阿昌教你通过docker搭建Redis集群
Posted 阿昌喜欢吃黄桃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿昌教你通过docker搭建Redis集群相关的知识,希望对你有一定的参考价值。
一、前言
阿昌在这里总结记录一下,如何通过docker搭建redis哈希槽分区解决方案的集群【3主3从】
涉及知识:
- redis
- docker基本指令
- linux
- 哈希槽分区
二、理论
在开始搭建之前搭建需要知道3种在redis集群搭建的分区算法,分别为:哈希取余分区、一致性哈希算法分区、哈希槽分区
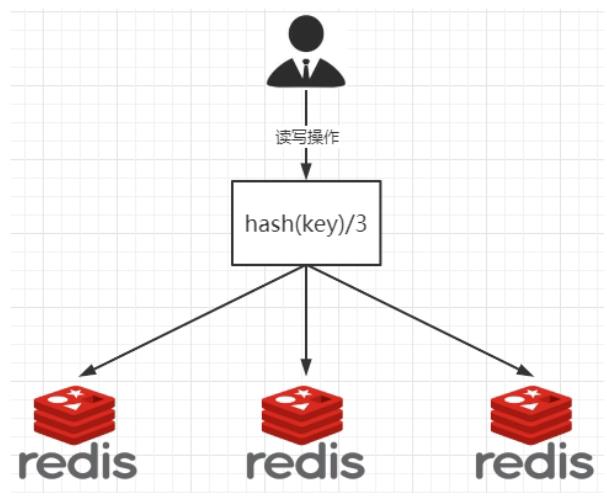
1、哈希取余分区
- 描述图
-
介绍
通过对key取余来直接确定他存放或读取拿个redis。
2亿条记录就是2亿个k,v,我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:
hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。 -
优点
简单粗暴,直接有效,只需要预估好数据规划好节点。例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到
负载均衡+分而治之的作用。 -
缺点
原来规划好的节点,进行扩容或者缩容就比较麻烦。不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key) /?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。 某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
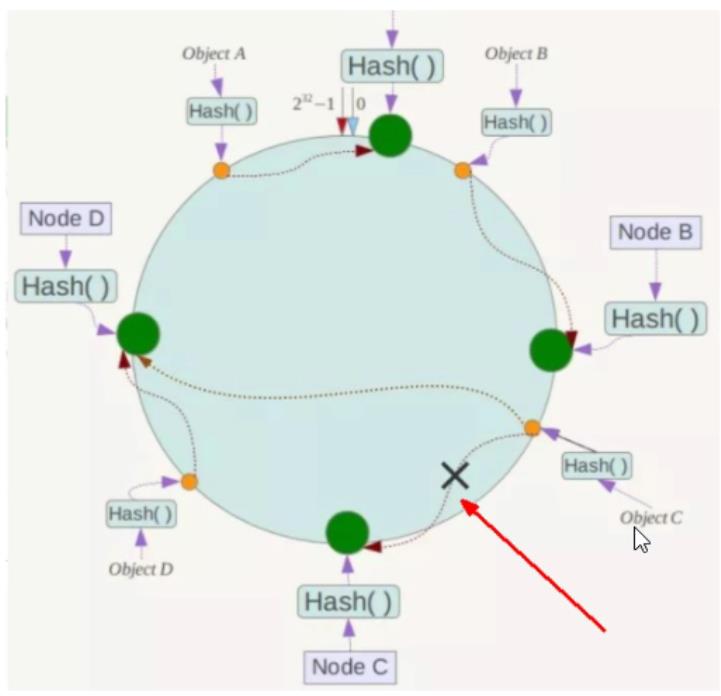
2、一致性哈希算法分区
-
描述图
-
介绍
分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了。
-
目的
为了在节点数目发生改变时尽可能少的迁移数据
将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会
顺时针找到临近的存储节点存放。而当有节点加入或退出时仅影响该节点在
Hash环上顺时针相邻的后续节点。 -
优点
- 一致性哈希算法的
容错性 - 一致性哈希算法的
扩展性
- 一致性哈希算法的
-
缺点
- 当节点数量少时,会出现一致性哈希算法的
数据倾斜问题
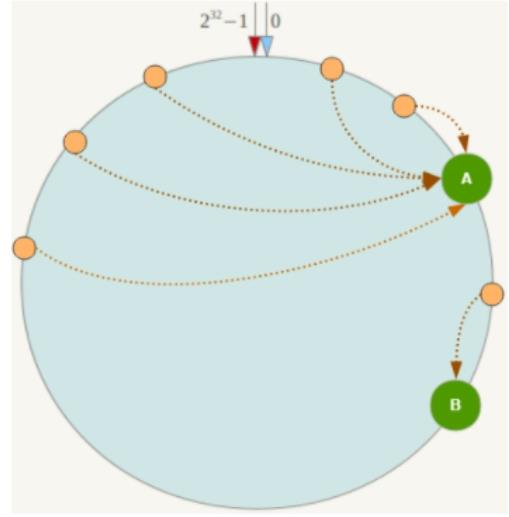
- 当节点数量少时,会出现一致性哈希算法的
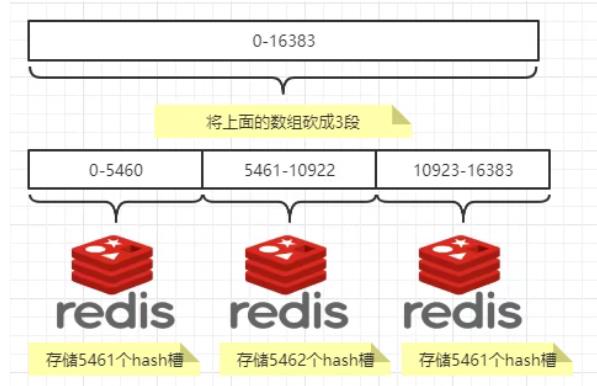
3、哈希槽分区
- 描述图
-
介绍
根据上面的
一致性哈希算法分区再进一步衍生出哈希槽分区,分为哈希槽,其实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。一个集群只能有16384个槽,编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。slot = CRC16(key) % 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。 -
目的
解决均匀分配的问题,
在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。【有点像将数组的一个一个位置反向代理成一个操作】槽解决的是粒度问题,相当于把粒度变大了,这样便于
数据移动。哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于
数据分配。
那这里理论就结束了,下面我就用docker搭建对应的Redis集群。
三、3主3从Redis集群搭建
1、确保Docker服务启动
systemctl start docker
2、新建6个docker容器redis实例
- docker命令
#节点-1
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
#节点-2
docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
#节点-3
docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
#节点-4
docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
#节点-5
docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
#节点-6
docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386
- 指令说明
docker run:创建并运行docker容器实例--name redis-node-6:容器名字--net host:使用宿主机的IP和端口,默认--privileged=true:获取宿主机root用户权限-v /data/redis/share/redis-node-6:/data:容器卷,宿主机地址:docker内部地址redis:6.0.8:redis镜像和版本号--cluster-enabled yes:开启redis集群--appendonly yes:开启aof持久化--port 6386:redis端口号

3、构建集群关系
- 进入容器—这里以node1为例
docker exec -it redis-node-1 /bin/bash
- 构建关系
注意,进入docker容器后才能执行一下命令,且注意自己的真实IP地址,阿昌这里是ip为:192.168.88.128
redis-cli --cluster create 192.168.88.128:6381 192.168.88.128:6382 192.168.88.128:6383 192.168.88.128:6384 192.168.88.128:6385 192.168.88.128:6386 --cluster-replicas 1
#--cluster-replicas 1 表示为每个master创建一个slave节点
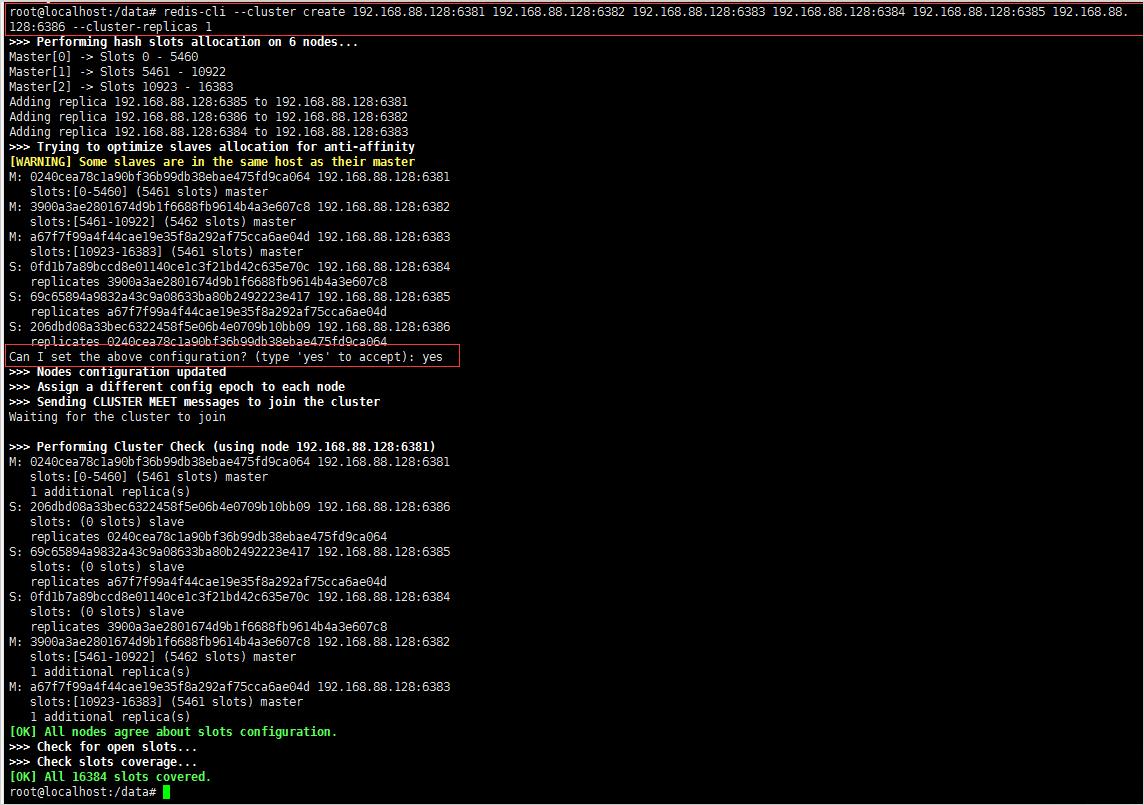
4、查看集群状态
- 查看集群状态—这里以node-1,6381作为切入点
redis-cli -p 6381 cluster info
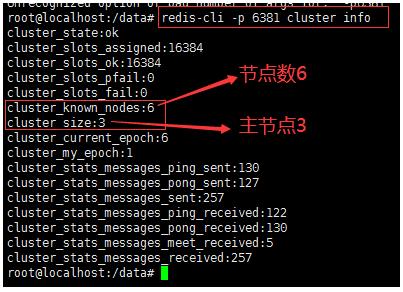
- 查看集群节点
redis-cli -p 6381 cluster nodes

5、集群的读写存储
- 通过
-c参数实现读写存储切换集群节点
因为他在读写key的时候会对key进行计算出这个key所在哪个节点的槽位,每个操作都对应每个节点才可以去读写
redis-cli -p 6381 -c

6、查看集群信息
redis-cli --cluster check 192.168.88.128:6382
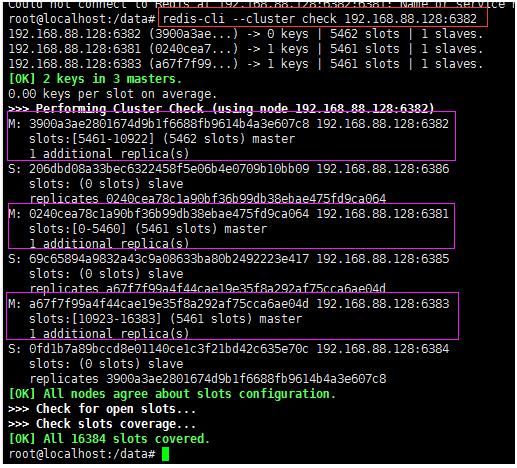
7、关于容错切换迁移
如果我们node1节点宕机了,那他的从节点就会顶上作为新的Master。如果node1节点后续又王者回归后,他也只能重新做新Master的从节点。
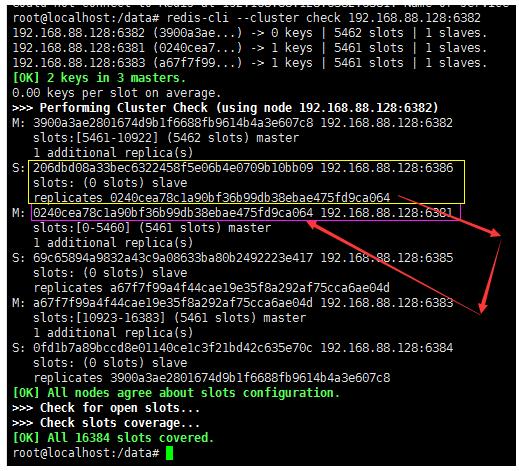
在我们这里的情况node-1节点的从节点是node-6,所以当node-1宕机后,node6就会成为新的master。
四、主从扩容
1、创建要扩容的节点
这里我们以再加入一对主从节点6387、6388,且6387是主,6388是从
#节点-7,主节点
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387
#节点-8,从节点
docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388
docker ps
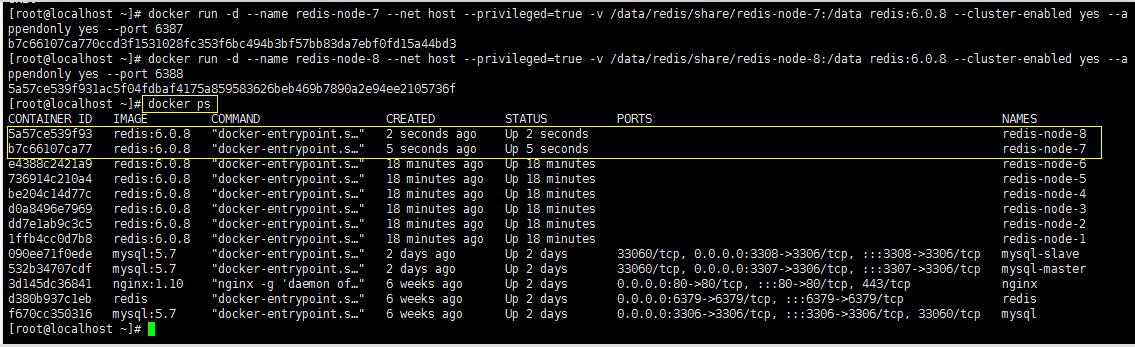
2、进入6387容器实例内部
docker exec -it redis-node-7 /bin/bash
3、将新增的6387节点(空槽号)作为master节点加入原集群
-
新增节点到集群中
将新增的6387作为master节点加入集群
redis-cli --cluster add-node 192.168.88.128:6387 192.168.88.128:6381 #6387 就是将要作为master新增节点 #6381 就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群

-
检查集群情况第1次
redis-cli --cluster check 192.168.88.128:6381
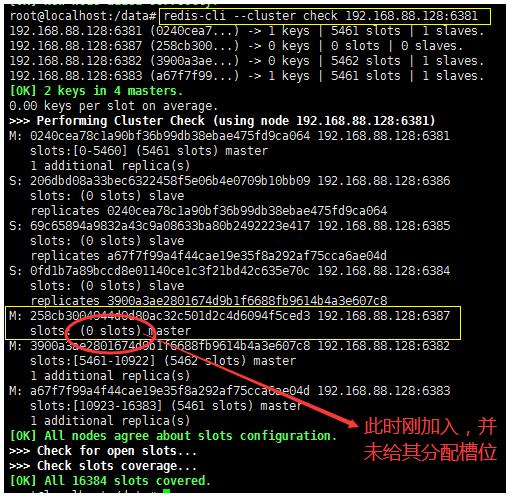
-
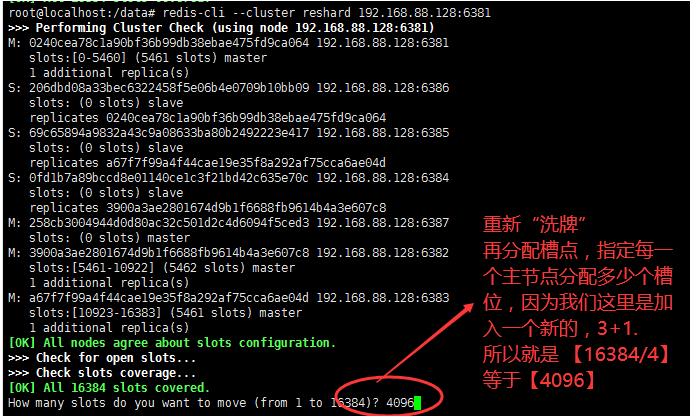
重新分派槽号—reshard
redis-cli --cluster reshard 192.168.88.128:6381- 指定再分配的节点槽位数量
4096-----16384/4
- 指定再分配的节点槽位数量
- 指定要给“谁”,是新机器node7
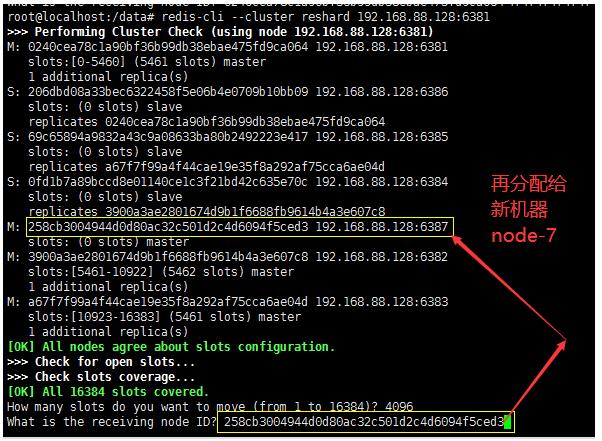
- 指定来源,是
所有节点—all
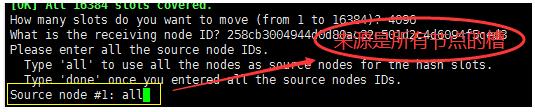
- 是否继续分配—yes

- 查看分配槽位后的结果
redis-cli --cluster check 192.168.88.128:6381
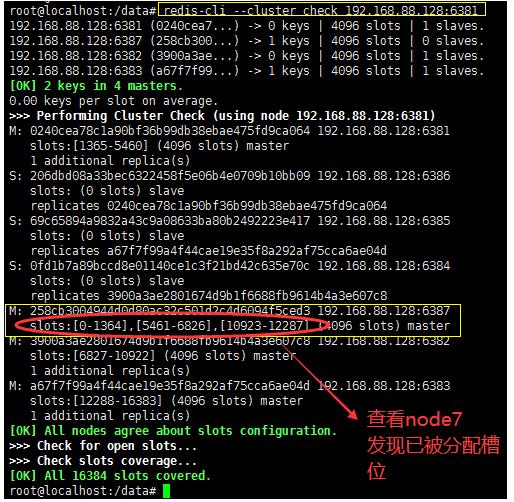
上面的node-7节点再分配到的操作发现是
[0-1364],[5461-6826],[10923-12287]结论是:他是将之前3个槽位的节点,
大家都抠出来一点再分配给新节点node-7
4、将node-8从节点加入Redis集群
redis-cli --cluster add-node 192.168.88.128:6388 192.168.88.128:6387 --cluster-slave --cluster-master-id 258cb3004944d0d80ac32c501d2c4d6094f5ced3
#258cb3004944d0d80ac32c501d2c4d6094f5ced3-------这个是6387的编号,按照自己实际情况
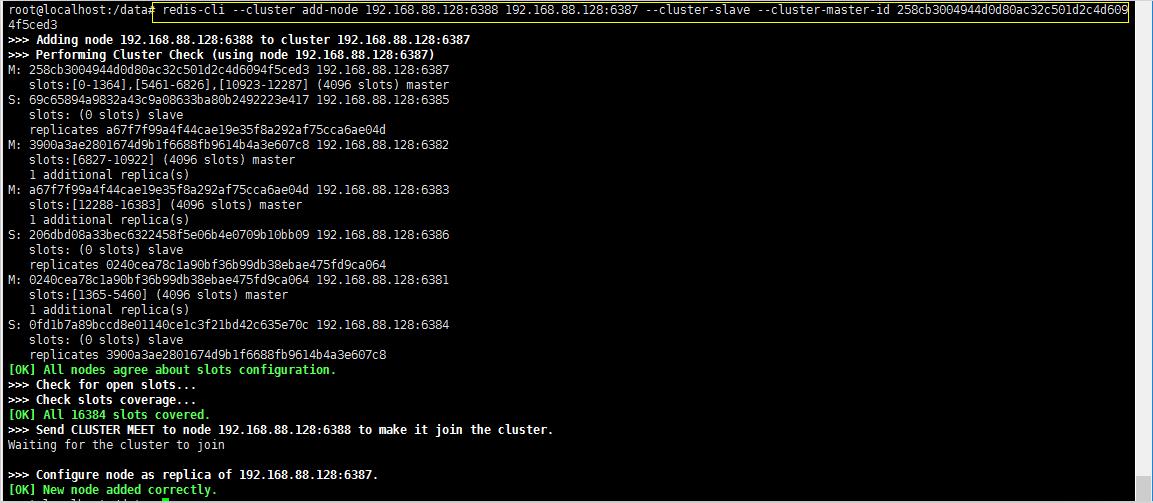
5、再次检查集群情况
redis-cli --cluster check 192.168.88.128:6382
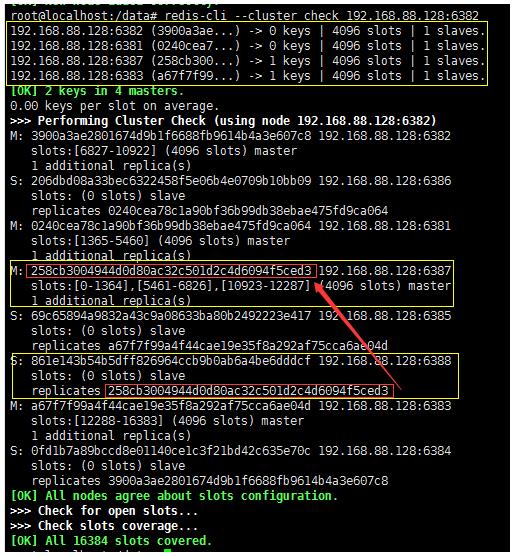
此时就有4台节点,且node-7是主节点,node-8是node-7的从节点。
那到这里主从扩容就结束了!
五、主从缩容
1、说明
将6387和6388下线,如果要删除一对主从,就需要先下线6388节点,再下线6387节点
2、检查集群情况1获得6388的节点ID
redis-cli --cluster check 192.168.88.128:6382
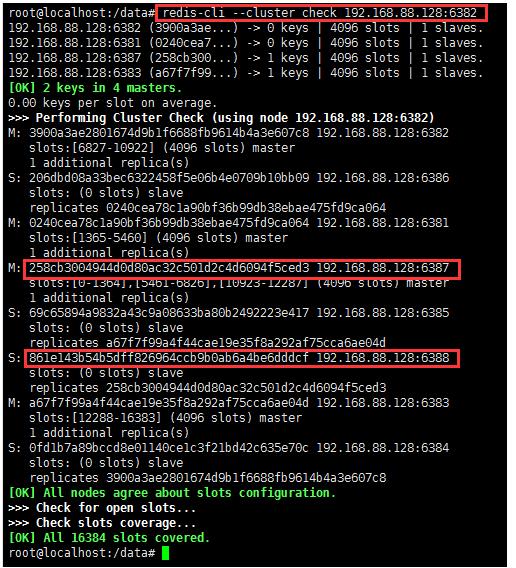
3、将集群中将从节点6388删除
redis-cli --cluster del-node 192.168.88.128:6388 861e143b54b5dff826964ccb9b0ab6a4be6dddcf

4、检查集群节点状态
redis-cli --cluster check 192.168.88.128:6382
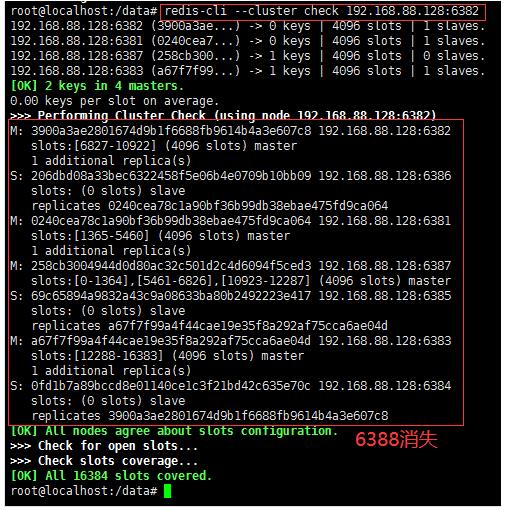
5、将6387的槽号清空,重新分配,本例将清出来的槽号都给6381
redis-cli --cluster reshard 192.168.88.128:6381
#流程,将6387中的4096个槽位全部发给6381
4096 #指定要分配的槽位
6381的id #指定谁接收槽位
6387的id #source从谁那里拿来给上面的接收人
yes
6、检查集群情况
redis-cli --cluster check 192.168.88.128:6382
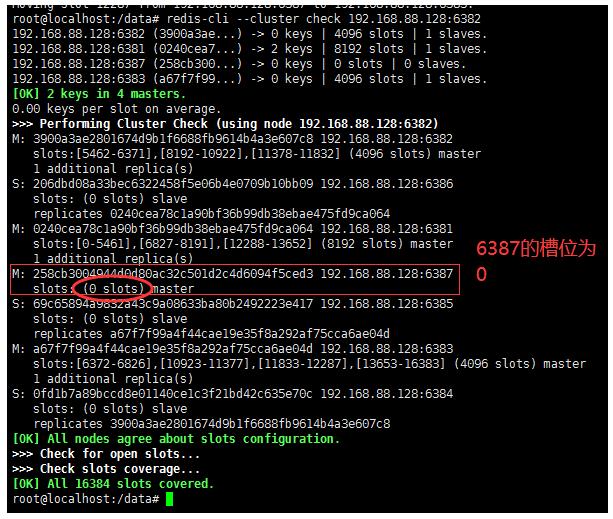
7、将6387删除
redis-cli --cluster del-node 192.168.88.128:6387 258cb3004944d0d80ac32c501d2c4d6094f5ced3
#258cb3004944d0d80ac32c501d2c4d6094f5ced3为6387的节点id

8、检查集群情况
redis-cli --cluster check 192.168.88.128:6382
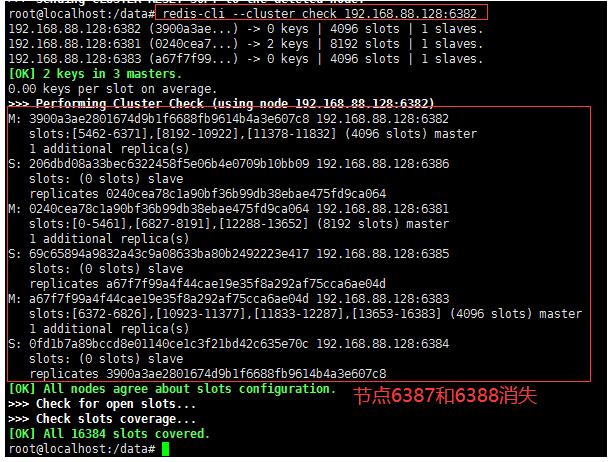
此时就删除了一对主从6387和6388节点
这就是本次记录分享的内容,感谢你能看到这里 (๑′ㅂ`๑)!!!
以上是关于阿昌教你通过docker搭建Redis集群的主要内容,如果未能解决你的问题,请参考以下文章