集成学习让你的模型更快更准
Posted 机器学习社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了集成学习让你的模型更快更准相关的知识,希望对你有一定的参考价值。
集成学习是机器学习中重要的分支,比如常用的Bagging和Boosting方法,以及一些机器学习模型如Random Forest,AdaBoost也都属于集成学习的范畴。在深度学习领域,通过集成多个模型往往也能提升效果,但模型集成相比单个模型的效率并没有得到系统的研究。近期,Google的一篇论文Wisdom of Committees: An Overlooked Approach To Faster and More Accurate Models系统地研究了基于委员会的模型(committee-based models,即model ensembles or cascades)的效率问题,发现最简单的模型集成或级联方法就能达到甚至超过单个SOTA模型的精度,而且计算量和速度上更有优势,比如两个EfficientNet-B5模型集成可以达到EfficientNet-B7的精度,但是FLOPs降低了50%(20.5B vs 37B),而级联两个EfficientNet-B5模型同样能达到相同的精度,但FLOPs可以进一步降低到13.1B。论文虽然主要研究了模型集成和级联在图像分类问题上的效率,但也在其它任务上(视频分类和语义分割)做了进一步验证。本文将简单介绍这篇论文的主要研究内容以及结论。
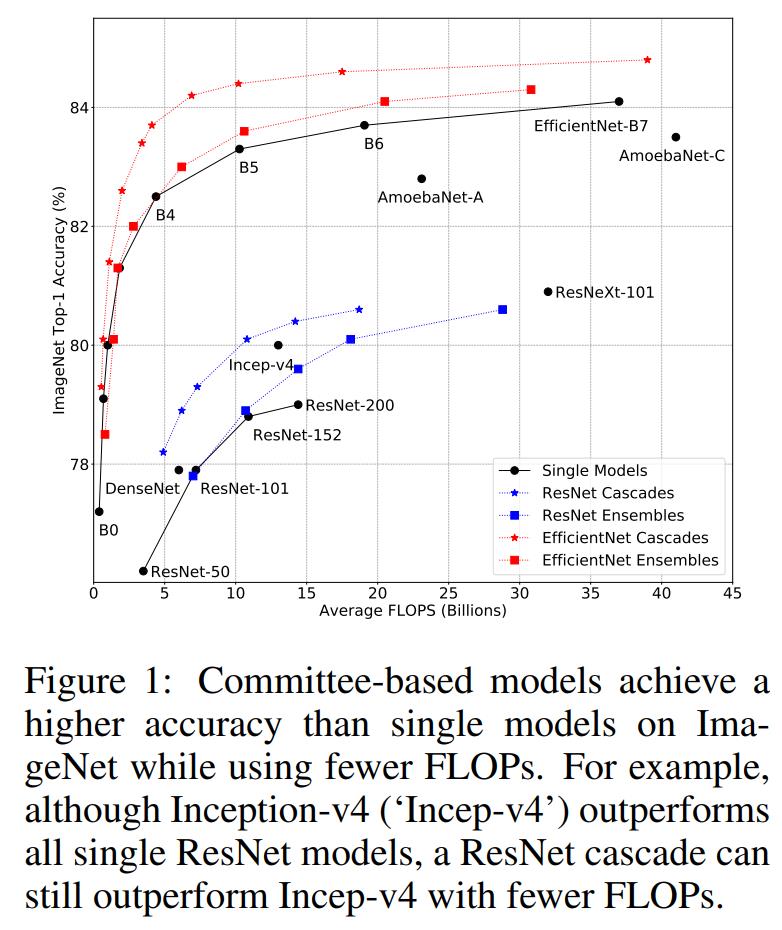
image.png
模型集成
众所周知,集成多个模型往往能提升准确度,但引入了额外的计算量;如果固定计算量,那么模型集成是否能够超越单个模型呢?这里以三个不同的图像分类模型EfficientNet,ResNet和MobileNetV2在ImageNet数据集上的表现来研究这个问题,这个三个架构都包含一系列不同计算量和分类准确度的模型,比如EfficientNet从B0到B7,模型FLOPs增加的同时分类准确度也同步增加。对每个架构,可以训练很多的模型(对于同样的模型设定,可以采用不同的随机种子训练多个模型)来进行集成来和单个模型进行对比。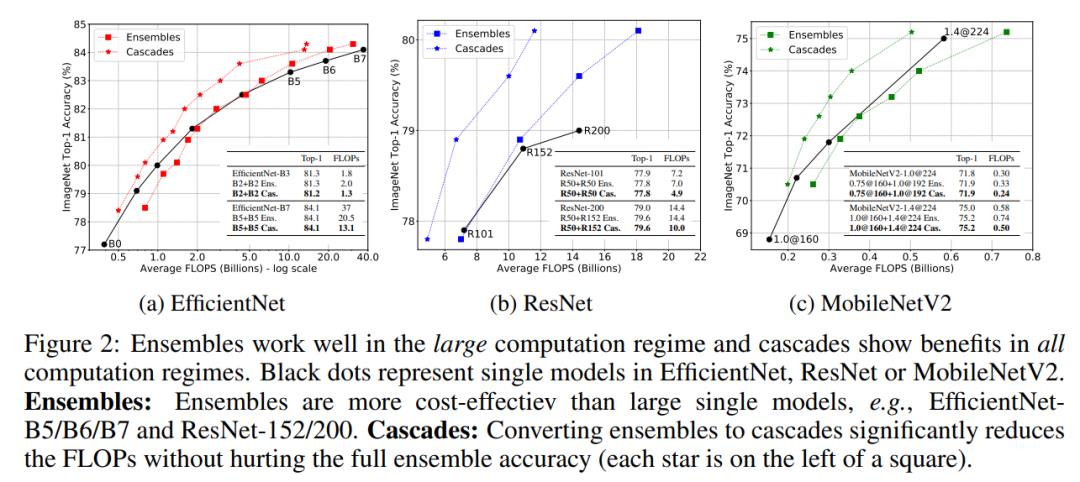 集成策略可以采用最简单的求平均方法:假定要对个不同的模型进行集成,对于给定的输入图像,模型预测的logits为(分类层的输出向量),取各个模型预测logits的平均值来作为模型集成的预测结果(用模型预测分类概率取平均是模型集成更常用的方法,不过论文实验发现两种方案效果是类似的),直接对logits取argmax就可以得到预测的分类类别。模型集成后的FLOPs是各个模型的FLOPs之和。模型集成和单个模型的对比效果如上图所示,可以看到:
集成策略可以采用最简单的求平均方法:假定要对个不同的模型进行集成,对于给定的输入图像,模型预测的logits为(分类层的输出向量),取各个模型预测logits的平均值来作为模型集成的预测结果(用模型预测分类概率取平均是模型集成更常用的方法,不过论文实验发现两种方案效果是类似的),直接对logits取argmax就可以得到预测的分类类别。模型集成后的FLOPs是各个模型的FLOPs之和。模型集成和单个模型的对比效果如上图所示,可以看到:
-
对于大计算量设置,达到同样的分类性能,模型集成要比单个模型在计算上更高效,比如对于EfficientNetB5/B6/B7和ResNet-152/200模型,集成后的模型的FLOPs要更小;
-
对于小计算量设置,达到同样的分类性能,单个模型比模型集成更高效,比如对于MobileNetV2模型,集成后的模型的FLOPs更大一些;
对于这种现象,可以用机器学习中的bias-variance tradeoff理论给出一个合理的解释。大模型拥有小的bias但大的variance,此时variance对测试误差影响较大,而模型集成能有效降低variance;但是小模型的bias大,此时bias往往主导测试误差,模型集成带来的variance收益无法抵消小模型bias的影响。
上面的实验可以看出对于大模型,通过模型集成可以在达到相同的性能时降低计算量,而且多个模型还可以并行计算从进一步加速。同时,模型集成的总训练时间也是优于单个模型的,比如两个EfficientNetB5模型的训练总时长为96,,比单个EfficientNetB7的训练时长160要小不少,但集成后与单个模型效果相当。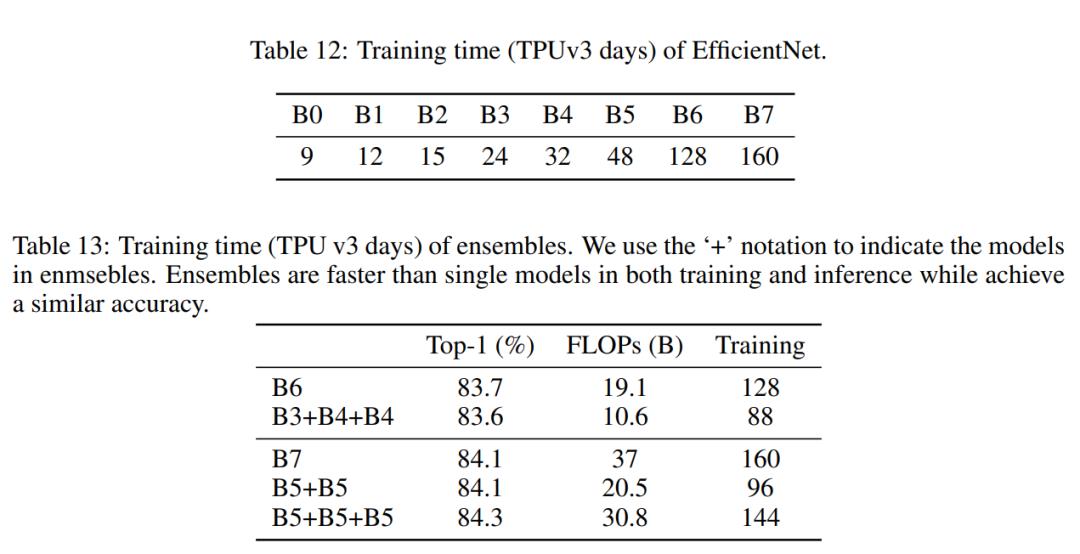
模型级联
模型集成虽然简单,但是存在计算冗余,因为大量的简单样本只需要单个模型就能给出正确的分类结果。一种有效降低计算量的方法是采用模型级联(model cascades),模型集成是并行计算多个模型,而级联是串行计算多个模型,它允许中间提前终止计算,从而减少计算量,具体如下: 可以看到级联是逐渐地集成多个模型,如果中间满足了一定条件,就终止后面模型的计算。这里需要一个置信度函数(confidence function)来决定是否停止后面模型的使用,这个置信度函数能给出模型对当前样本预测的确信度,如果模型对预测结果已经很确信了,那么就没有必要集成后面的模型了。一种最简单的置信度函数是计算模型预测的最大概率值:,因为往往预测概率值越大,模型的预测越准确,实际上论文实验发现大部分的模型存在稍微的underconfident,如下图所示,比如模型的预测概率为0.6时,模型的分类准确度理论上要接近60%,但实际上模型分类准确度比这个值要高一些(红色线),这说明模型对自己的预测有点不自信(低估了自己的能力),对于这种问题,可以通过模型校准来解决(蓝色线),不过论文发现校准几乎不影响效果,这大概是模型只存在少量的underconfident。
可以看到级联是逐渐地集成多个模型,如果中间满足了一定条件,就终止后面模型的计算。这里需要一个置信度函数(confidence function)来决定是否停止后面模型的使用,这个置信度函数能给出模型对当前样本预测的确信度,如果模型对预测结果已经很确信了,那么就没有必要集成后面的模型了。一种最简单的置信度函数是计算模型预测的最大概率值:,因为往往预测概率值越大,模型的预测越准确,实际上论文实验发现大部分的模型存在稍微的underconfident,如下图所示,比如模型的预测概率为0.6时,模型的分类准确度理论上要接近60%,但实际上模型分类准确度比这个值要高一些(红色线),这说明模型对自己的预测有点不自信(低估了自己的能力),对于这种问题,可以通过模型校准来解决(蓝色线),不过论文发现校准几乎不影响效果,这大概是模型只存在少量的underconfident。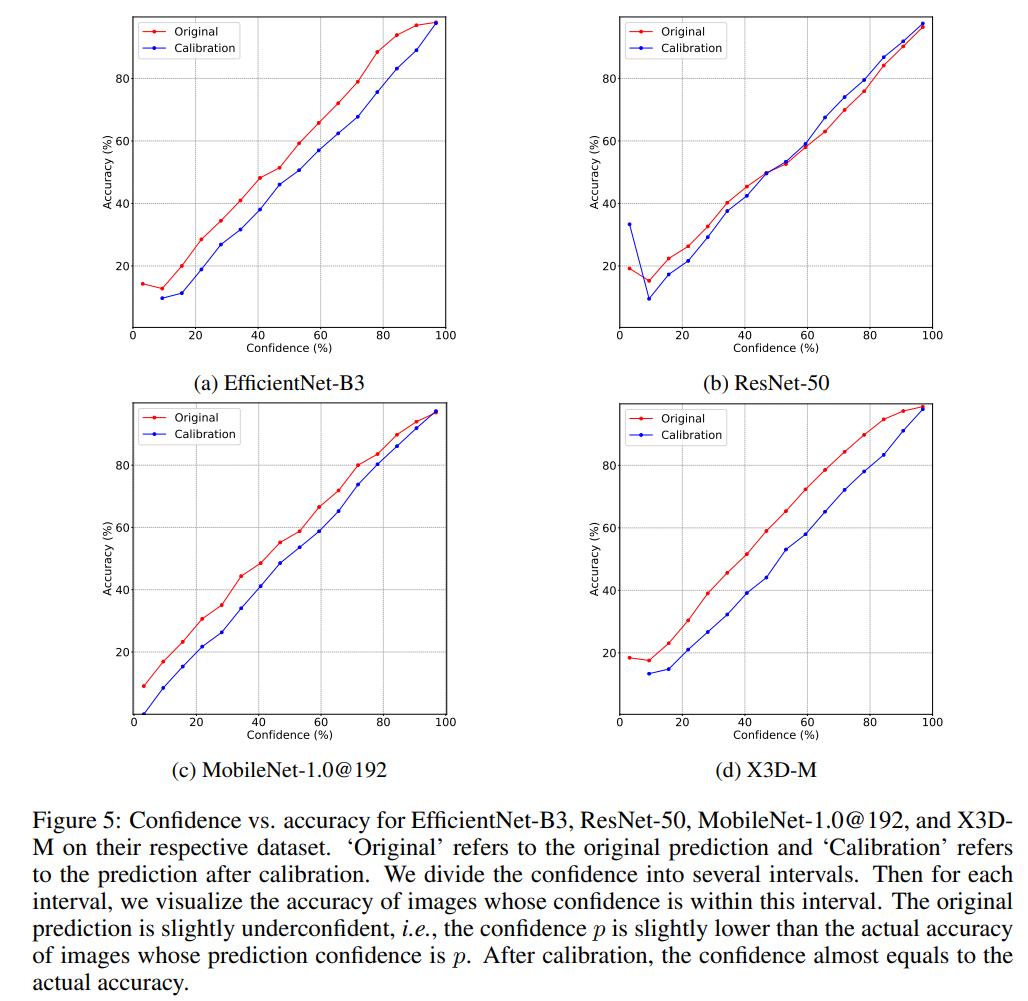 除了用最大预测概率作为置信度外,还可以用其它的指标,比如用最大的概率和第二大概率的gap,最大的logits和第二大logits的gap以及预测分布的负熵,它们都表现相似的性能,如下图所示(按置信度排序,计算不同topk样本下的准确度),论文默认采用最大概率。
除了用最大预测概率作为置信度外,还可以用其它的指标,比如用最大的概率和第二大概率的gap,最大的logits和第二大logits的gap以及预测分布的负熵,它们都表现相似的性能,如下图所示(按置信度排序,计算不同topk样本下的准确度),论文默认采用最大概率。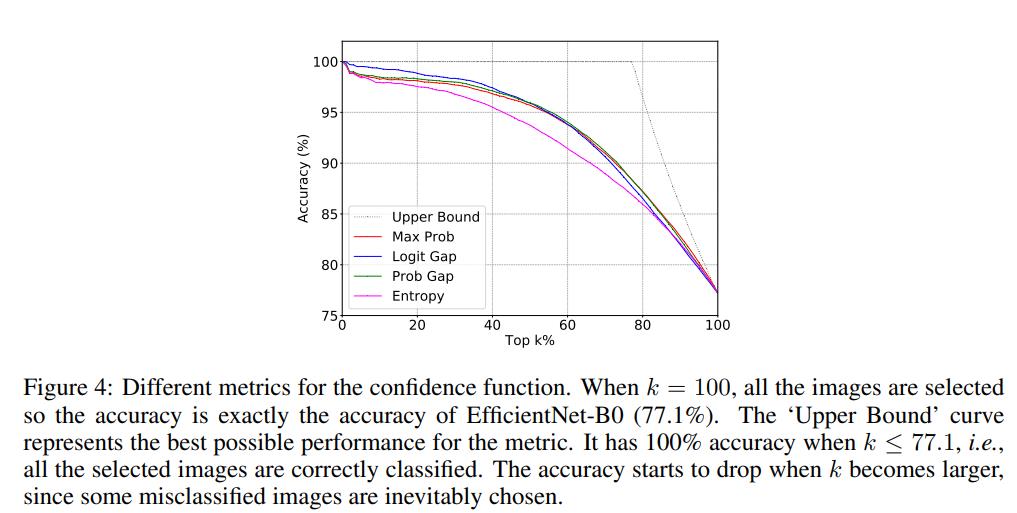 除了置信度函数,个模型级联还需要确定个阈值,当置信度大于这个阈值时,说明模型预测比较自信,就停止后面的模型计算。当置信度选择最大概率时,阈值取值范围为[0,1],阈值越小,后面模型集成的概率越小,当为0时就退化成单个模型,而为1时就变成完全的模型集成了。模型级联的FLOPs是变动的,但可以用验证集上所有图片的FLOPs的平均值来表示。当阈值从0到1变化时,FLOPs是逐渐增加的,只到全部模型的FLOPs之和。下图展示了模型级联在阈值变化下FLOPs和分类准确度的变化,可以看到每个曲线都会收敛到一条平线,这说明模型级联在达到和模型集成相似的效果下大大降低计算量。如果将之前的模型集成直接转成模型级联,模型级联在不同架构和不同计算量设置下均比单个模型计算更高效(见文中第2个图)。
除了置信度函数,个模型级联还需要确定个阈值,当置信度大于这个阈值时,说明模型预测比较自信,就停止后面的模型计算。当置信度选择最大概率时,阈值取值范围为[0,1],阈值越小,后面模型集成的概率越小,当为0时就退化成单个模型,而为1时就变成完全的模型集成了。模型级联的FLOPs是变动的,但可以用验证集上所有图片的FLOPs的平均值来表示。当阈值从0到1变化时,FLOPs是逐渐增加的,只到全部模型的FLOPs之和。下图展示了模型级联在阈值变化下FLOPs和分类准确度的变化,可以看到每个曲线都会收敛到一条平线,这说明模型级联在达到和模型集成相似的效果下大大降低计算量。如果将之前的模型集成直接转成模型级联,模型级联在不同架构和不同计算量设置下均比单个模型计算更高效(见文中第2个图)。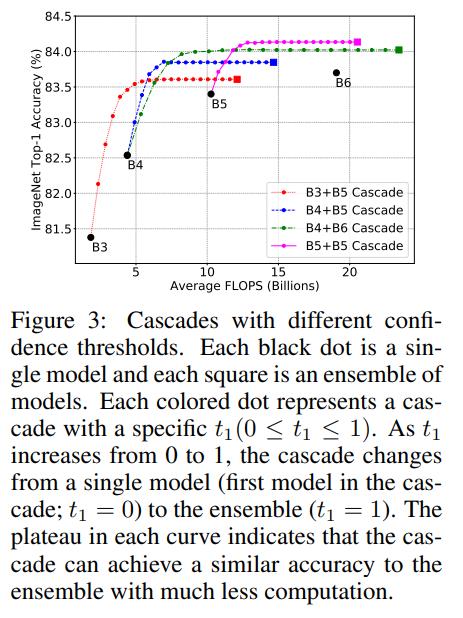
模型级联涉及组合不同的模型,而且也需要确定阈值超参数,在特定的条件下,这就变成了一个寻优问题。假定为模型候选集(可用于级联的模型集合),并限制FLOPs不能超过,模型级联共选择个模型,阈值设定为,此时就需要求解一个约束优化问题: 同样地,如果限定的条件是分类准确度下限,那么优化目标变成了最小化FLOPs。由于现实中和往往较小,比如EfficientNet架构设定,此时这个优化问题可以用穷举法来求解。下表给出了两种不同的限定条件下,EfficientNet,ResNet和MobileNetV2三种不同的架构模型级联的效果。可以看到,在相似的FLOPs下,模型级联的分类准确度要比单个模型有提升;而在相似的分类准确度下,模型级联的计算量较单个模型降低。
同样地,如果限定的条件是分类准确度下限,那么优化目标变成了最小化FLOPs。由于现实中和往往较小,比如EfficientNet架构设定,此时这个优化问题可以用穷举法来求解。下表给出了两种不同的限定条件下,EfficientNet,ResNet和MobileNetV2三种不同的架构模型级联的效果。可以看到,在相似的FLOPs下,模型级联的分类准确度要比单个模型有提升;而在相似的分类准确度下,模型级联的计算量较单个模型降低。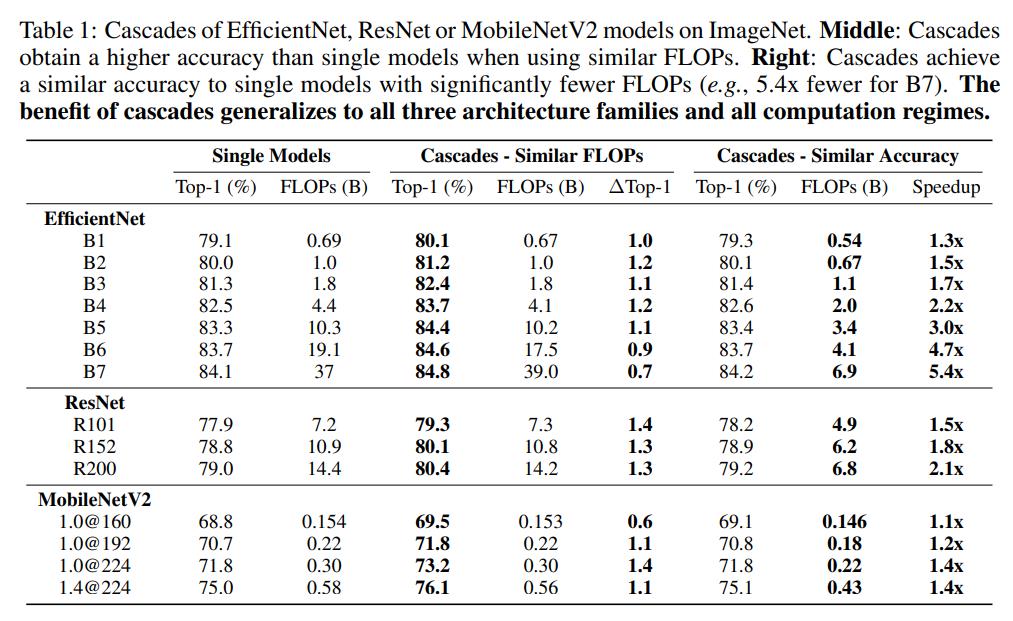 对于ViT架构,通过模型级联也可以得到类似的结论,如下表所示:
对于ViT架构,通过模型级联也可以得到类似的结论,如下表所示: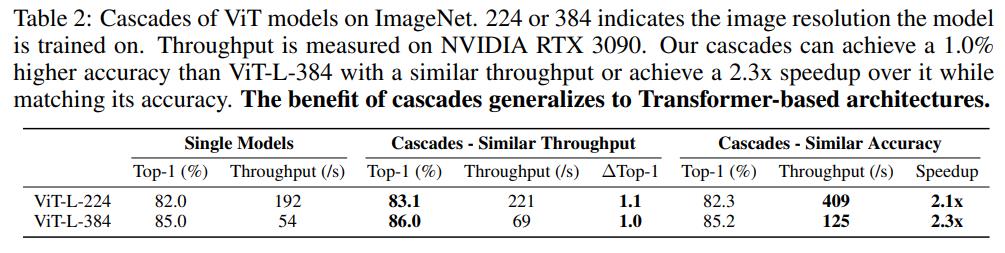 FLOPs并不直接等价于推理速度,论文同样对比了模型级联在TPU上的latency和throughput,如下表所示,可以看到FLOPs的减少确实带来的推理速度的提升。
FLOPs并不直接等价于推理速度,论文同样对比了模型级联在TPU上的latency和throughput,如下表所示,可以看到FLOPs的减少确实带来的推理速度的提升。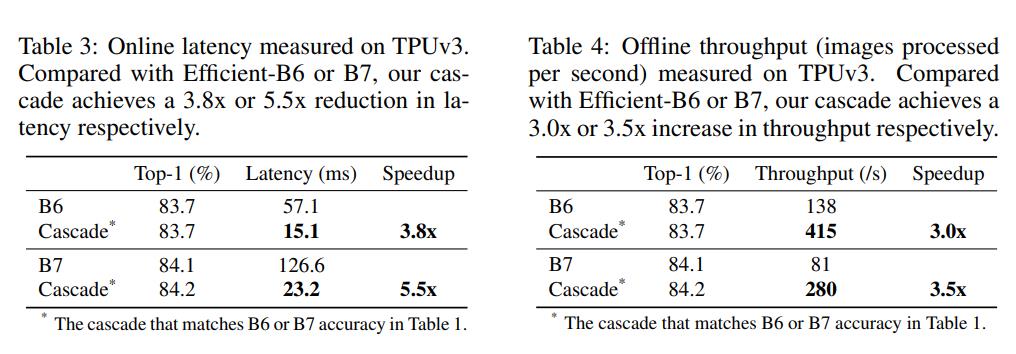 模型级联提升效率的优势主要在于提前停止,比如对于对标B7性能的一个4模型级联:[B3,B5,B5,B5],67.3%的图像只用了B3,而只有5.5%的图像用了所有的模型,这相比单个B7大模型可以大幅度减少计算量。
模型级联提升效率的优势主要在于提前停止,比如对于对标B7性能的一个4模型级联:[B3,B5,B5,B5],67.3%的图像只用了B3,而只有5.5%的图像用了所有的模型,这相比单个B7大模型可以大幅度减少计算量。
模型级联计算的是平均FLOPs,对于少量的样本会用到所有的模型,此时FLOPs就是所有模型的FLOPs之和,这是最差的情况。某些实际的应用场景往往需要保证最大的计算延迟,此时在寻优过程中就需要加上这个限制:。基于这个新增约束,新的实验结果如下所示,可以看到模型级联在得到相似的分类性能下,不仅能够加速,而且也能保证最差的FLOPs小于单个模型。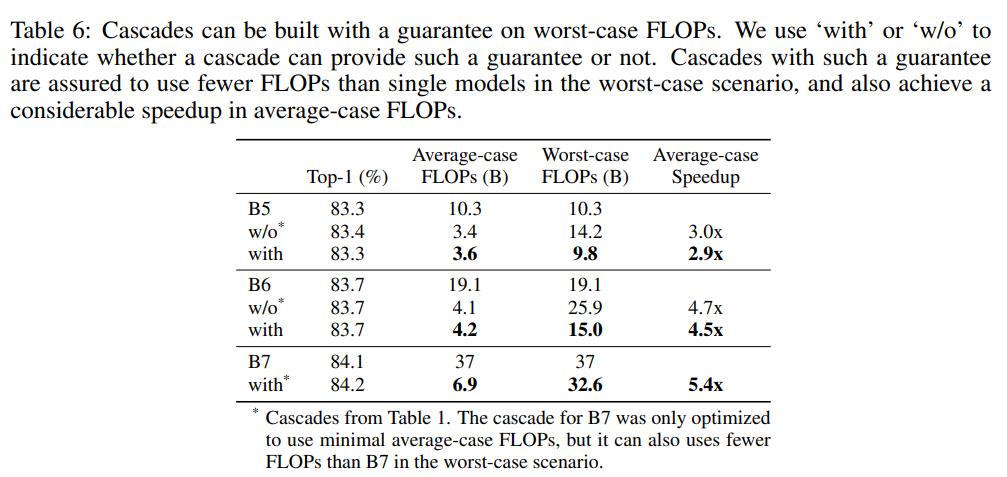 对于模型级联,除了阈值外,还有一个超参数就是模型数量,论文以EfficientNet实验,发现3-model级联要比2-model级联效果要好一些,但是4-model级联提升效果就不太明显了。这说明模型级联也存在性能上限。
对于模型级联,除了阈值外,还有一个超参数就是模型数量,论文以EfficientNet实验,发现3-model级联要比2-model级联效果要好一些,但是4-model级联提升效果就不太明显了。这说明模型级联也存在性能上限。
自级联
模型级联需要训练多个模型,如果只有一个模型,其实也可以进行级联,只不过是改变输入图像的分辨率。大部分情况下,提升输入图像分辨率会提升模型效果(存在上限),据此,在单模型级联可以逐渐提升图像分辨率。论文实验2-model级联,如下表所示,可以看到单模型多尺度级联相比单个模型也能提升计算效率,比如B6模型在528和600尺度上级联,性能可以达到B7效果,而且加速1.6x。
模型级联缩放
单个模型可以进行缩放来得到不同FLOPs的模型,比如EfficientNet设计了一个统一缩放因子来缩放模型的depth,width和resolution:,这里。当时,就是EfficientNetB0模型,而对应EfficientNetB7模型。那么模型级联是否也能够缩放呢,比如已经建立了一个base模型级联,是否能对级联的模型进行缩放,从而得到不同FLOPs下的级联模型。这里建立一个3-model级联的模型C0来对应EfficientNetB0,建立C0的候选模型包括13个模型,它们的缩放因子分别为:-4.0, -3.0, -2.0, -1.0, 0.0, 0.25, 0.5, 0.75, 1.0, 1.25, 1.50, 1.75, 2.0 ,部分比EfficientNetB0小,部分比EfficientNetB0大,最终寻优得到的C0其级联模型为-2.0,0.0,0.75。有了C0,就可以对C0的3个模型分别进行缩放(增加),从而得到不同FLOPs的级联模型。具体的结果如下所示,构建的C0C7可以和EfficientNetB0B7得到相似的效果。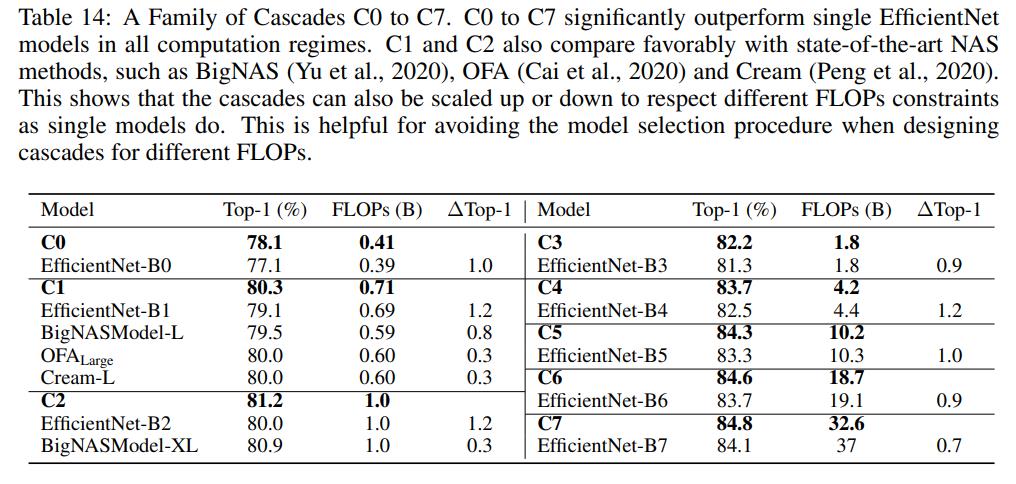
视频分类
与图像分类类似,视频分类模型最后的分类层也是预测logits,所以也可以用相同的方法对模型进行级联。这里以X3D架构和Kinetics-600数据集为例,X3D架构包括3个不同FLOPs的模型X3D-M,X3D-L和X3D-XL。对比结果如下表所示,可以看到无论是限定FLOPs还是分类准确度,级联后的模型均优于单个模型。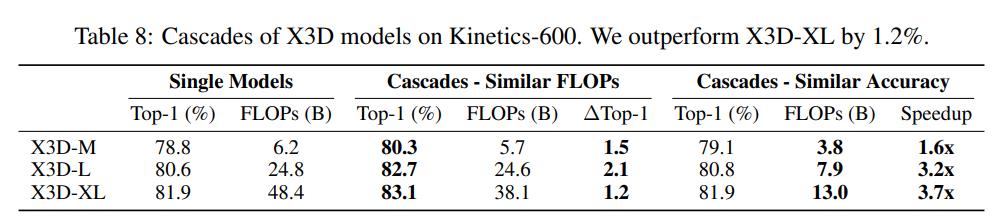
语义分割
对于语义分割,情况更复杂一些,因为语义分割预测图像中每个像素的分类logits,所以需要调整置信度函数。具体地,先计算每个像素点的最大预测概率值:,然后需要聚合所有像素的结果来得到整个图像的置信度,这里计算的是图像中所有像素点置信度的平均值:,这种方式比较简答粗暴,但是语义分割的一个现实难点是不同区域的分割难度可能不一样,如果只采用一个置信度来代表整个图像可能会不够准确,一个简单的解决方案是将图像分成不同的网格,对每个格子单独做级联。这里以DeepLabV3架构和Cityscapes数据集为例,建立一个2-model级联( DeepLabv3-ResNet-50和DeepLabv3-ResNet-101 ),具体的结果如下所示,这里的 指的是网格的大小,图像的输入为1024x2048大小,表示将图像分成8个网格。可以看到,如果不分成网格,虽然级联后模型的mIoU提升了但是FLOPs却增加了,如果分成网格能有加速效果。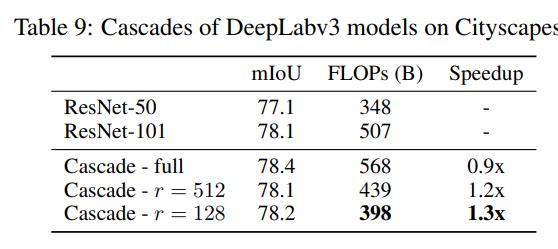 一个要注意的点是,对于语义分割Cityscapes数据集,很多像素点是没有标注的(训练和测试时忽略),这对计算置信度带来噪音,所以在实际计算整图置信度时只考虑置信度大于某个固定阈值下的像素点,即,这里设为0.5。
一个要注意的点是,对于语义分割Cityscapes数据集,很多像素点是没有标注的(训练和测试时忽略),这对计算置信度带来噪音,所以在实际计算整图置信度时只考虑置信度大于某个固定阈值下的像素点,即,这里设为0.5。
小结
对于模型集成或者级联,直观上会觉得增加了计算成本,但如果合理设计后反而是提升计算效率,这在工业部署实践中还是有比较大的应用意义。不过对于比较复杂的任务如分割和检测,模型集成就需要比较特殊的设计。
参考
- Wisdom of Committees: An Overlooked Approach To Faster and More Accurate Models
以上是关于集成学习让你的模型更快更准的主要内容,如果未能解决你的问题,请参考以下文章
目标检测开源框架YOLOv6全面升级,更快更准的2.0版本来啦