentData != null)
System.out.println("触发了永久监听的回调,当前值为:" + new String(currentData.getData()));
);
client.setData().forPath(pathNew, data2.getBytes());
Thread.sleep(2000);
client.setData().forPath(pathNew, data2.getBytes());
Thread.sleep(2000);
client.setData().forPath(pathNew, data2.getBytes());
Thread.sleep(2000);
client.delete().forPath(pathNew);
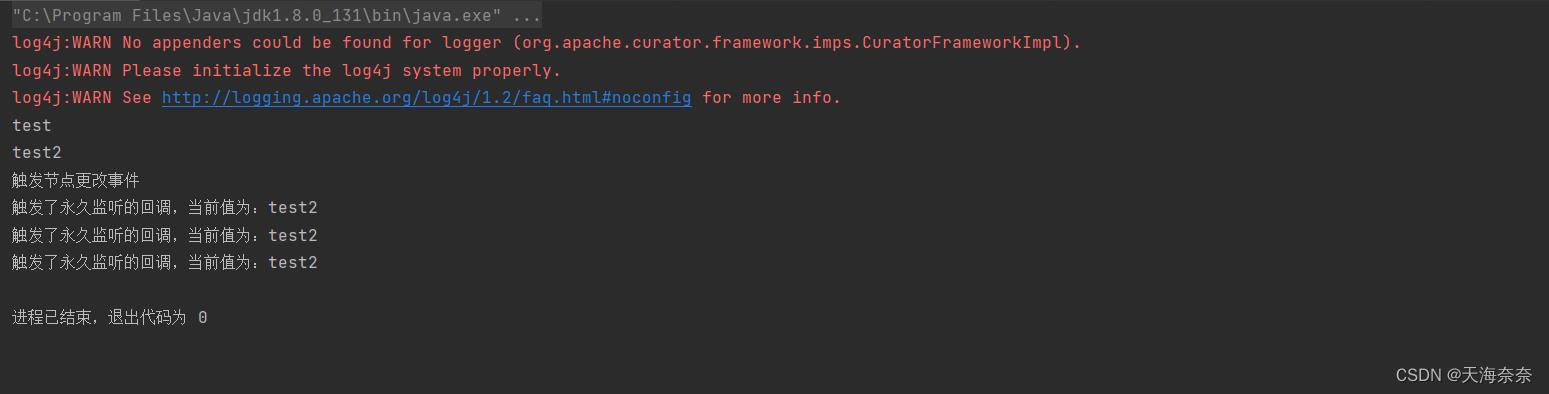
没有使用永久监听时是不会进行回掉模式一次性,所以只打印了一次,如果使用永久监听就不一样了。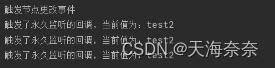
以上是关于猿创征文|[Zookeeper]快速上手Zookeeper.Zookeeper的初识别,安装,znode节点的理解,常用命令,Wacher机制,ACL权限控制及上述功能在idea的代码实现的主要内容,如果未能解决你的问题,请参考以下文章
猿创征文 | 国产数据库之openGauss的单机主备部署及快速入门