深度粗排在天猫新品中的实践
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度粗排在天猫新品中的实践相关的知识,希望对你有一定的参考价值。

本文主要阐述2021年天猫新品算法团队在深度粗排上关键的优化过程与结果。
背景
电商领域推荐业务从海量的商品底池中为用户推荐其最感兴趣的少量商品,整个过程时间一般需要在300ms以内。较为常用的推荐链路包含召回、粗排、精排、重排等主要阶段,每个阶段的商品量级逐级递减,以天猫新品频道页为例,其中召回阶段需要从完整商品池中根据用户偏好得到用户可能感兴趣的近万个商品,粗排阶段需要对其进行高性能的打分排序、截断5k个,精排需要对粗排后top600个商品进行计算最终用户偏好分,重排阶段对精排打分后的top20进行多目标重排。整体链路中,每个阶段都依赖着上游阶段的输出结果作为当前阶段建模的候选集,如粗排阶段决定了最终精排打分的上限,而粗排阶段作为召回后第一个模型打分阶段,待打分商品量级较大,一般情况下无法直接使用精排大模型进行复用,需要在算力约束的前提下尽可能高效地打尽可能多的商品,以帮助精排在全集空间下尽可能的挑选出相对较优的候选集。

▐ 粗排与精排阶段的差异
待打分数量不同
粗排需要对上千上万个商品进行高效打分,模型一般不能过于复杂,推理耗时要求较低
精排仅需对上百个商品进行打分,模型一般相对较大,推理耗时可以相对较高
模型结构不同
由于待打分数量不同,导致粗排性能要求较高。在召回引擎BE的优化下, 粗排一般采用双塔结构,如DSSM,user tower和item tower在最终上层决策层进行高效交互计算,如内积等形式,且模型中user tower和item tower无法在底层进行直接的显式交叉
精排一般采用复杂模型的思路,超长序列建模、特征交叉与增强等,如 SIM[4]等,且已被验证有效的用户和商品交叉特征在模型底层即可进行
样本空间不同
粗排待打分候选集较大,主要结合用户历史兴趣点在业务商品总底池的多路召回的结果,理论上应远大于点击曝光日志中的样本空间
精排待打分候选集来自于粗排打分倒排截断后的结果,空间相对较小,且存在一定的选择偏差影响
▐ 粗排优化过程
最早的时候我们会使用离线静态分作为规则对召回到的候选集进行截断,一般I2I是trigger_score*i2i_score*offline_ctr_score,X2I是trigger_score*offline_ctr_score;后期会训练一个gbdt作为粗排模型进行打分,特点是模型结构简单,特征少,线上rt低,但精度较低;再后期召回引擎BE2.0以及之前的版本支持部署深度模型,我们便尝试了深度粗排模型,使用了单塔WDL模型,线上ab效果相较于gbdt有所提升,但rt明显增高,无法进一步精细化模型结果或者增加特征,同时也没法全量;当时也有团队使用DSSM双塔版本的粗排模型,通过内积计算相似度简单高效,且item塔中间结果可以提前离线产出部署至召回引擎BE,user塔在线预测部分部署RTP,预测效率较高,模型可以设计相对复杂,但与此同时,这种使用方式由于两个平台独立部署会存在一个严重的版本不一致的问题,很难维持线上得到的 userembedding 和 item embedding的版本一致性。最后,得益于召回引擎BE3.0合图版本的升级与开放使用,我们也迎来了解法。BE3.0将原先一个粗排模型需要分别将 user tower 和 item tower 部署在两个不同的平台,转变为一个粗排模型仅需在 BE 内部部署,且模型构建完成后会根据配置自动进行O2O 优化(Offline2Online),提前生成好 item tower 结果后才会将服务状态切换至 online 可服务状态,此时新的请求访问 BE 时使用当前版本模型预测得到 user tower 结果,再直接读取当前版本模型离线产出的 item tower 结果执行剩余图的计算,天然地解决了版本一致性的问题。
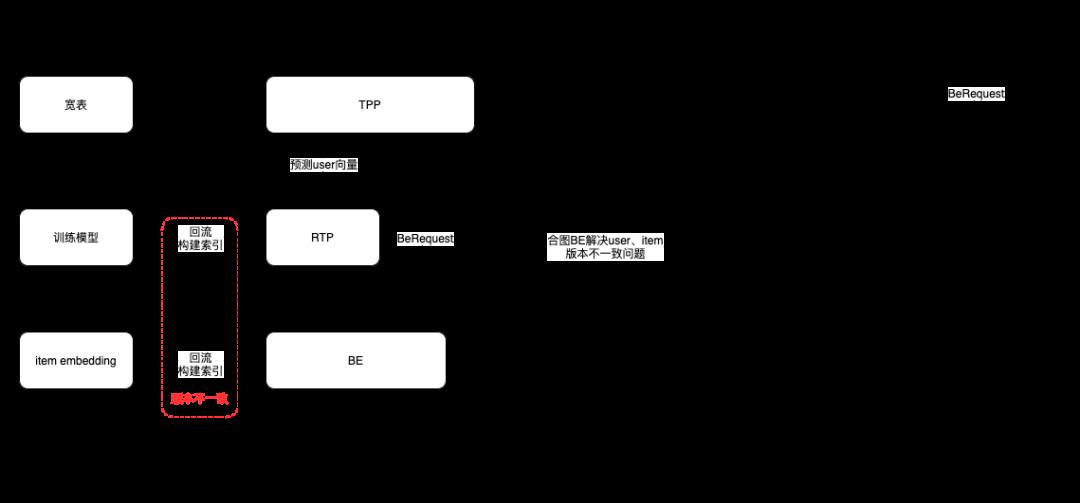
粗排模型优化-user attention interaction dssm
在BE合图版本中,我们第一步尝试的是base dssm模型,模型结构如下:
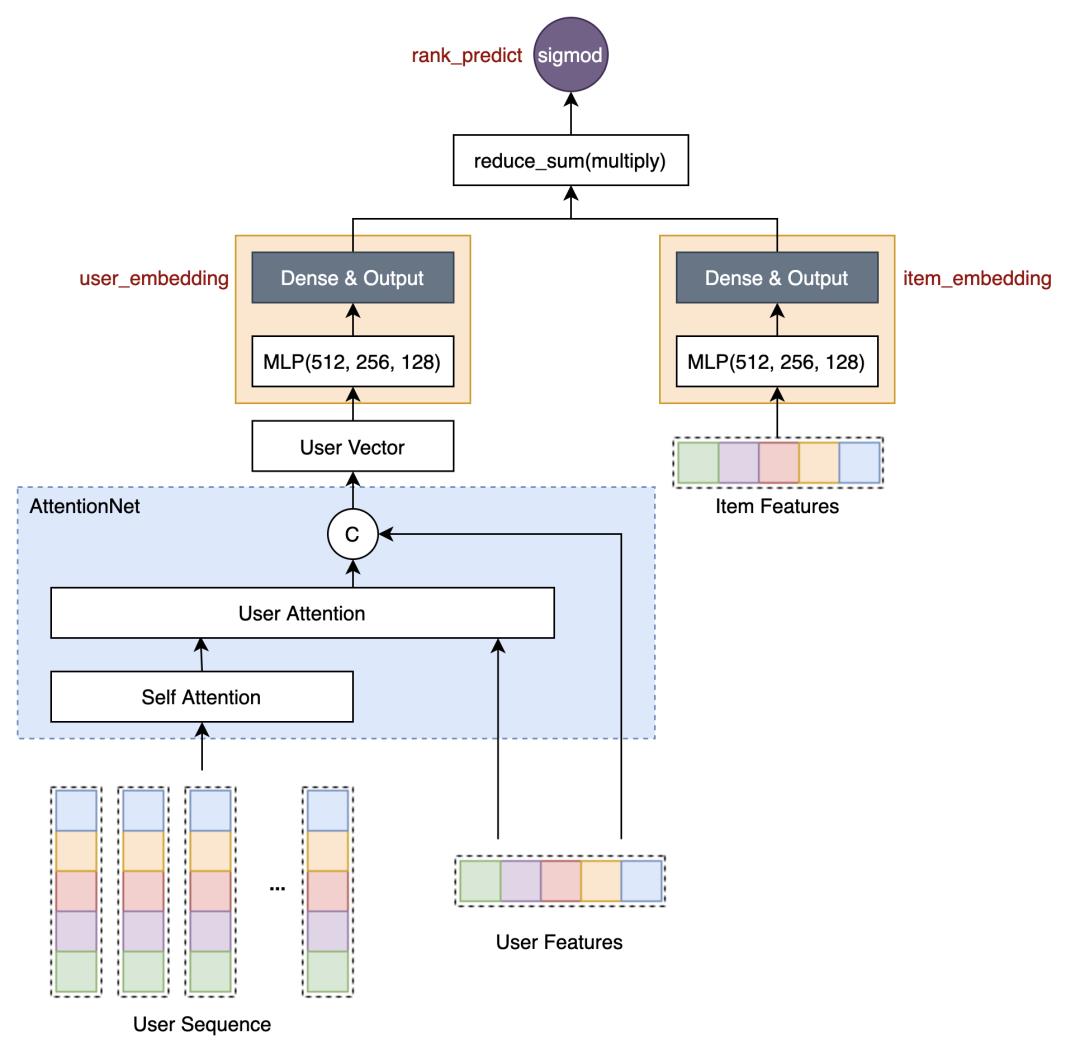
与线上精排模型对比,去掉了交叉特征、context特征,以及使用self attention+user attention替代了target attention,其主要结构如下:
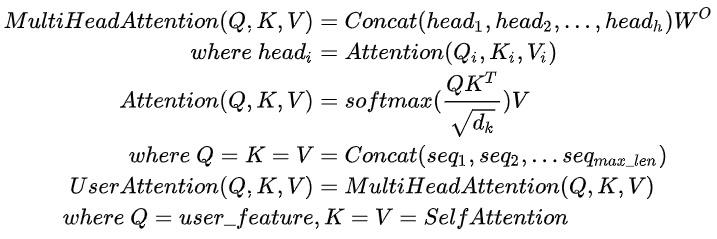
该模块先对用户序列特征进行self_attention,在对user feature做target attention,最终和user feature concat在一起后过MLP得到user embedding;item embedding直接根据item feature过MLP得到;整体loss采用交叉熵
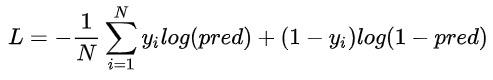
合图版本模型相较于原有的tf savedmodel形式效率大大提高,之前的版本线上有提升但是由于性能导致无法全量,而合图版本线上rt上涨不多,且效率上有明显的提升,与gbdt桶进行对比
线上效果:uctr+1.41%,pctr+3.54%,浏览深度+0.45%,点击次数+4.00%,点击用户平均点击次数+2.56%
▐ 粗排模型优化- 两阶段蒸馏
由于base dssm 在离线 GAUC 上仍和精排模型有一定的差距,且由于粗排阶段的 rt 约束,不能往大模型、复杂建模的角度优化,故我们在base dssm的基础上引入精排模型对粗排进行蒸馏优化。
目前模型蒸馏的方式较多[3],从蒸馏阶段上主要可分为
两阶段蒸馏:蒸馏时主要增益信息来自于预先训练好的teacher模型,后续蒸馏时teacher不继续更新,该方法利用线上已有的精排模型产出融合了 dark knowledge 的soft_label供粗排模型学习,无需新增模型参数,也不会增加训练成本。集团中暂无尝试,本文进行了粗浅地探索。
同步蒸馏:蒸馏时主要增益信息来自于与student模型同时训练的teacher模型,teacher模型往往可以采用更为有效复杂的建模结构或能使用 student 无法直接使用的优势特征。该方式也是目前集团对于粗排蒸馏主要采用的方式。
我们首先采用的是两阶段蒸馏的方式,实现成本较低。两阶段蒸馏的方式是精排模型正常训练,对日志预测一个分数作为soft_label,而粗排学习根据soft_label学习distill_loss。同时,粗排模型由于无法显示使用交叉特征,而交叉特征已经在精排模型被验证为是很有效的,我们也转换一种方式引入至粗排模型,其结构如下:
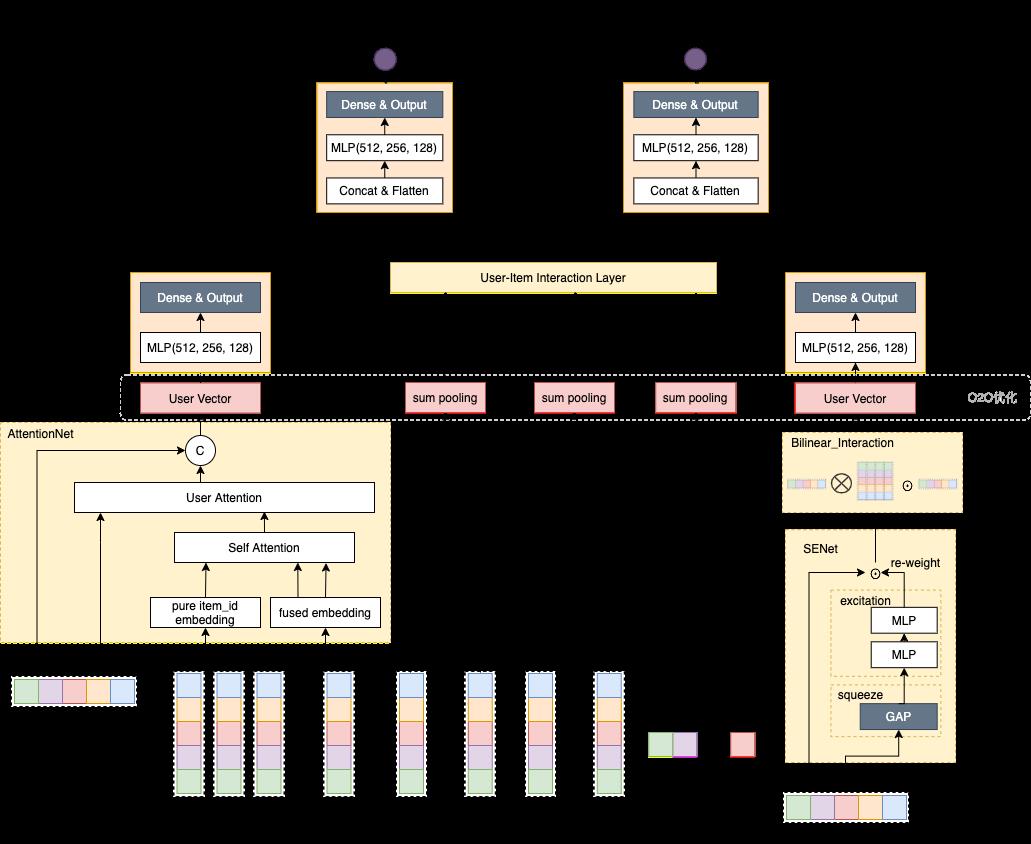
主要改进点如下:
两阶段多目标label蒸馏。引入精排打分,并使用多任务的方式分别学习soft_label以及hard_label,学习精度更高的精排模型
引入低成本特征交叉层。显式地对用户行为序列以及target Item feature进行一定程度的交叉
优化user tower。通过NOVA attention对用户行为序列的self attention进行去噪优化
优化item tower。通过SENET+Bilinear模块对item tower 进行特征筛选以及特征交叉优化
将顶层点积模块替换成MLP结构,提升表达能力。
两阶段多目标label蒸馏(distill)
hard_label指曝光点击日志中用户的实际行为,点击则为1,没有点击则为0。但事实上用户没有发生点击行为并不代表用户完全不感兴趣,而teacher对这部分曝光未点击样本预测得到的soft_label相比于hard label带有更多的信息以及更合理的分布,便于student model学习,以提升student model的泛化效果。Loss构建如下:
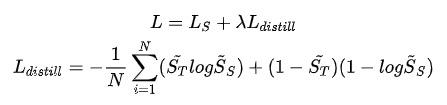
同时,我们在两阶段蒸馏框架下对粗排模型通过多目标的方式对 以及
以及 分开学习,因为我们认为hard_label和soft_label涵盖的信息丰富度是不一样的,学习难度也是不一样的,对于不同的任务应该使用独立的模块分别建模学习,避免相互干扰,最终权重融合至
分开学习,因为我们认为hard_label和soft_label涵盖的信息丰富度是不一样的,学习难度也是不一样的,对于不同的任务应该使用独立的模块分别建模学习,避免相互干扰,最终权重融合至 中。
中。
低成本特征交叉层(FM)
主要思想是在粗排上使用已被验证有用的user-item交叉特征部分,且满足合图BE分离式部署的特性,便于部署。定义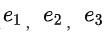 为用户的行为序列
为用户的行为序列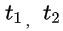 为target商品特征,基于FM的交叉公式如下:
为target商品特征,基于FM的交叉公式如下:
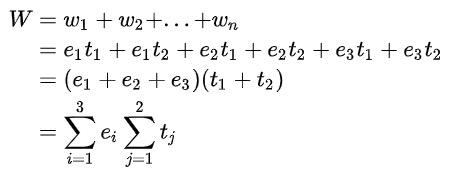
且整体用户侧的表征和target item侧的表征可以等价于sum pooling的结果,相较于target attention的逐项交叉方式计算量大大降低
user tower 优化(NOVA)
受到Non-invasive Self-attention for Side Information Fusion in Sequential Recommendation文章的启发[1],目前user sequence中使用的特征是item_id+cate_id+cate_level1_id+brand_id+seller_id+time,每一个特征都拥有不同维度的embedding,使用的方式是将embedding直接concat起来得到一个fusion表达,该表达在引入了side infomation的同时也不可避免的引入了一定的噪声,比如用户点击一个商品,对 cate_id是一定有偏好的,但是对对应的seller_id并不一定有偏好。但现有后验经验告诉我们side infomation也是非常有用,可以提供额外的信息,且能够一定程度上缓解SSB的问题,对建模是有所帮助的。对于这种带有噪声数据的 side infomation,Non-invasive attention 的优化方式可以很好的取其精华去其糟粕,其主要思想是针对self attention结构中,将V从fusion embedding的方式转为仅保留target info(item_id embedding)的方式,实现也非常方便。公式如下
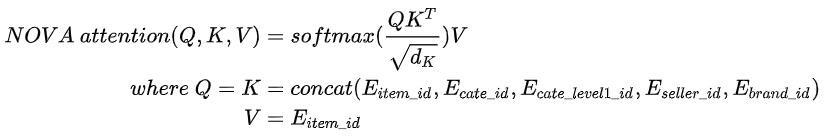
主要贡献在于Q、K依旧是融合了side info的fusion embedding,而V更换成了仅保留item_id的embedding,从公式上也可以看出,attention weight仍旧根据fusion embedding计算得到,而最终被加权的V是item_id本身,不进行融合的embedding数据,这样能够使得该部分self attention既能够通过side info增加信息,又能够一定程度上去噪,使得self attention更加准确。
item tower 优化(FIBI)
item tower 侧会在BE3.0合图版中预先进行O2O优化,离线先计算好item embedding 并构建索引,也就是说线上请求BE时不需要进行该部分的计算,item tower一定程度上可以相对复杂,而目前 item tower 纯MLP的建模方式无法合理地对众多带有场域性特色的数据,如手淘global 统计特征和业务场域内 local 统计特征等,故引入了SENET+Bilinear interaction模块针对 item tower 侧的特征进行特征筛选及特征交叉,主要参考FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction[2],包括一下两部分:
SE-NET 该模块使用squeeze(
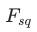 )&Excitation(
)&Excitation(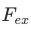 )两阶段做特征抽取,其不重要的特征将通过relu都置为0,后reweight得到新的embedding。
)两阶段做特征抽取,其不重要的特征将通过relu都置为0,后reweight得到新的embedding。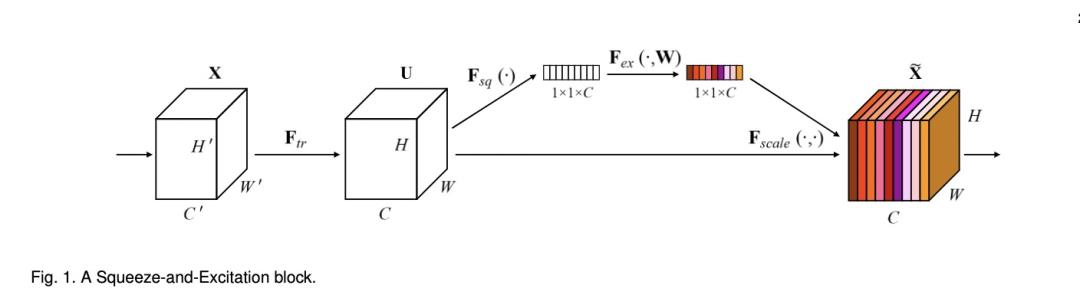
Bilinear-Interaction 该模块使用一种引入权重的特征交叉方式,相比于内积以及element-wise乘积的方式能更好地捕捉到特征交互信息。
inner product: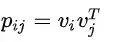
hadamard product: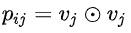
Bilinear product: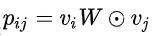
其中有三种交叉方式:
Field-All:所有特征交叉共享一个权重矩阵
Field-Each:单个特征和其他特征交叉时共享权重
Field-Interaction:两两交叉特征拥有单独权重,不共享
离线实验
有关bilinear interaction部分,目前只离线尝试all\\each的方式,interaction的方式内存需求太大且训练时间较长;其中each模式中由于user侧、item分开交叉,线上rt上升较高,故仅保留item侧特征交叉模块;蒸馏温度最终调参为3效果最佳。
模型 | GAUC提升 |
base | |
base+MLP | +1‰ |
base+MLP+FM | +6‰ |
base+MLP+FM+distill | +30‰(推全) |
模型 | GAUC提升 |
base | |
base+nova | +10‰ |
base+senet | +10‰ |
base+nova+senet+fibi_all | +8‰ |
base+nova+senet+fibi_each | +13‰ |
base+multi_task | +16‰ |
base+multi_task+nova+senet+fibi_each | +19‰(推全) |
线上实验
我们上线了蒸馏温度=3的两阶段蒸馏+user-item tower优化模型+多任务粗排模型,线上打分使用student塔输出的logits,其线上效果分别如下
两阶段蒸馏+低成本交叉:uctr+3.23%,pctr+1.78%,浏览深度+2.14%,点击次数+3.96%(先推全)
多目标+user、item tower优化:uctr+2.61%,pctr+0.70%,浏览深度+2.00%,点击次数+2.83%
蒸馏优化
两阶段蒸馏的方式实现成本小,但主要收益仅来自于soft_label,无法从teacher模型学到更多的信息,故使用同步蒸馏的方式即将teacher model和student model融合成一个model进行优化。与两阶段蒸馏不同的是
teacher使用交叉特征,student学习优势特征带来的增益信息
student底层embedding与teacher共享,能够很好地辅助student model学习
teacher可以指导student模型中较为重要的部分网络学习
每个step中,精排模型输出的logits供student模型作为soft_label进行学习,soft_label蒸馏
由于目前粗排分和精排分分布差距较大,故student model也通过计算kl散度学习teacher model的分数分布
网络结构如下:
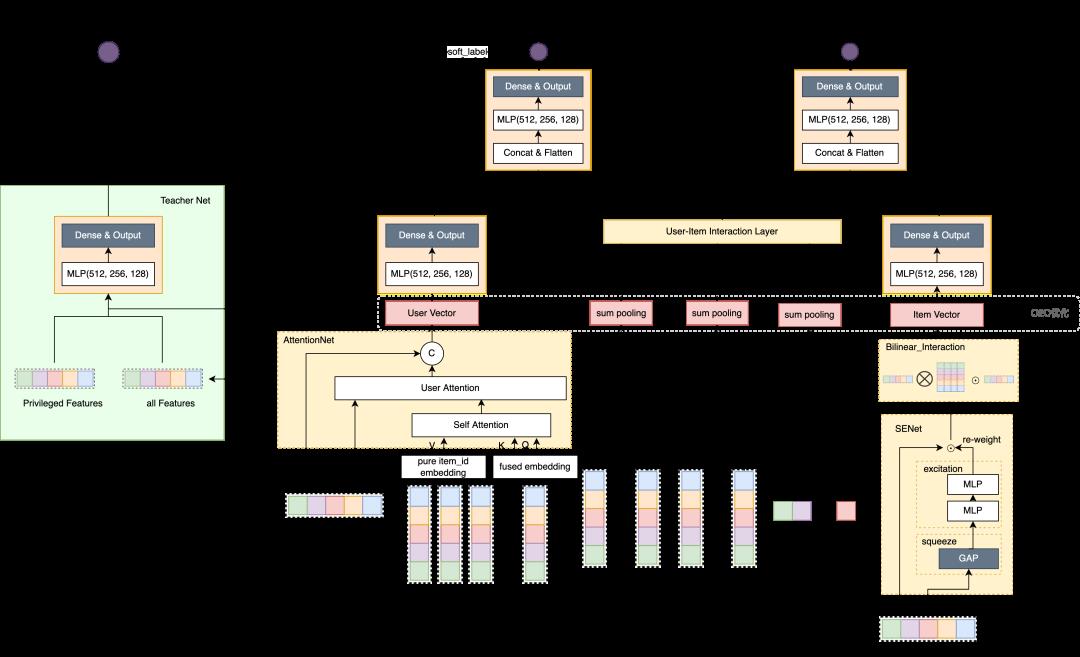
整体loss如下:
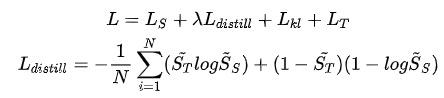
▐ 离线实验
模型 | GAUC提升 |
base | |
sync_distill | -2‰ |
sync_distill+indep | -6‰ |
sync_distill+stop_user_grad | +8‰ |
sync_distill+user_attention | +12‰(推全) |
sync_distill+stop_user_grad+user_attention | +11‰ |
离线对比了
sync_distill:同步蒸馏
sync_distill+indep:底层不共享,上层不产生任何交互
sync_distill+stop_user_grad:同步蒸馏+禁止student更新底层embedding
sync_distill+user_attention:同步蒸馏+使teacher更新user attention网络参数
sync_distill+stop_user_grad+user_attention:同步蒸馏+禁止student更新底层embedding+teacher更新student网络参数
从结果上分析,得到结论如下:
底层不共享使得效果大大下降
禁止student更新底层参数相比于单一同步蒸馏的有提升。主要是因为单一的共享底层时不让student更新底层embedding可以更好地使用teacher反向传播的结果,带来了一定的增益
同步蒸馏+teacher更新user attention网络参数效果最佳,该基础上使student禁止更新底层会有微弱的下降。主要增益还是来自于teacher指导了student的部分网络,而不让student更新底层会导致student受到了teacher的部分指导,但自身学习能力无法跟进这种指导,导致student上层网络无法和底层embedding很好地配合,使得模型天花板相对较低一些
▐ 线上效果
大盘:uctr+1.86%,pctr+1.68%,浏览深度+1.83%,点击次数+3.48%,点击用户平均点击次数+1.56%,人均曝光类目+3.10%,人均点击新类目数+3.58%
心智用户:uctr+1.52%,pctr+2.19%,浏览深度+3.11%,点击次数+5.33%,点击用户平均点击次数+3.93%,人均曝光类目数+2.44%,人均点击新类目数+4.20%
▐ 离线实验
模型 | GAUC提升 |
base | |
base+kl_loss+distill_loss | -2‰ |
base+only_kl_loss | +0.5‰ |
soft_label分布蒸馏在上述同步蒸馏模型推全后也补充了实验。就离线评测上来看,加入kl_loss学习分布并没有明显的提升,且如果直接在现有distill_loss基础上加入kl_loss还会下降。但上线后捞取线上打分实际分布,如下图所示,实验桶的粗排分与精排分的分布相较于基准桶的确更为相近,线上效果也的确更为优异。
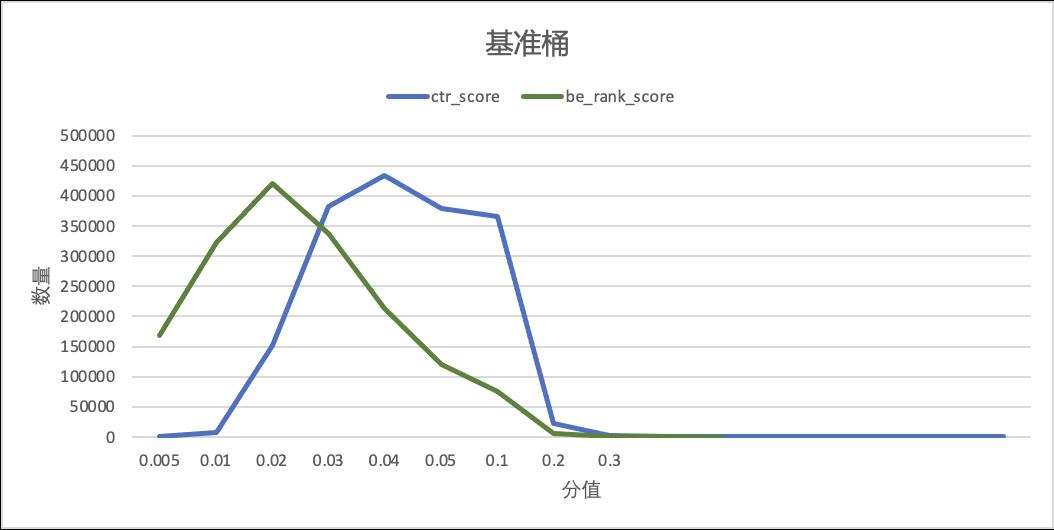
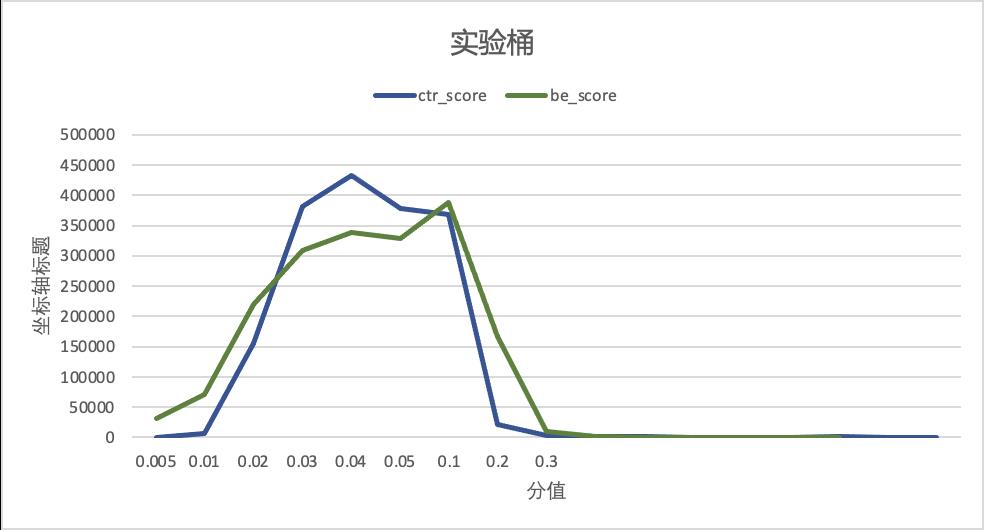
▐ 线上效果
大盘:uctr+0.57%,pctr+1.24%,浏览深度+0.66%,点击次数+1.87%
心智用户:uctr+2.13%,pctr-4.63%,浏览深度+3.76%,点击次数-0.99%
总结与展望
本文主要阐述2021年天猫新品算法团队在深度粗排上关键的优化过程与结果。在平衡模型打分效率与效果的前提下,我们基于基础的 dssm 双塔模型的基础上引入蒸馏的方式,通过使用精排大模型输出 soft_label 进行了低成本的两阶段蒸馏与更为精细的优势特征同步蒸馏的优化。优化过程中结合了 NOVA attention 、SENET+Bilinear Interaction 对双塔 user tower 和 item tower 分别进行了更为细致且低成本的优化,同时对如何更好地使用 teacher model 输出的 dark knowledge进行多方面蒸馏进行了探索,在优势特征蒸馏的基础上拟合 soft_label 的值与分布,进一步提高粗排模型的精度的同时也提高粗排精排模型打分分布一致性,提升离线与在线的关键指标。
但对于粗排优化而言,目前也存在一个比较明显且关键的问题,即粗排的优化目标与评价指标是什么?由于粗排的打分空间是全商品底池范围,而线上日志是用户对精排重排结果的一个显式反馈,粗排目前仅使用线上的曝光点击日志会使得模型的选择偏差更严重,线上的马太效应更大。目前有部分探索尝试加入精排打过分但未透出的样本或者直接对底池进行负采样的样本用于扩展粗排模型的学习空间、提高模型的泛化能力,但在目前的推荐范式下最终仍缺少一个客观的评价指标对此进行指导优化,该问题是深入优化的关键问题,目前仍是浅尝辄止。道阻且长,行则将至。
致谢
深度粗排模型能够持续迭代并在业务上取得正向提升离不开贤路师兄的支持与指导;同时也感谢智能场景小组以及每平每屋算法小组各位同学日常中的探讨与交流。
参考文献
Liu, Chang, et al. "Non-invasive Self-attention for Side Information Fusion in Sequential Recommendation." arXiv preprint arXiv:2103.03578 (2021).
Huang, Tongwen, Zhiqi Zhang, and Junlin Zhang. "FiBiNET: combining feature importance and bilinear feature interaction for click-through rate prediction." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
Gou, Jianping, et al. "Knowledge distillation: A survey." International Journal of Computer Vision 129.6 (2021): 1789-1819.
Pi Q, Zhou G, Zhang Y, et al. Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020: 2685-2692.
团队介绍
大淘宝技术-行业算法团队
行业算法团队主要服务于淘宝、天猫、闲鱼和每平每屋等业务线的数十个业务场景,提供线上零售、内容社区、场景导购等数据和算法服务。我们通过机器学习、强化学习、数据挖掘、机器视觉、NLP、运筹学、搜索和推荐算法,为千万商家寻找商机,为平台运营提供智能化方案,为用户提高使用体验,从而促进平台和生态的供给繁荣和用户增长,不断拓展商业边界。
这是一支快速成长中的学习型团队,真诚邀请海内外相关方向的优秀人才加入我们,在这里成长并贡献才智。
如果您有兴趣可将简历发至shiqing.zsh@alibaba-inc.com,期待您的加入!
✿ 拓展阅读


作者|世卿
编辑|橙子君


以上是关于深度粗排在天猫新品中的实践的主要内容,如果未能解决你的问题,请参考以下文章