人工智能--基于注意力机制的新闻话题分类
Posted Abro.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能--基于注意力机制的新闻话题分类相关的知识,希望对你有一定的参考价值。
学习目标:
- 理解注意力机制的基本原理。
- 掌握利用注意力机制进行文本分类的方法。
学习内容:
利用循环神经网络和注意力机制进行新闻话题分类的代码,并调整网络结构,看是否可以提高识别率。
学习过程:
经过调整网络结构,得出下表结果,
| optimizer | lr | batch_ size | trainable | epochs | 验证集识别率 |
| Adam | 0.001 | 128 | False | 10 | 0.6055 |
| RMSprop | 0.001 | 128 | False | 10 | 0.6035 |
用了两个不同的优化器,利用循环神经网络和注意力机制进行文本分类的效果:
| Adam |
|
| RMSprop |
|
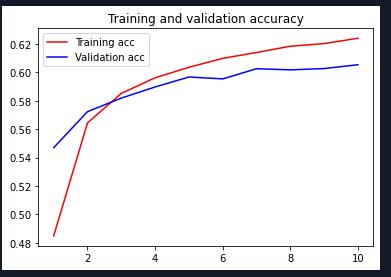
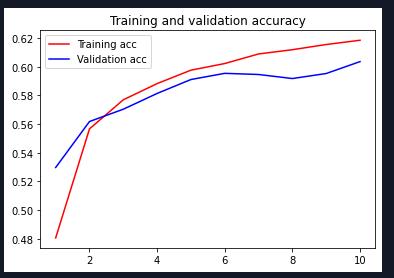
源码:
# In[1]: 读取新闻话题分类数据
import pandas as pd
df = pd.read_json(r'D:\\Cadabra_tools002\\course_data\\News_Category_Dataset.json', lines=True)
df.head()
# In[2]: 预处理,合并 "WORLDPOST"和"THE WORLDPOST"两种类别
df.category = df.category.map(lambda x:"WORLDPOST" if x == "THE WORLDPOST" else x)
categories = df.groupby('category')
print("total categories: ", categories.ngroups)
#print(categories.size())
# In[3]: 将单词进行标号
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
# 将标题和正文合并
df['text'] = df.headline + " " + df.short_description
# 将单词进行标号
tokenizer = Tokenizer()
tokenizer.fit_on_texts(df.text)
X = tokenizer.texts_to_sequences(df.text)
df['words'] = X
#print(X[:10])
#记录每条数据的单词数
df['word_length'] = df.words.apply(lambda i: len(i))
#清除单词数不足5个的数据条目
df = df[df.word_length >= 5]
df.word_length.describe()
# 把每个数据条目超过50个单词的部分去掉,
# 不足50个单词的补0,使得所有的条目具有相同的单词数量
maxlen = 50
X = list(sequence.pad_sequences(df.words, maxlen=maxlen))
# In[4]: 将类别进行编号
# 得到两个字典,可以从类别得到编号,或者从编号得到类别
categories = df.groupby('category').size().index.tolist()
category_int =
int_category =
for i, k in enumerate(categories):
category_int.update(k:i) # 类别 -> 编号
int_category.update(i:k) # 编号 -> 类别
df['c2id'] = df['category'].apply(lambda x: category_int[x])
# In[5]: 随机选取训练样本
import numpy as np
import keras.utils as utils
from sklearn.model_selection import train_test_split
X = np.array(X)
Y = utils.to_categorical(list(df.c2id))
# 将数据分成两部分,随机取80%用于训练,20%用于测试
seed = 29 # 随机种子
x_train, x_val, y_train, y_val = train_test_split(X, Y, test_size=0.2, random_state=seed)
# In[6]: 加载预先训练好的单词向量
EMBEDDING_DIM = 100
embeddings_index =
f = open(r'D:\\Cadabra_tools002\\course_data\\glove.6B.100d.txt',errors='ignore') # 每个单词用100个数字的向量表示
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Total %s word vectors.' %len(embeddings_index)) # 399913
# In[7]: 构造Embedding层,并用预训练好的单词向量初始化,注意该层不用训练
from keras.initializers import Constant
from keras.layers import Embedding
word_index = tokenizer.word_index
embedding_matrix = np.zeros((len(word_index) + 1, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
#根据单词挑选出对应向量
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
# Embedding层的输入的单词编号最大为 len(word_index)=86627
# 一个句子有 maxlen=50 个单词,每个单词编码成 EMBEDDING_DIM=100 维的向量
# Embedding层的输入大小为 (batch_size, maxlen)
# Embedding层的输出大小为 (batch_size, maxlen, EMBEDDING_DIM)
embedding_layer = Embedding(len(word_index)+1, EMBEDDING_DIM,
embeddings_initializer=Constant(embedding_matrix),
input_length = maxlen,
trainable=True #可以改成True
)
# In[]: 自注意力层的定义
from keras.layers import Layer
import keras.backend as K
class Self_Attention(Layer):
def __init__(self, output_dim, **kwargs):
# out_shape = (batch_size, time_steps, output_dim)
self.output_dim = output_dim
super(Self_Attention, self).__init__(**kwargs)
def build(self, input_shape):
# 为该层创建一个可训练的权重, 3个二维的矩阵(3,lstm_units,output_dim)
# input_shape = (batch_size, time_steps, lstm_units)
self.kernel = self.add_weight(name='kernel',
shape=(3,input_shape[2], self.output_dim),
initializer='uniform',
trainable=True)
super(Self_Attention, self).build(input_shape) # 一定要在最后调用它
def call(self, x):
WQ = K.dot(x, self.kernel[0])
WK = K.dot(x, self.kernel[1])
WV = K.dot(x, self.kernel[2])
# print("WQ.shape",WQ.shape)
# print("K.permute_dimensions(WK, [0, 2, 1]).shape",K.permute_dimensions(WK, [0, 2, 1]).shape)
QK = K.batch_dot(WQ,K.permute_dimensions(WK, [0, 2, 1]))
QK = QK / (64**0.5)
QK = K.softmax(QK)
# print("QK.shape",QK.shape)
V = K.batch_dot(QK,WV)
return V
def compute_output_shape(self, input_shape):
return (input_shape[0],input_shape[1],self.output_dim)
# In[11]: LSTM+注意力机制
from keras.layers import Input,Dense,Permute,Flatten
from keras.layers import LSTM,multiply,add,Lambda
from keras.models import Model
import matplotlib.pyplot as plt
import keras.backend as K
inputs = Input(shape=(maxlen,)) # 一批句子作为输入,每个句子有maxlen=50个单词
inputs_embedding = embedding_layer(inputs) # 输出(batch_size, maxlen=50, EMBEDDING_DIM=100)
# time_steps=maxlen=50
# INPUT_DIM=EMBEDDING_DIM=100
lstm_units = 32 #可改变单词向量的维度
# (batch_size, time_steps, INPUT_DIM) -> (batch_size, time_steps, lstm_units)
lstm_out = LSTM(lstm_units, return_sequences=True)(inputs_embedding)
#LSTM val_acc: 0.5705
lstm_out = Self_Attention(64)(lstm_out) # LSTM+Self_atten+sum: val_acc: 0.6117
## ATTENTION PART STARTS ------------------ #
## (batch_size, time_steps, lstm_units) -> (batch_size, lstm_units, time_steps)
#a = Permute((2, 1))(lstm_out)
#
## 对最后一维进行全连接,参数数量:time_steps*time_steps + time_steps
## 相当于获得每一个step中,每个lstm维度在所有step中的权重
## (batch_size, lstm_units, time_steps) -> (batch_size, lstm_units, time_steps)
#a = Dense(maxlen, activation='softmax')(a)
#
## (batch_size, lstm_units, time_steps) -> (batch_size, time_steps, lstm_units)
#a_probs = Permute((2, 1), name='attention_vec')(a)
#
## 权重和输入的对应元素相乘,注意力加权,lstm_out=lstm_out*a_probs
#lstm_out = multiply([lstm_out, a_probs], name='attention_mul')
## ATTENTION PART FINISHES ---------------- # LSTM+atten+sum:0.6028
#lstm_out = Permute((2, 1))(lstm_out)
lstm_out = Lambda(lambda X: K.sum(X,axis=1))(lstm_out)
#lstm_out = GlobalAveragePooling1D()(lstm_out)
#LSTM+sum val_acc: 0.6046
# (batch_size, time_steps, lstm_units) -> (batch_size, time_steps*lstm_units)
output = Dense(len(int_category), activation='softmax')(lstm_out)
model = Model([inputs], output)
model.summary()
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train, epochs=10, validation_data=(x_val, y_val), batch_size=128)
# val_acc: 0.5920
# 绘制训练过程中识别率和损失的变化
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.title('Training and validation accuracy')
plt.plot(epochs, acc, 'red', label='Training acc')
plt.plot(epochs, val_acc, 'blue', label='Validation acc')
plt.legend()
plt.show()
学习产出:
- 调整一下参数,但经过多次迭代后识别率还是有所下降,识别率上不了70%;
以上是关于人工智能--基于注意力机制的新闻话题分类的主要内容,如果未能解决你的问题,请参考以下文章