Redis底层数据结构详解
Posted LuckyWangxs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis底层数据结构详解相关的知识,希望对你有一定的参考价值。
Redis底层数据结构
上篇文章介绍了Redis底层涉及到的各类数据结构,今天这篇文章,是基于上一篇文章的,将五大数据类型结合底层数据结构一一剖析,如果读过上一篇文章,读这篇文章会更通透一些,没读过也没关系,也会有所收获
实际上Redis有五大基本类型,但它并非Redis底层的设计与实现,在整体实现上,采用了五大类数据类型,每类数据类型底层都采用了至少两种底层数据结构,使得每种数据类型在不同场景下发挥最佳效果,我画了一张Redis数据结构实现图,先来整体认识下(以下底层数据结构为主要的几种),下图基于Redis3.2版本之前
上图中每种数据结构下文都为介绍,可以先了解一下图中的内容,然后带着你的疑问往下读
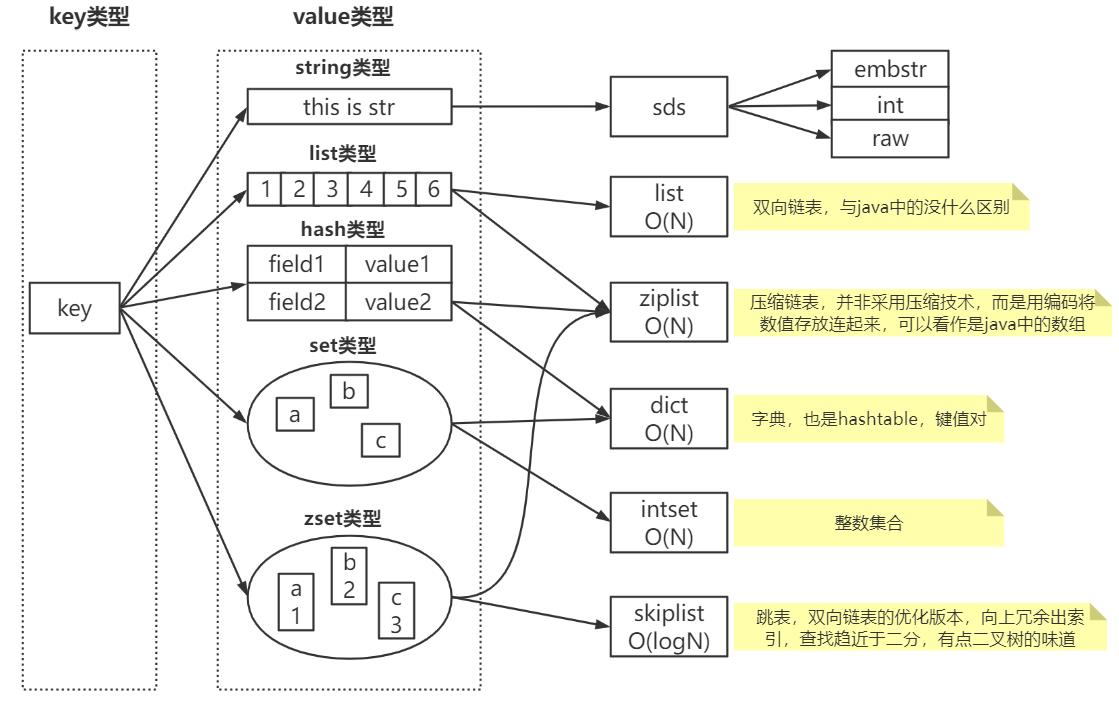
一、整体结构
Redis整体是以k-v组织起来的,底层并没有直接使用上述最后一列的几种数据结构,而是又封装了redisObject对象,这些对象内部通过属性控制,组成了我们常用的五大数据类型,Redis在创建一对键值对的时候,都会创建两个对象,一个是键对象,一个是值对象,而键对象,均为字符串对象,值对象一般来说会有不同类型,redisObject定义如下:
typedef struct redisObject
//类型, 4位表示
unsigned type;
//编码, 4位表示
unsigned encoding;
//指向底层数据结构的指针, 8字节表示
void *ptr;
//引用计数 4字节表示
int refcount;
//记录最后一次被程序访问的时间, 24位表示
unsigned lru;
robj
1. 类型:type属性
type:用于控制redisObject的类型得到我们常用的五大基本类型,对应关系如下:
| 对象 | tpye属性值 | 类型 |
|---|---|---|
| 字符串对象 | REDIS_STRING | “string” |
| 列表对象 | REDIS_LIST | “list” |
| 哈希对象 | REDIS_HASH | “hash” |
| 集合对象 | REDIS_SET | “set” |
| 有序集合对象 | REDIS_ZSET | “zset” |
可以通过命令来判断对象类型
127.0.0.1:6379> set key1 abc
OK
127.0.0.1:6379> type key1
string
127.0.0.1:6379> lpush list1 1 2 3
(integer) 3
127.0.0.1:6379> type list1
list
2. 编码:encoding属性
上述类型构成了五大基本数据类型,那么这几种数据类型在底层也采用了不同的数据结构(上图最后一列),每种数据类型至少采用了两种数据结构,使得在不同场景下,能发挥最好的性能,而不同的数据结构是由编码决定的,也就是代码的encoding属性,对应关系如下:
| 编码常量 | 对应的底层数据结构 |
|---|---|
| REDIS_ENCODING_INT | long类型的整数 |
| REDIS_ENCODING_EMBSTR | embstr编码的简单动态字符串 |
| REDIS_ENCODING_RAW | 简单动态字符串 |
| REDIS_ENCODING_HT | 字典 |
| REDIS_ENCODING_LINKEDLIST | 双向链表 |
| REDIS_ENCODING_ZIPLIST | 压缩列表 |
| REDIS_ENCODING_INTSET | 整数集合 |
| REDIS_ENCODING_SKIPLIST | 跳表 |
可以通过命令查看值对象的编码,也就是查看底层到底采用什么数据结构,如下,string类型的底层数据结构可以是embstr,也可以是int
127.0.0.1:6379> set key1 str
OK
127.0.0.1:6379> object encoding key1
"embstr"
127.0.0.1:6379> set key2 2
OK
127.0.0.1:6379> object encoding key2
"int"
127.0.0.1:6379> zadd set 3 a
(integer) 1
127.0.0.1:6379> object encoding set
"ziplist"
3. *ptr指针
这个东西指向底层数据结构,就相当于是Java中的引用类型一样,指向了堆中实际的对象
二、字符串对象(包含三种数据结构)
字符串对象底层采用了三种数据结构,分别是embstr、int、raw
① embstr结构
保存长度小于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)。
② int结构
保存长整型,也就是long类型的整数
③ raw结构
保存长度大于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)。
raw与embstr有什么区别呢?
1. 长度不同
raw用来存长字符串,embstr用来存短字符串
上文提到过大于39或者44字节,为什么以这个为界限呢?如何得来的呢?其实因为Redis底层的内存分配是统一管理的,分配的内存为2的倍数,通常为为2、4、8、16、32、64等,而Redis认为一个redisObject对象超过64字节了就算是长字符串,那么我们来算一下,根据第一节的对象定义,我们可以得到redisObject对象头占16字节,然后来算底层数据结构的大小
在3.2版本之前,SDS的定义为:
struct sdshdr
//记录buf数组中已使用的数量, 也为字符串长度
int len;
//记录 buf 数组中未使用的数量
int free;
//字节数组,用于保存字符串
char buf[];
我们可以看到 len、free都为int类型,也就是4字节,假设字符串为空,那么至少占4+4+1(\\01字节)=9字节,那么一整个redisObject对象最少占25字节,按照超过64字节为长字符串的标准,则实际字符串长度超过64-25=39字节即为大对象,转用raw格式存储
在3.2版本 对SDS做了优化,引入了五种sdshdr类型,3.2之前,只有一个sdshdr对象,是固定的,而3.2版本会根据字符串实际的长度选择一个sdshdr,其定义如下
struct __attribute__ ((__packed__)) sdshdr5
//实际上这个类型redis不会被使用。他的内部结构也与其他sdshdr不同,直接看sdshdr8就好。
unsigned char flags;
char buf[];
;
struct __attribute__ ((__packed__)) sdshdr8
uint8_t len;//表示当前sds的长度(单位是字节)
uint8_t alloc; //表示已为sds分配的内存大小(单位是字节)
unsigned char flags; //用一个字节表示当前sdshdr的类型,因为有sdshdr有五种类型,所以至少需要3位来表示000:sdshdr5,001:sdshdr8,010:sdshdr16,011:sdshdr32,100:sdshdr64。高5位用不到所以都为0。
char buf[];//sds实际存放的位置
;
struct __attribute__ ((__packed__)) sdshdr16
uint16_t len;
uint16_t alloc;
unsigned char flags;
char buf[];
;
struct __attribute__ ((__packed__)) sdshdr32
uint32_t len;
uint32_t alloc;
unsigned char flags;
char buf[];
;
struct __attribute__ ((__packed__)) sdshdr64
uint64_t len;
uint64_t alloc;
unsigned char flags;
char buf[];
;
在这个版本,假设实际字符串为空,则一个SDS最少需要占用sdshdr8: 1(len) + 1(alloc) + 1(flags) + 1(\\0) = 4字节,加上对象头16字节为20字节,按照Redis大于64字节为长字符串的标准,那么实际字符串超过64 - 20 = 44字节则为长字符串,转换为raw格式存储,
2. 底层存储方式不同
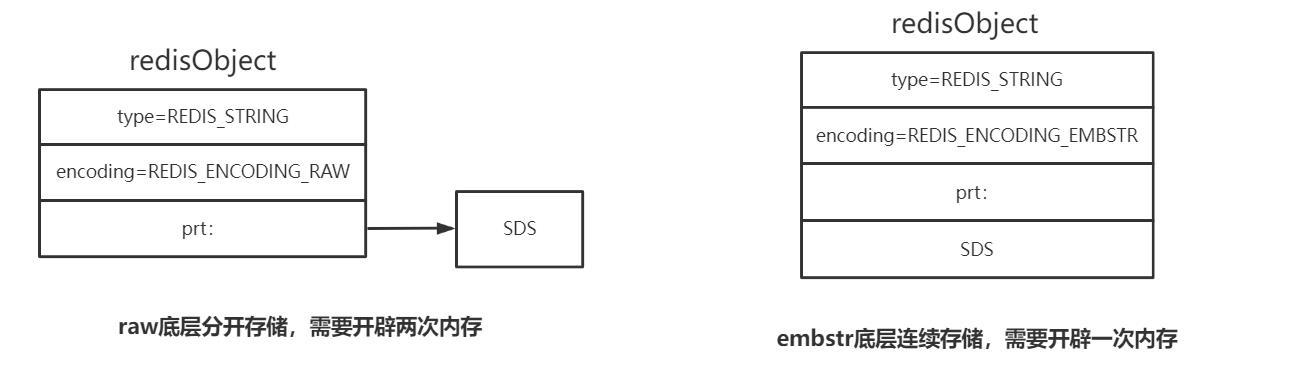
embstr与raw都使用redisObject和sds保存数据,区别在于,embstr的使用只分配一次内存空间(因此redisObject和sds是连续的),而raw需要分配两次内存空间(分别为redisObject和sds分配空间)。因此与raw相比embstr的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。而embstr的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,因此redis中的embstr实现为只读。
面试题:Redis中字符串的value最大不能超过多少呢?
Redis中key和字符串类型的value最大限制均为512M,key均为string类型
三、list对象
list数据类型的底层引用了两种底层数据结构,分别是linkedlist、ziplist;当然仅限于3.2版本之前,比如执行一下命令:
rpush key a b c
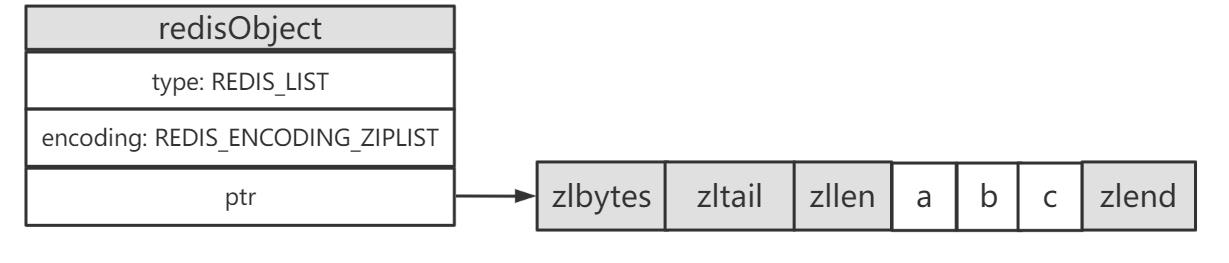
ziplist的存储结构如下:
linkedlist的存储结构如下:
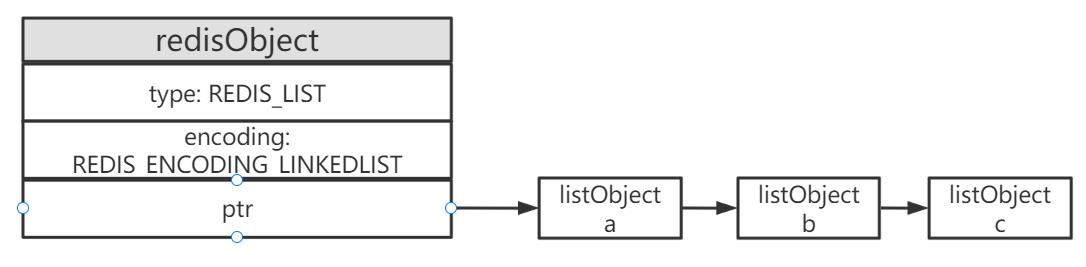
linkedlist是比ziplist占内存的,上篇文章详细介绍过,但是ziplist是有条件限制的:
- 当列表元素小于512个
- 每个元素的长度小于64字节
满足以上两个条件时会用采用ziplist,否则采用linkedlist,当然我们可以通过调整配置文件redis.conf的相关参数来控制,如下:
list-max-ziplist-entries 512
list-max-ziplist-value 64
但是这仅仅适用于Redis3.2版本之前,在3.2版本之后引入了quicklist,之后的list类型的底层都由quicklist实现的,这个数据结构,后续再讲
四、hash对象
hash类型底层采用了两种数据结构,分别是ziplist和dict,例如执行一下命令
hset person name wang
hset person age 18
hset person sex 1
来看一下压缩列表的存储结构

来看一下哈希表的存储结构
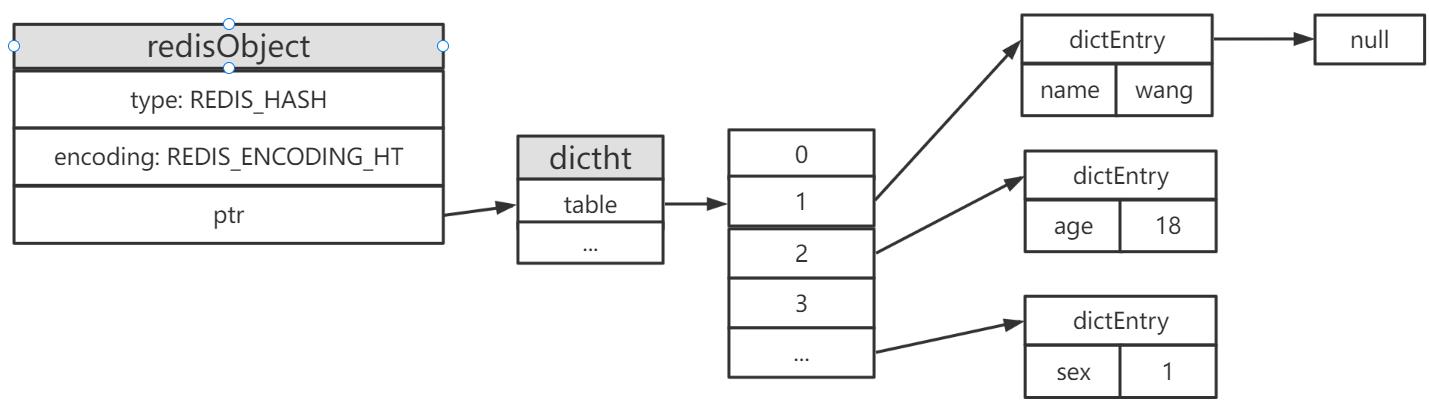
压缩列表是比较节省空间的,但同样也需要满足一下条件
- 列表保存元素个数小于512个
- 每个元素长度小于64字节
可以通过配置文件参数控制
hash-max-ziplist-entries 512 // 默认512个
hash-max-ziplist-value 64 // 默认64字节
五、set对象
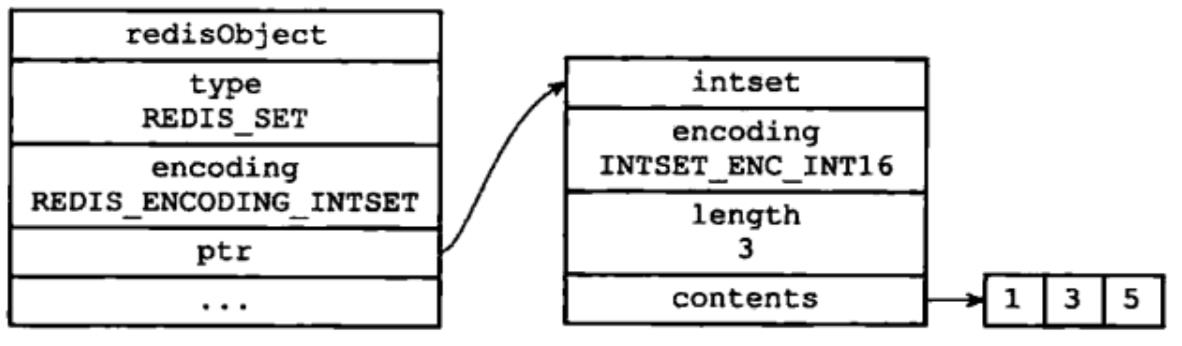
集合类型底层采用了两种数据结构,分别是intset和dict,使用哈希表的原理就像Java中的HashSet采用HashMap的key实现原理似的。
sadd sets 1 3 5
intset存储结构
哈希表存储结构
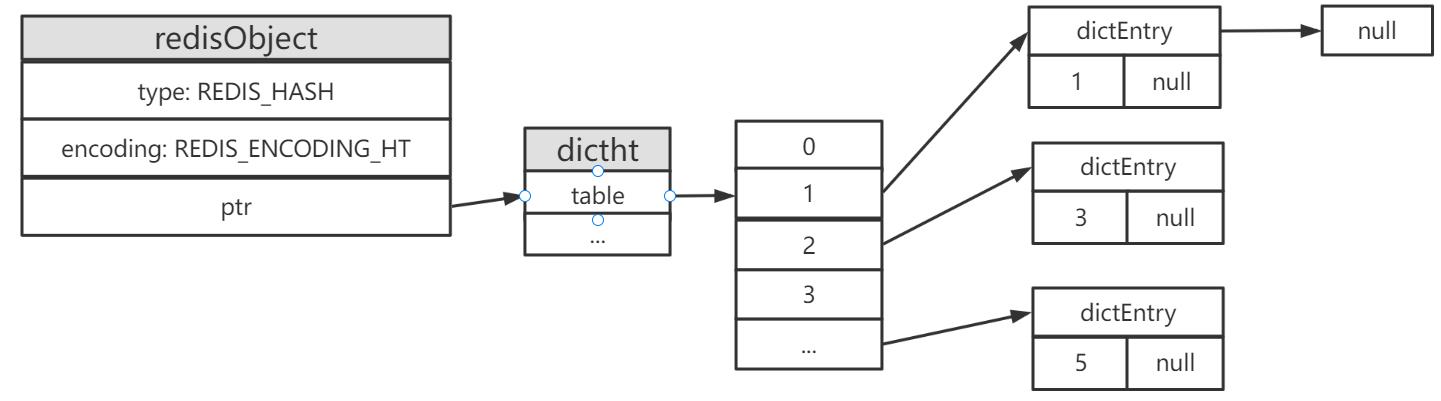
很明显可以知道intset是比较节省内存的,但是也有相应的条件约束
1、所有元素均为整数
2、元素个数小于512
如果不能满足以上条件,就会用哈希表结构,当然我们可以通过配置文件参数来调整启用哈希表的元素个数
set-max-intset-entries 512
六、zset对象
有序集合底层也是采用了两种数据结构,分别是跳表和压缩列表,例如我现在执行下面的命令
zadd score 75 zs 83 ls 65 ww

这是压缩列表的存储方式,按照从小到大依次存储,跳表就不再展示了,上篇文章有展示过,没什么差别,只用压缩表也有限制,可以根据不同业务场景进行调整:
1、保存的元素数量小于128
2、所有元素长度都小于64字节
依然是可以通过配置文件redis.conf的参数控制
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
总结
前面的文章有讲过Redis的基本类型,事务,搭建集群,集成到SoringBoot以及应用场景,但仅仅停留于表面,直到上一篇文章,介绍了底层六种数据结构,还有今天这篇底层与五大类型的结合,了解到这些,我们才能更有效地利用它,比如修改配置文件,让某种类型更适用于你的业务场景(我好像说了不得了的事情,又好像什么都没说),害~后续文章再讨论,手动狗头
Redis的五大常用类型涉及到的底层数据结构是有助于我们更全面理解Redis的,如果面试你只能说到五种数据类型以及各种数据类型的应用场景,那显然是不够的,现在这个行业非常内卷哈哈哈,如果你面试的岗位涉及到推荐,那大概率会问到set和zset这块的内容。成长之路不易,加油吧各位
参考文章
https://blog.csdn.net/weixin_43871678/article/details/115163940
https://www.cnblogs.com/cag2050/p/12524523.html
https://blog.csdn.net/weixin_33682719/article/details/88923569
https://www.cnblogs.com/ysocean/p/9102811.html#_label0
以上是关于Redis底层数据结构详解的主要内容,如果未能解决你的问题,请参考以下文章