Elasticseach:从微服务架构演变到大宽表思维的架构转变
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticseach:从微服务架构演变到大宽表思维的架构转变相关的知识,希望对你有一定的参考价值。
序言
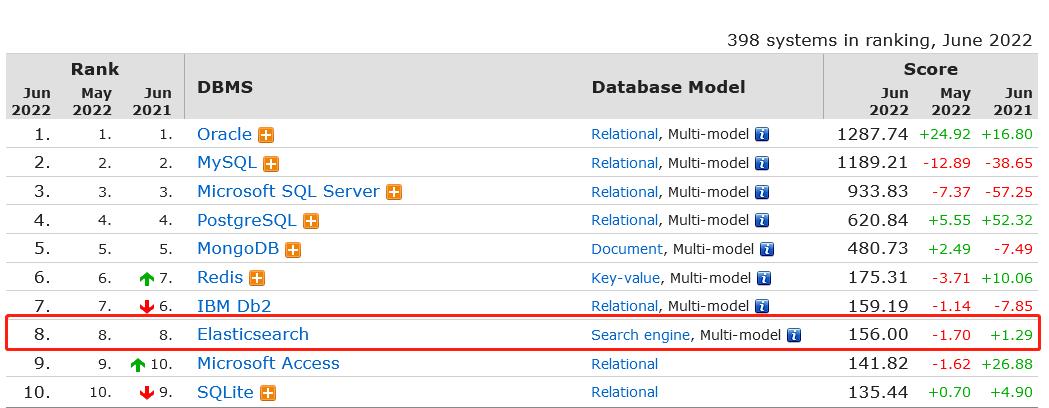
图示:Elasticsearch 在DB-Engine综合排名第8
Elasticsearch 简称"ES”, 在DB-Engine 综合排名第8,已经持续了相当长的时间,按照当下热度应该会继续保持或者上升一个名次;ES在多数工程师印象中最深刻可能是ELK三件套或者全文检索领域,但在笔者看来,应该是业务系统领域“大宽表查询”场景,或者叫“数据库查询加速”场景。
下面就从微服务架构开始,谈谈ES是如何解决应用系统中复杂查询的,为什么应该是首选?
微服务架构
微服务是一种应用系统架构模式,非指特定的技术框架。微服务时代人人都在谈微服务架构,在Java编程领域,Spring Cloud技术栈体系几乎已经成为了微服务的代名词或者首选,当下如果去应聘一名Java工程师,有三个必问技术框架,Spring,Spring Boot,Spring Cloud,俗称"厨房"三件套,随便打开一个招聘网站或者了解一个公司IT项目架构设计,几乎都有Spring XXXX。注意,这里不是跟大家讨论微服务技术栈,只是为了给大家探讨微服务架构模式的一些弊端与进化。
微服务架构模式
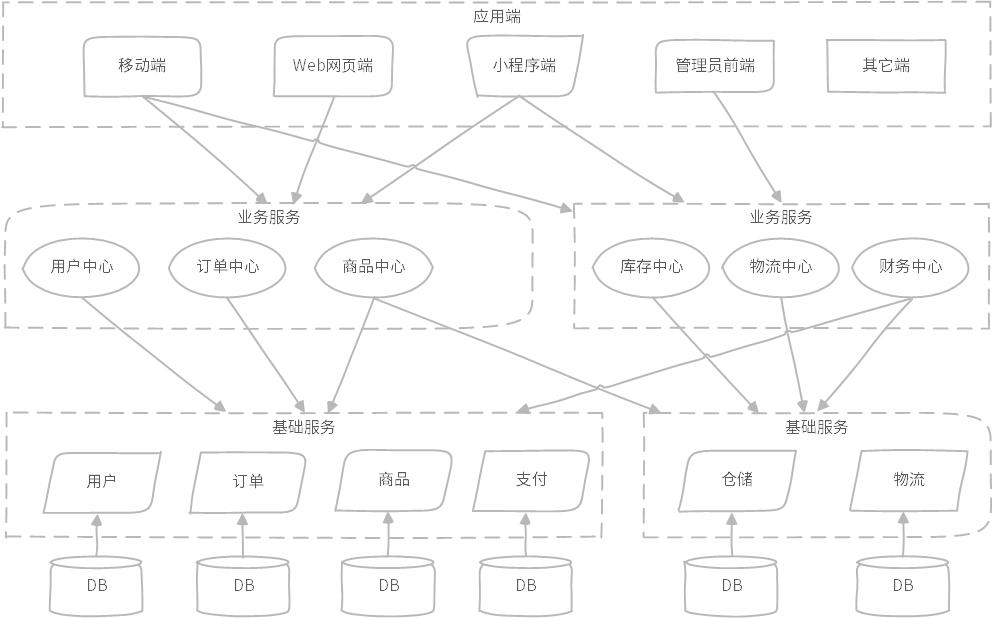
图示:某电商物流微服务架构模式示意图,参考百度百科
在微服务架构模式中,一般的做法会基于领域进行服务划分与编排;服务划分为基础服务与业务服务,基础服务更抽象一些,一个基础服务对应一个数据库模型。
如图所示,用户基础服务有用户领域专属 DB,订单基础服务有订单领域 DB,商品有商品领域 DB 等;业务服务一般是聚合服务,按照应用系统交互方式组合,如订单中心,需要查询订单基础服务与商品基础服务,在订单中心内部进行组合,还有如商品中心、库存中心、财务中心等都是基于组合各自需要的基础服务进行。
微服务架构弊端
基础服务抽象的划分与编排,初步看起来都非常美好,很符合微服务架构模式规范;业务服务组合各种基础服务,也看起来很美好,也很符合微服务架构模式规范。
随着业务规模越来越大,业务变化越来越复杂,以上微服务架构模式开始出现各种各样的查询复杂度问题;首先,用户、订单、商品、支付基础服务大概率都需要进行分库分表重构,在这之前订单中心的查询,进行一次关联查询,只需要跨几个基础服务查询,性能与复杂度都还能接受,在这之后,偶然的一次关联查询,就需要消耗非常多的查询资源,包括数据库层面、基础服务组合调用层面等。
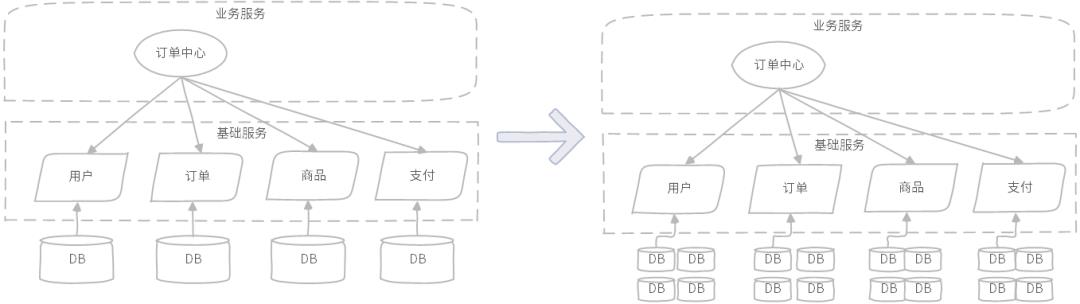
图示:订单中心关联查询模式,系统复杂度高、查询资源消耗大
如果能通过快速廉价的增加硬件资源方式继续这种微服务模式,倒也无可厚非,只是越往后可选择的余地越来越有限。
大宽表架构
为了解决微服务应用架构中,跨多个基础服务 join 联合查询问题,需要引入一种“大宽表”架构模式,简单来说就是将各种需要关联的基础服务数据提前关联计算好,并存储到一个强悍的数据产品中,基于此数据产品提炼新的基础服务或者业务服务,取名“xx数据服务”,以数据关联为导向融入到微服务架构体系之中。
数据架构模式
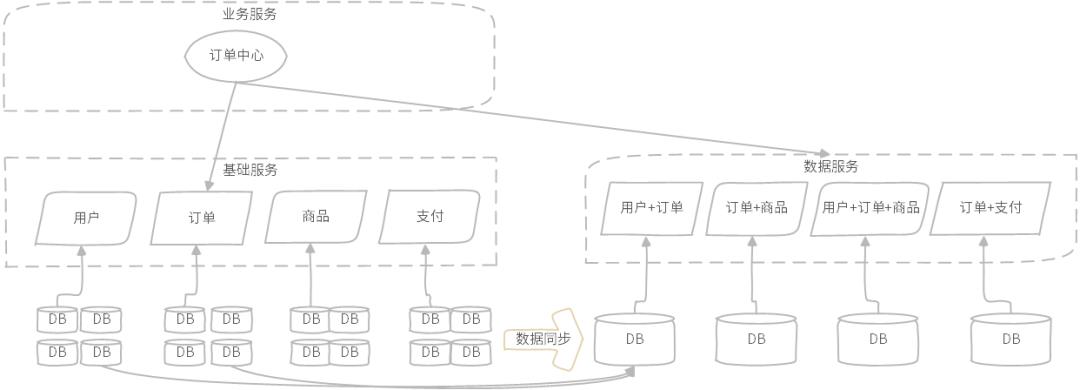
图示:订单中心关联查询,由数据服务提供
如图所示,订单中心的各种复杂查询由订单维度数据服务完成,数据服务独立于基础服务,与基础服务属于同一服务层次,数据服务依赖的数据库采用大宽表模式构建,数据来源于其它数据库同步,或离线同步或实时同步。
数据库范式
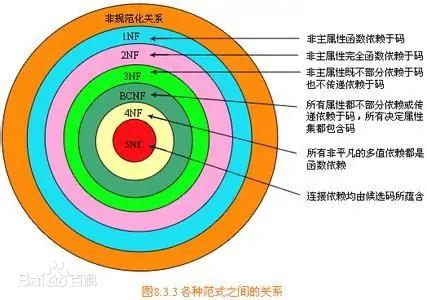
图示:数据库范式示意图,来自百度百科
我们知道,在设计数据库表模型,必须要遵守数据库范式,已知目前有五种,通常意义到第三范式就差不多了,但是在面对日益复杂的应用场景,反过来大大约束了数据产品的能力,进而导致微服务架构模式的性能问题。
在此场景下,我们还有必要遵守范式约束吗?答案是的,还是需要遵守,不过换个说法“反范式”。如订单中心图示,先必须有基础服务,然后才能有数据数据,数据服务底层数据数据模型采用反范式设计,数据来源基础服务,自己不生产数据,不修改数据,也不保证数据的 ACID,仅仅是为了查询存在。
数据同步
在大宽表架构模式下,数据服务不负责数据的产生与维护,数据来源于基础服务,从基础服务到数据服务,中间需要打通数据同步,解决了数据同步关键问题,也就解决了微服务架构模式与数据架构模式融合。

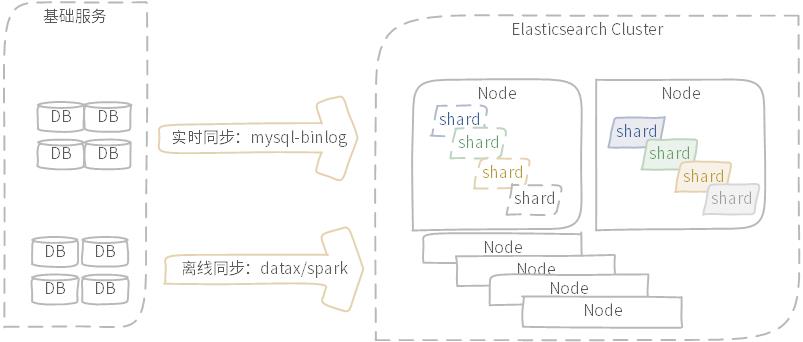
图示:实时同步与离线同步示意图
数据同步包含实时同步与离线同步,实时同步多数采用数据库支持的WAL机制完成,如mysql-Binlog;离线同步有更多的选择方式,如DataX工具等。此处不深入展开数据同步话题,可以参考笔者历史文章或公开分享内容。
用 ES 承载大宽表架构模式
为什么选择 Elasticsearch来承载数据服务,实现大宽表架构模式?以下简单说几点?
首先,ES最核心的是倒排索算法,支持任意复杂条件组合查询,大宽表的目的就是为了便于数据查询检索,而不必定制化的指定字段创建索引,同比传统数据库左侧原则检索算法,要灵活很多;
其次,ES数据模型构造基于Free Schema理念,应用层面采用Json填充,支持局部数据变更,提供了非常灵活的机制,大宽表模式数据构建时,原则上无法保证所有关联数据表完全同步更新,有了这种灵活模式,就不必拘泥于此;
最后,ES架构设计的特性,分布式架构,支持横向扩展,支持超大集群规模,数据层面采用分片与副本机制,保障性能与高可用等。
图示:ES分布式架构,数据分片与副本
结语
当传统微服务架构面临海量数据检索困境时,不要试图继续在微服务架构模式中优化,记得尝试数据架构转变,将大宽表架构模式融入其中。
以前会说“ES玩的好,下班下得早”,现在开始“数据玩的好,下班下得早”
篇幅有限,我们找个时间给大家视频分享一下,一起探讨一下 Elasticsearch 更多的应用花样。

参考文献
马丁叔叔 关于《微服务架构概要描述》https://martinfowler.com/articles/microservices.html
知乎《微服务架构是什么?》
https://www.zhihu.com/question/65502802
铭毅天下《干货 | Elasticsearch多表关联设计指南》https://mp.weixin.qq.com/s/j7YdtmyuzBFRK1BViDtp2w
数据库范式https://baike.baidu.com/item/%E6%95%B0%E6%8D%AE%E5%BA%93%E8%8C%83%E5%BC%8F/7309898
关于
关于作者
Elastic King 数据领域专家
Elastic Stack 国内顶尖实战专家
ELastic Stack 技术社区分享嘉宾
国内首批Elastic 官方认证工程师21人之一
阿里云MVP(大数据领域)
DBAPlus MVP(原创内容贡献者)
GitHub:https://github.com/ynuosoft
2012年入手Elasticsearch,对Elastic Stack技术栈开发、架构、运维、源码、算法等方面有深入实战;负责过多种Elastic Stack项目,包括大数据分析领域,机器学习预测领域,业务查询加速领域,日志分析领域,基础指标监控领域等;
服务过多家企业,提供Elastic Stack 咨询培训以及调优实施;
多次在Elastic Stack技术大会/技术社区分享,发表过多篇实战干货文章;
十余年技术实战从业经验,擅长大数据多种技术栈混合,系统架构领域。
以上是关于Elasticseach:从微服务架构演变到大宽表思维的架构转变的主要内容,如果未能解决你的问题,请参考以下文章