基于 YOLOV3的交通车辆检测
Posted 卓晴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于 YOLOV3的交通车辆检测相关的知识,希望对你有一定的参考价值。
简 介: 近年来,深度学习在交通安全、无人驾驶等领域被广泛研究与应用,而车辆检测作为其中不可或缺的一环,被人们所重点关注。本文基于
YOLOV3网络对其不同骨网进行了训练与分析,最终实现了对交通车辆的准确检测。在Paddle平台实验条件下,可同时得到高达78.432mAP与平均108.74ms的推测时间。
关键词: 目标检测,车辆,YOLOv3
§01 引 言
目标检测作为深度学习神经网络在计算机视觉方面的热门应用,在探测、医疗以及公共安全等领域都已成为研究热点,并有着丰富多元且广阔的应用前景,而车辆检测便是其重要应用分支之一,给交通及公共安全带来一层可靠保障。并且在交通系统日益繁杂的今天,仅仅依靠人为驾驶存在许多安全隐患,因此催生了人们在无人驾驶以及智能驾驶技术领域的广泛探索。车辆检测便是无人与智能驾驶能够实行的前提,本文则采用深度学习神经网络中的 YOLOV3对交通车辆实现了检测与识别。以下先对 YOLO模型进行简要介绍。
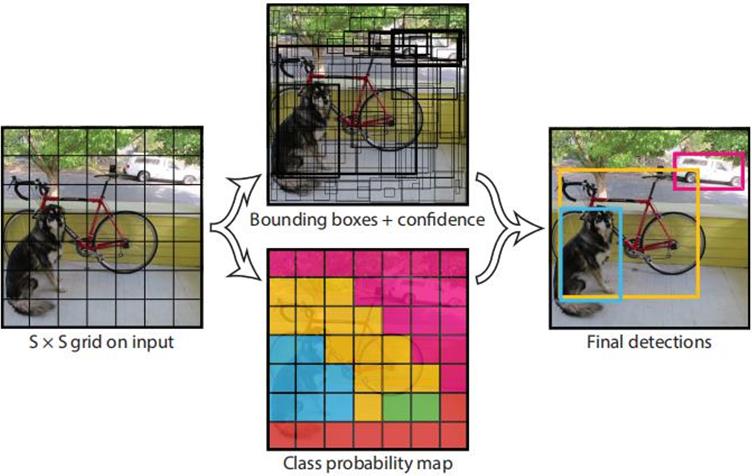
▲ 图1.1 YOLO模型检测
§02 YOLO目标检测
YOLO检测推算过程目标检测问题求解主要包括两部分,分为物体的识别(分类问题)与物体位置(回归问题)的求解。因此,在目标检测领域较为经典的 R-CNN系列网络采用的方法就是对上述两部分的分别求解。而在 2016年 Redmon等[1]提出 YOLO(You Only Look Once)目标检测模型网络,他将目标检测作为一个回归问题进行求解,即整个网络只对完整图像检测一次便可得到结果,因此检测速度有了大幅提高。其基本思路为将整幅图分为 SXS个网格,如图所示,各网格只负责预测落入该网格中心位置的物体,并同时给出物体类别的概率信息以及多个物体边界框及置信度信息。其中边界框通过对置信度设置阈值进行过滤,过滤之后又通过非极大值抑制( non-maximum suppression,NMS)处理以得到最终的检测结果。最终 YOLO可得到实时 45FPS的高速检测结果,但由于 YOLO的每个格子只能预测出一个物体,且只选择置信度最高的边界框进行输出,故在检测物体时的边框定位效果不佳。
随后, YOLO系列针对上述问题进行改进, YOLOV2[2]采用 Darknet-19作为特征提取的骨架,进一步提升检测速度,并在卷积层中加入了批量归一化 BN(Batch Normalize)以及引入锚框 (anchor),提升了的物体定位精度。
在 2017年的提出 YOLOV3[3]通过采用 logistic代替 softmax实现了多标签目标检测。其网络整体结构如下图所示,且图中各个小单元网络的详细结构如图底所示。 YOLOV3借鉴了 Resnet的残差网络,采用更深层次的 Darknet-53作为特征提取网络,因为其具有 53层卷积层,故称其为 Darenet53,其网络整体结构如图中左上部分所示。 concat为用于特征融合的计算单元,如图中所示,特征图经过相互融合,最终输出 3个不同尺度的特征图,并通过其来进行误差反向传播,从而实现对目标检测的训练。采用多尺度特征图,目的是为了降低小目标的特征丢失,因此最终提升了对小目标的检测精度。相比当时的其它网络模型,在相近检测表现的情况下, YOLOV3可实现 3.8倍左右的速度提升。
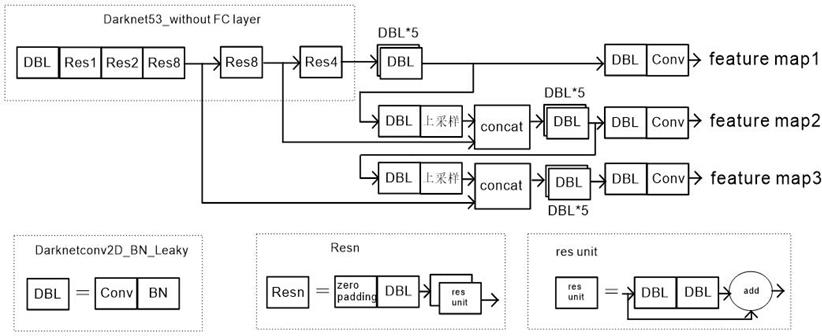
▲ 图2.1 YOLOV3网络结构
§03 数据准备
采用 UA-DETRAC作为车辆目标检测的数据集,其由天津和北京的道路监控摄像头拍摄而成,共有 20050张图片。数据集中共有三种车类型,分别为 Bus、 Van与 Car,共手动标注了 8250辆车的类型和边界框。
在本文中,在 PaddleX平台的至尊版环境下进行实验,将该数据集转为 VOC格式数据集类型进行训练和评估,每隔四张,取前 19000张图片作为训练集,最后 1000张图片作为评估测试集。此外还对图像进行数据增强、大小调整和归一化处理。

▲ 图3.1 UA-DETRACE数据集合
§04 网络训练
4.1 锚框选定
锚框在现今优秀的目标检测模型中已被广泛应用,可以解决以往一个窗口只能检测一个物体的问题,以及可加速后续训练的过程。在正式开始训练之前,首先对数据集进行 K-means聚类选取 9个合适的锚框,其中一次实验中的锚框大小和其对应的平均交并比( IOU)示例如下:

▲ 图4.1.1 锚框计算示例
4.2 正式训练
采用上述的锚框,开始进行正式训练,加载 ImageNet上的预训练权重,进行 50个 epoch共 59350个 step的训练。初始学习速率为 0.00025,并设置学习速率衰减,其学习速率随步数的变化如图 5所示。采用不同的 backbone,分别为 Resnet、MobilenetV1、MobilenetV3_large与 Darknet,各训练过程中的误差函数 loss变化分别如下图 6所示。从图中可得到在目标检测中 loss在经过一定训练后,振幅总是趋于稳定地振荡,而且由于边界框对物体的位置难以达到绝对精确,其绝对误差也相应地难以消除。

▲ 图4.2.1 学习苏伦岁训练步数变化曲线
从图中可得 Resnet具有误差极小值,略微优于其它网络。同时发现 Darknet下的 loss减小最快,即其具有最快的收敛速度。
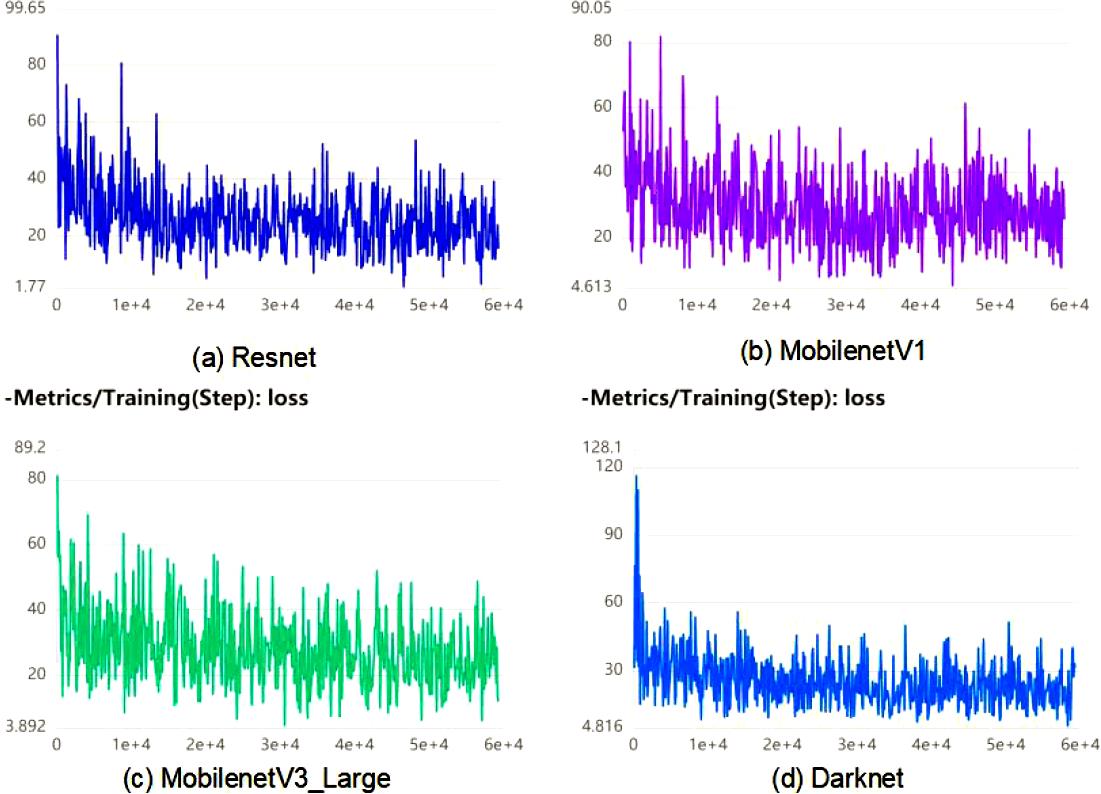
▲ 图4.2.2 不同骨干网络下的误差随训练步数变化
§05 效果评估
对边界框采用均值平均精度( mAP,mean Average Precision)作为指标,在训练中的每两个 Epoch对测试集进行评估,得到 mAP随 Epoch的变化曲线如图所示。首先,不同 backbone网络下,各自的 mAP首先随着训练都在快速上升,并且增长速度逐渐放缓。而训练到后期, mAP不增反降,出现过拟合的情况,需要训练多个 Epoch才能出现一次 mAP的极大值。此外,从曲线中可得, MobilenetV3_large与 Darknet在经过 40个 epoch的训练后取到最大值,能较快达到收敛,而另两个骨干网络则需在第 50个 epoch才达到最大值。尤其是 MobilenetV1,在训练后期其 mAP上升相比其它三种网络较为明显,比较难收敛。需要更长的训练周期。
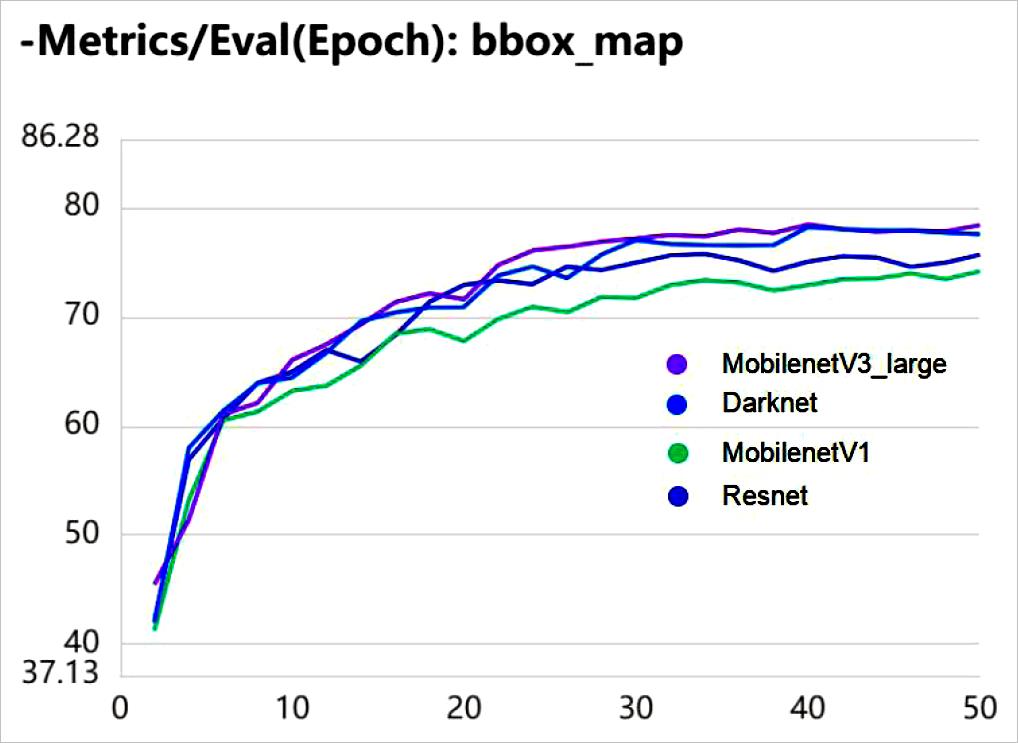
▲ 图5.1 不同骨干网边界框mAP在训练过程中的变化
在经过训练后,分别采取不同骨干网络中的最佳模型,从网上以及本人拍摄的图片中进行测试,如下图所示为部分测试效果。
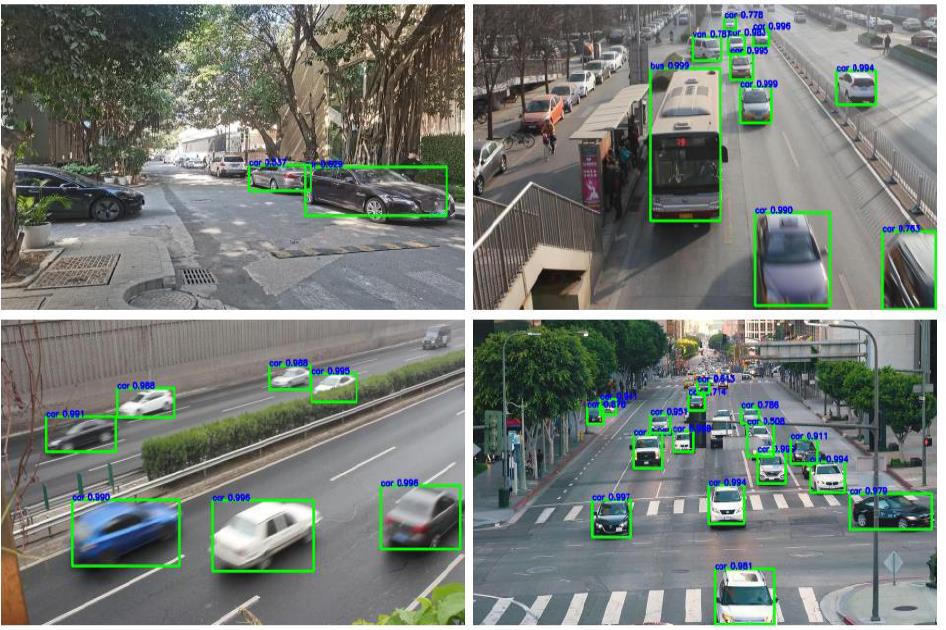
▲ 图5.2 不同的测试效果
在测试的过程中发现:
1. 由于数据集都是采用俯拍的形式进行拍摄,故在测试中部分平视拍摄所得照片的车辆识别效果不佳。
2. 对于车辆这种较大的物体识别,一旦存在车辆在图片中的显示不完整的情况,或者出现车辆被大部分遮掩的情况下,将会不予识别。而存在小部分遮掩的情况下,还是能够正确检测出种类与位置。
3. 同时由于对边界框大小进行了阈值设置,在图中较小的车辆目标将不会框注标示。
4. 即使图片中的车辆因为有较快的速度而导致其成像模糊,网络依然能较为准确地识别。
5. 总之,在俯拍情况下,交通车辆检测效果较佳,不同骨干网络情况下也能对各种种类车辆正确分类识别。用此数据集得到的训练结果网络更适用于俯拍等交通监控场合。
此外,在本次实验中,对采用各种不同骨架网络的 YOLOV3评估结果对比如下表 1所示。首先其中的 MobilenetV3_large与 Darknet取得了较佳的边界框 mAP,分别为 78.432与 78.191。由于此两种网络的网络层次相比其它两种网络都较深,在特征提取中不易丢失更多的信息。因此在经过同样的训练步骤后,取得最佳的训练效果。此外,不同骨干网络取得最大 mAP的 epoch有所不同。
另一方面,在此实验条件下从表中可以得出, MobilenetV1具有最短的训练时间和最快的推断速度,其对每张图片的推断时间平均需要 78.65ms。这是因为骨网层数越少的网络,经过的卷积运算等步骤越少,因此所需要的训练时间更短,并且对测试图像的推断速度更快。但此类网络的特征提取效果不如层次较深的网络,易丢失掉一些信息,导致最终的识别效果不如后两者。表 1各骨网最佳模型结果

▲ 图5.3 各骨网最佳模型结果
§06 总结与展望
在本次实验中,采用 YOLOV3针对车辆进行训练与检测,通过对四种不同骨干网络分别进行训练与讨论,不同骨干网在经过一定训练后,最终都能够对车辆进行较好程度的识别,并且在俯拍视角下效果更佳,适用于交通场合的检测。在讨论结果中,采用 MobilenetV3_large与 Darknet作为骨干网络可以得到较高的 mAP,最高可达到 78.432,同时有着较快的收敛速度。而网络规模较小的 Resnet与 MobilenetV1虽然在精度上不如上述两者,但其在推断速度上占优,在规格要求不高的场所下可采用。
由于时间仓促,本次实验仍有诸多不足。
- 对置信度阈值等参数没有进一步讨论,未来可对这些参数进行讨论,以期进一步提高检测效果。
- 车辆种类细分度不够,未来可考虑寻找和采用更全面的数据集,以能进一步细分识别更多种类的车辆,还可考虑加入识别行人功能。
※ 总 结 ※
近年来,深度学习在交通安全、无人驾驶等领域被广泛研究与应用,而车辆检测作为其中不可或缺的一环,被人们所重点关注。本文基于YOLOV3 网络对其不同骨网进行了训练与分析,最终实现了对交通车辆的准确检测。在Paddle 平台实验条件下,可同时得到高达78.432mAP 与平均108.74ms 的推测时间。
7.1 参考文献
[1] Redmon J , Divvala S , Girshick R , et al. You Only Look Once: Unified, Real-TimeObjectDetection[J]. IEEE,2016.
[2] Redmon J , Farhadi A . YOLO9000: Better, Faster, Stronger[C]// IEEE. IEEE, 2017:6517-6525.
[3] Redmon J , FarhadiA .YOLOv3:An Incremental Improvement[J]. arXiv e-prints, 2018.
[4]张琛 .基于 YOLOv3的道路目标检测方法研究 [D].青海大学 ,2021.
[5]孙恒 .基于改进 YOLOv3的交通信号灯检测和识别研究 [D].长安大学 ,2021.
● 相关图表链接:
- 图1.1 YOLO模型检测
- 图2.1 YOLOV3网络结构
- 图3.1 UA-DETRACE数据集合
- 图4.1.1 锚框计算示例
- 图4.2.1 学习苏伦岁训练步数变化曲线
- 图4.2.2 不同骨干网络下的误差随训练步数变化
- 图5.1 不同骨干网边界框mAP在训练过程中的变化
- 图5.2 不同的测试效果
- 图5.3 各骨网最佳模型结果
以上是关于基于 YOLOV3的交通车辆检测的主要内容,如果未能解决你的问题,请参考以下文章
Matlab实现YOLOV3对车辆进行检测--全程中文说明适合初学者学习
实时车辆行人多目标检测与跟踪系统-上篇(UI界面清新版,Python代码)