MyBatisPlus多数据源加ES大宽表架构落地实践
Posted 大飞哥~BigFei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MyBatisPlus多数据源加ES大宽表架构落地实践相关的知识,希望对你有一定的参考价值。
文章目录
1.背景
在微服务大行其道的今天,我们在业务系统的开发中难免会遇到一些问题,由于微服务的微的特点,将之前单体的应用划分为许多的微服务的模块,数据库也从原来的一整个库划分为许多业务库,从而就让各个微服务模块之前的交互变得不方便,从而引入了一些远程调用服务的rpc框架的出现,比如fegin、dubbo、grpc、http客户端工具等,让操作业务库的数据变得都要走一次网络远程接口调用,这样就产生了网络开销,哪有没有什么好的方案来解决这个问题呢?业务场景如下图所示,互联网公司有各种业务子系统,子系统都有有支付的功能,所以搞了如图所示的聚合支付服务,提供调用各个支付平台的支付相关的接口,各个业务系统有自己的业务订单数据库,聚合支付也有自己的交易订单数据库,互联网公司的财务会需要一个财务对账系统,需求是要去拉取第三方支付平台的支付单跟支付聚合服务库的交易订单对账,然后又要从支付聚合服务库的交易订单跟各个业务系统的业务订单数据对账,那么这两个财务的需求你应该如何设计这个对账系统呢?
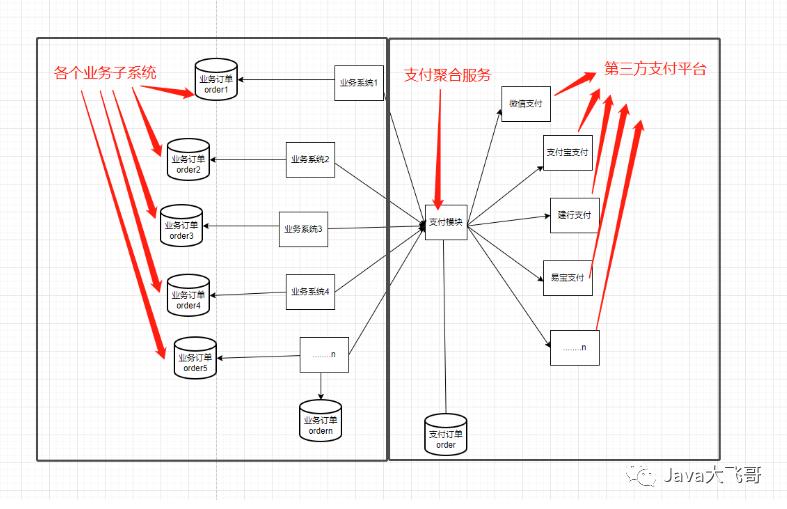
2.方案
需求:
支付聚合服务交易订单和第三方支付平台的支付单对账—资金对账单
支付聚合服务交易订单需要和各个业务子系统的业务订单对账—业务对账单
需要建立资金对账表和N个业务对账表
2.1使用传统的mysql数据库+fegin伪rpc调用
由于mysql数据是关系型数据库(一张二维表),如果业务系统过于复杂,那么建立资金对账表和N个业务对账表里面的字段就会相当的多,每次如果财务需要一些信息,那就得加字段,然后重新跑批更新之前已经生成的数据填充后面新增的字段,这样就会很麻烦,同时每次跑批(使用xxl-job)mysql的压力也会增大,每次去获取各个业务系统都需要使用fegin调用,使用fegin调用如果由于网络抖动(网络不稳定)会导致调用失败,从而让对账失败,所以就会产生巨大的网络开销,不仅会让网络堵塞还让服务器和数据库的压力增大,这种传统的方式会让人很痛苦。
2.2使用mybatisPlus多数据源+ES大宽表架构
es启动器
由于ES的特性可以将原先的mysql表主要的字段设计在一个索引字段中,可以设计一个json的字段存储对账两方的订单的原始数据,这种就方便查看全部的详细数据,不至于每次都需要去库里面查数据看业务对账的代码逻辑是怎样的来确定生成的该条对账数据是正确的还是错误的(差错数据对账自动标识出来的,就根据关联的id和两边的金额是否一致判断),同时使用mybatisPlus的多数据源的功能直接在财务对账系统中使用它嫁接在各个业务系统的数据库上,每次需要业务数据就只要通过切换数据源去各自的业务数据库中把数据搂过来,事先设计好索引,比如资金账单索引的设计,它的索引的id可以使用支付聚合服务交易订单的id作为索引的id这样每次重新执行对账,索引中的每一条数据会被更新覆盖,索引的各个字段会被覆盖更新,使用es的批量更新操作需要控制好并发,最好是单行程操作索引数据,还需要写接口去拉取第三方支付系统的账单数据,比如微信的是只能查询当前日期30天内的账单数据还是3个月的数据,所以每次对账数据都只能拉取到几个月内的数据,所以批处理任务每次执行的是前几天的数据,需要将其数据做一个备份,可以上传到OSS等文件存储做一个备份,这个是为了后期如果有数据对账数据是有误的可以去查看这个备份文件做一个排查和修复数据时使用,然后两种对账数据从es对用的索引中查数据万级别以下的数据分页查询也很轻松,如果数据量非常大的情况下,使用es分页查询会有深度分页的问题,解决思路参考如下连接,由于基本都是历史数据使用ES的大宽表将字段平铺在ES的索引中就可以轻松的解决上面两个需求,同时ES的近实时的查询,最多有1s的延迟,也提供了多维度的数据检索聚合的能力,单索引的存储检索能力达到PB级别,实际上索引分片一个在30G-50G最佳,这也是ES亿级文档的强大的检索聚合能。
# ElasticSearch深度分页解决方案:
https://juejin.cn/post/7091619223659053069
mybaitsPlus多数据源教程:
pom依赖:
<!--多数据源配置-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>p6spy</groupId>
<artifactId>p6spy</artifactId>
<version>3.8.0</version>
</dependency>
yml配置:
spring:
datasource:
p6spy: true
dynamic:
datasource:
# 主库
master:
url: jdbc:mysql://xxxxx:3306/xxxx?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowMultiQueries=true&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
username: xxx
password: xxxx
driver-class-name: com.mysql.cj.jdbc.Driver
# 业务订单001库
order_001:
url: jdbc:mysql://xxxx:3306/xxxxx?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowMultiQueries=true&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
username: xxxx
password: xxxx
driver-class-name: com.mysql.cj.jdbc.Driver
启动类上排除DataSourceAutoConfiguration:
@EnableFeignClients
@EnableDiscoveryClient
@MapperScan("com.xx.xxx.dao")
@SpringBootApplication(scanBasePackages = "com.xxx.xxxx.*", exclude =
DataSourceAutoConfiguration.class
)
public class xxxxxServiceApplication
public static void main(String[] args)
SpringApplication.run(xxxxxxServiceApplication.class, args);
数据源切换在类或方法上加上@DS(“order_001”)注解,order_001表示切换使用order_001库,然后调用相应的dao层方法即可取到相应库的数据了,使用mybatisPlus的多数据源切换异步更新、保存或者删除数据操作,需要使用如下姿势,不让会报错:
@Slf4j
@Service
@DS("order_001")
public class OrderServiceImpl extends ServiceImpl<OrderDao,OrderEntity> implements IOrderService
@Autowired
private OrderDao orderDao;
@Override
public List<OrderEntity> getOrdersByUserId(Long userId)
QueryWrapper<OrderEntity> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("user_id", userId).eq("is_delete", 0);
List<OrderEntity> orderEntities = orderDao.selectList(queryWrapper);
String dataSourceLookupKey = DynamicDataSourceContextHolder.getDataSourceLookupKey();
CompletableFuture<Void> vcf1 = CompletableFuture.runAsync(() ->
Optional.ofNullable(orderEntities).ifPresent(oe ->
DynamicDataSourceContextHolder.setDataSourceLookupKey(dataSourceLookupKey);
oe.stream().forEach(o ->
orderDao.deleteById(o.getId());
);
);
);
try
vcf1.get();
catch (Exception e)
e.printStackTrace();
return orderEntities;
DynamicDataSourceContextHolder也是我在遇到报错的时候去看了mybatisPlus的源码看到了这个类,先在主线程中的dataSourceLookupKey值取出来,然后在异步线程中重新设置进去,这样子线程就知道主线程使用的是哪个数据源了。
curl调用ES接口和索引设计示例:
首先使用curl获取集群中可用的Elasticsearch索引列表:
curl -XGET 'http://localhost:9200/_cat/indices?v&pretty'
curl -XGET 'http://localhost:9200/fund_rec/_count?pretty'
删除索引
curl -i -XDELETE http://127.0.0.1:9200/bis_bc_rec
kibana清除某个索引的数据
POST bis_wd_rec/_delete_by_query
"query": "match_all":
curl -XPOST 'http://127.0.0.1:9200/fund_rec/_delete_by_query?refresh&slices=5&pretty' -H 'Content-Type: application/json' -d'
"query":
"match_all":
'
curl -XGET 'http://localhost:9200/fund_rec/_doc/_count?pretty'
curl -i -XDELETE http://127.0.0.1:9200/fund_rec
1.fund_rec
curl -XPUT 'localhost:9200/fund_rec' -H 'content-Type:application/json' -d '
"settings":
"number_of_shards":1,
"number_of_replicas":2
,
"mappings":
"properties":
"id":
"type":"long"
,
"orderNo":
"type":"long"
,
"channelNo":
"type": "keyword"
,
"channelCode":
"type": "keyword"
,
"tradeState":
"type" : "short"
,
"orderAmount":
"type": "scaled_float",
"scaling_factor": 100
,
"realAmount":
"type": "scaled_float",
"scaling_factor": 100
,
"createTime":
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss"
,
"updateTime":
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss"
,
"tradeTime":
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss"
,
"refundTime":
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss"
,
"recState":
"type" : "short"
,
"recType":
"type" : "short"
,
"billType":
"type" : "short"
,
"refundAmount":
"type": "scaled_float",
"scaling_factor": 100
,
"centOrders":
"type" : "object"
,
"threeBills":
"type" : "object"
,
"desc":
"type":"text"
,
"billTime":
"type":"date",
"format":"yyyy-MM-dd"
,
"isDel":
"type" : "short"
,
"historyData":
"type":"text"
'
2.bis_bc_rec
curl -XPUT 'localhost:9200/bis_bc_rec' -H 'content-Type:application/json' -d '
"settings":
"number_of_shards":1,
"number_of_replicas":2
,
"mappings":
"properties":
"id":
"type": "long"
,
"recType":
"type": "short"
,
"orderNo":
"type": "long"
,
"yyOrderId":
"type": "long"
,
"cxOrderId":
"type": "keyword"
,
"originalOrderId":
"type": "keyword"
,
"orderType":
"type": "long"
,
"channelNo":
"type": "keyword"
,
"channelCode":
"type": "keyword"
,
"tradeState":
"type": "long"
,
"orderAmount":
"type": "float"
,
"realAmount":
"type": "float"
,
"centRealAmount":
"type": "scaled_float",
"scaling_factor": 100
,
"isDiscount":
"type": "short"
,
"discountName":
"type": "keyword"
,
"disAmount":
"type": "scaled_float",
"scaling_factor": 100
,
"bisType":
"type": "short"
,
"createTime":
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
,
"updateTime":
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
,
"tradeTime":
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
,
"recState":
"type": "short"
,
"centRefundAmount":
"type": "scaled_float",
"scaling_factor": 100
,
"refundTotalAmount":
"type": "scaled_float",
"scaling_factor": 100
,
"bisRefundAmount":
"type": "scaled_float",
"scaling_factor": 100
,
"isRefund":
"type": "short"
,
"refundNumb":
"type": "short"
,
"refundType":
"type": "short"
,
"refundTime":
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
,
"centOrders":
"type" : "object"
,
"bisData":
"type" : "object"
,
"desc":
"type": "text"
,
"billTime":
"type": "date",
"format": "yyyy-MM-dd"
,
"isDel":
"type": "short"
,
"ownLine":
"type": "keyword"
,
"isChange":
"type": "short"
,
"isUpdateOrder":
"type": "short"
,
"costDetails":
"type": "text"
,
"businessId":
"type": "keyword"
,
"useIntegral":
"type": "integer"
,
"isAddressOrder":
"type": "short"
,
"isChangeOrder":
"type": "keyword"
,
"changeAddrDifference":
"type": "scaled_float",
"scaling_factor": 100
,
"changeDifference":
"type": "scaled_float",
"scaling_factor": 100
,
"isPartRefund":
"type": "short"
,
"refundMoney":
"type": "scaled_float",
"scaling_factor": 100
,
"orderSource":
"type": "short"
,
"userId":
"type": "long"
,
"mobile":
"type": "keyword"
,
"status":
"type": "short"
,
"tradeNo":
"type": "long"
,
"refundNo":
"type": "long"
,
"cxOrderMoney":
"type": "scaled_float",
"scaling_factor": 100
,
"orderMoney":
"type": "scaled_float",
"scaling_factor": 100
,
"discountMoney":
"type": "scaled_float",
"scaling_factor": 100
,
"cashDiscount":
"type": "scaled_float",
"scaling_factor": 100
,
"integralNum":
"type": "integer"
,
图示:Elasticsearch 在DB-Engine综合排名第8
Elasticsearch 简称"ES”, 在DB-Engine 综合排名第8,已经持续了相当长的时间,按照当下热度应该会继续保持或者上升一个名次;ES在多数工程师印象中最深刻可能是ELK三件套或者全文检索领域,但在笔者看来,应该是业务系统领域“大宽表查询”场景,或者叫“数据库查询加速”场景。
下面就从微服务架构开始,谈谈ES是如何解决应用系统中复杂查询的,为什么应该是首选?
微服务架构
微服务是一种应用系统架构模式,非指特定的技术框架。微服务时代人人都在谈微服务架构,在Java编程领域,Spring Cloud技术栈体系几乎已经成为了微服务的代名词或者首选,当下如果去应聘一名Java工程师,有三个必问技术框架,Spring,Spring Boot,Spring Cloud,俗称"厨房"三件套,随便打开一个招聘网站或者了解一个公司IT项目架构设计,几乎都有Spring XXXX。注意,这里不是跟大家讨论微服务技术栈,只是为了给大家探讨微服务架构模式的一些弊端与进化。
微服务架构模式
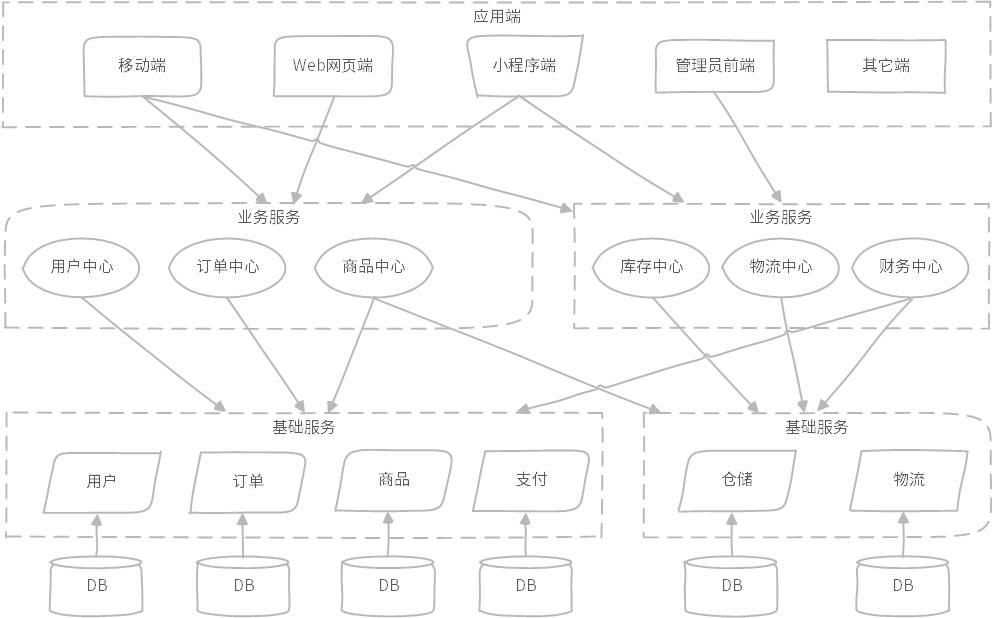
图示:某电商物流微服务架构模式示意图,参考百度百科
在微服务架构模式中,一般的做法会基于领域进行服务划分与编排;服务划分为基础服务与业务服务,基础服务更抽象一些,一个基础服务对应一个数据库模型。
如图所示,用户基础服务有用户领域专属 DB,订单基础服务有订单领域 DB,商品有商品领域 DB 等;业务服务一般是聚合服务,按照应用系统交互方式组合,如订单中心,需要查询订单基础服务与商品基础服务,在订单中心内部进行组合,还有如商品中心、库存中心、财务中心等都是基于组合各自需要的基础服务进行。
微服务架构弊端
基础服务抽象的划分与编排,初步看起来都非常美好,很符合微服务架构模式规范;业务服务组合各种基础服务,也看起来很美好,也很符合微服务架构模式规范。
随着业务规模越来越大,业务变化越来越复杂,以上微服务架构模式开始出现各种各样的查询复杂度问题;首先,用户、订单、商品、支付基础服务大概率都需要进行分库分表重构,在这之前订单中心的查询,进行一次关联查询,只需要跨几个基础服务查询,性能与复杂度都还能接受,在这之后,偶然的一次关联查询,就需要消耗非常多的查询资源,包括数据库层面、基础服务组合调用层面等。
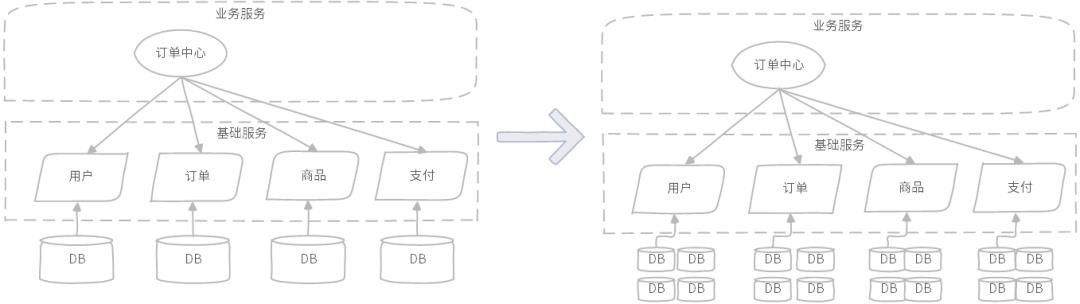
图示:订单中心关联查询模式,系统复杂度高、查询资源消耗大
如果能通过快速廉价的增加硬件资源方式继续这种微服务模式,倒也无可厚非,只是越往后可选择的余地越来越有限。
大宽表架构
为了解决微服务应用架构中,跨多个基础服务 join 联合查询问题,需要引入一种“大宽表”架构模式,简单来说就是将各种需要关联的基础服务数据提前关联计算好,并存储到一个强悍的数据产品中,基于此数据产品提炼新的基础服务或者业务服务,取名“xx数据服务”,以数据关联为导向融入到微服务架构体系之中。
数据架构模式
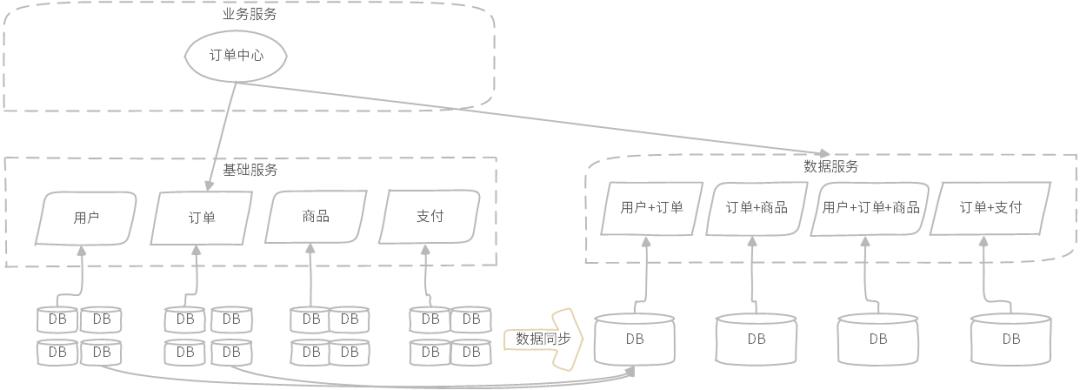
图示:订单中心关联查询,由数据服务提供
如图所示,订单中心的各种复杂查询由订单维度数据服务完成,数据服务独立于基础服务,与基础服务属于同一服务层次,数据服务依赖的数据库采用大宽表模式构建,数据来源于其它数据库同步,或离线同步或实时同步。
数据库范式
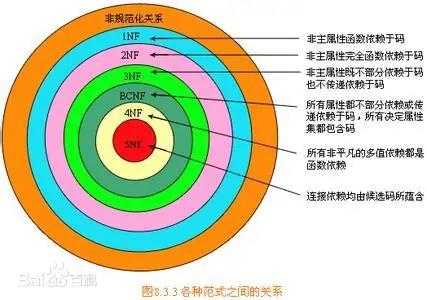
图示:数据库范式示意图,来自百度百科
我们知道,在设计数据库表模型,必须要遵守数据库范式,已知目前有五种,通常意义到第三范式就差不多了,但是在面对日益复杂的应用场景,反过来大大约束了数据产品的能力,进而导致微服务架构模式的性能问题。
在此场景下,我们还有必要遵守范式约束吗?答案是的,还是需要遵守,不过换个说法“反范式”。如订单中心图示,先必须有基础服务,然后才能有数据数据,数据服务底层数据数据模型采用反范式设计,数据来源基础服务,自己不生产数据,不修改数据,也不保证数据的 ACID,仅仅是为了查询存在。
数据同步
在大宽表架构模式下,数据服务不负责数据的产生与维护,数据来源于基础服务,从基础服务到数据服务,中间需要打通数据同步,解决了数据同步关键问题,也就解决了微服务架构模式与数据架构模式融合。

图示:实时同步与离线同步示意图
数据同步包含实时同步与离线同步,实时同步多数采用数据库支持的WAL机制完成,如Mysql-Binlog;离线同步有更多的选择方式,如DataX工具等。此处不深入展开数据同步话题,可以参考笔者历史文章或公开分享内容。
用 ES 承载大宽表架构模式
为什么选择 Elasticsearch来承载数据服务,实现大宽表架构模式?以下简单说几点?
首先,ES最核心的是倒排索算法,支持任意复杂条件组合查询,大宽表的目的就是为了便于数据查询检索,而不必定制化的指定字段创建索引,同比传统数据库左侧原则检索算法,要灵活很多;
其次,ES数据模型构造基于Free Schema理念,应用层面采用Json填充,支持局部数据变更,提供了非常灵活的机制,大宽表模式数据构建时,原则上无法保证所有关联数据表完全同步更新,有了这种灵活模式,就不必拘泥于此;
最后,ES架构设计的特性,分布式架构,支持横向扩展,支持超大集群规模,数据层面采用分片与副本机制,保障性能与高可用等。
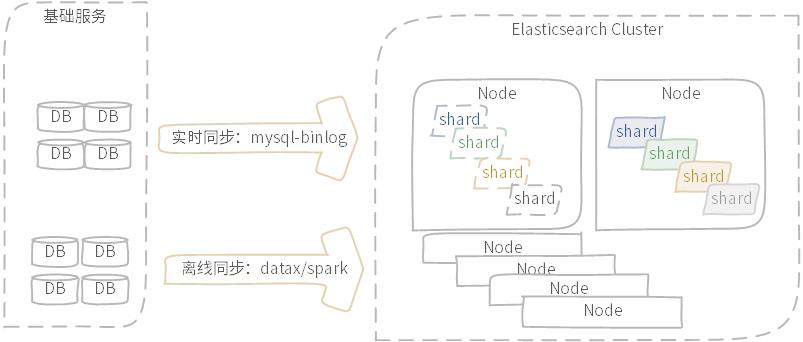
图示:ES分布式架构,数据分片与副本
结语
当传统微服务架构面临海量数据检索困境时,不要试图继续在微服务架构模式中优化,记得尝试数据架构转变,将大宽表架构模式融入其中。
以前会说“ES玩的好,下班下得早”,现在开始“数据玩的好,下班下得早”
篇幅有限,我们找个时间给大家视频分享一下,一起探讨一下 Elasticsearch 更多的应用花样。

参考文献
马丁叔叔 关于《微服务架构概要描述》https://martinfowler.com/articles/microservices.html
知乎《微服务架构是什么?》
https://www.zhihu.com/question/65502802
铭毅天下《干货 | Elasticsearch多表关联设计指南》https://mp.weixin.qq.com/s/j7YdtmyuzBFRK1BViDtp2w
数据库范式https://baike.baidu.com/item/%E6%95%B0%E6%8D%AE%E5%BA%93%E8%8C%83%E5%BC%8F/7309898
关于
关于作者
Elastic King 数据领域专家
Elastic Stack 国内顶尖实战专家
ELastic Stack 技术社区分享嘉宾
国内首批Elastic 官方认证工程师21人之一
阿里云MVP(大数据领域)
DBAPlus MVP(原创内容贡献者)
GitHub:https://github.com/ynuosoft
2012年入手Elasticsearch,对Elastic Stack技术栈开发、架构、运维、源码、算法等方面有深入实战;负责过多种Elastic Stack项目,包括大数据分析领域,机器学习预测领域,业务查询加速领域,日志分析领域,基础指标监控领域等;
服务过多家企业,提供Elastic Stack 咨询培训以及调优实施;
多次在Elastic Stack技术大会/技术社区分享,发表过多篇实战干货文章;
十余年技术实战从业经验,擅长大数据多种技术栈混合,系统架构领域。
以上是关于MyBatisPlus多数据源加ES大宽表架构落地实践的主要内容,如果未能解决你的问题,请参考以下文章