李宏毅 机器学习 p5学习 笔记
Posted bohu83
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李宏毅 机器学习 p5学习 笔记相关的知识,希望对你有一定的参考价值。
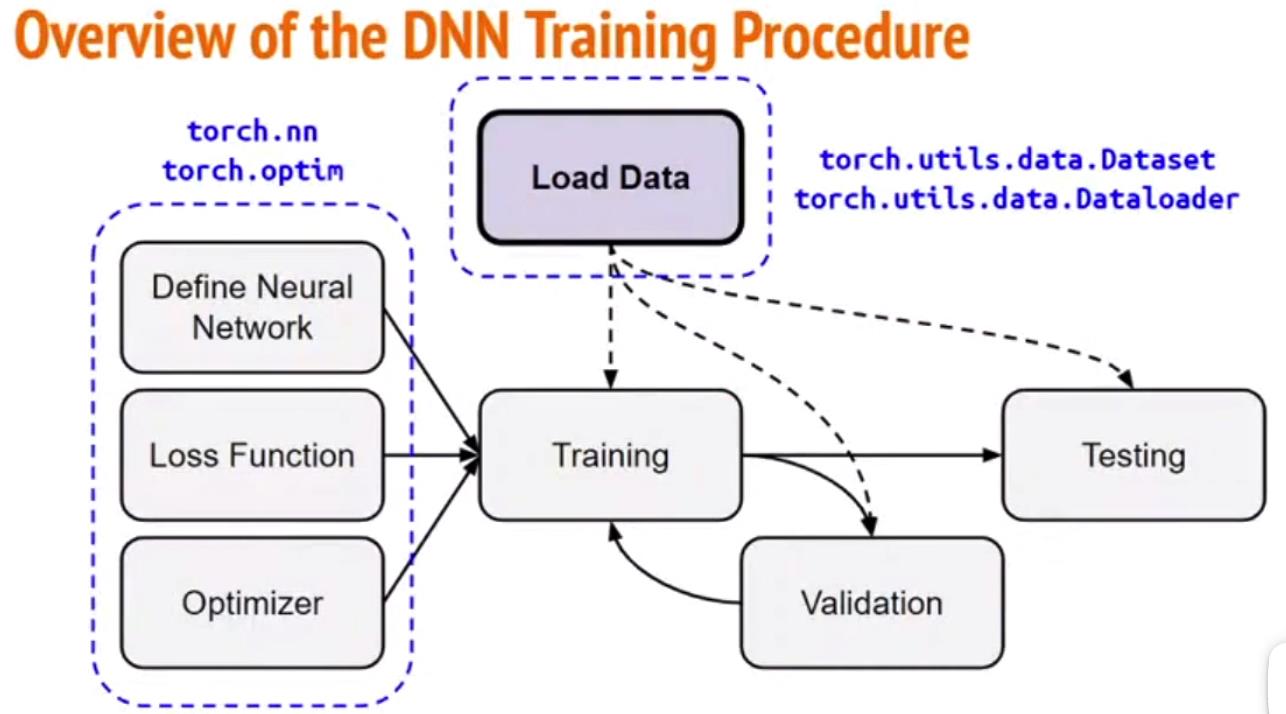
训练过程需要加载数据。其中需要dataset,dataloader.
dataset可以用来创建数据集.DataLoader 负责向训练传递数据的任务。

这个 dataset是一个表示数据集的抽象类。任何自定义的数据集都需要继承这个类并覆写len\\getitem方法。数据集就是一个负责处理索引(index)到样本(sample)映射的一个类(class)。
其中 len和getitem这两个函数
len:数据集的大小,getitem:查找样本。用来表示从索引到样本的映射(Map).
这个 跟之前面向对象语言很像,抽象类没法直接使用,必须使用子类 。
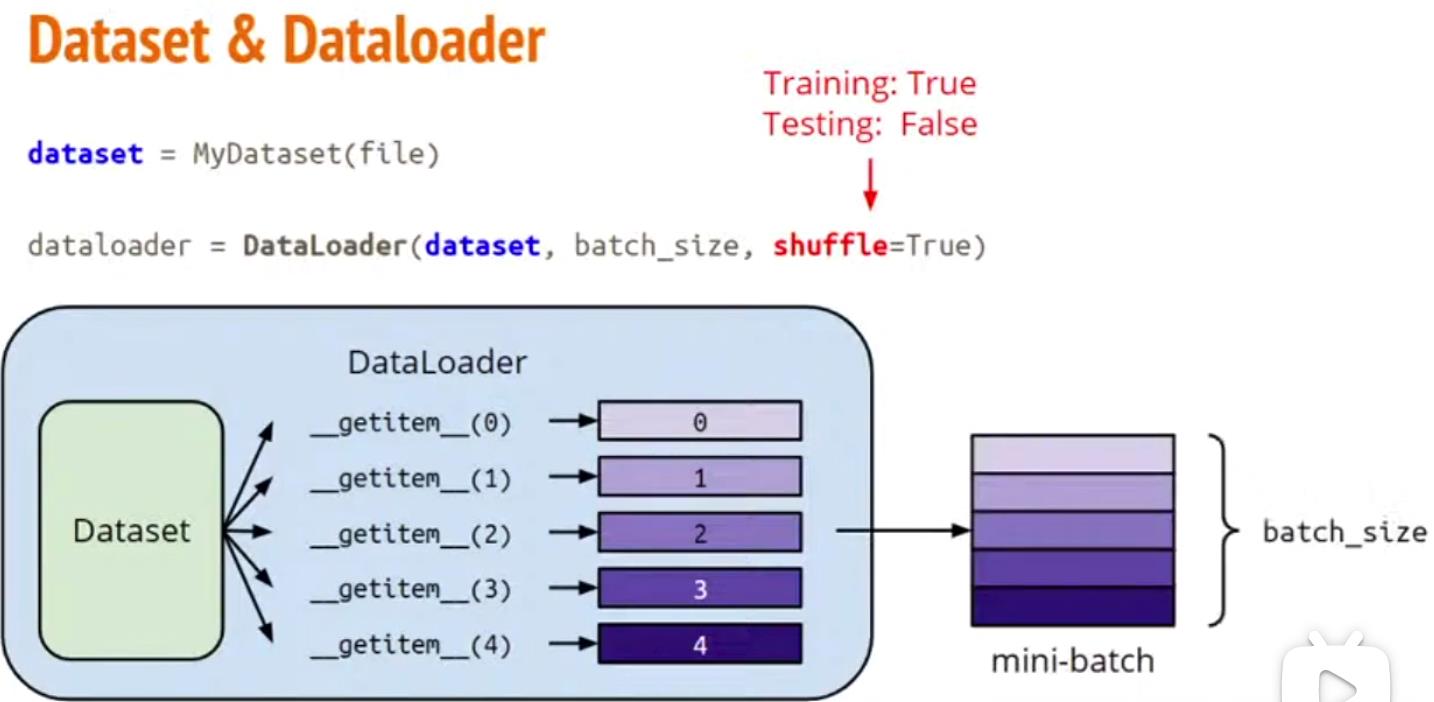
数据 加载 完了,接着看
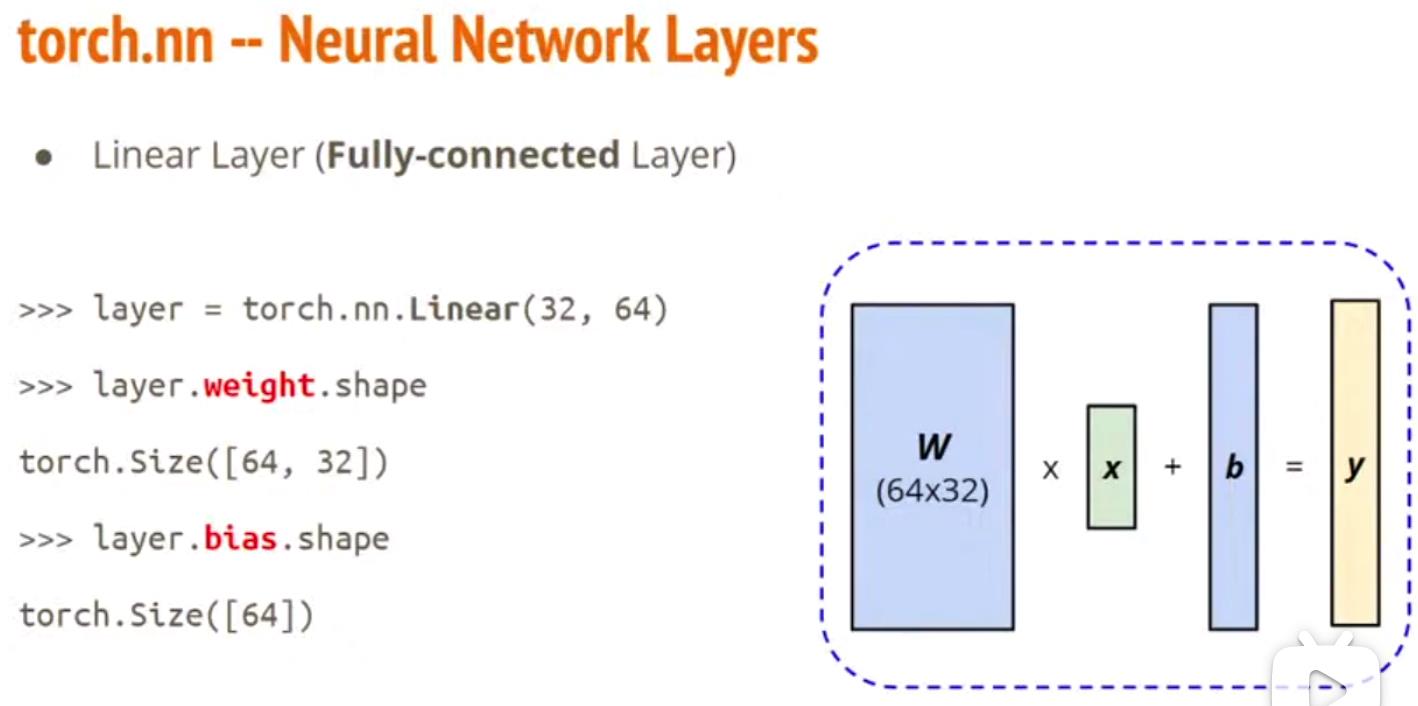
线性模型:
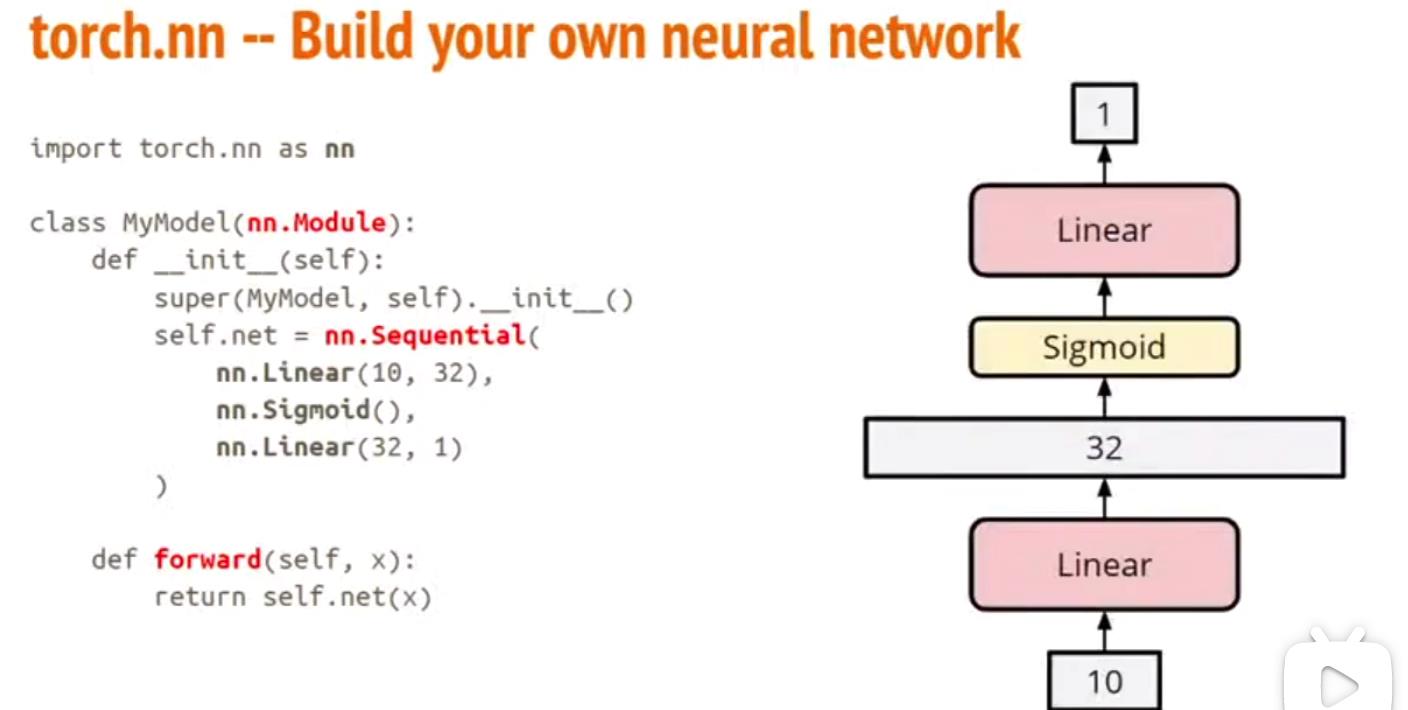
 损失函数
损失函数 
最优化(计算梯度)

training的 步骤





这节课老师快速介绍了一下使用pytorch深度学习的过程,还是需要看看练习题怎么做的,这个有些 对于新人有些模糊 。
以上是关于李宏毅 机器学习 p5学习 笔记的主要内容,如果未能解决你的问题,请参考以下文章