Elasticsearch 7.X 中文分词器 ik 使用,及词库的动态扩展
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 7.X 中文分词器 ik 使用,及词库的动态扩展相关的知识,希望对你有一定的参考价值。
一、ik中文分词器
上篇文章我们学习了ES集群分片和水平扩容,前面再使用的时候应该就会发现,在做match 匹配时,默认会进行分词,但当查询内容是中文时,分词效果是一个字被认定了一个词,这显然不符合我们对中文分词的效果,因此本篇我们讲解下ES中中文分词器ik 的使用。
上篇文章地址:https://blog.csdn.net/qq_43692950/article/details/122246286
ik是基于java开发的轻量级的中文分词工具包。它是以开源项目Luence为主体的,结合词典分词和文法分析算法的中文分词组件,下面是ik的Github地址:
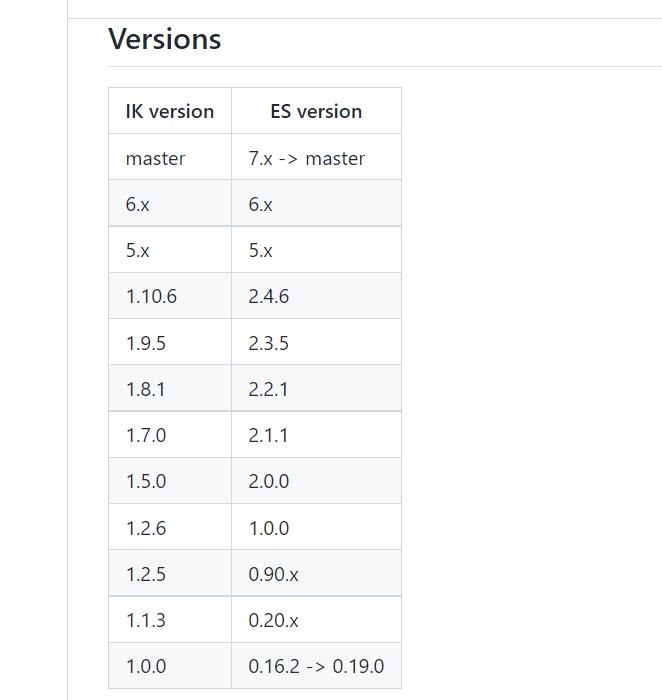
官方提供的 ik 和 ES的对应版本关系:
ik 的分词粒度:
ik_max_word:会将文本做最细粒度(拆到不能再拆)的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌」,会穷尽各种可能的组合ik_smart:会将文本做最粗粒度(能一次拆分就不两次拆分)的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、国歌」
二、ES安装ik
首先需要ik包,下载地址:
我们选用的是ES 7.140 版本的,所以这里要下载 7.14.0 的 ik:

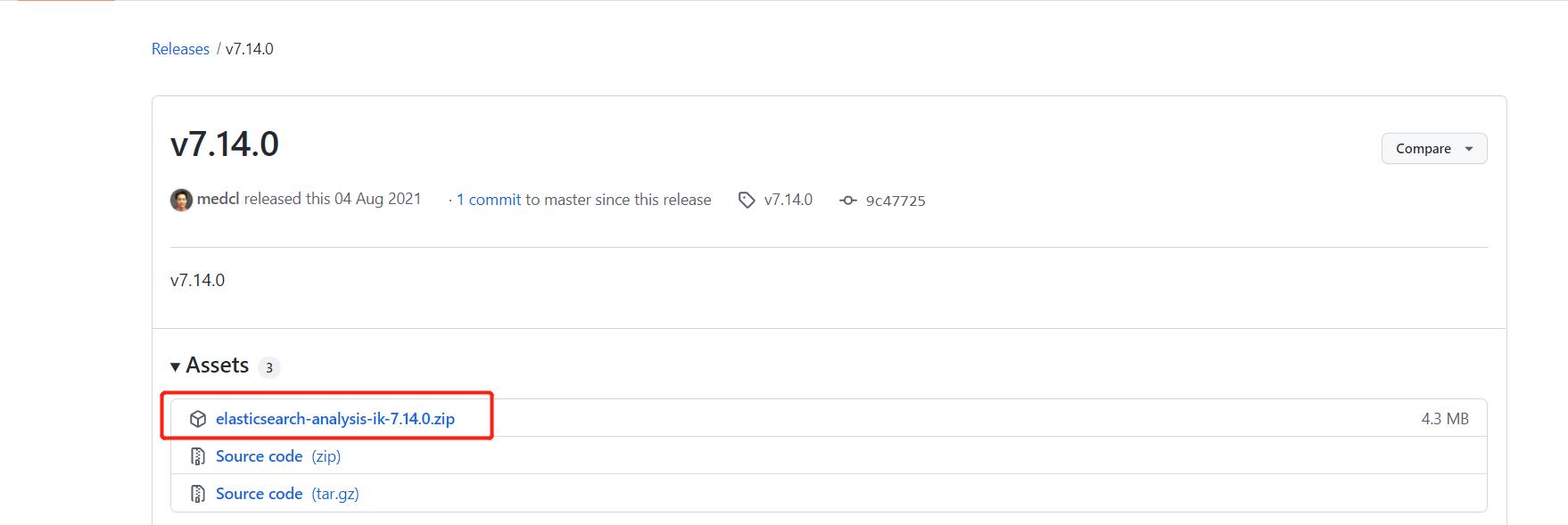
下载完成后,新建ik目录,并将解压后的文件放在ik目录下:
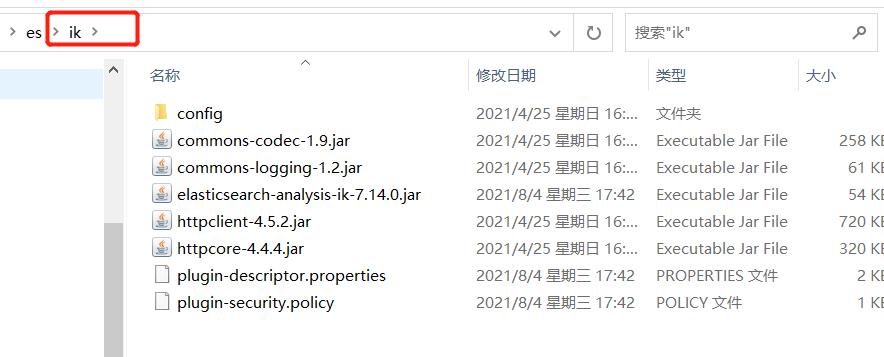
下面将ik 目录复制到es安装目录的 plugins 目录下:

重新启动 es:
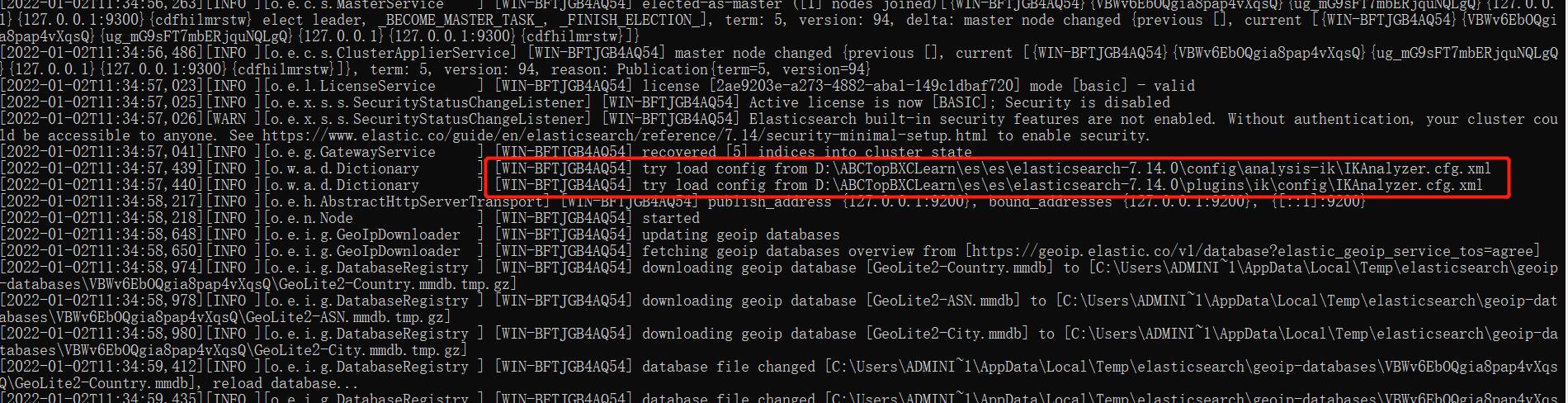
可以看到已经自动加载ik的配制。
三、测试中文分词
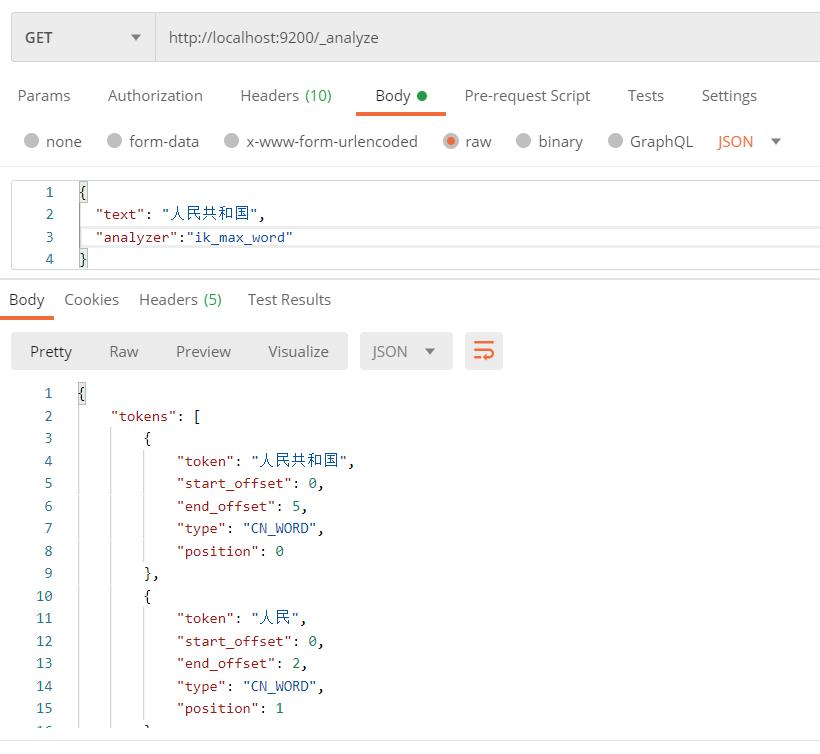
ik_max_word 细粒度分词
使用PostMan 向ES服务器 发送Get请求:
http://localhost:9200/_analyze
请求体内容:
"text": "人民共和国",
"analyzer":"ik_max_word"
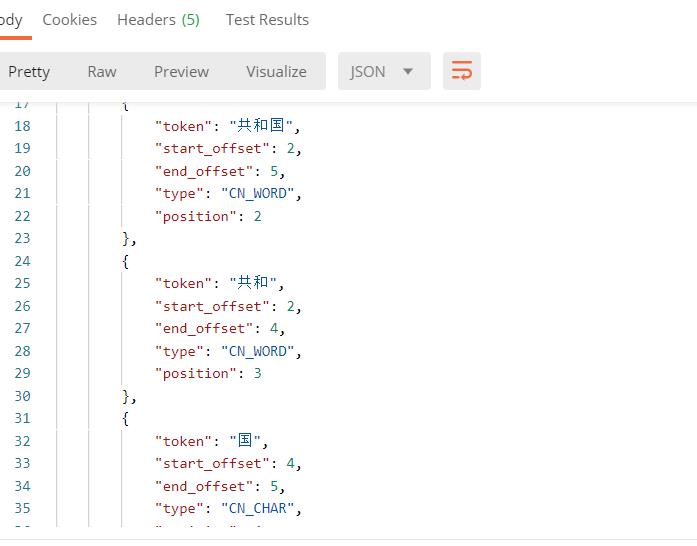
已经不是以前的一个中文就是一个词了,下面再测试下 ik_smart 的效果:
ik_smart 粗粒度分词
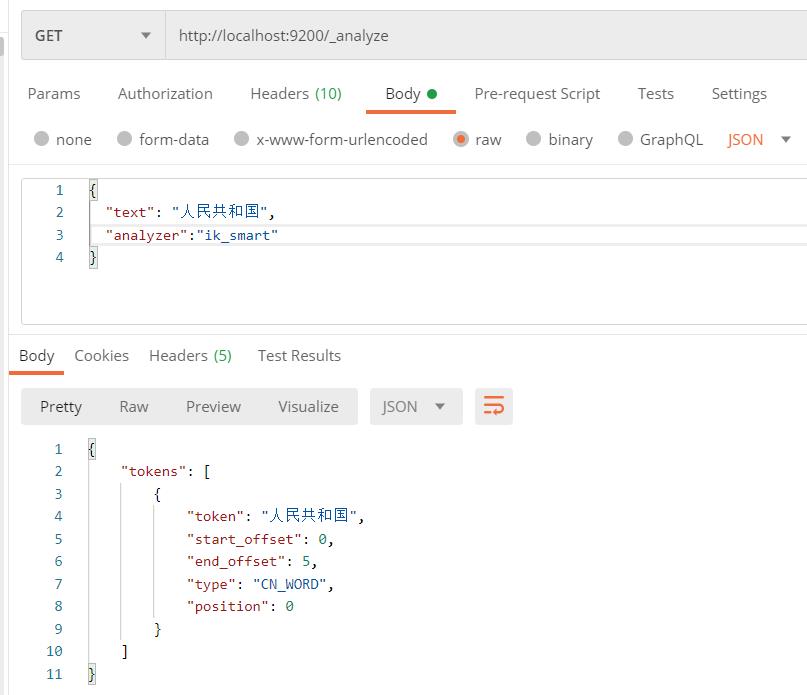
现在就已经成功使用了,ik中文分词器。
四、ik 扩展词汇
上面已经使用了ik分词器,已经有了分词效果,但是再对一些名词进行分词时,会怎么样的,如果测试下:德玛西亚 这个词,我们希望作为一个整体分词,下面看下结果:

可以看到将德玛西亚 这个词给分开了,这是由于Ik自带的分词库中并没有这个名词,所以就不知道怎么分了,此时,我们就可以进行扩展词汇:
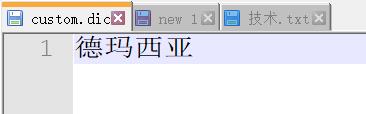
首先进入es安装目录,进入plugins\\ik\\config 目录下,创建 custom.dic 文件,内容我们写入:德玛西亚:
在这里插入图片描述
下面修改plugins\\ik\\config\\IKAnalyzer.cfg.xml文件:
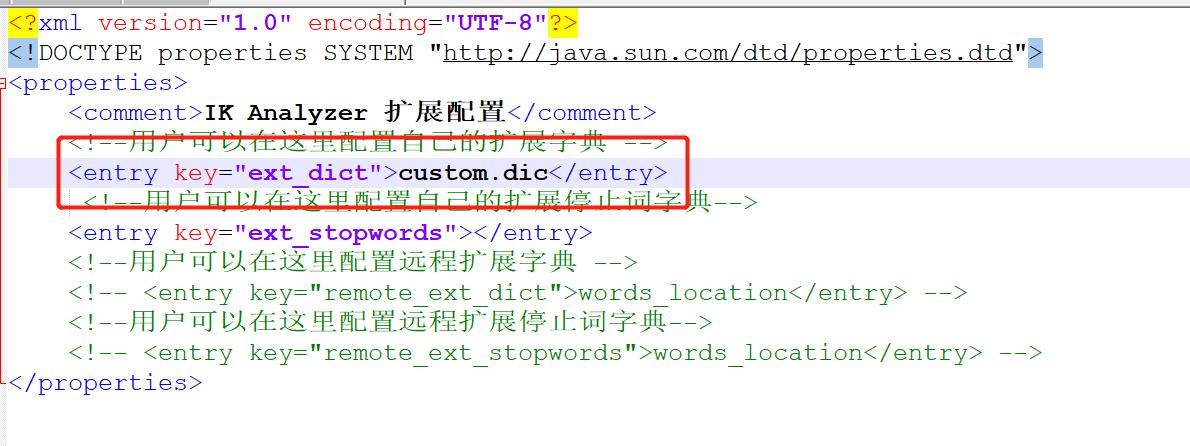
下面重启es,

可以看到已经加载我们自定义的词汇。
下面再来做上面的请求:
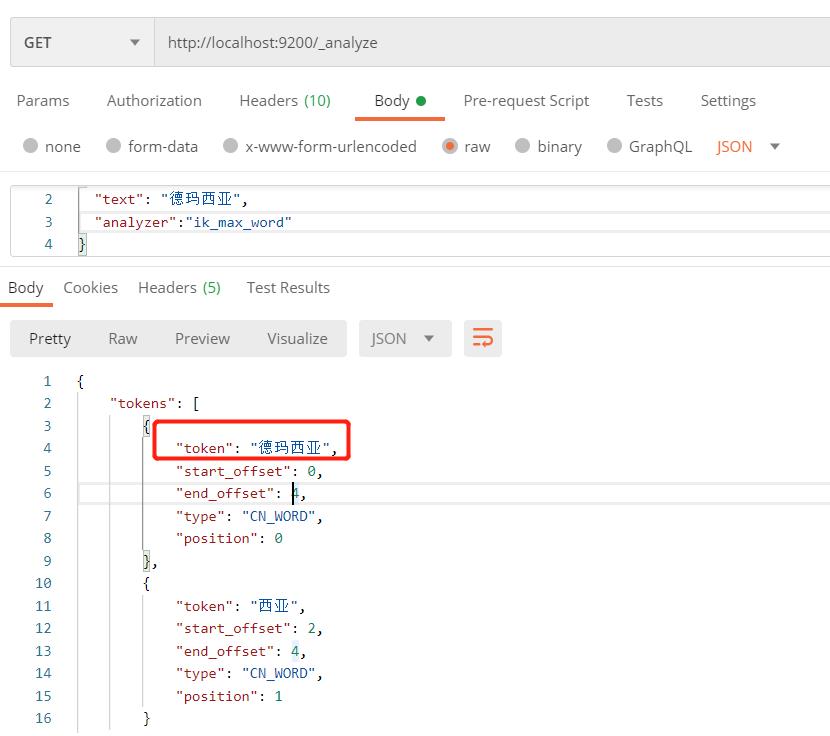
已经分词出了德玛西亚这个词语。
五、远程动态词库
上面已经实现对词库的扩展,但是会发现一个弊端,就是一旦扩展后就需要重启es使扩展词汇生效,如果使生产环境怎么能随便对es进行重启呢,对此es提供了远程词汇的方式,我们对远程词汇文件进行修改,es每次都以http请求的方式获取分词,但要符合两个条件:
- 该 http 请求需要返回两个头部(header),一个是 Last-Modified,一个是 ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
- 该 http 请求返回的内容格式是一行一个分词,换行符用 \\n 即可。
满足上面两点要求就可以实现热更新分词了,不需要重启 ES 实例。
对此,官方也给出了方案,就是将分词文件放在nginx中,当文件被修改nginx自动返回相应的 Last-Modified 和 ETag:

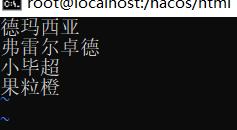
下面我们根据官方的方案进行实现下,首先新建一个 ik_dict.txt ,写入以下内容:
德玛西亚
弗雷尔卓德
小毕超
然后将该文件放在nginx的静态资源目录下:

然后启动nginx,访问http://192.168.40.167:8080/ik_dict.txt,注意修改为自己的ip:

然后修改es安装目录下 /plugins/ik/config/IKAnalyzer.cfg.xml文件:

然后重启es,测试效果:
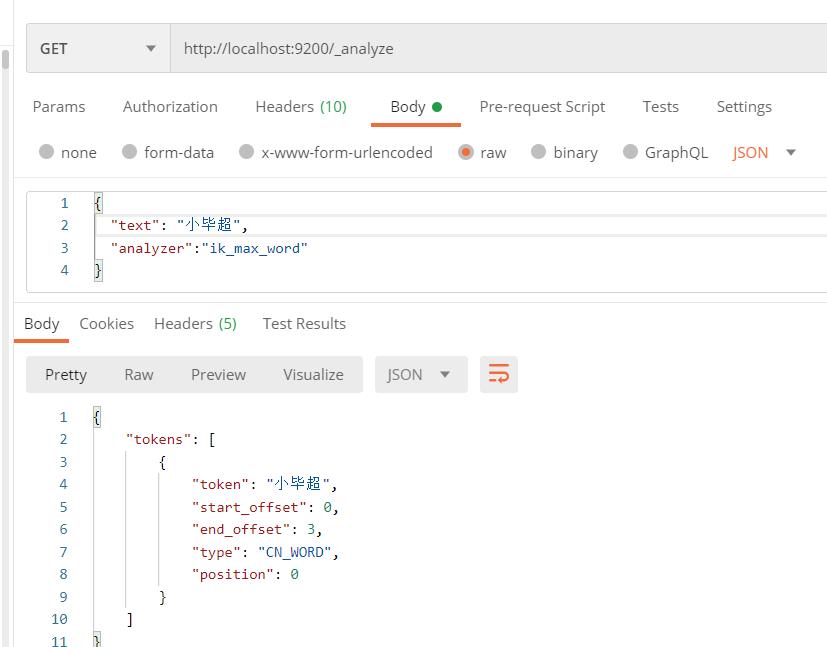
由于我们在远程库中配制了小毕超所以这里可以分析出来。
下面测试下没有配制的词语,比如果粒橙这个词语:

现在是一个字算了一个词语,下面我们修改ik_dict.txt文件:
再来请求下:
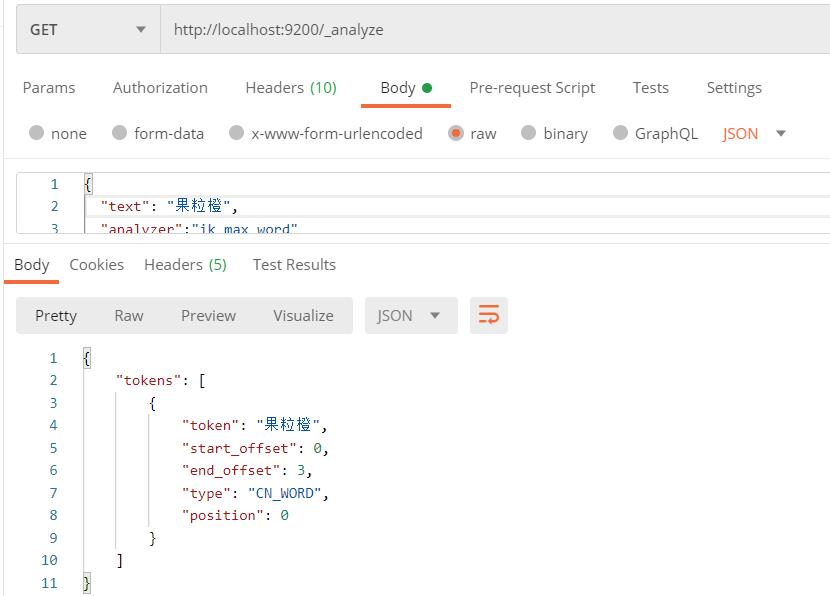
此时就实现了,无需重启es,热更新词库的效果了。
六、扩展 - 更新历史索引
上面已经实现了动态词库的效果,上面使用的都是直接使用分词器进行测试的,在实际使用中不可能这样做的,都是去查询数据的,所以这里就会出现一个问题。
在我们自定义拓展词库更改后,在原先的索引文档中,由于不是新插入的数据,所以其倒排索引列表还是原先的分词列表数据,导致就算拓展了词库,新增的分词也没有生效。在不重新导入数据的前提下,处理办法如下:
通过_update_by_query去更新匹配的文档,如果没有指定查询,那么就会在每个文档上执行更新:
向es服务器发送POST请求:
http://127.0.0.1:9200/user/_update_by_query?conflicts=proceed
其中user为索引名称,conflicts表示如果更新过程中发生异常冲突时如何处理,有两种方案:
- abort:中止(默认)
- proceed:继续执行
注意更新索引,会影响线上的es的 qps,尽量选择夜深人静的时候进行更新。

喜欢的小伙伴可以关注我的个人微信公众号,获取更多学习资料!
以上是关于Elasticsearch 7.X 中文分词器 ik 使用,及词库的动态扩展的主要内容,如果未能解决你的问题,请参考以下文章