深度粗排模型的GMV优化实践:基于全空间-子空间联合建模的蒸馏校准模型
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度粗排模型的GMV优化实践:基于全空间-子空间联合建模的蒸馏校准模型相关的知识,希望对你有一定的参考价值。

随着业务的不断发展,粗排模型在整个系统链路中变得越来越重要,能够显著提升线上效果。本文是对粗排模型优化的阶段性总结。
背景
在搜索、推荐、广告等大规模信息检索场景中,通常会将检索分为召回、粗排、精排三个阶段,每个阶段处理的数据量和目标各有不同。召回阶段,一般由多路召回构成,需要从海量候选集中尽可能全地找到与当前请求相关的集合;精排阶段,由结构复杂的模型构成,需要在数据规模相对小的集合上做精细化打分,给出最终展示给用户的排序列表。对于粗排阶段来说,在整个系统链路中处于中间环节,处理的数据量与模型复杂度也介于召回与精排之间。在业务规模不大时,粗排阶段往往会被弱化,比如使用召回阶段的分数来对召回集合做截断,就是一种最简化的粗排。随着业务的不断发展,粗排阶段会变得越来越重要,如何更好地融合多路召回的结果、如何为精排提供更有效的集合,是粗排模型需要解决的问题。
我们的场景是一个典型的多阶段检索系统。召回阶段,由多路召回构成,每个query需要从数亿量级的商品池中,召回10万量级的候选集;粗排阶段,由离线模型分或双塔内积模型构成,需要从10万量级的召回集合中筛选出1万量级提供给精排;精排阶段,由多层模型构成,结合业务规则,在粗排集合中进一步筛选出每页10个商品提供给用户。相对于海量的召回集合来说,最终只有少量商品有曝光机会,得到用户的点击、成交反馈。
淘宝应用场景
我们在优化过程中发现单独优化粗排模型,不考虑与精排模型或策略的联动,不一定能达到全局GMV最优的目标。在现阶段我们认为,粗排保持与精排目标的一致性,是提升线上效果的有效策略。粗排的打分量在10万量级,精排的打分量在1万量级,如果将精排模型直接下沉到粗排,会有比较大的性能问题。在严苛的性能要求下,粗排阶段一般会采用双塔内积模型,对海量item提前计算好item塔,对一个query只计算一次user+query塔,通过向量内积计算出排序分数,能显著提高性能,这也是粗排base模型。由于精排是由多层模型构成,也是在不断优化中的,就需要有方法能及时吸收到精排的知识,同时尽量把粗排模型优化与精排模型优化解耦开。由此,我们提出了基于精排模型的蒸馏校准模型,能够以比较小的成本达到这个目的。
在粗排阶段,模型预估出ctr和cvr后,如何组合ctr、cvr、price也是影响效果的关键因素。通常来说,会对ctr和cvr分别校准,再将ctr*cvr与price组合得到最终排序分数。在这里能发现,更本质的需求是预估校准后的ctcvr。我们基于蒸馏校准模型,引入了全空间建模的思路,并在现有的子空间建模的框架下进行了改进,以全空间-子空间联合建模的方式直接预估出蒸馏校准后的ctcvr。在新模型中,如何平衡ctr任务与ctcvr任务是一个需要解决的问题,我们采用了冲突梯度投影算法,并结合应用场景,做了适配与改进。
在我们的场景中,GMV是核心的线上指标,通过粗排模型的迭代,取得了整桶GMV提升1%的线上效果。
蒸馏校准模型
接下来介绍粗排模型的迭代,首先从蒸馏校准模型开始。设计这个模型的出发点有两个,一是吸收精排的知识,同时尽量把粗排模型优化与精排模型优化解耦开,二是与精排分数对齐,模型在训练过程中进行校准。
▐ 蒸馏
通常来说,知识蒸馏[1, 2]在多分类情况下更常见,student模型可以从一个更有经验的teacher模型里学习到关于多分类的知识,比如label是手写数字“2”时,teacher模型对手写数字“7”的预测概率也会相对高一些,这是在label之外的信息。对于二分类来说,这种知识同样存在,比如label是1时,teacher模型的预测概率是0.6还是0.9,包含了不同的信息量。[3]指出,对于二分类,知识蒸馏的效果相当于用teacher模型的预测概率来做样本加权,可以加快收敛速度,达到更好的局部最优解,并提高泛化性。
▐ 校准
精排是由多层模型构成的,最后包含了校准模型,目的是将预测概率的范围对齐到真实概率,以便将ctr和cvr相乘。预测概率之所以会偏离真实概率,有两方面原因,一是参数量巨大的神经网络会做出过于自信的预测,[4, 5]指出知识蒸馏在这种情况下会起到校准的作用;二是训练过程中,对负样本有采样,在采样数据上训练模型,预测概率会显著偏离真实分布。对于这种情况,工业界一般采用概率变换[6]和保序回归[7]两种事后的校准方式。我们主要考虑第二种情况,为了对齐精排分数和更好的准度,采用了训练过程中的校准。
▐ 模型架构
具体看一下模型架构:
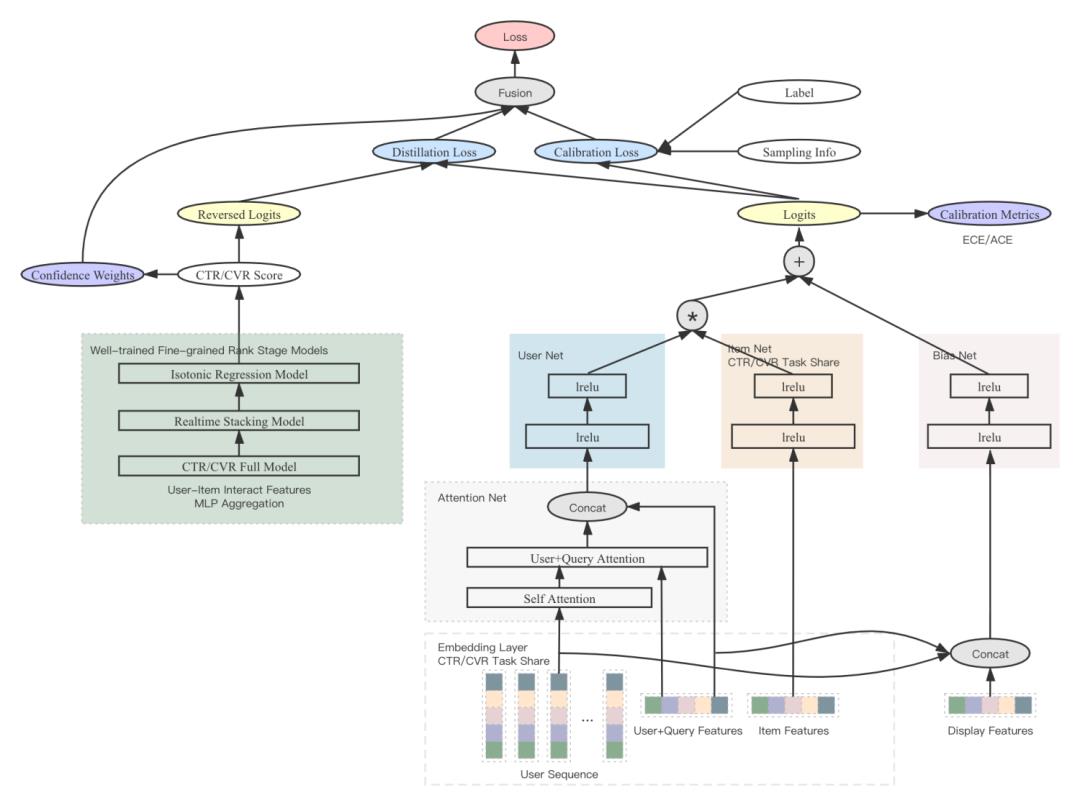
训练方式
采用ctr和cvr任务分别用独立数据源交替训练的方式,也就是对ctr和cvr在两个空间上分别建模,其中ctr的数据源是曝光样本,点击是正样本,未点击的负样本有采样;cvr的数据源是点击样本,成交是正样本。
模型结构
考虑到粗排场景的高性能要求,采用了双塔内积。ctr和cvr任务各自有独立的user net,共享item net,共享双塔底层的embedding层。user net由self attention和user+query attention构成的attention net来提取特征。在双塔内积之外,还有包含user、query、display特征的bias net来提高预估的准度。由于item net与user、query无关,可以提前计算好,模型在线上提供服务时,只需要对一个query计算一次user net和bias net,通过向量内积和加法计算出排序分数,能显著提高性能。
蒸馏
teacher模型:采用已经训练好的精排多层模型,指导粗排student模型的学习。精排模型的打分量比粗排模型小1~2个量级,相比粗排模型,精排模型包含了更多的特征以及在双塔内积架构下无法使用的user-item交叉特征和多层mlp。
反函数恢复logits:蒸馏需要获取精排网络的logits,但考虑到精排多层的异构情况,无法直接得到logits,我们采用sigmoid函数的反函数来从预测概率中恢复:
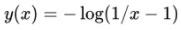 。需要注意的是,sigmoid函数的激活范围主要集中在[-10,10],对应到它的反函数就需要限定概率的范围,否则训练过程中会出现Nan。这个设计可以将粗排模型优化与精排模型优化解耦开,精排模型升级后,粗排模型仍然可以从中获得收益。
。需要注意的是,sigmoid函数的激活范围主要集中在[-10,10],对应到它的反函数就需要限定概率的范围,否则训练过程中会出现Nan。这个设计可以将粗排模型优化与精排模型优化解耦开,精排模型升级后,粗排模型仍然可以从中获得收益。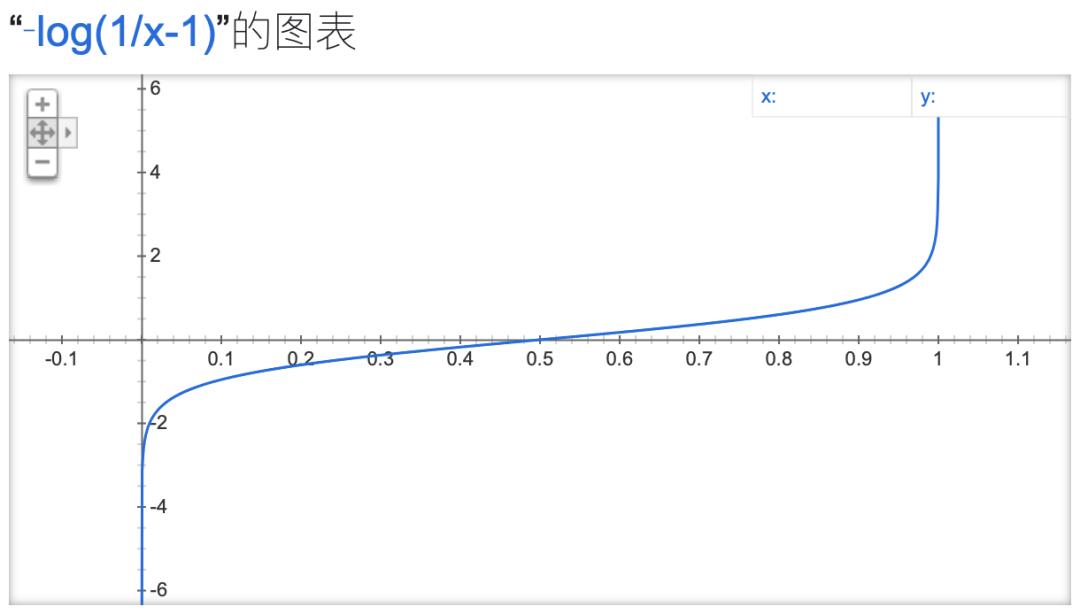
loss:得到从精排中恢复的logits后,记为rlogits,结合粗排网络里的logits,可以计算loss:
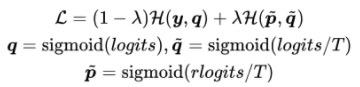
其中,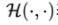 表示交叉熵,
表示交叉熵,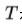 是蒸馏温度
是蒸馏温度
梯度平衡:用loss对logits求导,能发现loss中的第二项蒸馏loss的梯度与第一项相比,相差一个温度超参数T,如果不对蒸馏loss加权的话,梯度是失衡的,会影响收敛速度。这里我们对蒸馏loss乘以温度T,而不是[1, 3]中建议的T2,因为当T较大时,T2会过于增大蒸馏loss的梯度。
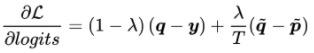
精排分数置信度:分析数据时发现,精排的分数处于不同区间范围时,对应区间上数据的auc会有所不同,特别在分数最低的一部分数据上auc最低,我们认为在这部分数据上精排的置信度比较低,这个置信度会反映到loss上进行权重调节。
校准
样本权重:假设ctr任务中负样本的采样率为r,在训练过程中可以对正负样本设置不同的权重,来将预测概率的分布恢复到采样前。只需要注意到采样前后似然项不变,就能推导出正负样本权重设置为r:1时,预测概率可以被校准回真实分布。在loss中,
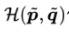 依赖精排校准后的概率,为了保持一致性,我们需要在训练过程中就进行校准,而不是事后校准。训练过程中的校准会通过loss驱动模型参数更新,比事后的无参数校准具有一定优势。
依赖精排校准后的概率,为了保持一致性,我们需要在训练过程中就进行校准,而不是事后校准。训练过程中的校准会通过loss驱动模型参数更新,比事后的无参数校准具有一定优势。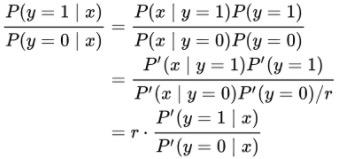
进一步,可以推导出与[6]中的事后校准一致的公式:
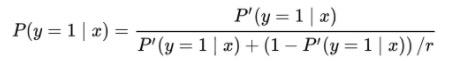
期望校准误差ECE:在训练过程中,我们采用[5]中的期望校准误差ECE来监控模型的校准程度。ECE的计算方式是:按照预测概率将样本分为M个区间,在每个区间上计算预测概率均值与真实概率的差值,将差值在M个区间上按照每个区间的样本数加权平均。因为一个batch内的样本数有限,为保证真实概率的置信度,这个指标需要像auc一样跨batch累计,并定期清空。
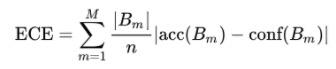
▐ 实验
我们以热启动的方式,用一周数据训练蒸馏校准模型。用来对比的base模型是在线上长期增量训练多年的双塔内积模型。
在调参过程中,我们发现对梯度平衡、精排分数置信度以及蒸馏温度的调节,都会提高收敛速度。能观察到温度越高,效果越好。经过多组实验,通过热启动的方式,只用一周数据训练,就得到了一个ctr/cvr auc比base模型提升0.2%的模型。
除auc的提升外,能观察到与base模型相比,期望校准误差ECE从13%下降到了0.1%。校准程度也可以通过Reliability Diagrams更加直观地看到:
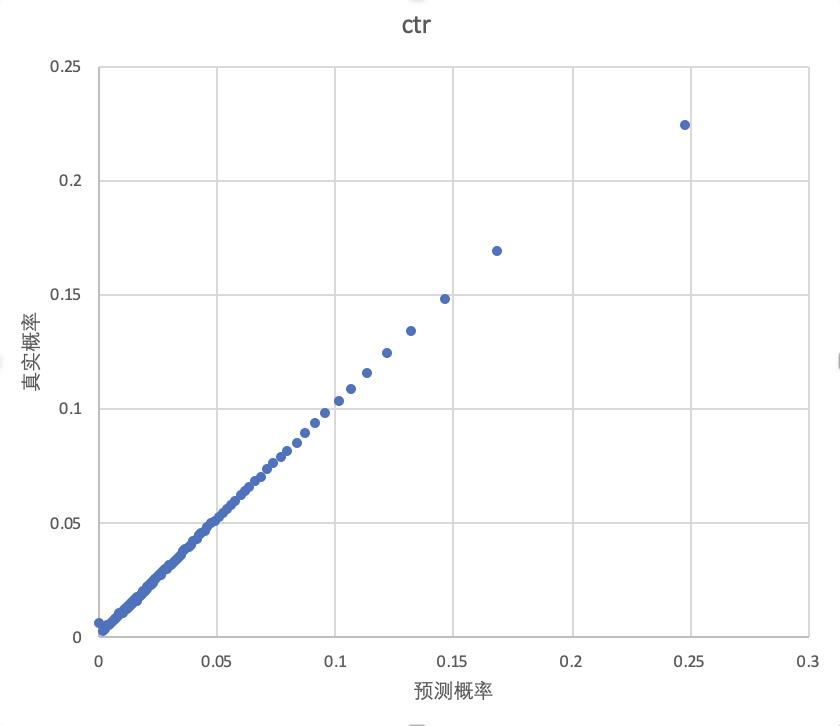
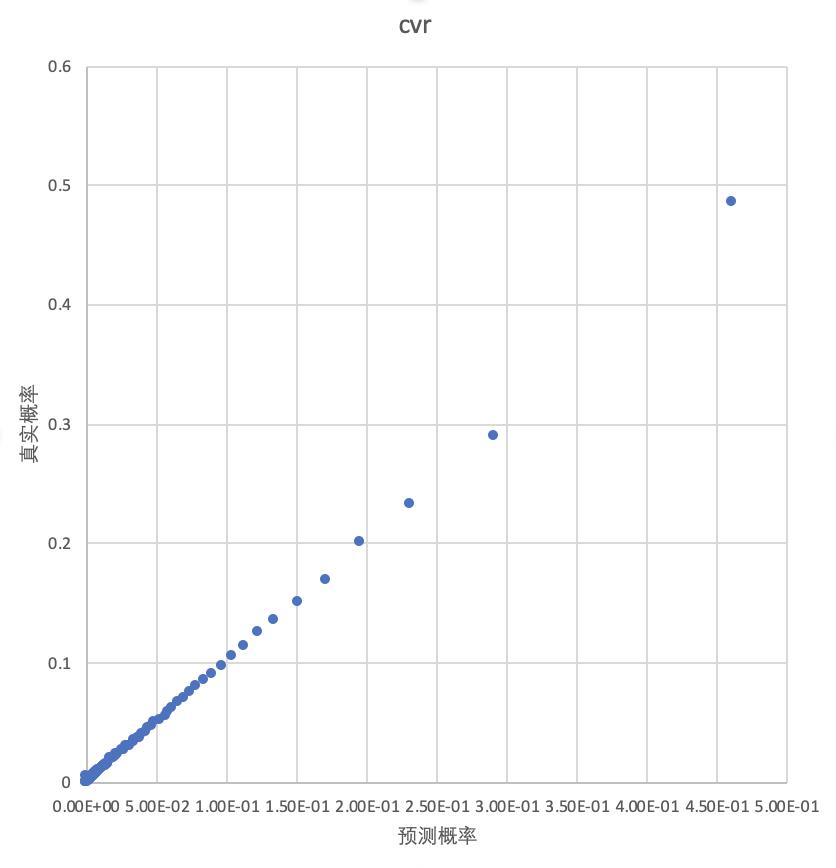
画Reliability Diagrams时,需要先按照预测概率将数据划分区间,为了使每个区间上真实概率的置信度更高,这里采用等频的划分方式,然后在每个区间上统计预测概率均值和真实概率。能看到校准后的曲线接近于y=x,意味着,在统计意义上预测概率接近真实概率。
全空间-子空间联合建模
蒸馏校准模型的训练方式是,对ctr和cvr任务分别用pv->click和click->pay两个独立数据源交替训练,也就是在两个空间上分别建模,其中click->pay是全空间pv->pay的子空间。对于一条pv样本来说,训练时模型没有同时对它打出ctr和cvr的分数,但这却是线上应用时的场景,也就是需要同时打出这两个分数再相乘。在这里,离线训练与在线预测存在bias。进一步,线上应用的本质是需要对pCTCVR做预估和校准。我们可以把全空间建模[8, 9]的思路引入到目前的子空间建模中,实现联合优化,直接对ctcvr任务建模。
▐ 引入全空间建模
对ESMM模型[8]来说,cvr任务是主任务,ctr和ctcvr任务是辅任务。通过pCTCVR=pCTR*pCVR的概率关系,在pv->click和pv->pay全空间上对ctr和ctcvr任务建模来得到pCVR。直接应用ESMM模型来建模pCTCVR会存在问题:pCTCVR由两个概率的乘积构成,它的准确性依赖pCTR和pCVR这两个概率,其中pCVR由原来的学习目标转变为新目标的中间环节,另外pv->pay全空间上的label也更稀疏。如何降低ctcvr任务的学习难度,是我们考虑的主要问题。我们从两方面来解决这个问题,一是利用上click->pay子空间上的label对pCVR进行学习,提高pCVR的准确性,二是对ctcvr任务引入蒸馏校准,增加除pv->pay的label之外的信息。由此,我们提出了全空间-子空间联合优化的蒸馏校准模型。
因为我们的模型本身是在pv->click和click->pay两个空间上学习的,可以用click->pay这个子空间上训练出来的cvr参数在pv样本上做预测,得到pCVR,进而得到全空间上的pCTCVR=pCTR*pCVR。同时,增加pv->pay全空间上的ctcvr学习任务,也可以更新click->pay子空间上的cvr参数。我们设计了如下的模型架构:
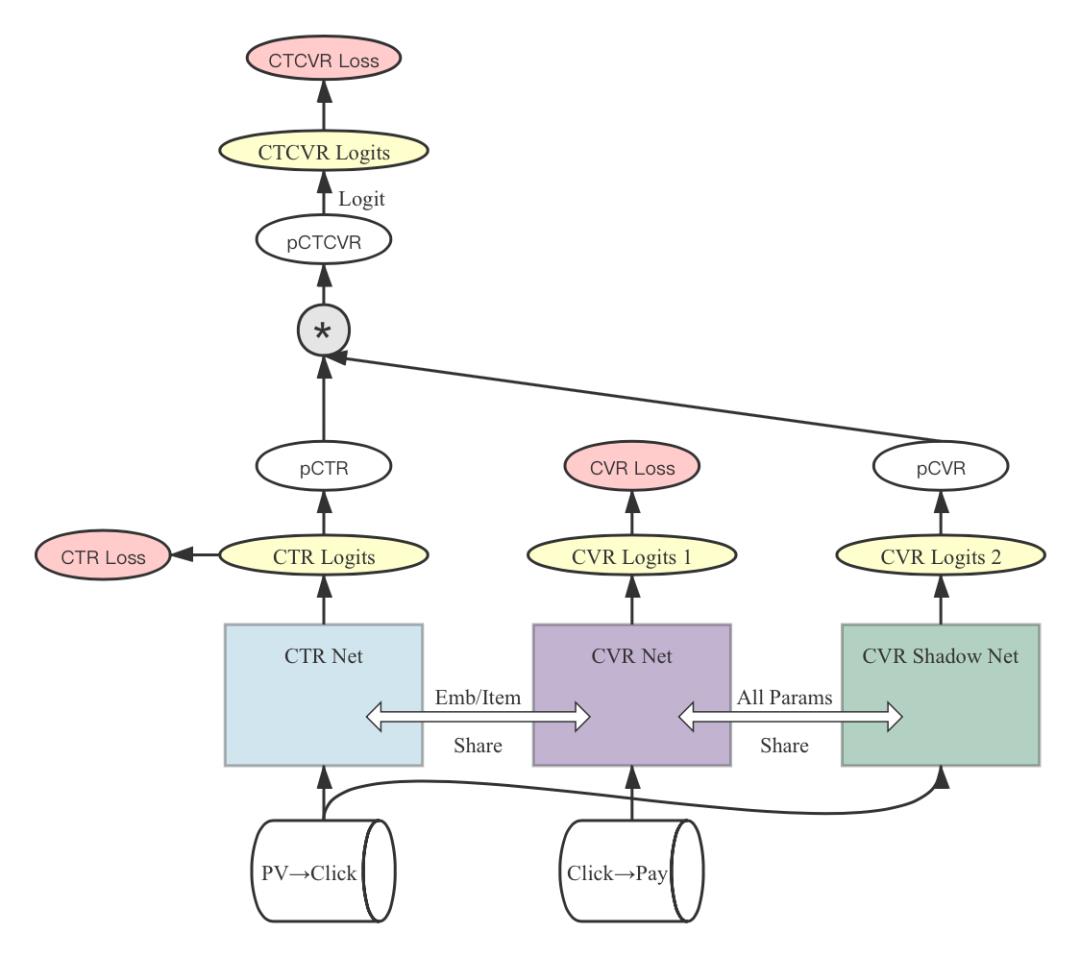
其中,ctr net和cvr net是蒸馏校准模型中的网络结构,各自有独立的数据源,共享embedding层和item塔。cvr shadow net不参与click->pay子空间上的训练过程,只是将cvr net的参数全部同步过来,在ctr net的同一条输入样本上预测出pCVR。在ctr net的训练过程中,包含ctr loss和ctcvr loss,ctcvr loss会通过cvr shadow net来更新cvr net的参数。在模型训练过程中,cvr shadow net起到了在全空间与子空间中交互信息的作用。
▐ 对ctcvr任务蒸馏校准
对pCTCVR应用sigmoid函数的反函数后,可以得到ctcvr logits。对于精排模型,同样将反函数应用到ctr和cvr分数的乘积,也可以得到相应的logits。这样一来,我们能够在原本稀疏的pv->pay的label之外通过蒸馏增加新的信息,来降低ctcvr任务的学习难度。
接下来,我们对ctcvr任务进行校准。假设pv->click的负样本采样率为r,click->pay没有负样本采样,那么pv->pay的负样本采样率可以推导出来:
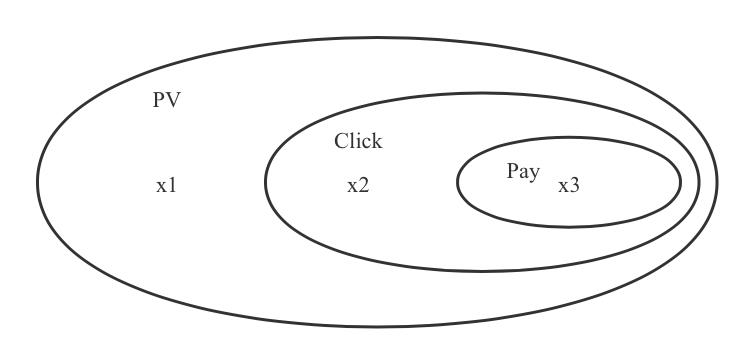
图中的x1、x2、x3互不相交,x1+x2+x3是采样后的整体pv数据,x3是ctcvr的正样本,x1+x2是采样后的ctcvr的负样本。所以,对ctcvr的负样本来说,采样率为:
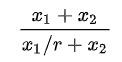
到这里,我们就可以用对ctr/cvr任务的类似处理方式,完成对ctcvr任务的蒸馏校准。
▐ 实验
我们以热启动的方式,用一周数据训练全空间-子空间联合优化模型,与蒸馏校准模型做对比。在我们的应用场景中,需要输出ctcvr,所以将ctcvr任务作为主任务,在ctr net训练时,将ctcvr loss的权重设置得比ctr loss更大。
通过手动调节多组不同的权重,我们得到了ctcvr auc提升0.14%,cvr auc提升0.37%的模型。能看到,全空间建模及蒸馏的引入,对ctcvr主任务是有益的,同时通过ctcvr loss驱动子空间上cvr参数的更新,对cvr任务也是有益的。
多任务平衡
我们观察到,对ctr loss和ctcvr loss设置不同的权重,会得到在指标上有不同侧重的模型。直觉上,手动设置权重除了调参成本比较高外,没有考虑到训练过程中不同任务的变化,对所有迭代都不加区分,存在改进的空间。在[10]中,通过对不同任务的不确定性建模来动态调节多任务权重。在[11, 12]中,通过动态调节权重,希望不同任务用相似的速度来学习,[11]在每次迭代中都需要计算额外的梯度,计算复杂度高,[12]则不需要,计算成本低。在[13, 14]中,采用了求pareto最优解的方式,找到多任务的平衡。
▐ 冲突梯度平衡
我们参考了[15],先对多任务的梯度判定是否冲突,再将冲突梯度向另一个梯度的正交方向做投影,能够使多任务在避免冲突的情况下学习。相对来说,解决问题的方法更直观,也可以与其他方法叠加。
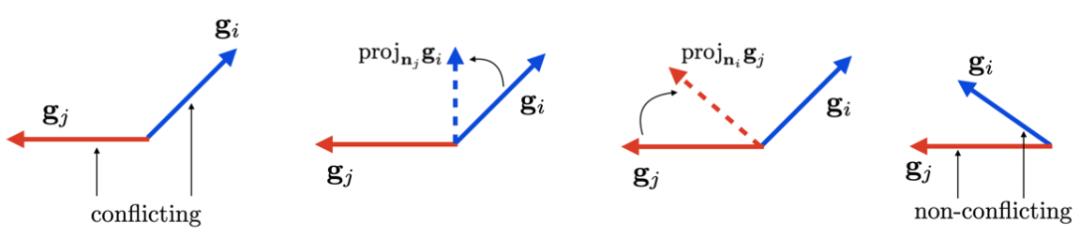

▐ 对PCGrad的适配与改进
在实现过程中,我们对算法做了一些针对应用场景的适配与改进:
在我们的模型中,embedding层非常巨大,个别特征的hash bucket size在亿级别,梯度更新时会对这个大型矩阵做局部处理。在PCGrad计算两个任务的梯度向量的内积时,需要单独对embedding矩阵的梯度做处理,否则会导致worker oom。
两个不冲突的高维梯度向量,在低维投影子空间里,可能是冲突的。比如,(1,1,1)和(-2,1,2)这两个向量的内积大于0,方向不冲突,但对于它们的子向量(1,1)和(-2,1)来说内积小于0,方向是冲突的。如果只看高维梯度向量,可能会错过对部分梯度的处理。所以,我们将高维向量切分成了多组低维子向量再判定是否冲突,在基本没有增加计算时间的情况下,提升了效果,同时降低了worker oom的可能性。
为了将模型朝着优化ctcvr的方向引导,我们也可以对ctcvr loss增加权重,让PCGrad算法来解决整体偏向ctcvr任务带来的梯度冲突。
▐ 实验
我们仍然以热启动的方式,用一周数据训练全空间-子空间联合优化模型,用PCGrad代替手工调节权重,与蒸馏校准模型做对比。由于将高维梯度向量切分为子向量对比不切分,能够将ctcvr auc提升0.1%,我们将切分作为默认设置。
PCGrad相比于手工调节权重得到的最优模型,ctcvr auc提升0.19%。为了将任务进一步向ctcvr引导,我们尝试了两种策略,第一种是只对embedding层变量提高ctcvr loss的权重,第二种是对全部变量提高ctcvr loss的权重。相比之下,第一种策略效果更好,对比不提高权重的模型,ctcvr auc提升0.15%。总的来说,经过PCGrad优化的全空间-子空间联合模型,相比于原始的蒸馏校准模型,ctcvr auc提升0.48%,cvr auc提升0.38%。
总结
在我们的场景中,随着业务的不断发展,粗排模型在整个系统链路中变得越来越重要。考虑到线上严苛的性能要求,我们在保持双塔内积架构的前提下,提出了蒸馏校准模型,从不断升级的精排多层模型中吸收知识。针对GMV优化的目标,我们在蒸馏校准模型的基础上,提出了全空间-子空间联合建模、使用梯度投影算法优化的新模型,在离线、在线都取得了效果的显著提升。
我们对粗排模型的探索仍在进行中,如何更好地与精排模型进行联动、如何超越精排模型的局限、如何平衡性能与效果,都是值得进一步思考的问题。
参考文献
[1] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015).
[2] Tang, Jiaxi, and Ke Wang. "Ranking distillation: Learning compact ranking models with high performance for recommender system." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
[3] Tang, Jiaxi, et al. "Understanding and Improving Knowledge Distillation." arXiv preprint arXiv:2002.03532 (2020).
[4] Müller, Rafael, Simon Kornblith, and Geoffrey E. Hinton. "When does label smoothing help?." Advances in Neural Information Processing Systems. 2019.
[5] Guo, Chuan, et al. "On calibration of modern neural networks." arXiv preprint arXiv:1706.04599 (2017).
[6] He, Xinran, et al. "Practical lessons from predicting clicks on ads at facebook." Proceedings of the Eighth International Workshop on Data Mining for Online Advertising. 2014.
[7] Niculescu-Mizil, Alexandru, and Rich Caruana. "Predicting good probabilities with supervised learning." Proceedings of the 22nd international conference on Machine learning. 2005.
[8] Ma, Xiao, et al. "Entire space multi-task model: An effective approach for estimating post-click conversion rate." The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018.
[9] Wen, Hong, et al. "Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction." Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2020.
[10] Kendall, Alex, Yarin Gal, and Roberto Cipolla. "Multi-task learning using uncertainty to weigh losses for scene geometry and semantics." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[11] Chen, Zhao, et al. "Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks." International Conference on Machine Learning. PMLR, 2018.
[12] Liu, Shikun, Edward Johns, and Andrew J. Davison. "End-to-end multi-task learning with attention." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[13] Sener, Ozan, and Vladlen Koltun. "Multi-task learning as multi-objective optimization." Advances in Neural Information Processing Systems. 2018.
[14] Lin, Xiao, et al. "A pareto-efficient algorithm for multiple objective optimization in e-commerce recommendation." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
[15] Yu, Tianhe, et al. "Gradient surgery for multi-task learning." arXiv preprint arXiv:2001.06782 (2020).
团队介绍
淘宝主搜召回团队:团队负责主搜链路中的召回、粗排环节,目前的主要技术方向为基于全空间样本的多目标个性化向量召回、基于大规模预训练的多模态召回、基于对比学习的相似Query语义改写以及粗排模型等。
✿ 拓展阅读


作者|幻士
编辑|橙子君
出品|阿里巴巴新零售淘系技术


以上是关于深度粗排模型的GMV优化实践:基于全空间-子空间联合建模的蒸馏校准模型的主要内容,如果未能解决你的问题,请参考以下文章