Spark开发笔记总结
Posted 魏晓蕾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark开发笔记总结相关的知识,希望对你有一定的参考价值。
1、Scala中::、+:、:+、:::、++的用法
package org.example
object testList
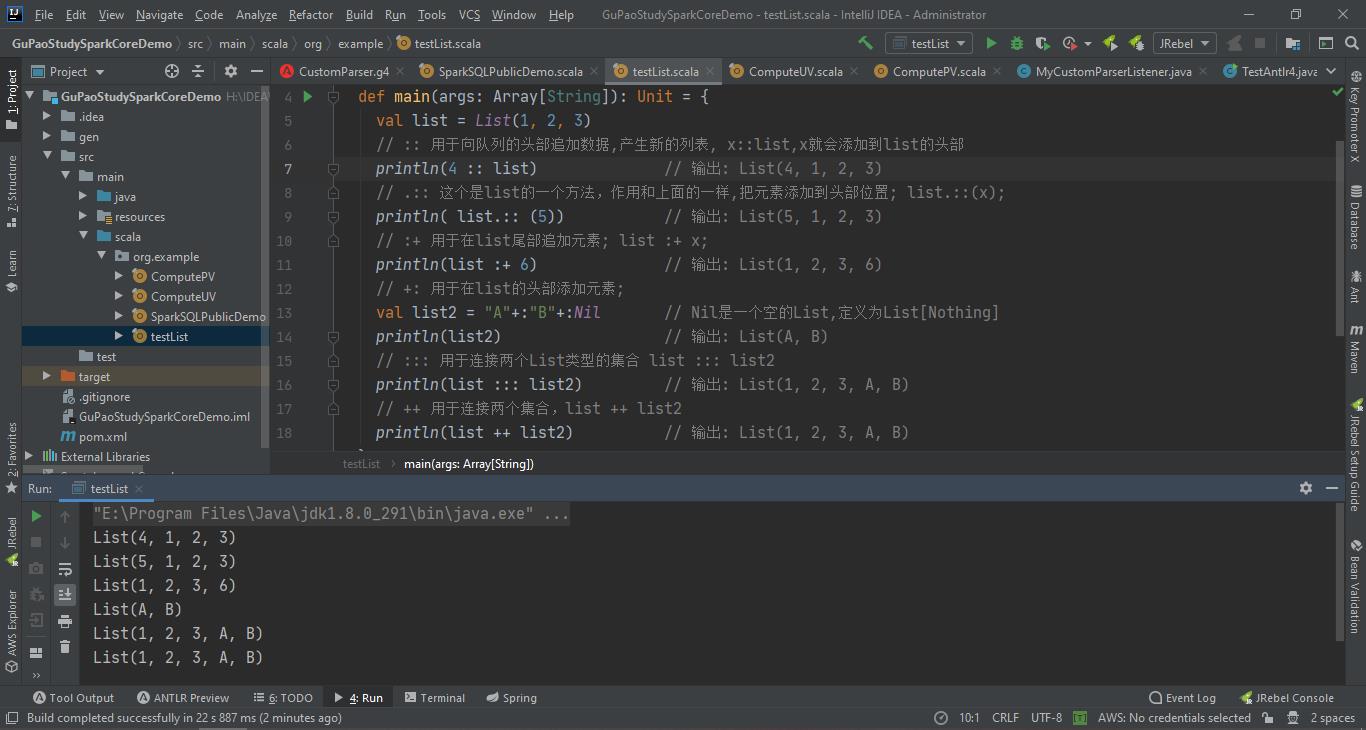
def main(args: Array[String]): Unit =
val list = List(1, 2, 3)
// :: 用于向队列的头部追加数据,产生新的列表, x::list,x就会添加到list的头部
println(4 :: list) // 输出: List(4, 1, 2, 3)
// .:: 这个是list的一个方法,作用和上面的一样,把元素添加到头部位置; list.::(x);
println( list.:: (5)) // 输出: List(5, 1, 2, 3)
// :+ 用于在list尾部追加元素; list :+ x;
println(list :+ 6) // 输出: List(1, 2, 3, 6)
// +: 用于在list的头部添加元素;
val list2 = "A"+:"B"+:Nil // Nil是一个空的List,定义为List[Nothing]
println(list2) // 输出: List(A, B)
// ::: 用于连接两个List类型的集合 list ::: list2
println(list ::: list2) // 输出: List(1, 2, 3, A, B)
// ++ 用于连接两个集合,list ++ list2
println(list ++ list2) // 输出: List(1, 2, 3, A, B)
2、mysql中CONCAT()、CONCAT_WS()、GROUP_CONCAT()的区别
- CONCAT()函数
CONCAT()函数用于将多个字符串连接成一个字符串。
使用数据表Info作为示例,其中SELECT id,name FROM info LIMIT 1;的返回结果为:
+----+--------+
| id | name |
+----+--------+
| 1 | BioCyc |
+----+--------+
语法及使用特点:
CONCAT(str1,str2,…)
返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。可以有一个 或多个参数。
使用示例:
SELECT CONCAT(id, ‘,’, name) AS con FROM info LIMIT 1;
+----------+
| con |
+----------+
| 1,BioCyc |
+----------+
SELECT CONCAT(‘My’, NULL, ‘QL’);
+--------------------------+
| CONCAT('My', NULL, 'QL') |
+--------------------------+
| NULL |
+--------------------------+
- CONCAT_WS()函数
使用函数CONCAT_WS()指定参数之间的分隔符。使用语法为:
CONCAT_WS(separator,str1,str2,…)
CONCAT_WS() 代表 CONCAT With Separator ,是CONCAT()的特殊形式。第一个参数是其它参数的分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。如果分隔符为 NULL,则结果为 NULL。函数会忽略任何分隔符参数后的 NULL 值。但是CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。
SELECT CONCAT_WS('_',id,name) AS con_ws FROM info LIMIT 1;
+----------+
| con_ws |
+----------+
| 1_BioCyc |
+----------+
SELECT CONCAT_WS(',','First name',NULL,'Last Name');
+----------------------------------------------+
| CONCAT_WS(',','First name',NULL,'Last Name') |
+----------------------------------------------+
| First name,Last Name |
+----------------------------------------------+
- GROUP_CONCAT()函数
GROUP_CONCAT()函数返回一个字符串结果,该结果由分组中的值连接组合而成。
使用表info作为示例:
SELECT locus,id,journal FROM info WHERE locus IN('AB086827','AF040764');
+----------+----+--------------------------+
| locus | id | journal |
+----------+----+--------------------------+
| AB086827 | 1 | Unpublished |
| AB086827 | 2 | Submitted (20-JUN-2002) |
| AF040764 | 23 | Unpublished |
| AF040764 | 24 | Submitted (31-DEC-1997) |
+----------+----+--------------------------+
使用语法及特点:
GROUP_CONCAT([DISTINCT] expr [,expr ...]
[ORDER BY unsigned_integer | col_name | formula [ASC | DESC] [,col ...]]
[SEPARATOR str_val])
在 MySQL 中,你可以得到表达式结合体的连结值。通过使用 DISTINCT 可以排除重 复值。如果希望对结果中的值进行排序,可以使用 ORDER BY 子句。
SEPARATOR 是一个字符串值,它被用于插入到结果值中。缺省为一个逗号 (","),可以通过指定 SEPARATOR “” 完全地移除这个分隔符。
可以通过变量 group_concat_max_len 设置一个最大的长度。在运行时执行的句法如下:
SET [SESSION | GLOBAL] group_concat_max_len = unsigned_integer;
如果最大长度被设置,结果值被剪切到这个最大长度。如果分组的字符过长,可以对系统参数进行设置:
SET @@global.group_concat_max_len=40000;
使用示例:
SELECT locus,GROUP_CONCAT(id) FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus;
+----------+------------------+
| locus | GROUP_CONCAT(id) |
+----------+------------------+
| AB086827 | 1,2 |
| AF040764 | 23,24 |
+----------+------------------+
SELECT locus,GROUP_CONCAT(distinct id ORDER BY id DESC SEPARATOR '_') FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus;
+----------+----------------------------------------------------------+
| locus | GROUP_CONCAT(distinct id ORDER BY id DESC SEPARATOR '_') |
+----------+----------------------------------------------------------+
| AB086827 | 2_1 |
| AF040764 | 24_23 |
+----------+----------------------------------------------------------+
SELECT locus,GROUP_CONCAT(concat_ws(', ',id,journal) ORDER BY id DESC SEPARATOR '. ') FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus;
+----------+--------------------------------------------------------------------------+
| locus | GROUP_CONCAT(concat_ws(', ',id,journal) ORDER BY id DESC SEPARATOR '. ') |
+----------+--------------------------------------------------------------------------+
| AB086827 | 2, Submitted (20-JUN-2002). 1, Unpublished |
| AF040764 | 24, Submitted (31-DEC-1997) . 23, Unpublished |
3、离线安装Pandas
在阿里云镜像下载pypi安装包,下载地址:https://mirrors.aliyun.com/pypi/simple/。
在线pip源配置:
a. 找到下列文件:
~/.pip/pip.conf(Linux环境)
C:\\Users\\yanyan\\pip\\pip.ini(Windows环境)
b. 在上述文件中添加或修改:
[global]
index-url = https://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
离线安装Pandas版本1.0.1,需要以下python组件(安装的Python环境为Python3.7):
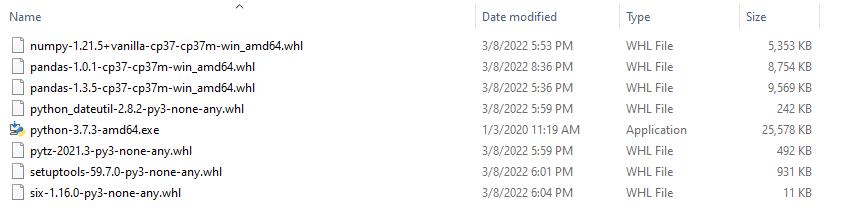
在该目录下运行以下命令:
pip install six-1.16.0-py3-none-any.whl setuptools-59.7.0-py3-none-any.whl pytz-2021.3-py3-none-any.whl python_dateutil-2.8.2-py3-none-any.whl "numpy-1.21.5+vanilla-cp37-cp37m-win_amd64.whl" pandas-1.0.1-cp37-cp37m-win_amd64.whl
即可离线安装Pandas-1.0.1版本。
以上是关于Spark开发笔记总结的主要内容,如果未能解决你的问题,请参考以下文章
Spark (Python版) 零基础学习笔记—— Spark Transformations总结及举例