Spark开发环境搭建——Spark开发学习笔记
Posted katus
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark开发环境搭建——Spark开发学习笔记相关的知识,希望对你有一定的参考价值。
前言:本人水平有限,目前在前辈的指导下进行Spark开发的自学,在此整理出自学笔记,主要是巩固一下学习的内容,如果本文内容能对各位读者有所启发,我将十分高兴。另外由于个人水平有限,所写内容难免有疏漏之处,欢迎各位批评指出。
Spark开发环境搭建
本文的操作环境和安装的版本
- 操作系统:Windows 10 1909版本
- IDE:IntelliJ IDEA Ultimate 2019.2.4版本
- JDK:1.8.0_221
- Hadoop:2.7.1
- Spark:3.0.0-preview
- Scala:2.12.10
- Maven:3.6.2
一、Java环境搭建
安装java环境需要安装部署JDK和JRE,本次选择的JDK版本是1.8。前往官网即可下载,官网链接:JDK下载地址。
我们选择64位Windows版本下载,然后进行安装。
安装完成之后进行系统变量的配置,需要配置如下系统变量。(请根据自己的安装目录进行设置)
- JAVA_HOME:C:\\Program Files\\Java\\jdk1.8.0_221
- CLASSPATH:.;%JAVA_HOME%\\lib\\dt.jar;%JAVA_HOME%\\lib\\tools.jar;
- Path:%JAVA_HOME%\\bin;%JAVA_HOME%\\jre\\bin
完成之后在命令行分别输入java、javac命令均有相应结果,说明配置正确。
二、安装IDE
本文选用的IDE为JetBrains套件中的IntelliJ IDEA,可以前往JetBrains官网下载安装,具体安装方式不再演示。
三、Hadoop安装
本文下载的Hadoop版本为2.7.1,前往Hadoop镜像网站下载对应的Hadoop包。
在Windows环境下部署Hadoop环境与Linux不同,需要额外的文件,不单单是解压就可以了。额外的文件包括hadoop.dll和winutils.exe,这两个文件可以在4ttty的winutils GitHub项目下找到,复制这两个文件到Hadoop文件夹下的bin目录下。
实际在配置的时候如果只添加上述两个文件还是会导致Spark项目运行报错,说winutils.exe与你运行的Windows版本不兼容;后来我经过大量尝试发现需要把上述的GitHub工程中对应Hadoop版本下的bin文件夹下的全部拷贝到本机上的Hadoop/bin文件夹下才能正常。
完成后配置系统环境变量,如下。(请根据自己的安装目录进行设置)
- HADOOP_HOME:D:\\Compilers\\hadoop-2.7.1
- Path:%HADOOP_HOME%\\bin
四、Spark安装
在Spark官网下载合适版本的Spark,需要注意版本需要契合之前安装的Hadoop版本,本文就选用3.0.0-preview版本。
和Hadoop的安装类似,解压,修改系统环境变量如下。(请根据自己的安装目录进行设置)
- SPARK_HOME:D:\\Compilers\\spark-3.0.0-preview-bin-hadoop2.7
- Path:%SPARK_HOME%\\bin
五、Scala语言安装
前往Scala官方网站选择相应版本的Scala版本进行安装,注意此处安装的版本需要和选用的Spark版本对应的Scala版本相一致才行,例如本文选用的Spark版本为3.0.0-preview(目前最新),其对应的适用Scala版本为2.12.10。
查询这种对应关系可以通过查看Spark中的jar包中的scala-compiler-2.XX.XX.jar,最后面的数字即为对应的Scala版本。本文中的对应jar包为scala-compiler-2.12.10,即Scala版本为2.12.10。
安装过程保持默认即可。
完成后修改系统变量如下。(请根据自己的安装目录进行设置)
- SCALA_HOME:C:\\Program Files (x86)\\scala
- Path:%SCALA_HOME%\\bin
六、安装maven
前往maven官网下载maven的二进制ZIP包,在特定目录解压即可。

七、工程项目环境配置
(一)IDE配置
打开IntelliJ IDEA,第一次使用需要激活、设定UI、选用下载插件,统统默认完成之后打开如下界面。
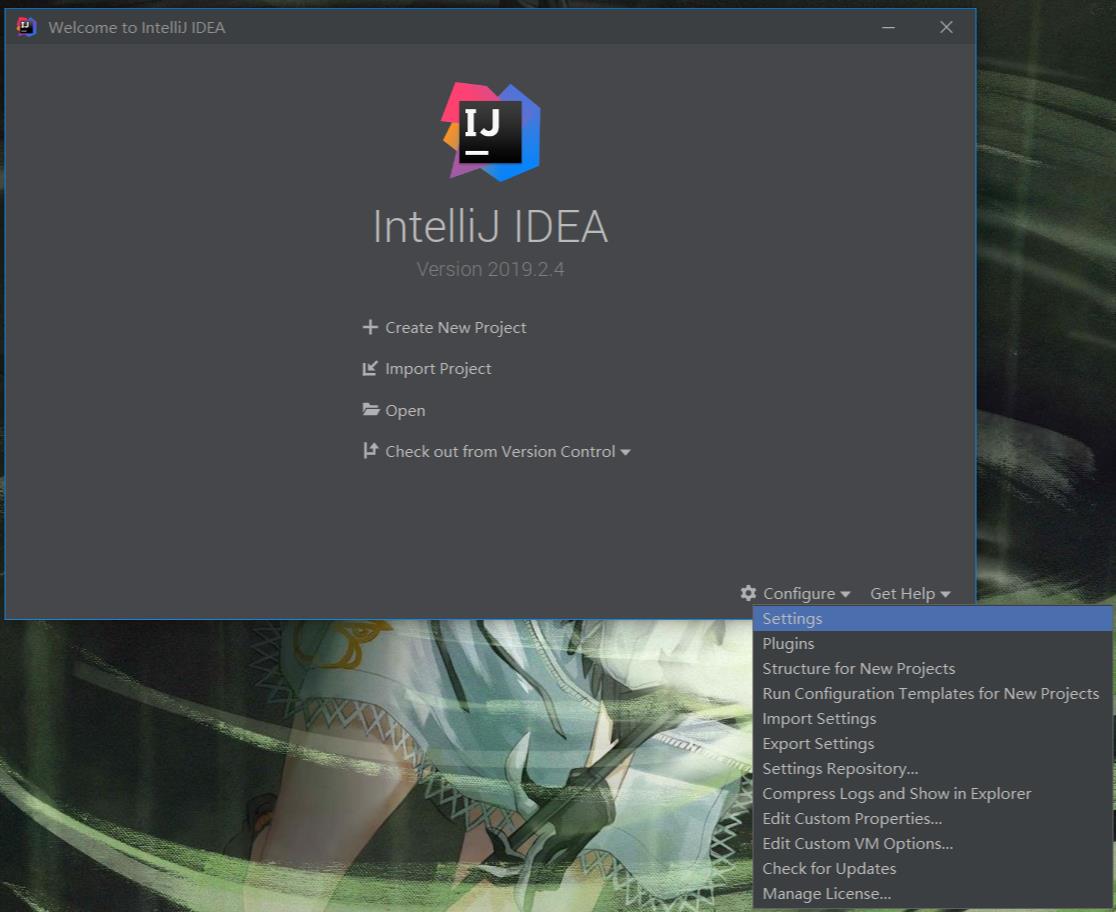
接下来需要依次设置配置下的Plugins、Structure for New Projects、Settings选项。
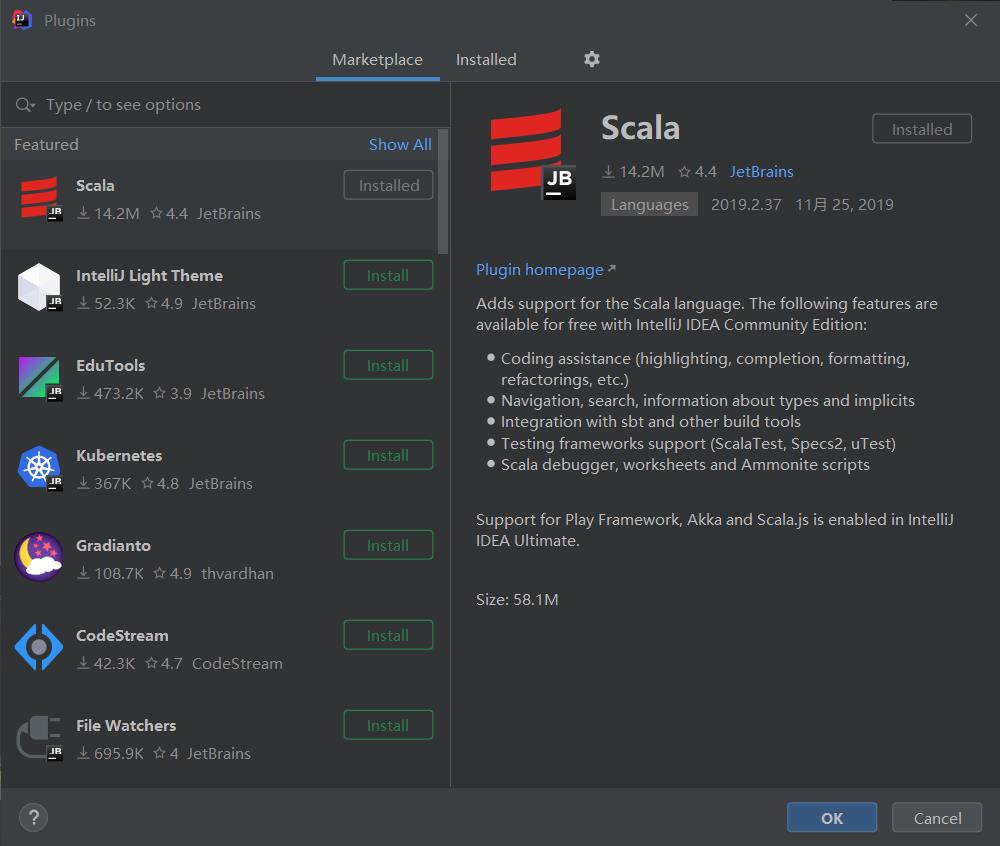
首先是Plugins,安装Scala插件,完成后点击OK。
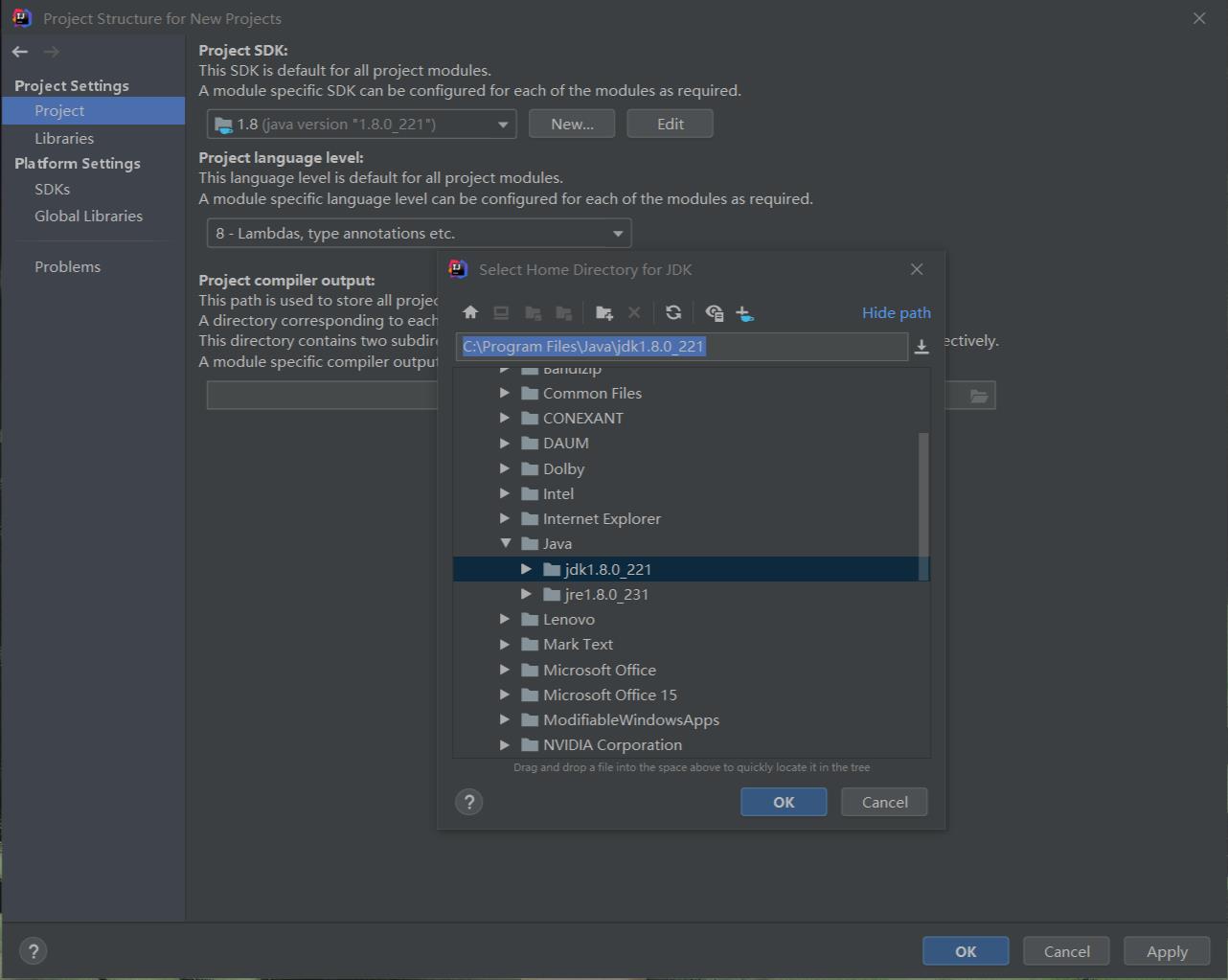
然后设置Structure for New Projects,Project选项卡,点击New按钮,点击JDK选项,选择刚才安装的JDK路径,确认。
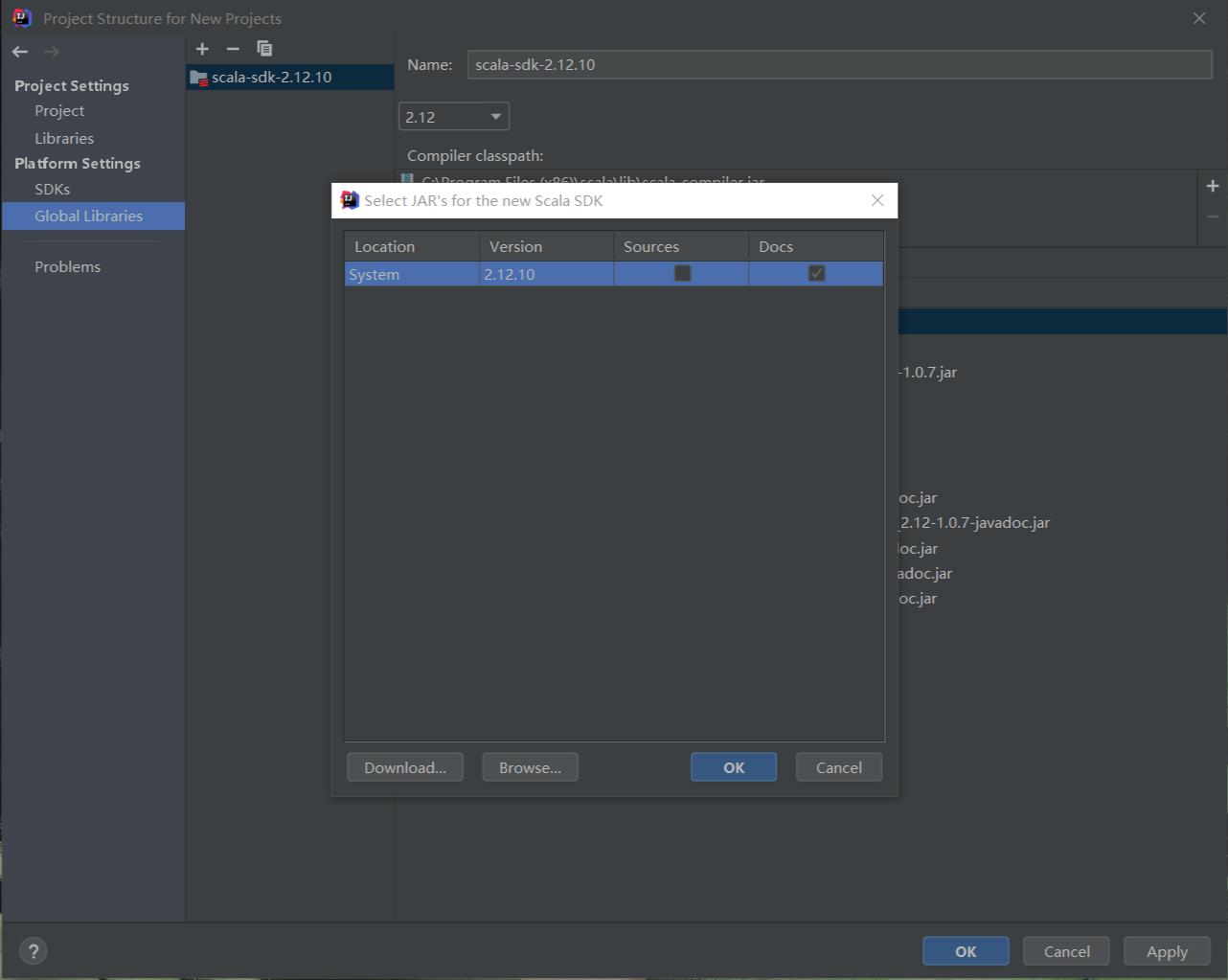
Global Libraries选项卡,点击加号,选择Scala SDK,添加刚刚在系统中安装的Scala,点击OK。
最后设置Settings,选择Build, Execution, Deployment下的Build Tools下的Maven选项卡,设置右侧Maven home directory为刚刚maven下载的解压目录,其中User settings file和Local repository可以通过勾选Override选项更换位置。此处建议将Local repository设置到其他位置。
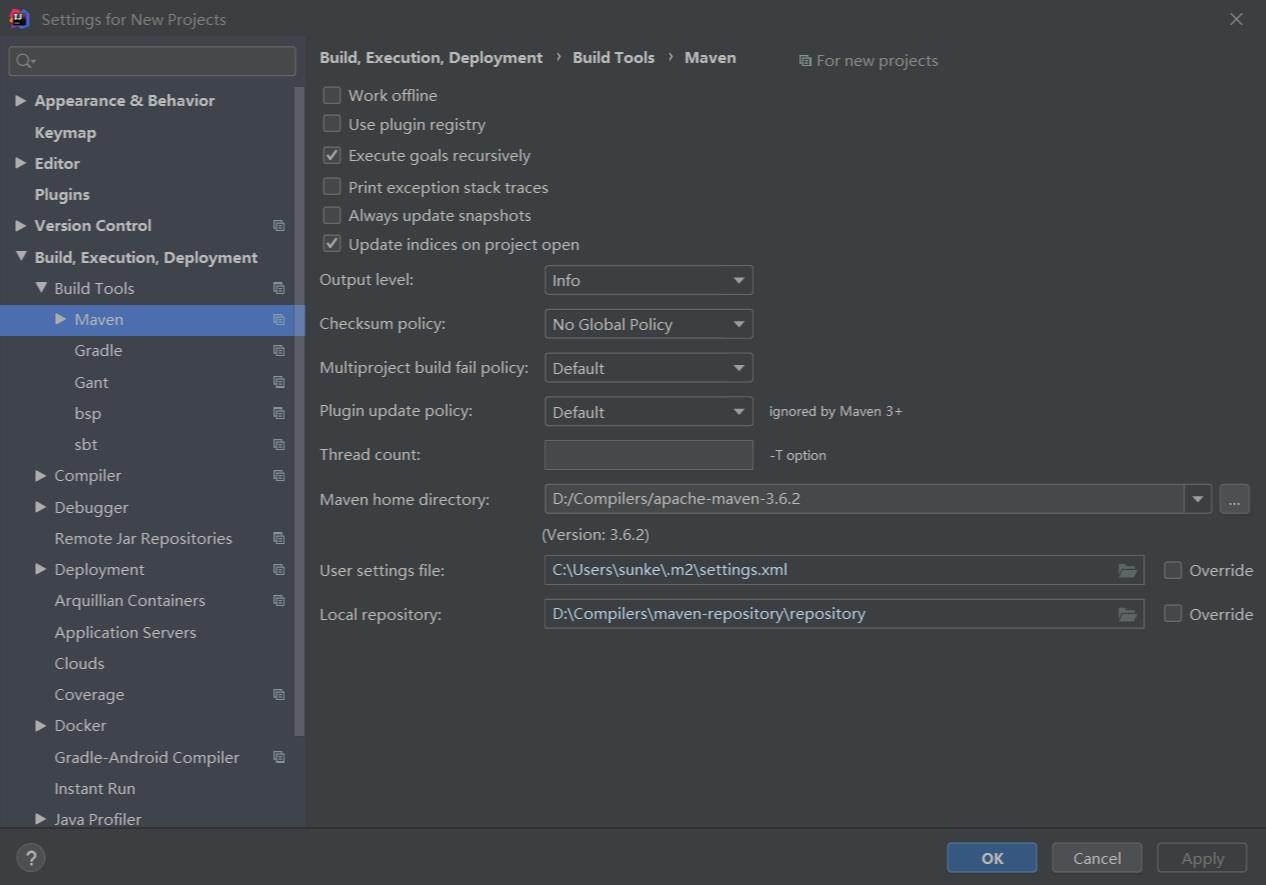
更改repository默认位置可以通过在maven配置文件settings.xml的settings标签下增加如下代码来实现。(标签中的值为自定义设置的repository目录)
<localRepository>D:\\Compilers\\maven-repository\\repository</localRepository>
如果在一会下载依赖jar包的时候如果速度过慢,可以使用国内镜像,方法是在maven配置文件settings.xml的settings标签下的mirrors标签下增加如下代码(以阿里云镜像为例)。
<!-- 阿里云镜像 -->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
点击Compiler下的Java Compiler选项卡,设置合适的编译器版本,此处选择8。(截图中WordCount会在后续新建项目之后出现,后续也可以通过菜单栏再次修改Settings)
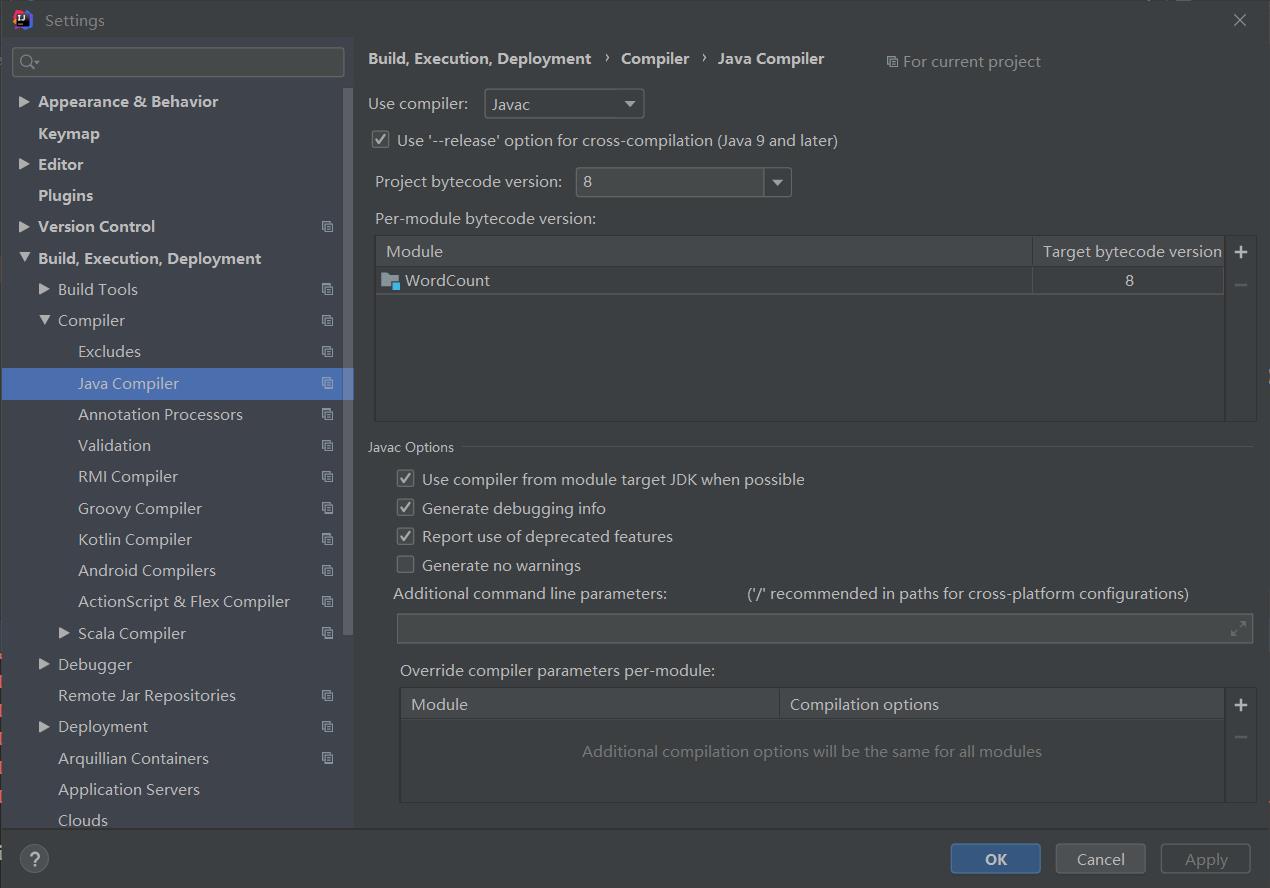
此处设置的编译器版本取决于你的Spark支持的版本、JDK版本和你的代码中所用到的Java特性。
设置完成点击OK即可。
(二)创建Maven项目
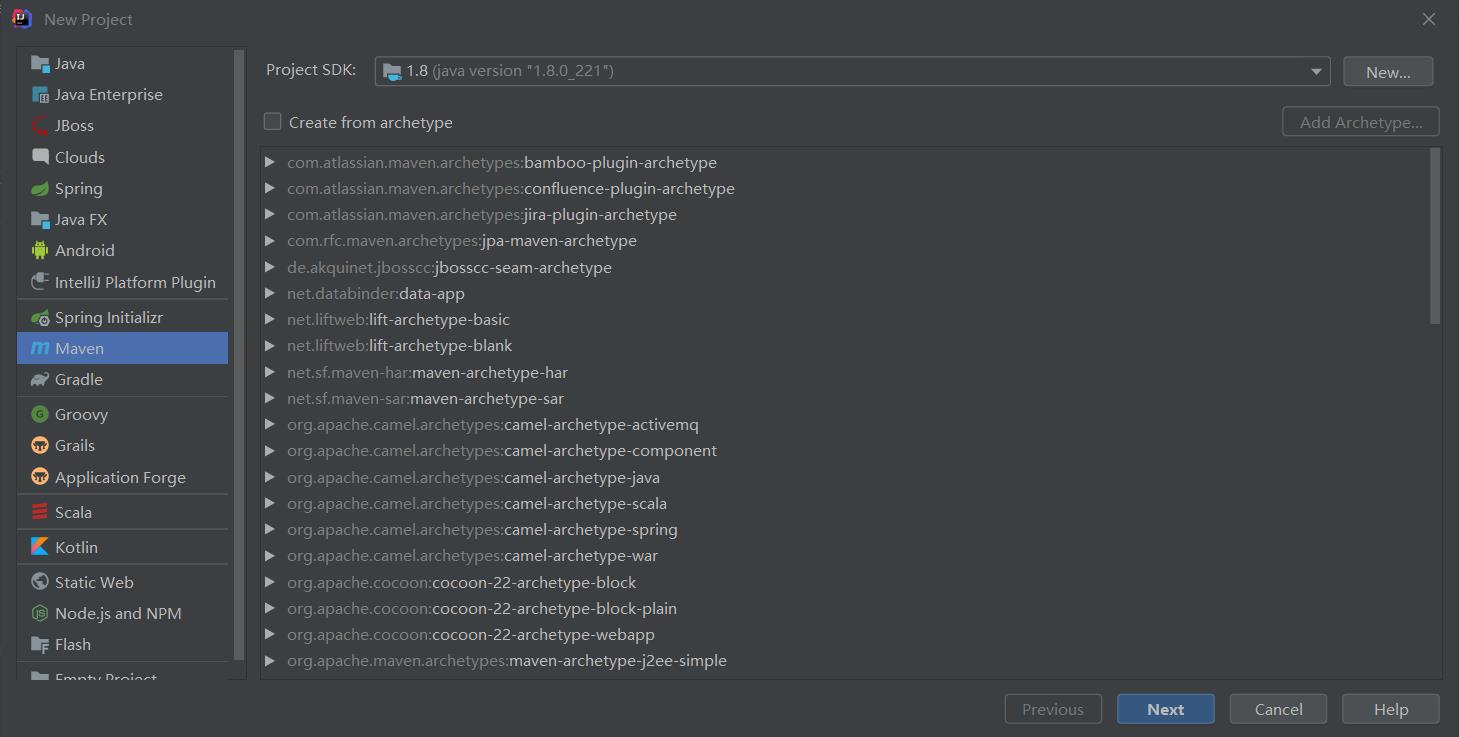
点击Create New Project,在左侧选择Maven,右侧JDK版本选择1.8,完成后点击Next。
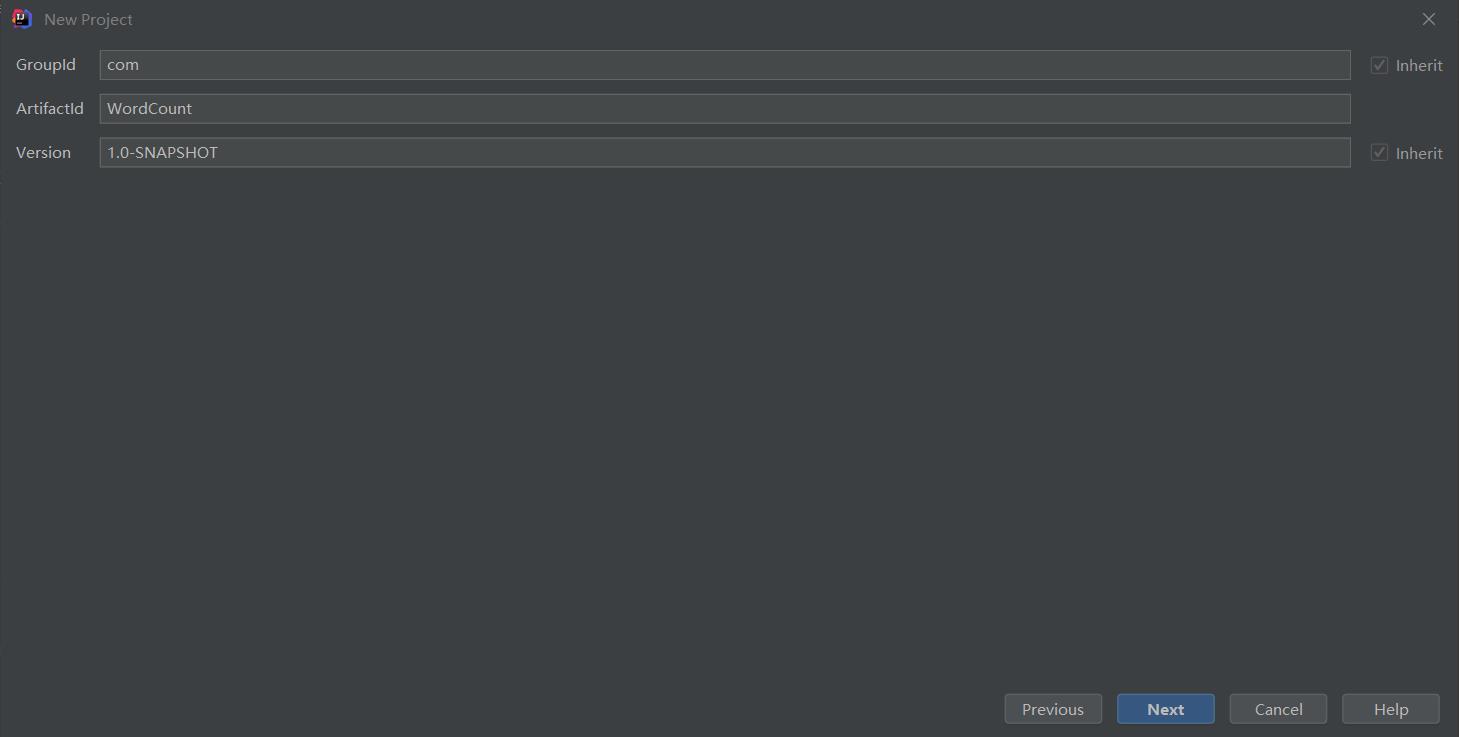
设置GroupId和ArtifactId,没有什么具体要求,建议ArtifactId与项目名一致,完成后点击Next。
设置项目名称,项目保存路径,完成后点击Finish。
(三)配置Maven依赖
在新项目根目录下的pom.xml修改为如下代码,请注意配置时GroupId和ArtifactId请以自己的为准。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>zju</groupId>
<artifactId>WordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<jdk.version>1.8.0</jdk.version>
<spark.version>3.0.0-preview</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0-preview</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0-preview</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0-preview</version>
</dependency>
</dependencies>
</project>
配置Maven依赖时,如果遇到不清楚的依赖写法,可以通过在Maven存储库网站中进行查询。
然后在项目目录下的pom.xml文件上右键,点击Maven下的Reimport,重新导入依赖。(或者在右下角的提示中选择导入修改)
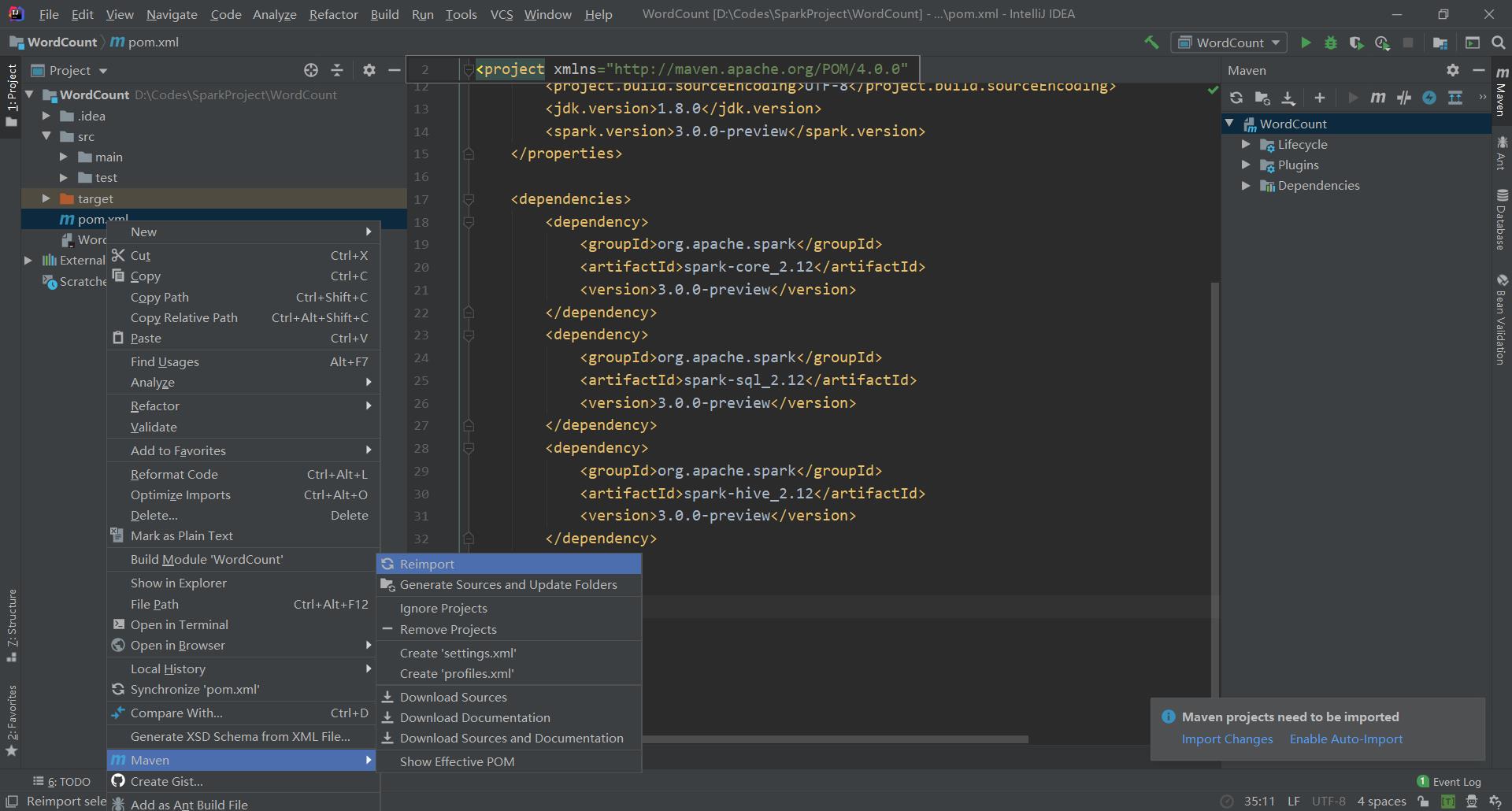
等待下载完成即可。
(四)示例程序测试
在新建的工程中新建WordCount类,然后增加如下代码。
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.List;
public class WordCount
public static void main(String[] args)
String inputFile = "D:\\\\words.txt";
String outputFile = "D:\\\\result";
SparkSession session = SparkSession.builder().getOrCreate();
JavaSparkContext sparkContext = JavaSparkContext.fromSparkContext(session.sparkContext());
sparkContext.textFile(inputFile).flatMapToPair(s ->
String[] words = s.split("\\\\s");
List<Tuple2<String, Integer>> r = new ArrayList<Tuple2<String, Integer>>();
for (String word : words)
r.add(new Tuple2<String, Integer>(word, 1));
return r.iterator();
).reduceByKey((i, j) -> i + j).saveAsTextFile(outputFile);
session.stop();
在右上角配置java运行环境,配置如下。
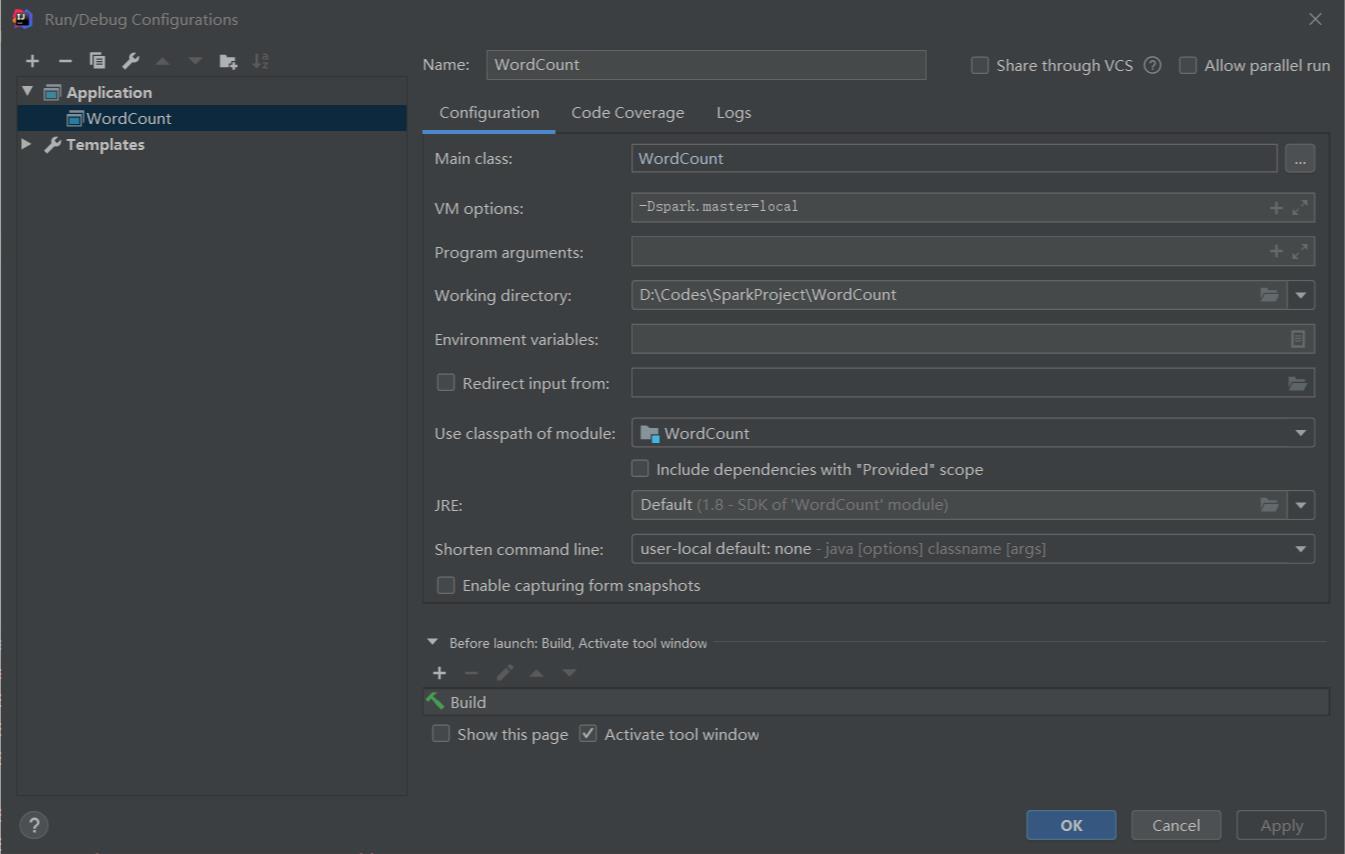
然后点击运行,正常运行说明配置成功。
最后查看运行结果如下。
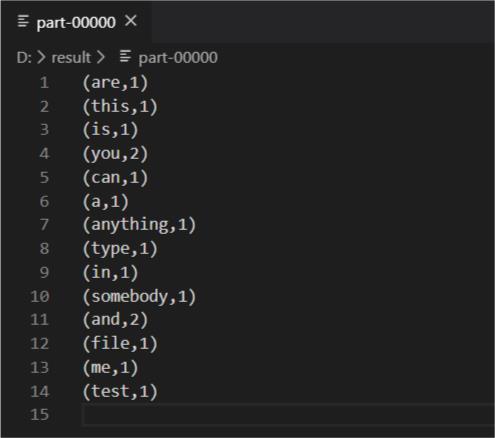
以上是关于Spark开发环境搭建——Spark开发学习笔记的主要内容,如果未能解决你的问题,请参考以下文章