机器学习:WEKA的应用之 J48(C4.5)
Posted happy_XYY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习:WEKA的应用之 J48(C4.5)相关的知识,希望对你有一定的参考价值。
对于机器学习分类问题的解决方法除了SVM(支持向量机)、maxent(最大熵)还有J48和Adaboost,这两项工具箱都有集成在weka里,下面先说一下对J48即C4.5的应用
- weka的下载与安装
- 什么是J48(C4.5)
- weka中J48(C4.5)的应用
一、weka的下载与安装
下载地址:weka下载地址(SourceForge) 我用的是win7的32位系统,安装后点击图标,在命令框中会出现如下提示
---Registering Weka Editors---
Trying to add database driver (JDBC): jdbc.idbDriver - Error, not in CLASSPATH?
由于暂时用不到数据库,此错误可以先忽略
二、什么是J48(C4.5)
J48是一种决策树算法,那下面首先说一下什么是决策树。
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法。他是一种监管学习,所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
决策树算法
Trees 即决策树算法,决策树是对数据进行分类,以此达到预测的目的。该决策树方法先根据训练集数据形成决策树,如果该树不能对所有对象给出正确的分类,那么选择一些例外加入到训练集数据中,重复该过程一直到形成正确的决策集。决策树代表着决策集的树形结构。决策树由决策结点、分支和叶子组成。决策树中最上面 的结点为根结点,每个分支是一个新的决策结点,或者是树的叶子。每个决策结点代表一个问题或决策,通常 对应于待分类对象的属性。每一个叶子结点代表一种可能的分类结果。沿决策树从上到下遍历的过程中,在每个结点都会遇到一个测试,对每个结点上问题的不同的 测试输出导致不同的分支,最后会到达一个叶子结点,这个过程就是利用决策树进行分类的过程,利用若干个变量来判断所属的类别。
Id3 即决策树 ID3 算法
ID3 算法是由 Quinlan 首先提出的。该算法是以信息论为基础,以信息熵和信息增益度为衡量标准,从而实现对数据的归纳分类。
以下是一些信息论的基本概念:
定义 1:若存在 n 个相同概率的消息,则每个消息的概率 p 是 1/n,一个消息传递的信息量为 Log2(n)
定义 2:若有 n 个消息,其给定概率分布为 P=(p1,p2 … pn),则由该分布传递的信息量称为 P 的熵,记为
I (p) =-(i=1 to n 求和 ) piLog2(pi) 。
定义 3:若一个记录集合 T 根据类别属性的值被分成互相独立的类 C1C2..Ck,则识别 T 的一个元素所属哪个类所需要的信息量为 Info (T) =I (p) ,其中 P 为 C1C2 … Ck 的概率分布,即 P= (|C1|/|T| … |Ck|/|T|)
定义 4:若我们先根据非类别属性 X 的值将 T 分成集合 T1,T2 … Tn,则确定 T 中一个元素类的信息量可通过确定 Ti 的加权平均值来得到,即 Info(Ti) 的加权平均值为:
Info(X, T) = (i=1 to n 求和 ) ((|Ti|/|T |) Info (Ti))
定义 5:信息增益度是两个信息量之间的差值,其中一个信息量是需确定 T 的一个元素的信息量,另一个信息量是在已得到的属性 X 的值后需确定的 T 一个元素的信息量,信息增益度公式为:
Gain(X, T) =Info (T)-Info(X, T)
J48 即决策树 C4.5 算法
C4.5 算法一种分类决策树算法 , 其核心算法是 ID3 算法。C4.5 算法继承了 ID3 算法的优点,并在以下几方面对 ID3 算法进行了改进:
用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
在树构造过程中进行剪枝;
能够完成对连续属性的离散化处理;
能够对不完整数据进行处理。
C4.5 算法有如下优点:产生的分类规则易于理解,准确率较高。其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
三、weka中J48(C4.5)的应用
1、简单介绍一下weka
Weka的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),是一款免费的,非商业化(与之对应的是SPSS公司商业数据挖掘产品–Clementine )的,基于JAVA环境下开源的机器学习(machine learning)以及数据挖掘(data minining)软件。它和它的源代码可在其官方网站下载(网址)。有趣的是,该软件的缩写WEKA也是New Zealand独有的一种鸟名,而Weka的主要开发者同时恰好来自New Zealand的the University of Waikato。
WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
2、主要界面
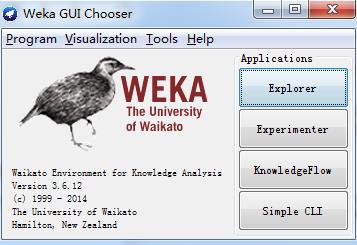
上图中,主要使用右方的四个模块,说明如下:
explorer : 使用weka探索数据的环境,包括获取关联项,分类预测,聚簇等
experimenter:运行算法试验、管理算法方案之间的统计检验的环境;
knowledgeFlow:这个环境本质上和Explorer所支持的功能是一样的,但是它有一个,可以拖放的界面。有一个优势,就是支持增量学习
simpleCLI:提供一个简单的命令行界面,从而可以在没有自带命令行的操作系统中直接执行weka命令(某些情况下使用命令行功能更好一些)
主界面:进入explorer模式后
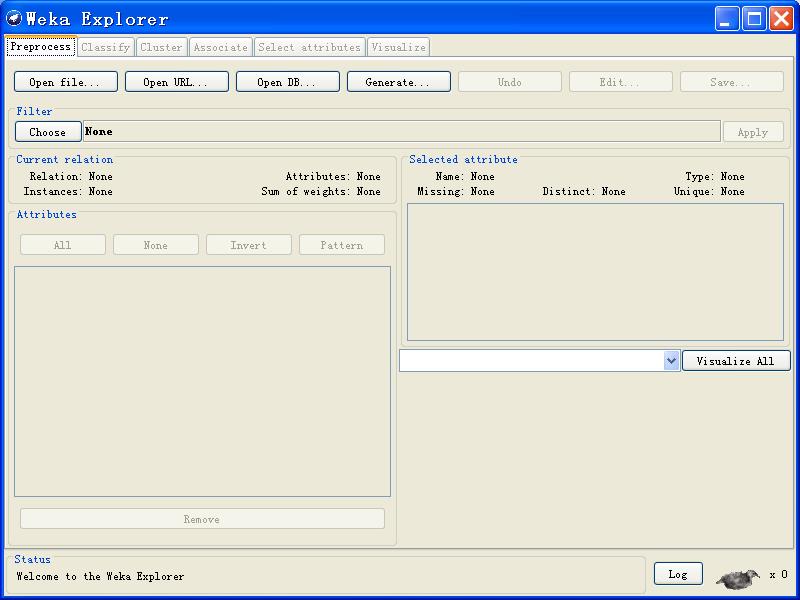
标签栏
主界面最左上角(标题栏下方)的是标签栏,分为五个部分,功能依次是:
Preprocess(数据预处理):选择和修改要处理的数据;
Classify(分类):训练和测试关于分类或回归的学习方案;
Cluster(聚类):从数据中学习聚类;
Associate(关联):从数据中学习关联规则;
Select attributes(属性选择):选择数据中最相关的属性;
Visualize(可视化):查看数据的交互式二维图像。
载入、编辑数据
标签栏下方是载入数据栏,功能如下:
Open file:打开一个对话框,允许你浏览本地文件系统上的数据文件(.dat);
Open URL:请求一个存有数据的URL 地址;
Open DB:从数据库中读取数据;
Generate:从一些数据生成器中生成人造数据。
其他界面说明
接下来的主界面中依次是Filter(筛选器),Currtent relation(当前关系)、Attributes(属性信息)、Selected attribute(选中的属性信息)以及Class(类信息),分别介绍如下:
Filter
在预处理阶段,可以定义筛选器来以各种方式对数据进行变换。Filter 一栏用于对各种筛选器进行必要设置。Filter一栏的左边是一个Choose 按钮。点击这个按钮就可选择Weka中的某个筛选器。用鼠标左键点击这个choose左边的显示框,将出现GenericObjectEditor对话框。用鼠标右键点击将出现一个菜单,你可从中选择,要么在GenericObjectEditor对话框中显示相关属性,要么将当前的设置字符复制到剪贴板。Currtent relation
显示当前打开的数据文件的基本信息:Relation(关系名),Instances(实例数)以及Attributes(属性个数)。Attributes 显示数据文件中的属性信息,并且包含四个操作按键:

All:所有选择框都被勾选;
None:所有选择框被取消;
Invert:已勾选的选择框都被取消,反之亦然;
Pattern:让用户基于Perl 5正则表达式来选择属性。例如,用*_id选择所有名称以_id结束的属性。
底下显示的就是数据文件包含的属性,可以进行勾选等操作。特别地,当数据预处理是不要某个属性时,将其各选,点击列表正下方的Remove按键即可删除这一属性:

Selected attribute
显示勾选的属性的基本信息。
Class
显示属性中数据元组的直方图。点击Visualize all按键可以查看所有属性中元组的直方图。
实现基本数据挖掘功能:
Associate(关联规则)
注意:目前,Weka的关联规则分析功能仅能用来作示范,不适合用来挖掘大型数据集。
各部分功能说明如下:
Associator
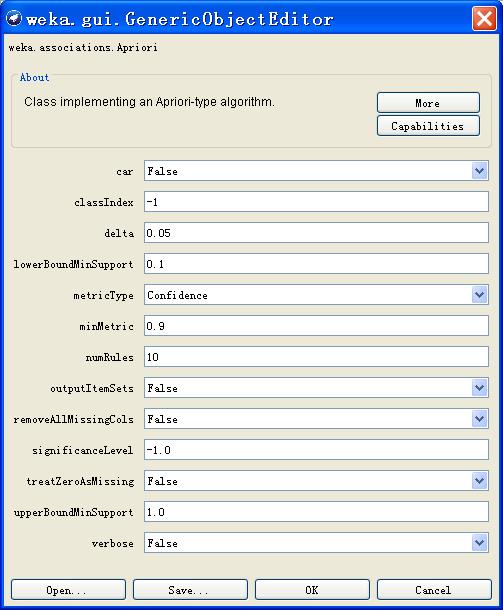
切换到Associate选项卡。单击choose按键,可以选择关联规则算法,系统默认关联规则分析算法是Apriori算法。选择关联规则算法后,点Choose右边的文本框修改默认的参数,弹出的窗口中点More可以看到各参数的说明。一下简列几项:
upperBoundMinSupport:最小支持度上限 removeAllMissingCols :移除具有遗失值的列
lowerBoundMinSupport :最小支持度下限 outputItemSets :如果有可能也输出项集
significanceLevel:显著性水平 classIndex:确定分类属性,如果设为-1,则最后一个属性为分类属性
treatZeroAsMissing :将遗失值全部置为0 numRules:在某种关联规则下取出的满足条件的规则数;
metricType:关联、程度指标;
注意:各种关联规则算法都是尤其使用范围的,并不是所有的属性的数据类型都能被某一算法处理,典型的例如Apriori算法。因此可以在choose下拉菜单中选择Filter选项,在其中勾选待处理数据的属性的类型以滤除无法使用的算法。要想知道每种算法都是用哪些数据类型,可以左击choose旁边的文本框,在弹出的菜单栏中单击capabilities选项可以看到这种算法能够处理的数据类型。
Result list 点击Associator下方的start按键可以开始进行关联项分析,结果列表即出现在Result list中,右击出现更多选项可供选择。Associator output 这里显示关联分析结果,如图为一个例子:
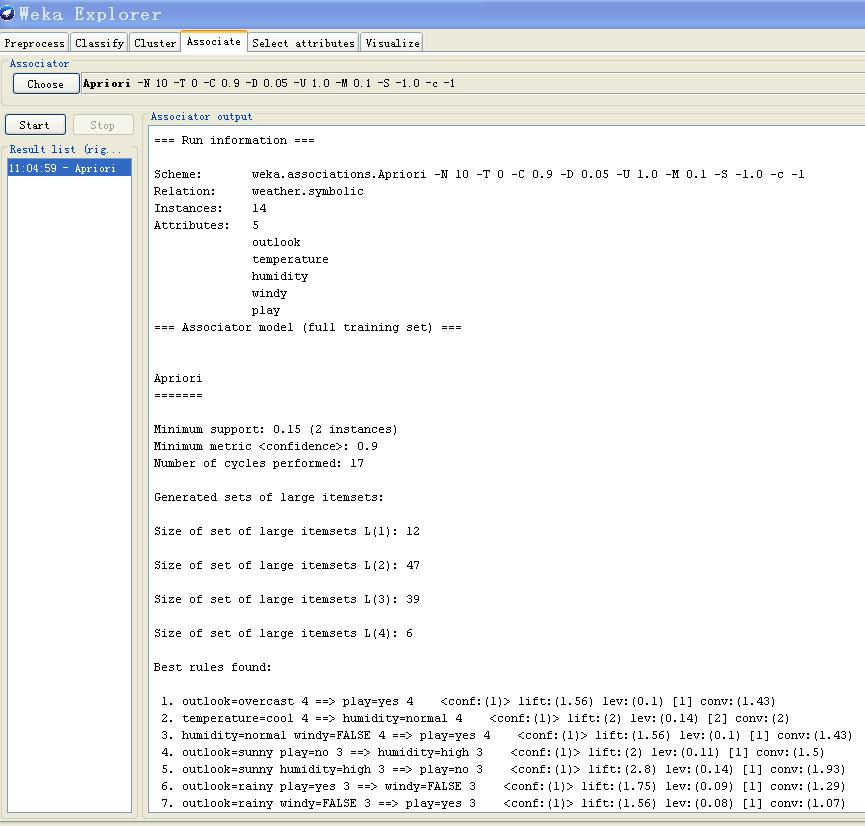
一次显示了10个符合条件的关联规则,并且在其后显示了关联规则的四项指标以供参考。
Classify(分类预测)
该部分实现数据挖掘中的分类与预测功能,提供了各种主要的分类预测算法供使用者选择。下面是界面各部分的介绍:
Classifier
在choose一栏中选择需要的分类算法,同样地方法,每当选择一个算法,这个算法便在choose左边的文本框中进行显示,单击他会出现一个菜单,其中包含了一些参数的设定和more以及capabilities选项,欠着用来获取那些需要设定参数的具体信息,后者用来获取算法适合的属性数据类型,这一点是相似的,因此在对数据进行处理是也应该注意数据的属性类型,单击choose在下拉菜单中选择Filter按键可以进行数据类型的选择从而过滤掉不能使用的算法。。
Test option
提供四种测试模式:
1. Using training set.根据分类器在用来训练的实例上的预测效果来评价它。
2. Supplied test set. 从文件载入的一组实例,根据分类器在这组实例上的预测效果来评价它。点击 Set…按钮将打开一个对话框来选择用来测试的文件。
3. Cross-validation.使用交叉验证来评价分类器,所用的折数填在Folds 文本框中。
4. Percentage split.从数据集中按一定百分比取出部分数据放在一边作测试用,根据分类器这些实例上预测效果来评价它。取出的数据量由% 一栏中的值决定。
当一切准备就绪时,点击start按键开始分类过程,完成后Result list中会显示结果列表,并且Classifier output中会显示出结果。右击Result list中的结果,可以看见多个选项,选择Visualize tree,新窗口里可以看到图形模式的决策树。建议把这个新窗口最大化,然后点右键,选“Fit to screen”,可以把这个树看清楚些。先运行一个结果解释其中一些内容,如图所示:
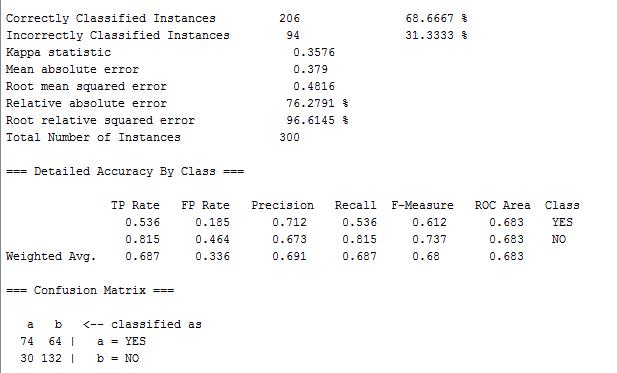
第一行的Correctly Classified Instances表示当前参与分类的实例中被正确分类的实例数目,第二行Incorrectly Classified Instances表示未被正确分类的实例数目。
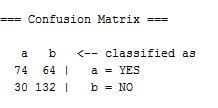
关于Confusion Matrix,解释如下:
原本“pep”是“YES”的实例,有74个被正确的预测为“YES”,有64个错误的预测成了“NO”;原本“pep”是“NO”的实例,有30个被错误的预测为“YES”,有132个正确的预测成了“NO”。74+64+30+132 = 300是实例总数,而(74+132)/300 = 0.68667正好是正确分类的实例所占比例。这个矩阵对角线上的数字越大,说明预测得越好。
更多选项及解释内容参见:
Cluster(聚簇分析)
聚簇分析的原理就是将为标定类的数据根据其相似性分为几个类,在同一类中的 数据元组具有较强的相似性,而在不同类中的数据元组则没有相似性或者很弱。
现对其主要界面说明如下:
Clusterer
单击choose,在这里可以选择适当的聚簇算法,选择后该算法会出现在choose左边的文本框中,在单击弹出的菜单可以对参数进行设定。同时在选择more或者capabilities选项可以查看每种设定表示的具体信息和该算法的适用范围(包括适用的数据类型信息等)。
Cluster mode
Cluster Mode一栏用来决定依据什么来聚类以及如何评价聚类的结果。前三个选项和分类的情形是一样的:Use training set、Supplied test set 和Percentage split区别在于现在的数据是要聚集到某个类中,而不是预测为某个指定的类别。第四个模式,Classes to clusters evaluation,是要比较所得到的聚类与在数据中预先给出的类别吻合得怎样。和Classify面板一样,下方的下拉框是用来选择作为类别
的属性的。在 Cluster mode 之外,有一个Store clusters for visualization的勾选框,该框决定了在训练完算法后可否对数据进行可视化。
设定按start开始进行,注意在其上方的可以允许我们忽略某些属性。
Result list
与前面的情形一样,该栏对结果进行顺序显示。右击每一项弹出选择菜单:如,Visualize cluster assignments和Visualize tree。后者在它不可用时会变灰。
Clusterer output
显示聚簇分析的结果。
3、J48所做的主要操作
(1) 需要调整数据的格式(可以先在matlab中将数据转换为CSV格式的数据,然后再用explorer中的编辑将数据save为arff格式的数据)
(2) 在classification中选择好模型,并选择合适的参数
(3) 将结果存储,或者做评估。





以上是关于机器学习:WEKA的应用之 J48(C4.5)的主要内容,如果未能解决你的问题,请参考以下文章
如何使用 Weka API 在 J48 / C4.5 上进行 10 倍交叉验证后保存最佳树
weka中用J48(即C4.5)算法对数据集进行训练建模与测试,结果不是很理想,