海量数据分析更快更稳更准。GaussDB(for MySQL) HTAP只读分析特性详解
Posted 华为云官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了海量数据分析更快更稳更准。GaussDB(for MySQL) HTAP只读分析特性详解相关的知识,希望对你有一定的参考价值。
本文作者康祥,华为云数据库内核开发工程师,研究生阶段主要从事SPARQL查询优化相关工作。目前在华为公司参与华为云GaussDB(for MySQL) HTAP只读内核功能设计和研发。
1. 引言
HTAP(Hybrid Transactional/Analytical Processing)这个词相信大家最近经常会听到,它能够同时支撑在线事务处理(On-Line Transactional Processing, 简称OLTP) 和在线数据分析 (On-Line Analytical Processing, 简称 OLAP)。令人惊喜的是,ClickHouse 作为近年来炙手可热的大数据分析系统可以通过MaterializeMySQL 引擎挂载为 MySQL 的从库,作为 MySQL 的 "协处理器"面向 OLAP 场景提供高效数据分析能力,这对解决异构数据库之间数据共享问题提供了新的途径。我们可以充分发挥 ClickHouse 的分析性能,结合 TP 类引擎如 MySQL 等提供 HTAP 能力。然而实际应用场景中 ClickHouse 仍然面临一些挑战,因此 GaussDB(for MySQL)的HTAP只读分析应运而生,除了拥有 ClickHouse 本身的极致性能外,GaussDB(for MySQL)的HTAP只读分析在 MaterilizeMySQL引擎的性能和稳定性等方面具有更优秀的表现,为提供更快更准的数据分析保驾护航。
2. 背景
大数据时代的到来,数据量急剧增长的同时用户结构也越来越多样化,这些用户处理数据时发现,仅仅是创建一个可视化报表需要经过数据的抽取 (Extract), 转换 (Transform) 和装载 (Load), 整个周期可能长达数日甚至数周。事实上,ETL 模式的优点在于能够结合数据湖等处理多源数据,低成本处理海量数据且生态较完善,当然缺点也十分明显,传统的数据仓库和数据湖等无法支持大量实时并发的更新,数据分析时效性较低。除此之外,ETL 模式应对变化的能力也相对较弱,如上游数据源发生变化(例如表结构的变化等),整个数据链的处理过程都需要做相应的修改,增加了数据维护的难度。
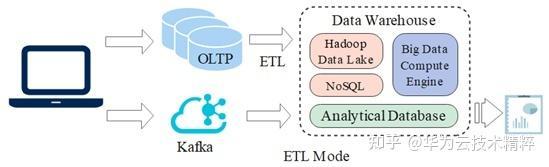
如何追求实时分析呢?答案是 HTAP。HTAP 可以支持大量并发的更新且数据同步时延通常在在秒级或毫秒级,有效避免传统解决方案中数据抽取,转换和装载等繁琐步骤,极大提升数据处理的时效性。
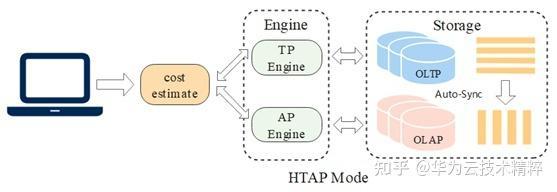
3.极致性能-ClickHouse
- ClickHouse
ClickHouse 是 Yandex 公司开源的面向 OLAP 的分布式列式数据库,具有实时查询、完备的DBMS、高效数据压缩压缩,支持批量更新及高可用等特性。此外,ClickHouse 拥有非常完善的SQL支持以及开箱即用等许多特点。在官方公布的基准测试对比中,ClickHouse 遥遥领先对手。
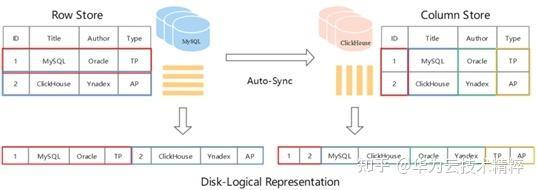
- Row Store & Column Store
MySQL 存储采用的 Row Store,表中数据按照 Row 为逻辑存储单元在存储介质中连续存储。这种存储方式适合随机的增删改查操作,对于按行查询较为友好。但如果选择查询的目标只涉及一行中少数几个属性,Row 存储方式也不得不将所有行全部遍历再筛选出目标属性,当数据表很宽(表的属性很多)时,查询效率通常较低。尽管索引等优化方案在 OLTP 应用场景中能够提升一定效率,但是在面对海量数据背景的 OLAP 场景仍然显得有些力不从心。
ClickHouse 则采用的是 Column Store,表中数据按照 Column 为逻辑存储单元在存储介质中连续存储。这种存储方式适合采用 SIMD(Single Instruction Multiple Data) 并发处理数据,恰恰弥补了 RowStore 存储方式的缺陷,尤其在大宽表(属性很多)的时候,查询效率明显提升。此外,列存方式相邻数据类型相同,因此天然适合数据压缩,从而达到极致的数据压缩比。
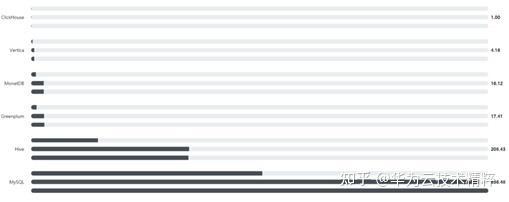
- Performance
下表是 Yandex 公司官方公布的性能测试数据,数据集 100 million,从上至下的三条数据分别表示:Cold Cache,Second Round,Third Round 的查询响应时间,可以看出 ClickHouse 的性能遥遥领先各大数据库引擎,相比于MySQL而言,性能甚至高达600多倍。
注:以下实验数据均为单节点:2 * Intel (R) Xeon (R) CPU E5-2650 v2 @ 2.60GHz; 128 GiB RAM; mdRAID-5 on 8 6TB SATA HDD; ext4.
4. 巨人肩膀上的 GaussDB(for MySQL) HTAP只读分析
尽管 ClickHouse 拥有如此极致的性能,但实践生产过程中仍然面临一些困境。比如存在数据类型不支持,全量复制性能问题等方面的挑战。此外也有一些与引擎本身设计有关的性能问题:比如 FINAL 去重导致的查询性能问题等,给用户使用过程带来一些不好的体验。
- 全量并行复制
Materialize MySQL 引擎通过消费 BinLog 的方式来订阅 MySQL 数据。数据同步过程分为三个步骤,首先是检验源端 MySQL 参数是否符合规范,然后是全量和增量复制阶段。ClickHouse 数据同步的全量复制过程是单线程的,在数据量较大时复制时延较高。GaussDB(forMySQL) HTAP只读分析对全量复制进行了并行化处理,优化后的复制性能平均提升 8-10 倍,对实际生产实践是十分有意义的。
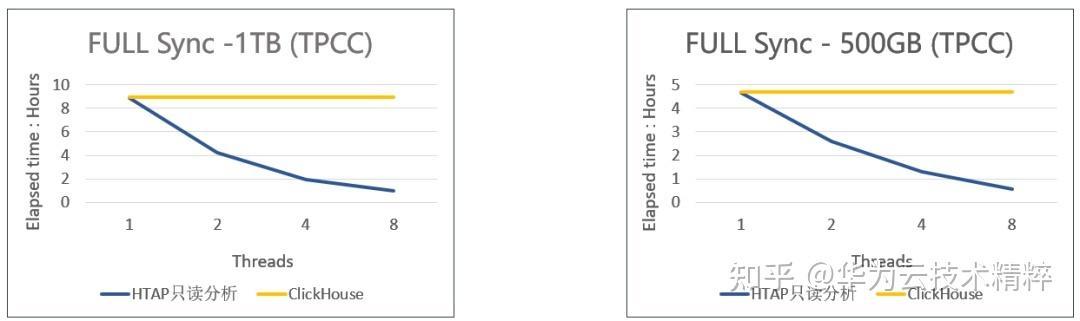
- MVCC & Snapshot
MaterializeMySQL 引擎在 DDL 转化过程中默认增加了2个隐藏字段:_sign (-1删除,1插入/更新) 和 _version (数据版本)。下方是同一张表在 MySQL 和 ClickHouse 里的 DDL:
Create Table: CREATE TABLE `runoob_tbl` (
`runoob_id` int unsigned NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`runoob_id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
---------------------------------------------------------------
ATTACH TABLE _ UUID \'14dbff59-930e-4aa8-9f20-ccfddaf78077\'
(
`runoob_id` UInt32,
`_sign` Int8 MATERIALIZED 1, /// _sign 字段
`_version` UInt64 MATERIALIZED 1 /// _version 字段
Materialize MySQL 引擎当前不提供 MySQL 数据的事务一致性视图,数据行以批量插入的方式同步到 ClickHouse 中,引擎底层使用的是 ReplacingMergeTree。如果数据发生了修改,获取最新的数据时需要指定 FINAL(类似于 GROUP BY)去重,并使用过滤器隐藏已删除的行。然而当数据规模很大时,FINAL 操作的性能往往不太理想。
为了感知事务,GaussDB(for MySQL) HTAP只读分析实现了事务一致性并提供四种隔离级别,用户可以根据具体使用场景选择不同的隔离级别。此外,GaussDB(for MySQL) HTAP只读分析还提供了快照功能,优化 FINAL带来的查询性能问题。
read_uncommitted: 不提供 MVCC 支持,可能会引入脏读
read_committed: 提供 MVCC 支持(包括SubQuery),读最新已 commit 的数据
query_snapshot: 规避 SELECT + FINAL 查询中的 Merge 开销,直接查询快照
query_raw: 不做任何优化,返回所有数据(包括已删除和更新的不同版本)
- FINAL 性能优化
前面提到 MaterializeMySQL 底层使用的是 ReplacingMergeTree,该引擎后台会按照一定规则执行 Merge 操作,用户想要获得最新数据则必须通过 FINAL 操作去重。除了采用 MVCC + Snapshot 机制保障查询性能外,GaussDB(for MySQL) HTAP只读分析从索引以及过滤策略等方面对ReplacingMergeTree 引擎本身的 FINAL 操作进行了优化,即使不依赖 MVCC + Snapshot 也能提供不错的查询性能。
5. GaussDB(for MySQL) HTAP只读分析兼容性及稳定性
- 类型支持增强
MySQL 和 ClickHouse 的基本数据类型之间都有对应的映射关系(见下表),值得一提的是 ClickHouse 将不支持的 MySQL 数据类型都转换为 String 类型存储。MySQL 不支持的 ClickHouse 类型也都被转换为 MYSQL_TYPE_STRING 类型。从下表中不难看出,ClickHouse 仍有一部分数据类型还未支持,而这部分数据类型在实际应用场景中是有可能出现的,因此 GaussDB(for MySQL) HTAP只读分析针对常用的数据类型例如 BIT 和 TIME 以及 YEAR 等做了适配,解决部分用户的刚要需求。
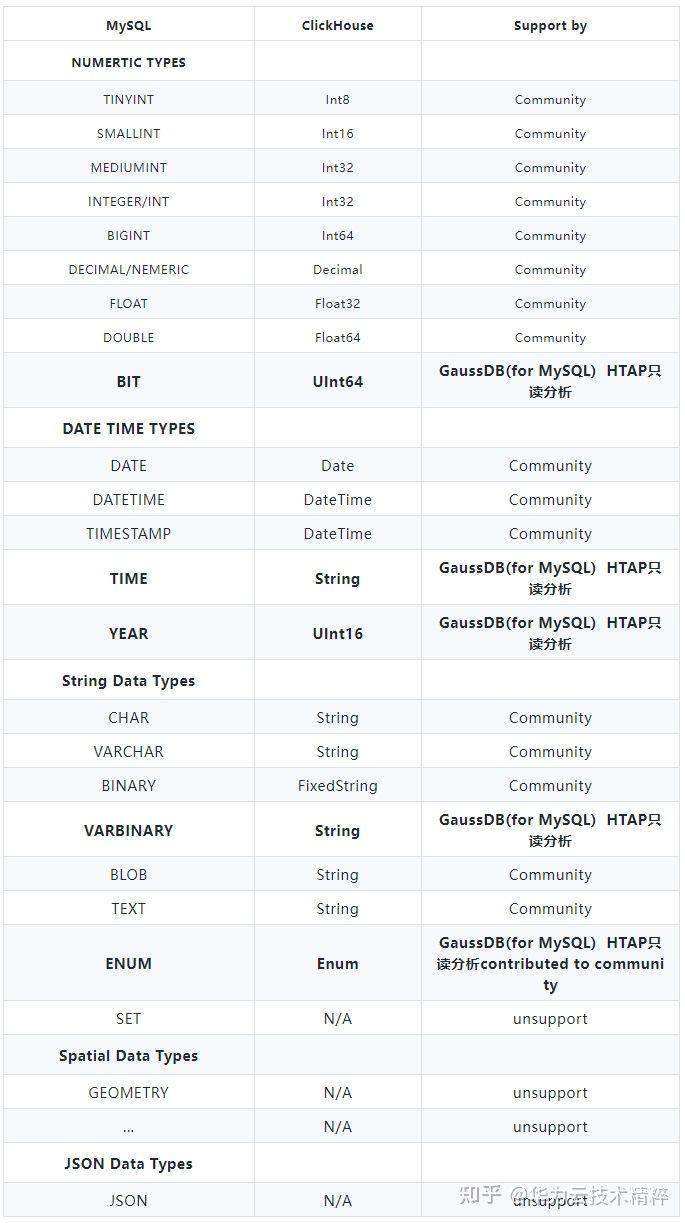
- Unique Key 同步支持
MaterializeMySQL 引擎当前仅支持含有 Primary Key 的表同步,现实生产过程中是可能存在一些表格没有主键,但却含有 Unique Key 的,因此有必要支持这种表的数据同步。GaussDB(for MySQL) HTAP只读分析对仅含有 Unique Key (NOT NULL) 的表单独处理,使用 Unique Key 进行分区。
- 优雅的复制中断重连
实际应用过程中,全量数据复制的数据规模通常较大,同步时间较长,复制中断(网络,MySQL服务端宕机等)的情况是有可能发生的,ClickHouse 遇到上述情况时选择终止当前库的同步并返回错误。为了提升数据同步的稳定性,GaussDB(for MySQL) HTAP只读分析针对MaterializeMySQL 引擎设计了重连,当中断发生时清理现场并在一定时间间隔内进行重连。与全量复制中断重连不同的是,增量复制中断后不需要清理现场,这与增量复制的方式有关,增量复制基于 BinLog Event,已经增量同步成功的数据不需要重新再来一次,重新建立连接后会根据全局 GTID 找到最新的同步点开始同步。
- 更完备的异常处理机制
GaussDB(for MySQL) HTAP只读分析不仅引入了 MVCC +Snapshot 以及并行复制等新特性,也为内核嵌入了更完备的异常处理机制。以全量并行复制为例,GaussDB(for MySQL) HTAP只读分析为所有并行线程维护独立的异常处理信息和堆栈。在新的异常处理机制下 GaussDB(for MySQL) HTAP只读分析更加稳定,更容易帮助用户发觉潜在问题的根源。
6. GaussDB(for MySQL) HTAP只读分析个性化定制
- Show Slave Status 支持
GaussDB(for MySQL) HTAP只读分析为用户提供了类似 MySQL 主备间的 SHOW SLAVE STATUS 指令,通过该指令可以直观地获取 MaterializeMySQL 引擎同步的数据库状态。这些状态信息除了反应同步线程是否异常之外,还涵盖了当前复制的 BinLog 位点,GITD 以及Second Behind Master 等有价值的信息,为用户运维提供极大方便。
- ALTER Database 支持
Alter Database 为 MaterializeMySQL 引擎用户提供了如下操作:
ALTER DATABASE db MODIFY SETTING ... // 修改库级 settings
ALTER DATABASE db ADD TABLE OVERRIDE tbl ... // ADD TABLE 且支持 Override
ALTER DATABASE db MODIFY TABLE OVERRIDE tbl ... // MODIFY TABLE 且支持 Override
ALTER DATABASE db DROP TABLE ...
- 表定义重写 Override
为了提供个性化的建库同步操作,GaussDB(for MySQL) HTAP只读分析为 MaterializeMySQL 引擎增加了 Over Write 功能,用户可以覆盖指定表的列并添加新列,添加索引并覆盖PARTITION BY 或 SAMPLE BY 字段,使用示例如下:
CREATE DATABASE test
ENGINE=MaterializeMySQL(\'host:port\', \'db\', \'user\', \'pw\')
TABLE OVERRIDE table1 (
_staged UInt8 MATERIALIZED 1 // 增加 MATERIALIZED 列,类型为 UInt8
)
PARTITION BY (...) // 覆盖分区字段
- 适配 MySQL Partition
数据分区是提升数据库使用性能的重要途径之一,ClickHouse的分区策略是优先考虑日期,否则会选择类型长度较小的字段做哈希处理并进行分区。可以看到,ClickHouse 的分区策略和 MySQL 有一定区别,为了尽可能的支持 MySQL 的分区策略,GaussDB(for MySQL) HTAP只读分析目前支持 Range 分区,如果建表语句里没有 Range 分区,则使用 ClickHouse 默认的分区策略。
- 黑/白名单过滤
MaterializeMySQL 引擎建立的数据同步是库级的,意味着默认情况下会尝试将该库所有表全部复制,在某些实际应用场景中往往不需要复制全部的表,或者说有些表本身不适合复制(例如没有 Primary Key 或者 NOT NULL 的 Unique Key),GaussDB(for MySQL) HTAP只读分析不希望因为部分表无法复制导致整个库的复制失败,而是能够有选择的进行复制。GaussDB(for MySQL) HTAP只读分析针对这个问题设计了黑/白名单的过滤,允许用户自定义需要复制的表,这在生产应用是十分有意义的,用法参考如下:
CREATE DATABASE test
ENGINE = MaterializeMySQL(\'host:port\', \'db\', \'user\', \'pw\')
SETTINGS black_list=\'T1,T2\' // 将T1、T2加入黑名单
7. 场景示例
前文分析了许多 GaussDB(for MySQL) HTAP只读分析的优点,那 GaussDB(for MySQL) HTAP只读分析到底能提供什么样的解决方案,为用户解决数据难题呢?
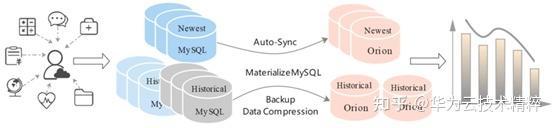
上图以 MySQL + GaussDB(for MySQL) HTAP只读分析为例,用户既能得到 MySQL 完备的事务保障,又能享受到 GaussDB(for MySQL) HTAP只读分析的极致分析性能。用户从不同渠道获取数据并加载到 MySQL 引擎,GaussDB(for MySQL) HTAP只读分析作为 MySQL 的 “从库” 实时同步用户数据并提供高效的数据分析能力。
- 高实效性
与传统 ETL(T + 1)方案不同,GaussDB(for MySQL) HTAP只读分析搭配 MySQL 的 HTAP 解决方案能够提供秒级数据同步。
- 数据压缩
GaussDB(for MySQL) HTAP只读分析底层存储采取 Column Store,这种存储形式天然适合数据压缩,因此GaussDB(for MySQL) HTAP只读分析拥有极致的数据压缩比,同等条件下能够为用户节约大量存储成本。
- 历史备份
相比在 MySQL 中备份,GaussDB(for MySQL) HTAP只读分析的存储成本更低,某些场景下更适合用于历史数据备份。
- 存储分层
为了进一步降低用户存储成本,GaussDB(for MySQL) HTAP只读分析提供 ESSD + EVS + OBS 分层存储方案,将热数据温数据和冷数据分别存在不同的存储介质中,进一步降低存储成本。
8. 小结
HTAP虽然不是一个非常新的概念,但随着现阶段数据业务越来越模糊(AP业务TP化 ,TP业务AP化),这个概念又重新回到了人们的视线。用户对数据处理和消费需求的不断迭代和升级,也为 HTAP 的发展创造了更多机会。GaussDB(for MySQL) HTAP只读分析站在 ClickHouse 极致性能的肩膀上针对实际生产遇到的问题做了一系列优化,获得更快更好的使用体验。相信未来 HTAP 的竞争会愈演愈烈,这对 GaussDB(for MySQL) HTAP只读分析来说既是挑战也是机会,GaussDB(for MySQL) HTAP只读分析会继续为用户提供海量数据的高效解决方案,助力企业数字化转型。
本文由华为云发布。
以上是关于海量数据分析更快更稳更准。GaussDB(for MySQL) HTAP只读分析特性详解的主要内容,如果未能解决你的问题,请参考以下文章
GaussDB(for MySQL) HTAP只读分析特性详解
50亿海量数据如何高效存储和分析? GaussDB (for Cassandra) 3个秘诀搞定