Beats与Logstash与Kibana知识概括
Posted GeorgeLin98
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Beats与Logstash与Kibana知识概括相关的知识,希望对你有一定的参考价值。
Beats与Logstash与Kibana知识概括
Beats
Beats简介:
- 轻量型数据采集器:Beats平台集合了多种单一用途数据采集器。它们从成百上千或成千上万台机
器和系统向Logstash 或 Elasticsearch发送数据。 - Beats 系列:全品类采集器,搞定所有数据类型。
①Filebeat:日志文件
②Metricbeat:指标
③Packetbeat:网络数据
④winlogbeat:windows事件日志
⑤Auditbeat:审计数据
⑥Heartbeat:运行时间监控”
⑦Functionbeat:无需服务器的采集器
Filebeat
Filebeat简介:
- 轻量型日志采集器:当您要面对成百上千、甚至成千上万的服务器、虚拟机和容器生成的日志时,请告别SSH吧。Filebeat将为您提供一种轻量型方法,用于转发和汇总日志与文件,让简单的事情不再繁杂。
- 汇总、“tail -f’和搜索:启动Filebeat后,打开Logs Ul,直接在Kibana中观看对您的文件进行tail 操作的过程。通过搜索栏按照服务、应用程序、主机、数据中心或者其他条件进行筛选,以跟踪您的全部汇总日志中的异常行为。
- 架构:用于监控、收集服务器日志文件。
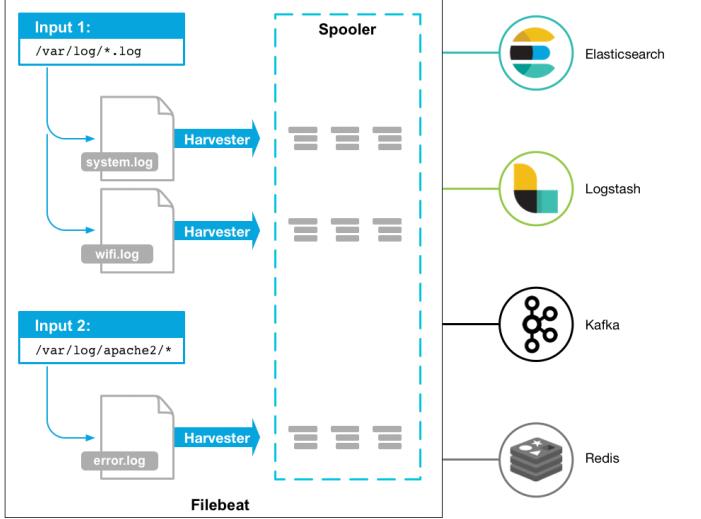
部署与运行:
mkdir /itcast/beats
tar -xvf filebeat-6.5.4-linux-x86_64.tar.gz
cd filebeat-6.5.4-linux-x86_64
#创建如下配置文件 itcast.yml
filebeat.inputs:
- type: stdin
enabled: true
setup.template.settings:
index.number_of_shards: 3
output.console:
pretty: true
enable: true
#启动filebeat
./filebeat -e -c itcast.yml
#输入hello运行结果如下:
hello
- 结果:
"@timestamp": "2019-01-12T12:50:03.585Z",
"@metadata": #元数据信息
"beat": "filebeat",
"type": "doc",
"version": "6.5.4"
,
"source": "",
"offset": 0,
"message": "hello", #输入的内容
"prospector": #标准输入勘探器
"type": "stdin"
,
"input": #控制台标准输入
"type": "stdin"
,
"beat": #beat版本以及主机信息
"name": "itcast01",
"hostname": "itcast01",
"version": "6.5.4"
,
"host":
"name": "itcast01"
读取文件:
#配置读取文件项 itcast-log.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /itcast/beats/logs/*.log
setup.template.settings:
index.number_of_shards: 3
output.console:
pretty: true
enable: true
#启动filebeat
./filebeat -e -c itcast-log.yml
#/haoke/beats/logs下创建a.log文件,并输入如下内容
hello
world
#观察filebeat输出
"@timestamp": "2019-01-12T14:16:10.192Z",
"@metadata":
"beat": "filebeat",
"type": "doc",
"version": "6.5.4"
,
"host":
"name": "itcast01"
,
"source": "/haoke/beats/logs/a.log",
"offset": 0,
"message": "hello",
"prospector":
"type": "log"
,
"input":
"type": "log"
,
"beat":
"version": "6.5.4",
"name": "itcast01",
"hostname": "itcast01"
"@timestamp": "2019-01-12T14:16:10.192Z",
"@metadata":
"beat": "filebeat",
"type": "doc",
"version": "6.5.4"
,
"prospector":
"type": "log"
,
"input":
"type": "log"
,
"beat":
"version": "6.5.4",
"name": "itcast01",
"hostname": "itcast01"
,
"host":
"name": "itcast01"
,
"source": "/haoke/beats/logs/a.log",
"offset": 6,
"message": "world"
- 可以看出,已经检测到日志文件有更新,立刻就会读取到更新的内容,并且输出到控制台。
自定义字段:
#配置读取文件项 itcast-log.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /itcast/beats/logs/*.log
tags: ["web"] #添加自定义tag,便于后续的处理
fields: #添加自定义字段
from: itcast-im
fields_under_root: true #true为添加到根节点,false为添加到子节点中
setup.template.settings:
index.number_of_shards: 3
output.console:
pretty: true
enable: true
#启动filebeat
./filebeat -e -c itcast-log.yml
#/haoke/beats/logs下创建a.log文件,并输入如下内容
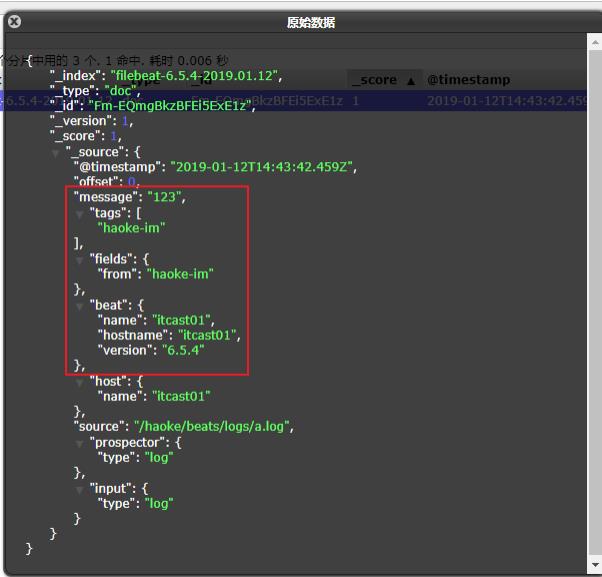
123
#执行效果
"@timestamp": "2019-01-12T14:37:19.845Z",
"@metadata":
"beat": "filebeat",
"type": "doc",
"version": "6.5.4"
,
"offset": 0,
"tags": [
"haoke-im"
],
"prospector":
"type": "log"
,
"beat":
"name": "itcast01",
"hostname": "itcast01",
"version": "6.5.4"
,
"host":
"name": "itcast01"
,
"source": "/itcast/beats/logs/a.log",
"message": "123",
"input":
"type": "log"
,
"from": "haoke-im"
输出到Elasticsearch:
# itcast-log.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /itcast/beats/logs/*.log
tags: ["haoke-im"]
fields:
from: haoke-im
fields_under_root: false
setup.template.settings:
index.number_of_shards: 3 #指定索引的分区数
output.elasticsearch: #指定ES的配置
hosts: ["192.168.1.7:9200","192.168.1.7:9201","192.168.1.7:9202"]
- 在日志文件中输入新的内容进行测试:
Filebeat工作原理:
- Filebeat由两个主要组件组成:prospector 和 harvester。
①harvester:
<1>负责读取单个文件的内容。
<2>如果文件在读取时被删除或重命名,Filebeat将继续读取文件。
②prospector
<1>prospector 负责管理harvester并找到所有要读取的文件来源。
<2>如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个harvester。
<3>Filebeat目前支持两种prospector类型:log和stdin。 - Filebeat如何保持文件的状态:
①Filebeat 保存每个文件的状态并经常将状态刷新到磁盘上的注册文件中。
②该状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行。
③如果输出(例如Elasticsearch或Logstash)无法访问,Filebeat会跟踪最后发送的行,并在输出再次可用时继续读取文件。
④在Filebeat运行时,每个prospector内存中也会保存的文件状态信息,当重新启动Filebeat时,将使用注册文件的数据来重建文件状态,Filebeat将每个harvester在从保存的最后偏移量继续读取。
⑤文件状态记录在data/registry文件中。 - 启动命令:
./filebeat -e -c itcast.yml
./filebeat -e -c itcast.yml -d "publish"
#参数说明
-e: 输出到标准输出,默认输出到syslog和logs下
-c: 指定配置文件
-d: 输出debug信息
#测试: ./filebeat -e -c itcast-log.yml -d "publish"
DEBUG [publish] pipeline/processor.go:308 Publish event:
"@timestamp": "2019-01-12T15:03:50.820Z",
"@metadata":
"beat": "filebeat",
"type": "doc",
"version": "6.5.4"
,
"offset": 0,
"tags": [
"haoke-im"
],
"input":
"type": "log"
,
"prospector":
"type": "log"
,
"beat":
"name": "itcast01",
"hostname": "itcast01",
"version": "6.5.4"
,
"source": "/haoke/beats/logs/a.log",
"fields":
"from": "haoke-im"
,
"host":
"name": "itcast01"
,
"message": "456"
读取Nginx日志文件:
# itcast-nginx.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /usr/local/nginx/logs/*.log
tags: ["nginx"]
setup.template.settings:
index.number_of_shards: 3 #指定索引的分区数
output.elasticsearch: #指定ES的配置
hosts: ["192.168.40.133:9200","192.168.40.134:9200","192.168.40.135:9200"]
#启动 ./filebeat -e -c itcast-nginx.yml
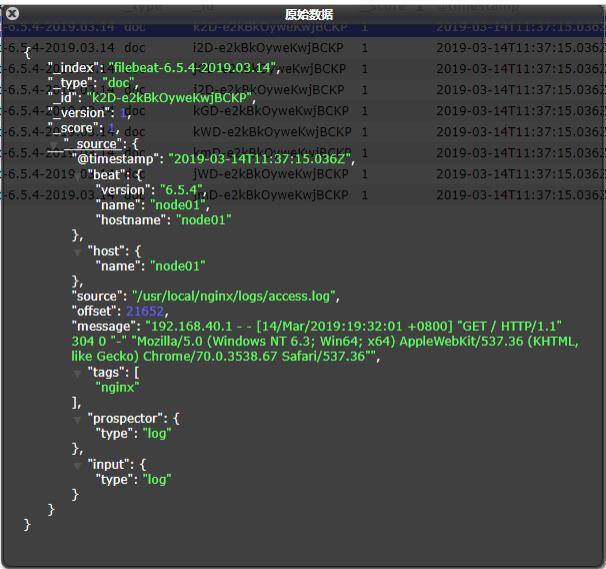
- 启动后,可以在Elasticsearch中看到索引以及查看数据:可以看到在message中已经获取到了nginx的日志,但是,内容并没有经过处理,只是读取到原数据,那么对于我们后期的操作是不利的。
Module:
- 前面要想实现日志数据的读取以及处理都是自己手动配置的,其实,在Filebeat中,有大量的Module,可以简化我们的配置,直接就可以使用,如下:
./filebeat modules list
Enabled:
Disabled:
apache2
auditd
elasticsearch
haproxy
icinga
iis
kafka
kibana
logstash
mongodb
mysql
nginx
osquery
postgresql
redis
suricata
system
traefik
- 可以看到,内置了很多的module,但是都没有启用,如果需要启用需要进行enable操作。可以发现,nginx的module已经被启用。
./filebeat modules enable nginx #启动
./filebeat modules disable nginx #禁用
Enabled:
nginx
Disabled:
apache2
auditd
elasticsearch
haproxy
icinga
iis
kafka
kibana
logstash
mongodb
mysql
redis
osquery
postgresql
suricata
system
traefik
nginx module 配置:
- module: nginx
# Access logs
access:
enabled: true
var.paths: ["/usr/local/nginx/logs/access.log*"]
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths:
# Error logs
error:
enabled: true
var.paths: ["/usr/local/nginx/logs/error.log*"]
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths: 9101112131415161718
- 配置filebeat:
#vim itcast-nginx.yml
filebeat.inputs:
#- type: log # enabled: true
# paths:
# - /usr/local/nginx/logs/*.log
# tags: ["nginx"]
setup.template.settings:
index.number_of_shards: 3
output.elasticsearch:
hosts: ["192.168.40.133:9200","192.168.40.134:9200","192.168.40.135:9200"]
filebeat.config.modules:
path: $path.config/modules.d/*.yml
reload.enabled: false
- 测试:
./filebeat -e -c itcast-nginx.yml
#启动会出错,如下
ERROR fileset/factory.go:142 Error loading pipeline: Error loading pipeline for
fileset nginx/access: This module requires the following Elasticsearch plugins:
ingest-user-agent, ingest-geoip. You can install them by running the following
commands on all the Elasticsearch nodes:
sudo bin/elasticsearch-plugin install ingest-user-agent
sudo bin/elasticsearch-plugin install ingest-geoip
#解决:需要在Elasticsearch中安装ingest-user-agent、ingest-geoip插件
#在资料中可以找到,ingest-user-agent.tar、ingest-geoip.tar、ingest-geoip-conf.tar 3个文件
#其中,ingest-user-agent.tar、ingest-geoip.tar解压到plugins下
#ingest-geoip-conf.tar解压到config下 #问题解决。
- 测试发现,数据已经写入到了Elasticsearch中,并且拿到的数据更加明确了:
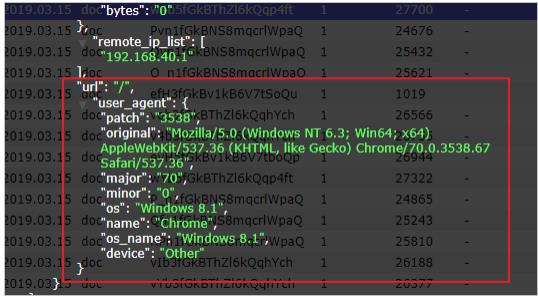
- 当然了,其他的Module的用法参考官方文档,链接:官方文档
Metricbeat
Metricbeat简介:
- Metricbeat轻量型指标采集器:用于从系统和服务收集指标。Metricbeat能够以一种轻量型的方式,输送各种系统和服务统计数据,从CPU 到内存,从 Redis到 Nginx,不一而足。
- 作用:
①定期收集操作系统或应用服务的指标数据
②存储到Elasticsearch中,进行实时分析
Metricbeat组成:
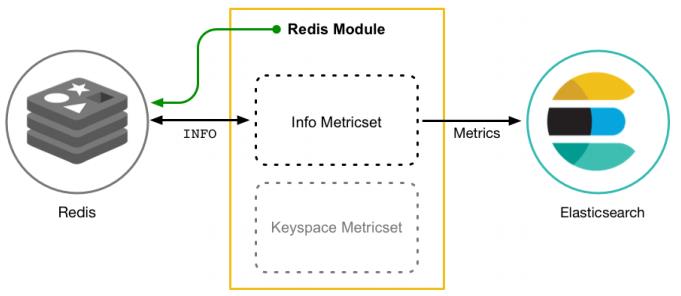
- Metricbeat有2部分组成,一部分是Module,另一部分为Metricset。
①Module:收集的对象,如:mysql、redis、nginx、操作系统等;
②Metricset:收集指标的集合,如:cpu、memory、network等; - 以Redis Module为例:
部署与收集系统指标:
tar -xvf metricbeat-6.5.4-linux-x86_64.tar.gz
cd metricbeat-6.5.4-linux-x86_64
vim metricbeat.yml
metricbeat.config.modules:
path: $path.config/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
index.codec: best_compression
setup.kibana:
output.elasticsearch:
hosts: ["192.168.40.133:9200","192.168.40.134:9200","192.168.40.135:9200"]
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
#启动
./metricbeat -e
- 在ELasticsearch中可以看到,系统的一些指标数据已经写入进去了:
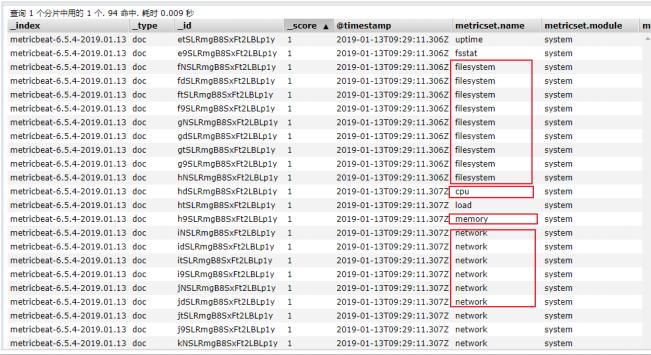
- system module配置:
root@itcast01:modules.d# cat system.yml
# Module: system
# Docs: https://www.elastic.co/guide/en/beats/metricbeat/6.5/metricbeat-module- system.html
- module: system
period: 10s
metricsets:
- cpu
- load
- memory
- network
- process
- process_summary
#- core
#- diskio
#- socket
process.include_top_n:
by_cpu: 5 # include top 5 processes
by CPU by_memory: 5 # include top 5 processes by memory
- module: system
period: 1m
metricsets:
- filesystem
- fsstat
processors:
- drop_event.when.regexp:
system.filesystem.mount_point: '^/(sys|cgroup|proc|dev|etc|host|lib)($|/)'
- module: system
period: 15m
metricsets:
- uptime
#- module: system
# period: 5m
# metricsets:
# - raid
# raid.mount_point: '/'
Module:
./metricbeat modules list #查看列表
Enabled:
system #默认启用
Disabled:
aerospike
apache
ceph
couchbase
docker
dropwizard
elasticsearch
envoyproxy
etcd
golang
graphite
haproxy
http
jolokia
kafka
kibana
kubernetes
kvm
logstash
memcached
mongodb
munin
mysql
nginx
php_fpm
postgresql
prometheus
rabbitmq
redis
traefik
uwsgi
vsphere
windows
zookeeper
Nginx Module:
- 开启nginx的状态查询:在nginx中,需要开启状态查询,才能查询到指标数据。
#重新编译nginx
./configure --prefix=/usr/local/nginx --with-http_stub_status_module
make
make install
./nginx -V #查询版本信息
nginx version: nginx/1.11.6
built by gcc 4.4.7 20120313 (Red Hat 4.4.7-23) (GCC)
configure arguments: --prefix=/usr/local/nginx --with-http_stub_status_module
#配置nginx
vim nginx.conf
location /nginx-status
stub_status on;
access_log off;
- 测试:
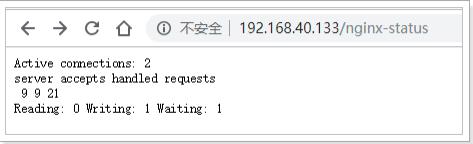
- 结果说明:
①Active connections:正在处理的活动连接数
②server accepts handled requests
<1>第一个 server 表示Nginx启动到现在共处理了9个连接
<2>第二个 accepts 表示Nginx启动到现在共成功创建 9 次握手
<3>第三个 handled requests 表示总共处理了 21 次请求
<4>请求丢失数 = 握手数 - 连接数 ,可以看出目前为止没有丢失请求
②Reading: 0 Writing: 1 Waiting: 1
<1>Reading:Nginx 读取到客户端的 Header 信息数
<2>Writing:Nginx 返回给客户端 Header 信息数
<3>Waiting:Nginx 已经处理完正在等候下一次请求指令的驻留链接(开启keep-alive的情况下,这个值等于Active - (Reading+Writing)) - 配置Nginx Module:
#启用redis module
./metricbeat modules enable nginx
#修改redis module配置
vim modules.d/nginx.yml
# Module: nginx
# Docs: https://www.elastic.co/guide/en/beats/metricbeat/6.5/metricbeat-module- nginx.html
- module: nginx
#metricsets:
# - stubstatus
period: 10s
# Nginx hosts
hosts: ["http://192.168.40.133"]
# Path to server status. Default server-status
server_status_path: "nginx-status"
#username: "user"
#password: "secret"
#启动
./metricbeat -e
- 测试:
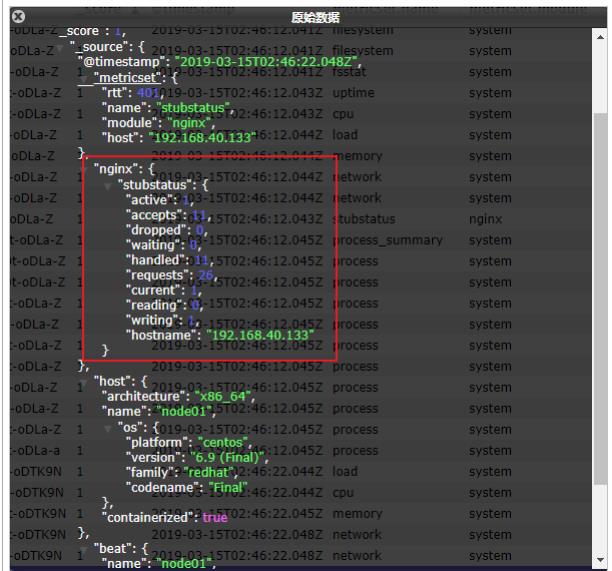
- 可以看到,nginx的指标数据已经写入到了Elasticsearch。
Kibana
Kibana简介:
- 您使用 Elastic Stack的窗口 通过Kibana ,您能够对Elasticsearch 中的数据进行可视化并在Elastic Stack进行操作,因此您可以在这里解开任何疑问∶例如,为何会在凌晨2:00收到传呼,雨水会对季度数据造成怎样的影响。
- Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和Elasticsearch协作。您可以 使用 Kibana 对 Elasticsearch索引中的数据进行搜索、查看、交互操作。您可以很方便的利用图表、表格及地图对 数据进行多元化的分析和呈现。
- 链接:官网
配置安装:
#解压安装包
tar -xvf kibana-6.5.4-linux-x86_64.tar.gz
#修改配置文件
vim config/kibana.yml server.host: "192.168.40.133" #对外暴露服务的地址
elasticsearch.url: "http://192.168.40.133:9200" #配置Elasticsearch
#启动
./bin/kibana
#通过浏览器进行访问
http://192.168.40.133:5601/app/kibana
- 可以看到kibana页面,并且可以看到提示,导入数据到Kibana。
Kibana详解:
- 功能说明:
- 数据探索:
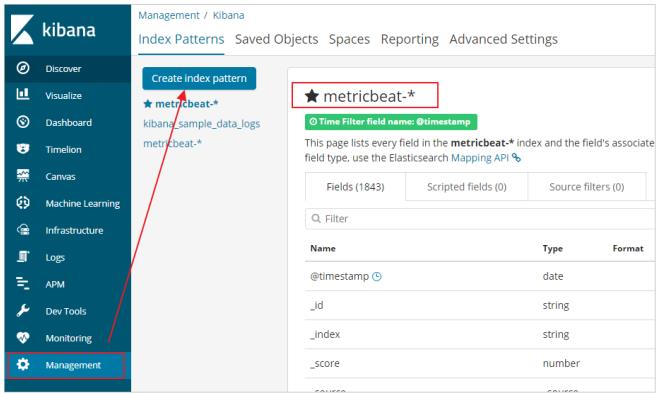
即可查看索引数据:
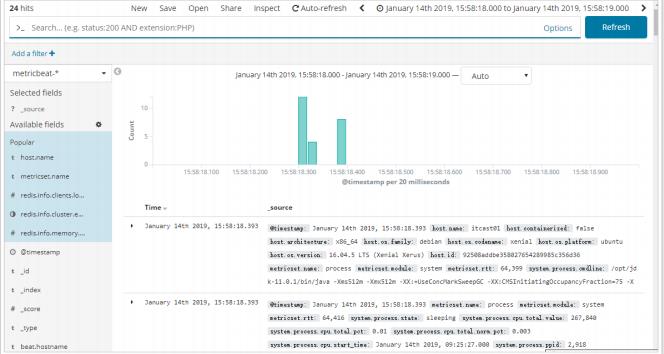
- Metricbeat 仪表盘:可以将Metricbeat的数据在Kibana中展示,即可在Kibana中看到仪表盘数据。
#修改metricbeat配置
setup.kibana: host: "192.168.40.133:5601" #安装仪表盘到Kibana ./metricbeat setup --dashboards
- Nginx 指标仪表盘:
- Nginx 日志仪表盘:可以看到nginx的FileBeat的仪表盘了。
#修改配置文件 vim itcast-nginx.yml
filebeat.inputs:
#- type: log
# enabled: true
# paths:
# - /usr/local/nginx/logs/*.log
# tags: ["nginx"]
setup.template.settings:
index.number_of_shards: 3
output.elasticsearch:
hosts: ["192.168.40.133:9200","192.168.40.134:9200","192.168.40.135:9200"] filebeat.config.modules:
path: $path.config/modules.d/*.yml
reload.enabled: false
setup.kibana:
host: "192.168.40.133:5601"
#安装仪表盘到kibana
./filebeat -c itcast-nginx.yml setup
- 自定义图表:
①在Kibana中,也可以进行自定义图表,如制作柱形图:
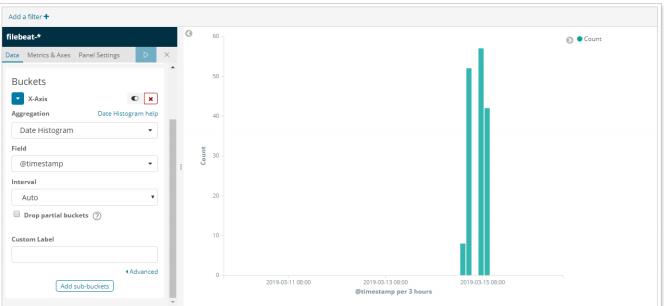
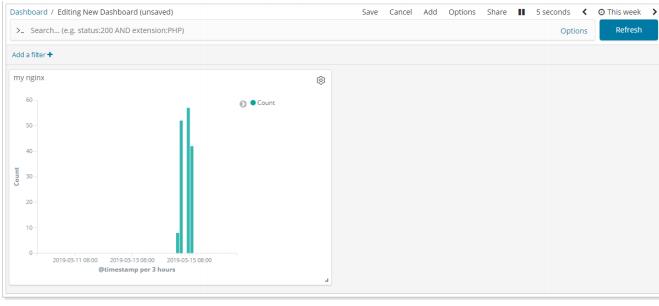
②将图表添加到自定义Dashboard中:
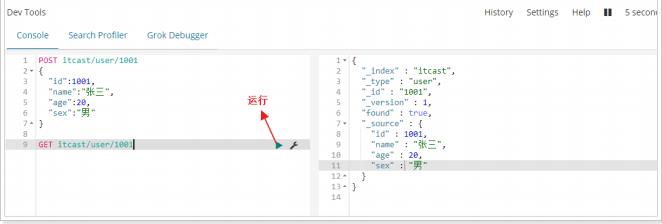
- 开发者工具:在Kibana中,为开发者的测试提供了便捷的工具使用,如下:
Logstash
Logstash简介:
- 集中、转换和存储数据:Logstash是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。(我们的存储库当然是Elasticsearch。)
- 用途:
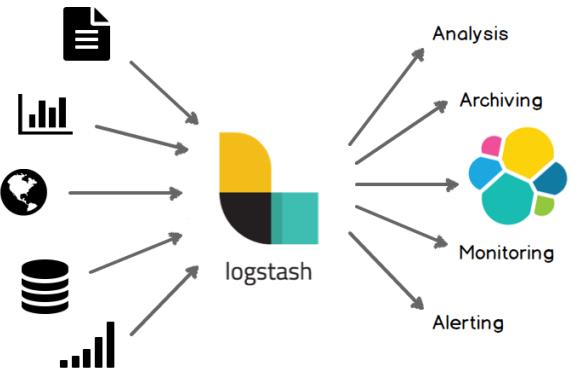
部署安装:
#检查jdk环境,要求jdk1.8+
java -version
#解压安装包
tar -xvf logstash-6.5.4.tar.gz
#第一个logstash示例
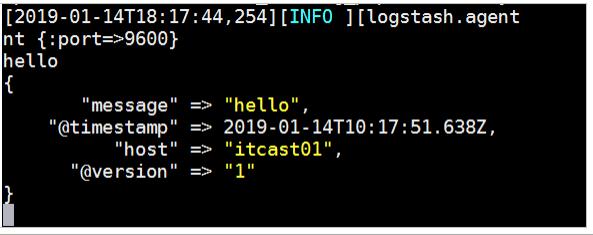
bin/logstash -e 'input stdin output stdout '
- 执行效果如下:
配置详解:
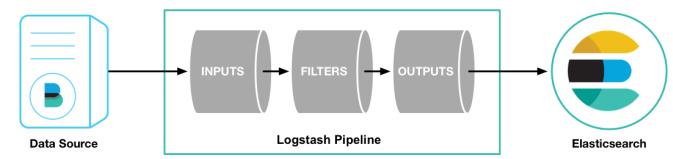
- Logstash的配置有三部分,如下:
input #输入
stdin ... #标准输入
filter #过滤,对数据进行分割、截取等处理
...
output #输出
stdout ... #标准输出
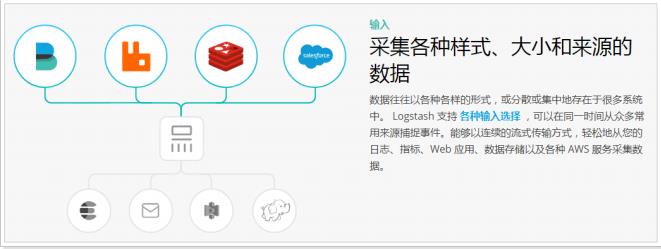
- 输入:
①采集各种样式、大小和来源的数据,数据往往以各种各样的形式,或分散或集中地存在于很多系统中。
②Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
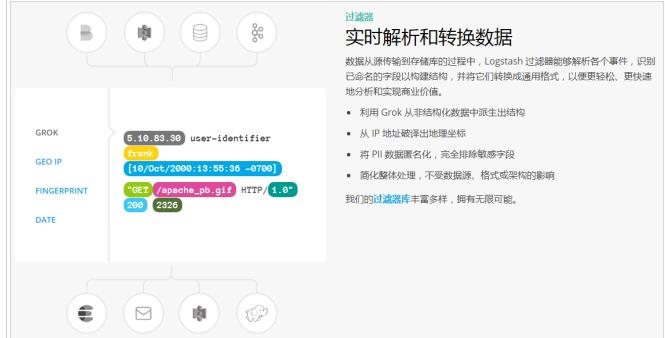
- 过滤:
①实时解析和转换数据
②数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
- 输出:Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
读取自定义日志:
- 前面我们通过Filebeat读取了nginx的日志,如果是自定义结构的日志,就需要读取处理后才能使用,所以,这个时候就需要使用Logstash了,因为Logstash有着强大的处理能力,可以应对各种各样的场景。
- 日志结构:可以看到,日志中的内容是使用“|”进行分割的,使用,我们在处理的时候,也需要对数据做分割处理。
2019-03-15 21:21:21|ERROR|读取数据出错|参数:id=1002 1
- 编写配置文件:
#vim itcast-pipeline.conf
input
file
path => "/itcast/logstash/logs/app.log"
start_position => "beginning"
filter
mutate
split => "message"=>"|"
output
stdout
codec => rubydebug
- 启动测试:可以看到,数据已经被分割了。
#启动
./bin/logstash -f ./itcast-pipeline.conf
#写日志到文件
echo "2019-03-15 21:21:21|ERROR|读取数据出错|参数:id=1002" >> app.log
#输出的结果
"@timestamp" => 2019-03-15T08:44:04.749Z,
"path" => "/itcast/logstash/logs/app.log",
"@version" => "1",
"host" => "node01",
"message" => [
[0] "2019-03-15 21:21:21",
[1] "ERROR",
[2] "读取数据出错",
[3] "参数:id=1002"
]
- 输出到Elasticsearch:
input
file
path => "/itcast/logstash/logs/app.log"
#type => "system"
start_position => "beginning"
filter
mutate
split => "message"=>"|"
output
elasticsearch
hosts => [ "192.168.40.133:9200","192.168.40.134:9200","192.168.40.135:9200"]
#启动
./bin/logstash -f ./itcast-pipeline.conf
#写入数据
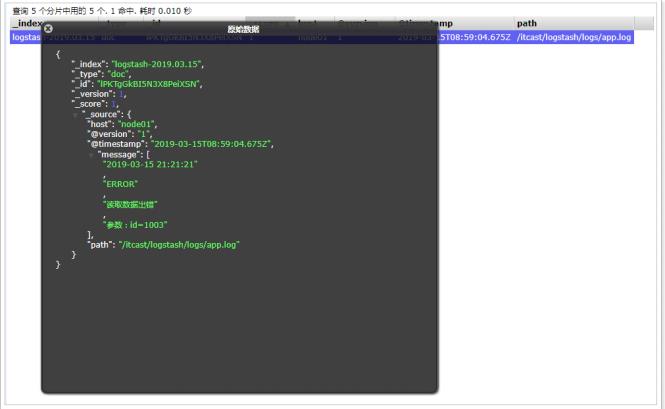
echo "2019-03-15 21:21:21|ERROR|读取数据出错|参数:id=1003" >> app.log
- 测试:
以上是关于Beats与Logstash与Kibana知识概括的主要内容,如果未能解决你的问题,请参考以下文章
Filebeat+Kafka+Logstash+ElasticSearch+Kibana 日志采集方案
Elasticsearch + Logstash + Filebeat + Kibana搭建ELK日志分析平台(官方推荐的BEATS架构)
Elasticsearch + Logstash + Beats + Kibana