Elasticsearch 7.X 集群分片 及 水平扩容 讲解
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 7.X 集群分片 及 水平扩容 讲解相关的知识,希望对你有一定的参考价值。
一、ES 中的分片
上篇文章我们讲解了ES 7.X 的集群环境搭建,本篇主要讲解下ES的分片和扩容。
上篇文章地址:https://blog.csdn.net/qq_43692950/article/details/122244793
一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有 10 亿文档数据的索引占据 1TB 的磁盘空间,而任一节点都可能没有这样大的磁盘空间。或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力,每一份就称之为分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因:
- 允许你水平分割 / 扩展你的内容容量。
- 允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合和搜索请求,是完全由Elasticsearch 管理的,对于作为用户的你来说,这些都是透明的,无需过分关心。
注意:一个 Lucene 索引 我们在 Elasticsearch 称作 分片 。 一个
Elasticsearch 索引 是分片的集合。 当 Elasticsearch 在索引中搜索的时候, 他发送查询到每一个属于索引的分片(Lucene 索引),然后合并每个分片的结果到一个全局的结果集。
ES 中的分片可以在创建索引的时候进行指定,例如创建一个user索引:
向ES服务器发送PUT 请求:
http://192.168.40.130:9200/user
请求体内容为:
"settings":
"number_of_shards": 3,
"number_of_replicas": 1
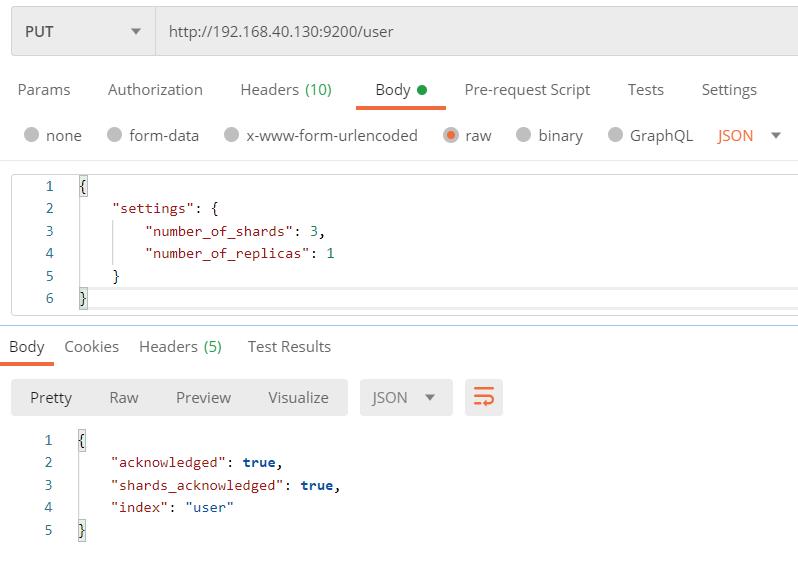
表示user索引被分为了3个分片,每个分片有一个副本,就是一共有6个分片。
可以通过 elasticsearch-head这个插件方便的看到分布情况:
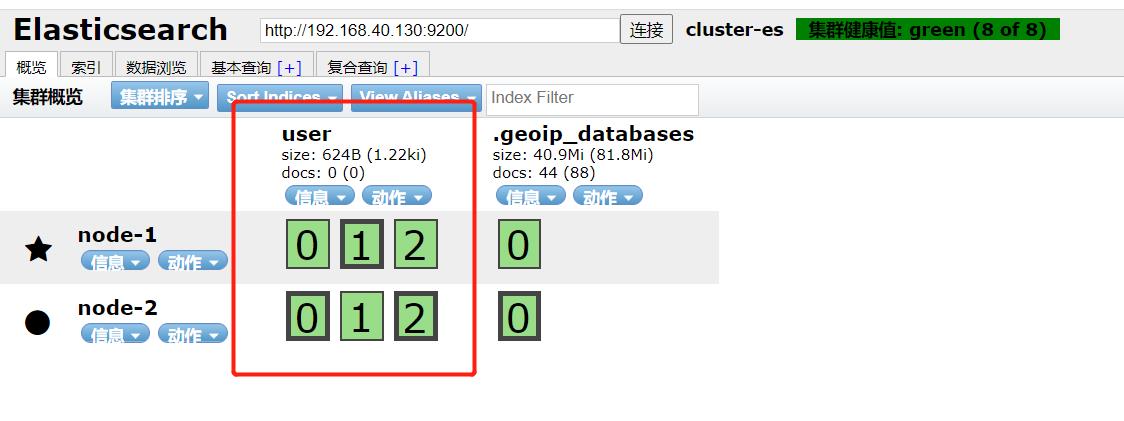
可以看到有6个分片了,其中加粗的为主分片。
这里还需要注意的是,分片数一旦指定后面就无法修改,副本数是可以修改的,因为分片是采用的Hash/分片数 的方式进行数据的划分的,所以在创建索引时,就要规划好分片的数量。
二、ES 副本扩容
在一个网络 / 云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
副本分片之所以重要,有两个主要原因:
-
提供了高可用性,即使主分片节点宕机,可以从其中一个副本节点升级为主分片继续提供服务。
-
扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
总之,每个索引可以被分成多个分片。一个索引也可以被复制 0 次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。默认情况下,Elasticsearch 中的每个索引被分片 1 个主分片和 1 个复制,这意味着,如果你的集群中至少
有两个节点,你的索引将会有 1 个主分片和另外 1 个复制分片(1 个完全拷贝),这样的话每个索引总共就有 2 个分片,我们需要根据索引需要确定分片个数。
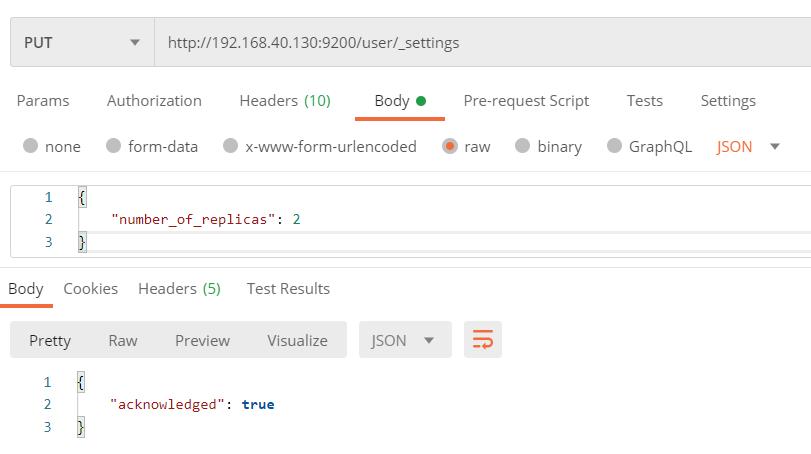
上面我们创建了一个user索引,前面提到分片数一旦指定即无法修改,但副本数是可以动态改变的,下面进行ES副本的扩容操作,将每个分片的副本由1扩容到2,扩容出来应该是9个节点。
向ES服务器发送请求:
http://192.168.40.130:9200/user/_settings
请求体内容:
"number_of_replicas": 2
查看 elasticsearch-head 中的变化:
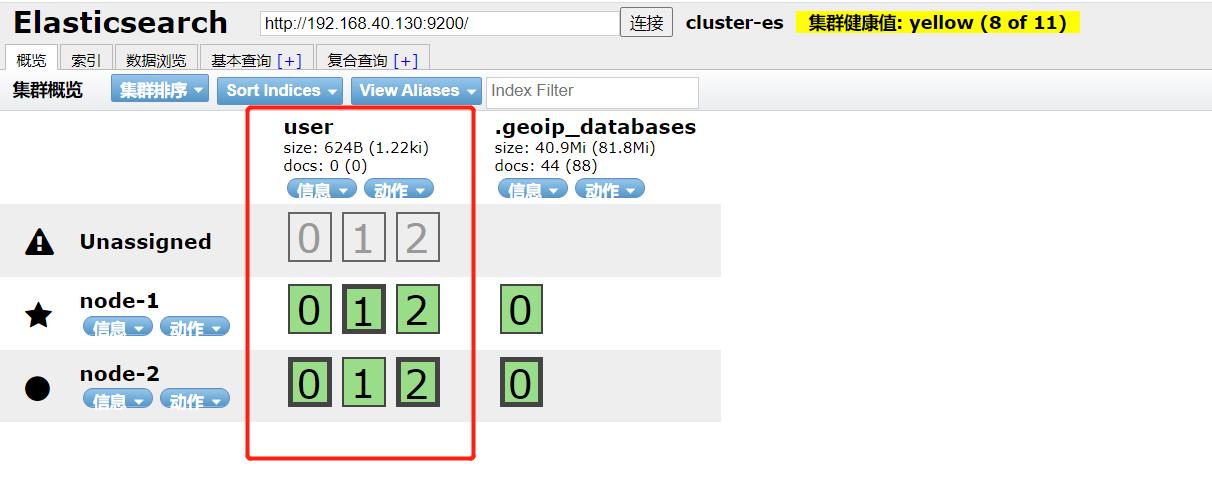
现在已经扩容到9个节点了,但是看到扩容出的副本是灰色的,切集群环境变成了黄色,黄色表示分片依然可以正常提供服务,但是有副本集没有正常启动,这里确实有三个副本是灰的没有正常启动,但是为什么没有正常启动呢?
因为ES在每个ES节点上,不会同时分布两个相同的副本及主分片,以确保某个ES节点宕机,无法进行容灾的转移 。但这里我们一共就有两个ES节点,切分片数为3个,所以只能正常运行3 主分片 + 3副本 6个节点,但我们是3主分片且每个有2个副本,即9个节点,所以有三个副本不可用。
但是从上面就可以看出,已经扩容成功了,下面我们再扩容出一个ES节点,那不就可以让那 3 个副本有空间运行了。
三、扩容ES节点
找一台新的主机,在该主机上搭建好ES所需的环境,可以参考上篇文章的内容,修改ES 的 config/elasticsearch.yml ,写入以下内容:
#集群名称
cluster.name: cluster-es
#节点名称,每个节点的名称不能重复
node.name: node-3
#ip 地址,每个节点的地址不能重复
network.host: 192.168.40.168
#是不是有资格主节点
node.master: true
node.data: true
http.port: 9200
# head 插件需要这打开这两个配置,解决跨域问题
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["node-1"]
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["192.168.40.130:9300","192.168.40.167:9300","192.168.40.168:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
#集群内同时启动的数据任务个数,默认是 2 个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个
cluster.routing.allocation.node_concurrent_recoveries: 16
#初始化数据恢复时,并发恢复线程的个数,默认 4 个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
主要修改的是 cluster.name 必须和原集群保持一致。node.name 要保证唯一,不要和现有集群重复。discovery.seed_hosts 就填写现有集群所有的主机ip 和自己的 ip。
下面启动 ES :
./elasticsearch -d
下面查看 elasticsearch-head
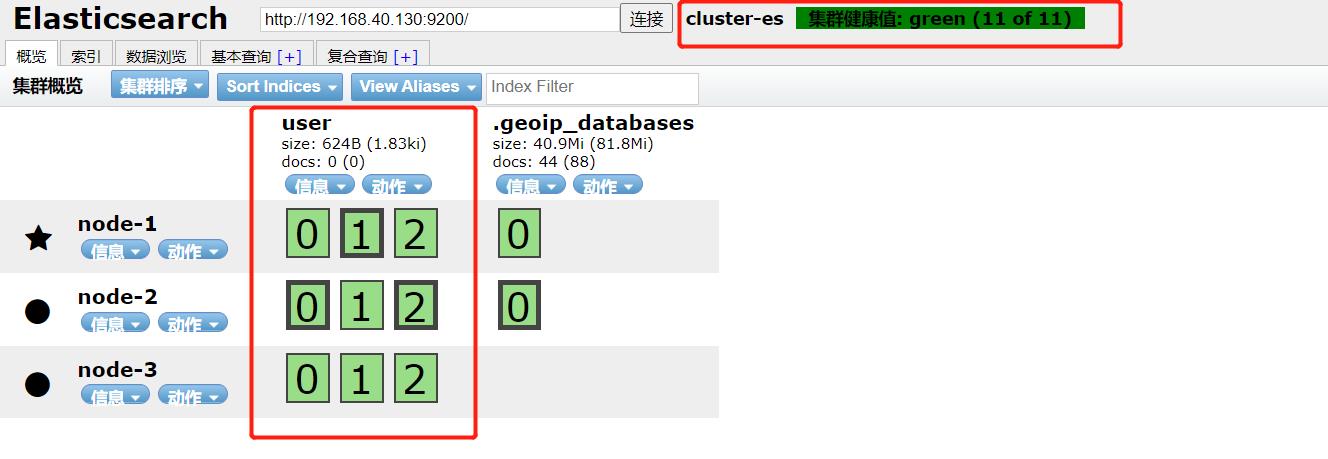
集群状态就恢复到绿色了。可以看出node-1上有第一个分片的主分片,如果将node-1 机器停掉,再看 elasticsearch-head
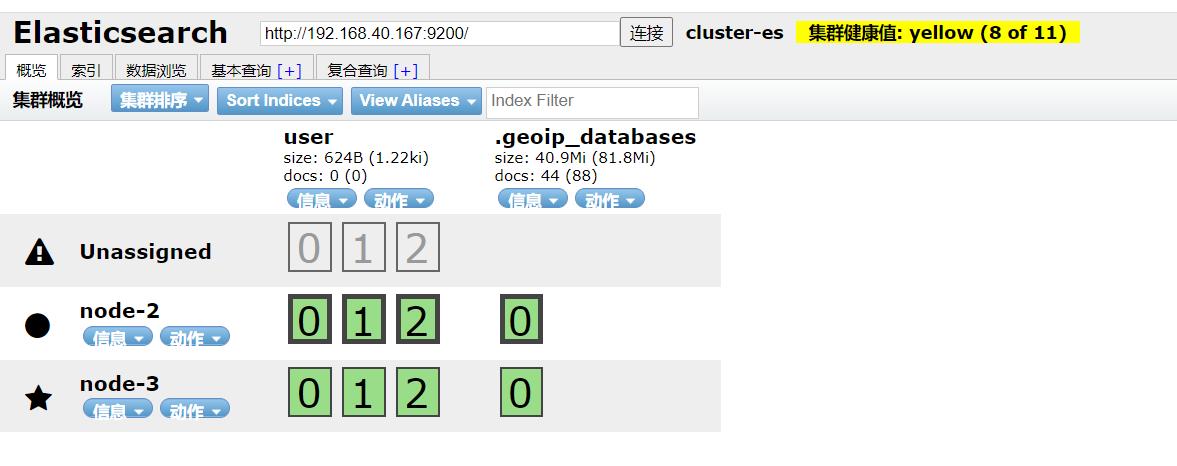
分片已经划分到了node-2节点上。

喜欢的小伙伴可以关注我的个人微信公众号,获取更多学习资料!
以上是关于Elasticsearch 7.X 集群分片 及 水平扩容 讲解的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch 7.X 中文分词器 ik 使用,及词库的动态扩展
Day123.ElasticSearch:CAP定理集群搭建架构原理及分片倒排索引面试题